Русский разбить по слогам: Переносы в слове русский, деление на слоги
Слог. Ударение. Перенос слов. | интернет проект BeginnerSchool.ru
Ранее мы разбирали, что же такое звук и буква и делали звуко-буквенный разбор. Когда ребенок твердо усвоил, что такое звук и буква, перейдем к изучению слога.
Как разбить слова на слоги, где в слове поставить ударение и как перенести слово? – это основные понятия, которые будут встречаться в изучении русского языка в начальной школе.
Усвоив эти, казалось бы, простые истины, ребенок будет легко понимать основные правила правописания в русском языке.
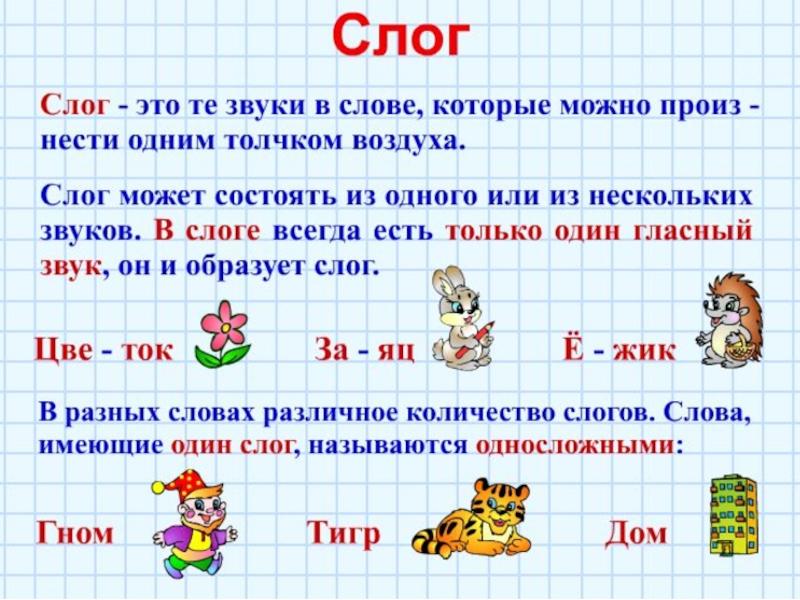
Итак, ранее мы договорились о том, что слово состоит из звуков. А как можно поделить слово на части? Когда мы хотим прокричать слово кому-то находящемуся далеко, мы стараемся разбить слово. Попробуйте вместе с ребенком прокричать слово мама. Как у вас получилось?
ма-ма
Вот вы и разбили это слово на два слога. Попробуйте ещё, например, слова весна и ручейки.
Получилось: вес-на и ру-чей-ки. То есть в слове весна 2 слога, а в слове ручейки 3 слога.
Давайте попробуем пропеть слово мама. Получается м-а-а—м-а-а.
Гласные звуки мы произносим, раскрыв рот – звук свободно выходит изо рта. Произнося согласные звуки, мы ставим речевым аппаратом препятствия звуку. Таким образом, мы разбиваем слова на части, отсюда основное правило:
Сколько в слове гласных, столько и слогов.
Пример слов с одним, двумя и тремя слогами:
Теперь попробуйте сами придумать слова, которые впишутся в предложенные схемы, в каждую ячейку можно вставить только один слог:
Слова, состоящие из одного слога, называются односложными, из двух слогов – двухсложными, из трех – трехсложными и так далее.
Примеры односложных слов: снег, их, птиц, по.
Двухсложных: тихо, ветку, стали.
Трехсложных: гуляет, березы.
Каждое слово произносится с акцентом, на каком ни будь слоге. Для примера возьмем, опять, слово мама.
Мы делаем акцент на первом слоге этого слова: мА-ма. А точнее на первой гласной букве этого слога. Этот акцент и называется ударением и обозначается следующим образом:
А буква, на которую ставится ударение, называется ударной.
Зачем же нужно ударение в слове? Давайте возьмем слово машина:
Мы ставим ударение на гласную букву второго слова. Попробуйте поставить ударение на гласную букву первого слога, получается совсем другое слово, не относящееся ни как к средству передвижения.
Из этих слов можно составить предложение:
Как видно это два разных слова. Ну а если поставим ударение на последний слог, то получится вовсе бессмыслица.
А гласные буквы, на которые не падает ударение, называются безударными.
Теперь потренируйтесь, вместе с ребенком, правильно ставить ударение в словах:
Морозы, пенёк, крыжовник.
Получается, что роль ударения в произношении слов очень важна, а в дальнейшем мы узнаем, что с помощью ударения мы можем узнать, как правильно писать безударные гласные в словах.
При написании слов мы сталкиваемся с тем, что иногда слово полностью не помещается в строке. Тогда это слово можно перенести на другую строку. Как же это сделать? Очень просто: надо разбить слово на слоги и перенести.
Например, слово карандаш можно перенести так:
ка-
ран-
даш
Просто? Но есть несколько правил, которыми нельзя пренебрегать:
- Одну букву нельзя оставлять на строке. Например, слово иней не переносится.
- Слово, состоящее из одного слога, не переносится. Например: труд .
- Одну букву слова нельзя оставлять на предыдущей строке. Также нельзя одну букву переносить на следующую строку. Например, слова аист и идея не переносятся.
- Нельзя оставлять на предыдущей строке или переносить на следующую одну согласную без гласной. Например, слово круглый можно перенести так круг-лый. Неправильно перенести так: к-руглый или кр-углый.

- Буквы й, ы, ъ, ь нельзя отделять от предшествующей буквы: вой-на, подъ-езд, рай-он.
Есть еще несколько правил переноса, но их мы будем изучать по мере усваивания дальнейшего материала.
Спасибо, что Вы с нами.
Понравилась статья – поделитесь с друзьями:
Оставляйте пожалуйста комментарии в форме ниже
Карточки .Деление слов на слоги. Перенос слов.
1.Спиши. Раздели слова на слоги.
В лесу рос красивый куст. Куст цвёл яркими цветами. Это был шиповник. Хороши душистые розы. Стала Ася рвать розы. А там шипы. У Аси заноза.
На дереве лежит большая рыжая кошка. У кошки зелёные глаза и пушистые кисточки на ушах. Сильные лапы зверя впились в ствол. Это рысь.
2.Перепиши, разделяя слова на слоги для переноса.
Школа, дружба, читайте, ручейки, улица, девочка, муравей, слушайте, птичка, принесла, клетка, комната, растение, окно, заяц, узоры, Яблоко, урожай, увидели.
3.Подчеркни слова, которые нельзя перенести.
Якорь, книга, слои, кошка, майка, узор, аист, зверь, тетрадь, яма, чиж, Учитель, ложка, ежи, вилка, ёлочка, карандаш, май, усы, слой, азбука, чайка, мост, цветы, юла, океан, Оля, куст, Алёна, поезда, пост, Ирина, лей, Юля, мяч, Игорь, луч, Евгений, Яша, чай, Арина, брат, слойка, лейка, мёд, олень, ёжик, Юра, отец.
4.Раздели слоги для переноса всеми возможными способами.
Ягода _____________________________________________________
Осёл ____________________________________________________
Язык
___________________________________________________
Пою ______________________________________________________
Олег
______________________________________________________
Ужин
_______________________________________________________
Карандаш
_______________________________________________________
Лакомились
______________________________________________________
Края
_______________________________________________________
Уполз
_______________________________________________________
Арбузы
______________________________________________________
Лужайка
_______________________________________________________
Чайники
_______________________________________________________
Заморозки
5. «Свари кушу» из слов, которые можно разделить на слоги для переноса. Раздели слова на слоги для переноса всеми возможными способами.
«Свари кушу» из слов, которые можно разделить на слоги для переноса. Раздели слова на слоги для переноса всеми возможными способами.
Ячмень, овёс, рожь, кукуруза, горох, пшеница, гречиха.
6. Измени слова так, чтобы их можно было перенести.
Дуб___________________________________________________________
Лист _________________________________________________________
Гриб___________________________________________________________
Крот___________________________________________________________
Мышь__________________________________________________________
Конь___________________________________________________________
Куст_____________________________________________________________
Мак_______________________________________________________________
7. В каждом слове найди лишний слог. Из получившихся слогов составь слово. Раздели слова на слоги для переноса всеми возможными способами.
Стаукан, саморолёт, узокиры.
___________________________________________________________________
Как читать русские слова. Стресс по-русски. Омографы.
Загружается…
Загружается…
Загружается…
Количество слов в нашем словаре русского произношения
| Майк | 20 000 слов |
| Майк | |
| Лела | 10 000 слов |
| Лела | |
| Дживин | 3700 слов |
| Дживин Дживин | |
| Андрей | 9400 слов |
| Эндрю | |
| Кристин | 37 600 слов |
| Кристин | |
| Чарльз | 2500 слов |
| Чарльз Чарльз | |
| Адриан | 10 000 слов |
| Адриан | |
| Карен | 10 000 слов |
| Карен | |
| Кили | 14 000 слов |
| Кили | |
| Хунмэй | 14 000 слов |
| Хунмэй | |
| Тимур | 3200 слов |
| Тимур Тимур | |
Варианты подписки
Вы изучаете или преподаете русский язык?
Мы знаем, что иногда русский язык может показаться сложным. Мы не хотим, чтобы вы тратили свое время.
Мы не хотим, чтобы вы тратили свое время.
Проверьте все наши инструменты и быстрее изучайте русский язык!
вставка фонетической транскрипции в субтитры
Привет от разработчика Тимур
Узнайте, как активировать свой мозг и учиться быстрее (4 мин.)
Ваш браузер не поддерживает видео HTML5!
Тимур Байтукалов. Полное руководство по изучению языка. Часть 1: Изучение произношения
Бесплатный вебинар «Фонетическая транскрипция для быстрого изучения языка» (20 мин.)
Ваш браузер не поддерживает аудио HTML5!
Обучение Русское произношение может быть сложным для людей, которые только начинают учиться Русский . Как вы, возможно, знаете, русские гласные произносятся по-разному в зависимости от того, являются ли они ударными или безударными .
В отличие от некоторых других языков, русский не имеет строгих правил для положения ударения. Ударение может падать на любой слог слова (в отличие, например, от французского, где ударение почти всегда падает на последний слог). Модели стресса практически невозможно предсказать, особенно для тех, кто только начал изучать русский язык.
Ударение может падать на любой слог слова (в отличие, например, от французского, где ударение почти всегда падает на последний слог). Модели стресса практически невозможно предсказать, особенно для тех, кто только начал изучать русский язык.
Этот онлайн-инструмент автоматически вставляет знаки ударения в русские слова
и восстанавливает букву «ё» в русском тексте. Это сэкономит вам много времени — вам больше не нужно искать положение ударения в словаре.Некоторые русских слов с одинаковым написанием могут иметь разное значение в зависимости от расстановки ударения. Сравните:
- замо́к (замок) ↔ за́мок (замок)
- больша́я (большая) ↔ бо́льшая (большая)
Эти слова называются омографами . Инструмент покажет вам все возможные позиции ударения в таких словах. Словарь содержит 23 376 омографов (16 609 уникальных вариантов написания).
В русском языке также есть группа слов, которые можно рассматривать как «фальшивые» омографы — слова с буквой «ё», которые становятся омографами при написании с буквой «е». Например, если «берёг» пишется с буквой «е», оно может произноситься как «бе́рег» (берег) или как «берёг» (заботился). Этот онлайн-инструмент покажет обе позиции ударения в этих словах. Дополнительные примеры приведены ниже:
Например, если «берёг» пишется с буквой «е», оно может произноситься как «бе́рег» (берег) или как «берёг» (заботился). Этот онлайн-инструмент покажет обе позиции ударения в этих словах. Дополнительные примеры приведены ниже:
- колеса́ (колесо, родительный падеж ) ↔ колёса (колеса)
- о́зера (озеро, родительный падеж ) ↔ озёра (озёра)
В русском языке есть ещё одна группа слов, которые могут писаться как с буквой «ё», так и с буквой «е». Положение ударения в обоих словах одинаковое, но смысл разный. Например:
- все́ (все) ↔ всё (все)
- небо (небо) ↔ нёбо (нёбо)
- Словарь фонетики и произношения
- Международный фонетический алфавит для русского языка — Таблица IPA
- Инструмент русского произношения – переводчик фонетической транскрипции
- Русские словари онлайн – Project Modelino
- PHP-yoficator – программа, восстанавливающая букву «ё» в русских словах.

- Русский алфавит – Википедия
- Фонология русского языка – Википедия
- Омограф — Википедия
- Гетероним — Википедия
Обновления в инструменте для расстановки ударений в русские слова
Внесены некоторые улучшения в инструмент для расстановки ударений в русские слова. Главное – возможность восстановить букву “ё” в русских словах….
21 декабря 2013 г.
Русский язык, фонетика русского языка, русское произношение, МФА, таблица МФА, переводчик МФА, словарь, изучение языка, фонетический словарь, фонетическая транскрипция, ударение
Переводчик фонетической транскрипции и словарь произношения
Мы поможем вам сэкономить время при изучении языка
Ваши настройки сохранены!
Автоматическое определение словесного ударения на русском языке
1 Введение
В последнее время большое внимание уделяется моделям уровней персонажей и встраиваниям персонажей.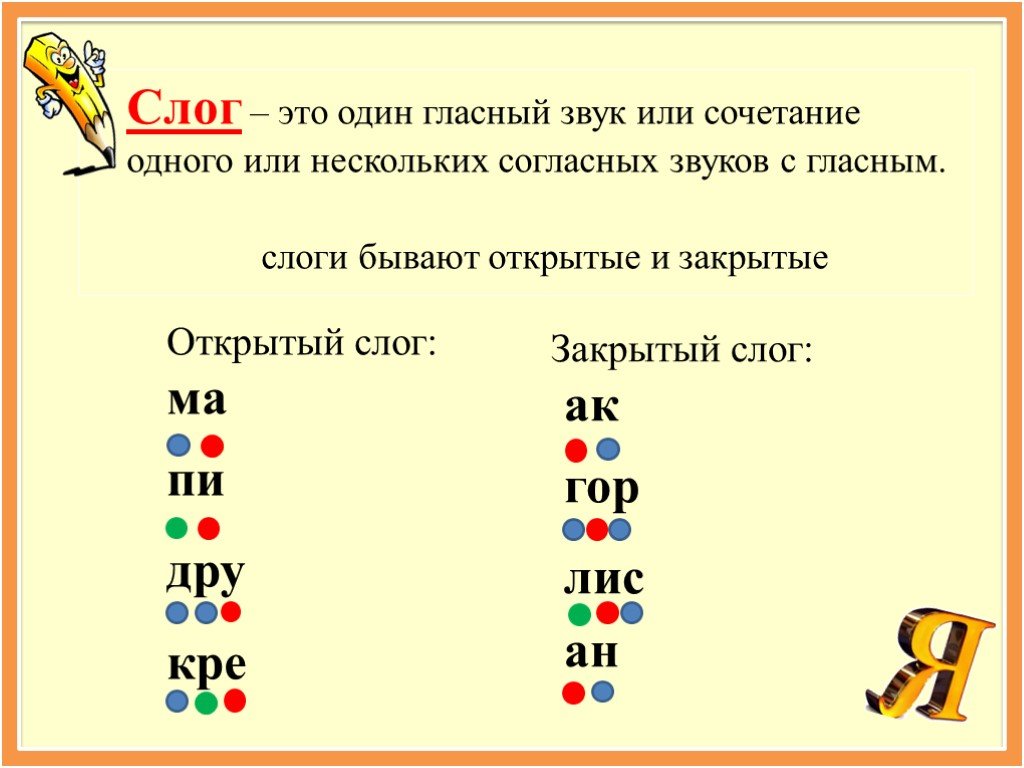
В этом исследовании мы сосредоточимся на менее известной проблеме, которая, насколько нам известно, еще не решена полностью, а именно на автоматическом обнаружении словесного ударения. Для некоторых языков, например. В России эта проблема может иметь решающее значение для обработки и генерации речи.
Лишь немногие авторы затрагивают проблему автоматического определения словесного ударения в русском языке. Среди них стоит особо отметить один исследовательский проект (Hall and Sproat, 2013) . Авторы ограничили задачу обнаружения стресса поиском правильного порядка в массиве предположений о стрессе, где допустимые модели стресса были ближе к началу списка, чем недействительные. Тогда первое предположение о напряжениях в перестроенном списке считалось правильным. Для решения этой проблемы авторы использовали метод максимального энтропийного ранжирования (Collins and Koo, 2005) и в качестве признаков взяли символьные би- и триграммы, суффиксы и префиксы ранжированных слов, а также суффиксы и префиксы, представленные в «абстрактной» форме. где большинство гласных и согласных были заменены ярлыками их фонетических классов. В исследовании представлены результаты, полученные с использованием корпуса словоформ русского языка, сформированного на основе Словаря Зализняка (около 2 млн словоформ). Тестирование модели на случайно разделенном поезде и тестовых выборках показало точность 0,9.87. По словам авторов, они наблюдали такую высокую точность, потому что случайное разделение выборки во время тестирования помогло алгоритму извлечь выгоду из лексической информации, т. е. разные словоформы одного и того же лексического элемента часто имеют одну и ту же позицию ударения.
Тогда первое предположение о напряжениях в перестроенном списке считалось правильным. Для решения этой проблемы авторы использовали метод максимального энтропийного ранжирования (Collins and Koo, 2005) и в качестве признаков взяли символьные би- и триграммы, суффиксы и префиксы ранжированных слов, а также суффиксы и префиксы, представленные в «абстрактной» форме. где большинство гласных и согласных были заменены ярлыками их фонетических классов. В исследовании представлены результаты, полученные с использованием корпуса словоформ русского языка, сформированного на основе Словаря Зализняка (около 2 млн словоформ). Тестирование модели на случайно разделенном поезде и тестовых выборках показало точность 0,9.87. По словам авторов, они наблюдали такую высокую точность, потому что случайное разделение выборки во время тестирования помогло алгоритму извлечь выгоду из лексической информации, т. е. разные словоформы одного и того же лексического элемента часто имеют одну и ту же позицию ударения. Затем авторы попытались решить более сложную задачу и протестировали свое решение на небольшом количестве словоформ, для которых парадигмы не были включены в обучающую выборку. В результате была достигнута точность 0,839. Предложенная авторами методика оценки весьма далека от практического применения, что является основным недостатком их исследования. Обычно решения в области автоматизированного определения ударения применяются к реальным текстам, где частотное распределение словоформ резко отличается от такового в наборе слов, полученном при «разворачивании» всех элементов словаря.
Затем авторы попытались решить более сложную задачу и протестировали свое решение на небольшом количестве словоформ, для которых парадигмы не были включены в обучающую выборку. В результате была достигнута точность 0,839. Предложенная авторами методика оценки весьма далека от практического применения, что является основным недостатком их исследования. Обычно решения в области автоматизированного определения ударения применяются к реальным текстам, где частотное распределение словоформ резко отличается от такового в наборе слов, полученном при «разворачивании» всех элементов словаря.
Кроме того, в другом исследовании (Reynolds and Tyers, 2015)
описывается основанный на правилах метод автоматического обнаружения стресса без помощи машинного обучения. Авторы предложили систему конечных автоматов, имитирующих правила ударения в русском языке и формальную грамматику, которая частично устраняла неоднозначность ударения за счет применения синтаксических ограничений. Таким образом, используя все вышеупомянутые решения вместе с информацией о частоте словоформ, авторы добились точности 0,9.62 на относительно небольшом помеченном вручную корпусе на русском языке (7689 токенов), который не оказался общедоступным. Предлагаемый метод можно рассматривать как базовый для решения задачи автоматизированного определения словесного ударения в русском языке.
Таким образом, используя все вышеупомянутые решения вместе с информацией о частоте словоформ, авторы добились точности 0,9.62 на относительно небольшом помеченном вручную корпусе на русском языке (7689 токенов), который не оказался общедоступным. Предлагаемый метод можно рассматривать как базовый для решения задачи автоматизированного определения словесного ударения в русском языке.
Во многих языках, таких как французский, чешский, финский и немецкий, правила автоматического определения словесного ударения могут быть формализованы довольно легко. Тем не менее, есть языки, в которых фонологические характеристики не предсказывают положение ударения, например, такие просодические системы слов можно найти в северо-западных кавказских (абхазских) и прибалтийско-славянских языках (литовский, сербско-хорватский, русский) (ван дер Халст, 1999 г.) .
В русском языке каждое слово имеет один и только один ударный слог. Лексическое ударение свободно в своем расположении (ударение может ставиться на любой слог, как показано в (1)) и подвижно (для многих лексем лексическое ударение зависит от словоформы, как показано в (2)).
эта [This-Sg.F.Nom] нейросет [сеть-Gg.Nom] будет [be-3Sg.Fut] расставить [put-Inf] ударения [stress-Pl.Acc] в [in] словах [слово-Pl.Loc] русский [русский-Sg.M.Gen] язика [язык-Sg.Gen]
dérevo [tree-Sg.Nom] derevya [tree-Pl.Nom]
Лексическое ударение может иметь решающее значение при устранении неоднозначности между омографами, как между двумя словоформами ((3)), так и между двумя лексемами ((4)):
rukí [ручной-сержант] ruki [ручной-Pl.Nom]
берег [берег реки-Sg.Dat] берег [защита-1Sg.Pres]
Положение лексического ударения в русском языке зависит от многих факторов, в том числе от морфологического содержания слова, а также от типа словообразования, его частоты и значения. В фундаментальных исследованиях разработана сложная система маркеров, которые определены для всех морфем (Зализняк, 1985) . Есть правила, определяющие иерархию и взаимодействие маркеров, но некоторые из них не являются строгими и могут считаться скорее тенденцией.
Для практических целей может подойти словарный подход к акцентуации текста. Можно представить себе систему, которая находит акцентированную форму для каждой лексемы, используя некоторый заранее определенный список. Однако у такой системы было бы несколько недостатков, наиболее важным из которых была бы ее неспособность предсказать ударение для неизвестных слов.
В этой статье мы предлагаем формальный подход к проблеме автоматической акцентуации русского текста, пытаясь использовать для этих целей нейронные модели персонажей. Кроме того, мы стараемся избегать использования каких-либо дополнительных или сторонних инструментов для маркировки частей речи и пытаемся разработать упрощенный подход, основанный только на использовании обучающих данных.
2 набора данных
Мы рассмотрели два набора данных:
Словарь русской грамматики Зализняка, в котором содержится более 100 000 лексем (Зализняк, 1985) . Каждая лексема и ее словоформы имеют ударение.
 Словарь был разделен на обучающий и тестовый наборы данных в соотношении 2:1, так что все формы одной лексемы принадлежат либо поезду, либо тестовому набору данных, и ни одна лексема не принадлежит обоим. Мы присвоили имя Dictionary Model (DictM) RNN, обученной на этом наборе данных.
Словарь был разделен на обучающий и тестовый наборы данных в соотношении 2:1, так что все формы одной лексемы принадлежат либо поезду, либо тестовому набору данных, и ни одна лексема не принадлежит обоим. Мы присвоили имя Dictionary Model (DictM) RNN, обученной на этом наборе данных.Транскрипции из речевого подкорпуса 1 1 1 Словесное ударение в базе данных разговорных текстов Национального корпуса русского языка. /search-spoken.html Национального корпуса русского языка (РНК) (Гришина, 2003) . Разговорный корпус был собран путем записи разговоров людей в разных ситуациях, после чего он был расшифрован и аннотирован словесным ударением, также были включены стенограммы русских фильмов. Основное отличие этих транскрипций от Словаря Зализняка состоит в том, что транскрипция обычно не содержит всех форм слова и, что более важно, содержит контексты слов, т.е. предшествующие слова. Принимая во внимание контекст, мы можем попытаться различать такие падежи, как «óblaka» [cloud-Sg.
 Gen] и «oblaka» [cloud-Pl.Nom], поскольку предыдущее слово в большинстве случаев покажет, является ли слово единственным. или множественное число. Этот набор данных был разделен на обучающие и тестовые наборы данных с использованием того же соотношения 2:1.
Мы обучили две модели на корпусе. Назовем первую RNN контекстно-зависимой моделью (CDM). Для того чтобы учесть предыдущее слово, мы использовали следующий алгоритм: если в предыдущем слове меньше трех букв, мы снимаем с него словесное ударение и соединяем его с текущим словом (например, «те_облака» [тот-мн.ч. облако-Pl.Nom]). Если предыдущее слово состоит из 3 и более букв, мы используем последние три, так как русские окончания обычно состоят из 2-3 букв, а словообразовательные морфемы обычно располагаются на правой периферии слова. Таким образом, мы получаем, например, «ogo_óblaka» [Sg.N.Gen cloud-Sg.Gen] от «belogo_óblaka» [белый-Sg.N.Gen cloud-Sg.Gen]. Вторая модель (Context Free Model, CFM) имеет ту же архитектуру, но не учитывает контекст.
Gen] и «oblaka» [cloud-Pl.Nom], поскольку предыдущее слово в большинстве случаев покажет, является ли слово единственным. или множественное число. Этот набор данных был разделен на обучающие и тестовые наборы данных с использованием того же соотношения 2:1.
Мы обучили две модели на корпусе. Назовем первую RNN контекстно-зависимой моделью (CDM). Для того чтобы учесть предыдущее слово, мы использовали следующий алгоритм: если в предыдущем слове меньше трех букв, мы снимаем с него словесное ударение и соединяем его с текущим словом (например, «те_облака» [тот-мн.ч. облако-Pl.Nom]). Если предыдущее слово состоит из 3 и более букв, мы используем последние три, так как русские окончания обычно состоят из 2-3 букв, а словообразовательные морфемы обычно располагаются на правой периферии слова. Таким образом, мы получаем, например, «ogo_óblaka» [Sg.N.Gen cloud-Sg.Gen] от «belogo_óblaka» [белый-Sg.N.Gen cloud-Sg.Gen]. Вторая модель (Context Free Model, CFM) имеет ту же архитектуру, но не учитывает контекст.
3 Архитектура
Мы приняли архитектуру уровня персонажа из стандартных руководств по платформе Keras
2 2 2http://keras.io
. Наша нейронная сеть представляет собой двунаправленную рекуррентную нейронную сеть с 64 узлами LSTM и регуляризацией отсева. Каждое входное слово представлено матрицей 40 на 33, где 40 означает максимальную наблюдаемую длину слова в символах. Более короткие слова дополняются символом заполнения. 33 — это количество букв в русском алфавите, и каждая буква в слове кодируется однократными кодировками.
Ударение можно считать характеристикой гласного, имеющей два возможных значения. Слог в русском языке имеет структуру (C)V(C), поэтому количество гласных равно количеству слогов, и в каждом слове ударение будет только на одну гласную. Словесное ударение также кодируется с помощью горячего кодирования и показывает, какая из 40 букв аннотируется словесным ударением. Выходной слой RNN снова имеет 40 узлов и активируется softmax. Для оценки качества определения словесного ударения мы использовали точность.
Выходной слой RNN снова имеет 40 узлов и активируется softmax. Для оценки качества определения словесного ударения мы использовали точность.
4 Результаты и обсуждение
При тестировании 3 3 3Нашу реализацию метода можно найти здесь: http://github.com/MashaPo/accent_lstm тестовый набор данных. Мы обучили DictM на 10 эпохах и получили наилучшие результаты на четвертой эпохе с точностью 88,7% для тестового набора из словаря. Оценку можно сравнить с результатами второго эксперимента в
(Hall and Sproat, 2013) и доказывает, что RNN столь же эффективен, как и ранжирование максимальной энтропии для этой задачи.
Второй набор данных был немного больше и содержал 2 306 776 уникальных экземпляров поезда и 1 154 067 уникальных тестовых экземпляров. Мы использовали этот набор данных для обучения CDM и CFM в течение 10 эпох. CDM добился наилучших результатов в течение пятой эпохи с точностью 97,7% для всех слов. CFM показал наивысшую точность 97,9% в течение шестой эпохи.
CFM показал наивысшую точность 97,9% в течение шестой эпохи.
Существенная разница между этими значениями показывает, что учет предыдущего контекста повышает точность, хотя с помощью корпуса мы могли бы проигнорировать некоторые сложные падежи, которые не имеют широкого употребления в реальной речи, но присутствуют в словаре Зализняка и увеличивают вес большинства частые слова, которые не обязательно имеют общий тип размещения ударения. Здесь мы имеем в виду числительные и частые наречия, которые имеют свой особый тип размещения ударения. Из-за своей частоты такие случаи негативно влияли на точность DictM.
Мы реализовали следующий метод для сравнения RNN. Мы использовали эти три модели для определения словесного ударения в тестовом наборе корпуса. Затем мы подсчитали количество правильных предсказаний для слов разной длины и рассчитали микросреднее значение точности для каждой модели. Стоит отметить, что значение точности для DictM снизилось по сравнению с оценкой, полученной из набора тестов словаря (88,7% для набора тестов словаря и 75,1% для набора тестов корпуса). Результаты для DictM, CFM, CDM представлены в таблицах 1, 2 и 3 соответственно.
Результаты для DictM, CFM, CDM представлены в таблицах 1, 2 и 3 соответственно.
| Количество слогов | Правильные определения, % | Правильное обнаружение |
| 2 | 0,690 | 182 285 из 263 952 |
| 3 | 0,721 | 127 012 из 176 144 |
| 4 | 0,846 | 85 675 из 101 229 |
| 5 | 0,918 | 42 124 из 45 879 |
| 6 | 0,952 | 15 241 из 16 009 |
| 7 | 0,958 | 3 813 из 3 979 |
| 8 | 0,96 | 744 из 775 |
| 9 | 0,928 | 156 из 168 |
| Микросреднее | 0,751 | |
| Количество слогов | Правильные определения, % | Правильное обнаружение |
| 2 | 0,981 | 259 179 из 263 952 |
| 3 | 0,974 | 171 645 из 176 144 |
| 4 | 0,975 | 98 707 из 101 229 |
| 5 | 0,975 | 44 774 из 45 879 |
| 6 | 0,972 | 15 567 из 16 009 |
| 7 | 0,950 | 3 782 из 3 979 |
| 8 | 0,940 | 729 из 775 |
| 9 | 0,934 | 157 из 168 |
| Микросреднее | 0,977 | |
| Количество слогов | Правильные определения, % | Правильное обнаружение |
| 2 | 0,983 | 259 656 из 263 952 |
| 3 | 0,977 | 172 164 из 176 144 |
| 4 | 0,976 | 98 887 из 101 229 |
| 5 | 0,977 | 44 837 из 45 879 |
| 6 | 0,973 | 15 591 из 16 009 |
| 7 | 0,955 | 3 802 из 3 979 |
| 8 | 0,923 | 716 из 775 |
| 9 | 0,952 | 160 из 168 |
| Микросреднее | 0,979 | |
| Количество слогов | Правильные определения, % | Правильное обнаружение |
| 2 | 0,756 | 17 852 из 23 606 |
| 3 | 0,829 | 5 402 из 6 510 |
| 4 | 0,823 | 1 011 из 1 227 |
| Микросреднее | 0,77 | |
| Количество слогов | Правильные определения, % | Правильное обнаружение |
| 2 | 0,810 | 19 143 из 23 606 |
| 3 | 0,844 | 5 498 из 6 510 |
| 4 | 0,847 | 1 040 из 1 227 |
| Микросреднее | 0,819 | |
 Для DictM существует четкая положительная корреляция между количеством слов и точностью прогнозов, DictM дает лучшие результаты, чем CDM на 8- и 9-м-сложные слова, которые в корпусе встречаются редко и могут быть «новыми» для CFM и CDM, тогда как DictM мог бы «усвоить» всю парадигму. CFM и DFM показывают отрицательную корреляцию между точностью и количеством слогов, что ожидается из-за более низкой частоты более длинных слов.
Для DictM существует четкая положительная корреляция между количеством слов и точностью прогнозов, DictM дает лучшие результаты, чем CDM на 8- и 9-м-сложные слова, которые в корпусе встречаются редко и могут быть «новыми» для CFM и CDM, тогда как DictM мог бы «усвоить» всю парадигму. CFM и DFM показывают отрицательную корреляцию между точностью и количеством слогов, что ожидается из-за более низкой частоты более длинных слов.Затем результаты CDM ясно демонстрируют преимущества обучения RNN с учетом предыдущего слова, поскольку это увеличивает количество правильно обнаруженных словесных ударений, включая случаи омографа. Подобный способ тестирования модели делает наши результаты сопоставимыми с результатами, полученными в (Reynolds and Tyers, 2015) , наша независимая от контекста модель и модель, зависящая от контекста, показали более высокое микросреднее значение точности, чем базовый уровень.
Чтобы показать, что CDM более точен, чем CFM из-за устранения неоднозначности омографов, мы провели дополнительные тесты, чтобы узнать, как обе модели обрабатывают омографы. Точнее, мы извлекли из словаря наборы слов, различающихся только позицией ударения («дорогой» [дорогой-M.Sg.Nom] «дорогой» [дорогой-Sg.Instr] ). Далее подбирались такие пары омографов, чтобы для обоих слов количество вхождений в корпус было выше заданного порога. В таблицах 4 и 5 показаны результаты тестирования CFM и CDM на 50 наиболее часто встречающихся парах.
Более подробные результаты для четырех пар омографов показаны в Таблице 6. Данные ясно показывают, что CFM просто выбирает наиболее часто встречающееся слово в паре омографов. хотя CDM допускает ошибки при анализе более часто встречающихся слов в паре, он значительно повышает точность менее часто встречающихся слов. Общая точность для случаев, когда частота омографов сопоставима (строки 1, 2 и 4 таблицы), для CDM заметно выше, чем для CFM.
Точнее, мы извлекли из словаря наборы слов, различающихся только позицией ударения («дорогой» [дорогой-M.Sg.Nom] «дорогой» [дорогой-Sg.Instr] ). Далее подбирались такие пары омографов, чтобы для обоих слов количество вхождений в корпус было выше заданного порога. В таблицах 4 и 5 показаны результаты тестирования CFM и CDM на 50 наиболее часто встречающихся парах.
Более подробные результаты для четырех пар омографов показаны в Таблице 6. Данные ясно показывают, что CFM просто выбирает наиболее часто встречающееся слово в паре омографов. хотя CDM допускает ошибки при анализе более часто встречающихся слов в паре, он значительно повышает точность менее часто встречающихся слов. Общая точность для случаев, когда частота омографов сопоставима (строки 1, 2 и 4 таблицы), для CDM заметно выше, чем для CFM.
Мы также провели анализ ошибок. Прежде всего, огромным источником ошибок являются имена собственные как имена, так и фамилии. Несколько типичных русских фамилий образованы от существительных или прилагательных и отличаются от других словоформ только ударением. Мы можем решить эту проблему, используя алгоритмы NER и вводя специальные правила для имен собственных. Другой вид ошибок связан со словами с неоднозначным словесным ударением. Например, в словах типа «мусоропровод» [garbage.chute-Sg.Nom] в современном русском языке возможны два словесных ударения: мусоропровод или мусоропровод. И последнее, но не менее важное: в русском языке буква ë всегда ставится под ударением, но если эта буква пишется как обычная e, RNN может ошибочно ее проигнорировать.
Мы можем решить эту проблему, используя алгоритмы NER и вводя специальные правила для имен собственных. Другой вид ошибок связан со словами с неоднозначным словесным ударением. Например, в словах типа «мусоропровод» [garbage.chute-Sg.Nom] в современном русском языке возможны два словесных ударения: мусоропровод или мусоропровод. И последнее, но не менее важное: в русском языке буква ë всегда ставится под ударением, но если эта буква пишется как обычная e, RNN может ошибочно ее проигнорировать.
5 Будущая работа
Есть несколько направлений для дальнейшей работы:
улучшает то, как мы учитываем контекст слова. Мы можем использовать более изощренные методы, чтобы определить окончание и морфологические особенности предыдущего слова. Мы также можем исследовать, как рассмотрение следующего слова улучшает производительность.
введение правил для именованных объектов вообще и имен собственных в частности;
экспериментирует с уменьшением количества экземпляров в наборе данных поезда, чтобы сократить время обучения и найти конкретные важные примеры для обучения;
тщательно экспериментировать с RNN, чтобы получить больше лингвистической интуиции о том, как выбирается словесное ударение.