Язык по слогам: Слоги в слове язык
Как перенести слово “язык”?
Слово «язык» не подлежит переносу с одной строки на другую в соответствии с правилом орфографии.
Прежде чем выполнить перенос слова «язык«, установим в нем количество гласных звуков, которые являются слогообразующими.
Деление на слоги слова «язык»
Чтобы перенести слово «язык» с одной строки на другую, разделим его на слоги. В словах русского языка гласный звук самостоятельно или в сочетании с одним или несколькими согласными организует фонетический слог. Посмотрим, как правильно разделить на слоги слова:
- о-бод
- у-че-ник
- ка-ра-вай
Большинство слогов являются открытыми, так как их составляют гласные в одиночку или гласные с согласными. Закрытые слоги образуют все шумные согласные в конце слов. Сонорные согласные (й, л, м, н, р) могут закрыть слог как в конце, так и в середине слов:
- кор-ка
- бан-ка
- ба-ла-лай-ка
- у-кром-ный
Вспомнив особенности слогоделения, выясним, сколько слогов содержит слово «язык».
Это существительное состоит из двух слогов в соответствии с наличием в нем двух гласных звуков:
я-зык.
Первый открытый слог обозначен буквой «я». Второй слог закрывает согласный, обозначенный буквой «к».
Перенос слова «язык»
Это двусложное слово может оказаться в конце строки, на которой оно не помещается целиком. Тогда возникает необходимость перенести его по слогам с одной строки на другую. Учтем, что это существительное является примером того, что фонетическое деление на слоги и орфографический перенос слов иногда не совпадают.
В грамматике русского языка не всегда перенос слова можно осуществить по его слогоделению. Это существительное нельзя перенести по слогам в соответствии с правилом переноса слов.
В русском языке одну гласную, даже слогообразующую, не переносят на другую строку, поэтому все слово пишем целиком на одной строке.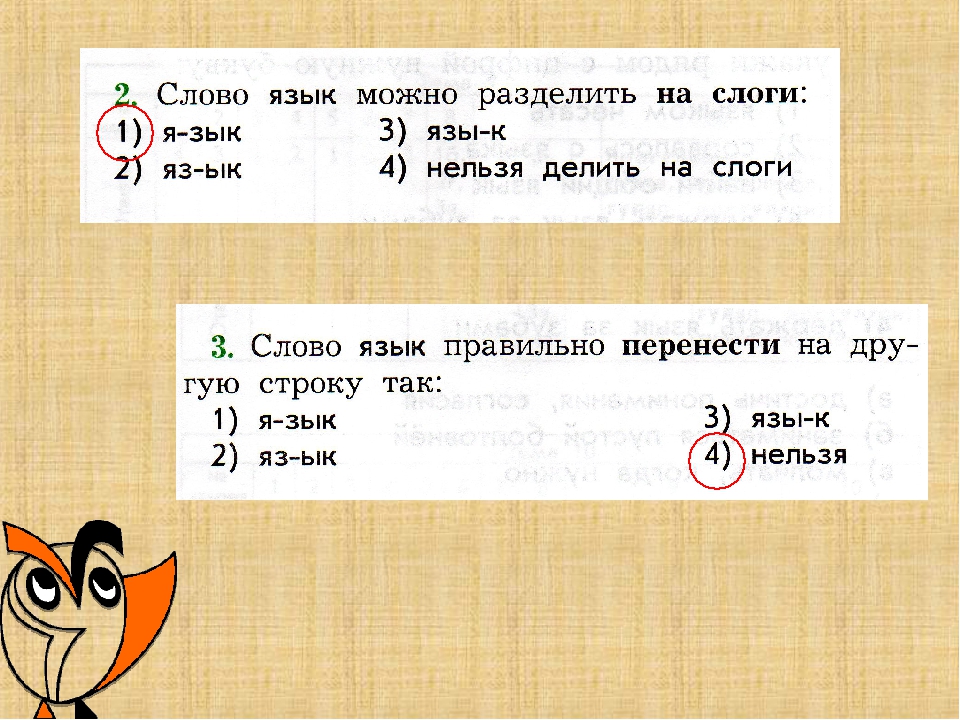
Слово «язык» нельзя перенести по слогам с одной строки на другую.
Аналогично не переносятся по слогам двусложные слова:
- о-лень
- о-сень
- я-ма
- е-нот
- ю-ла
- о-крик.
- о-дин
- у-ход
- я-корь
- и-меть
- тво-и.
В них гласный звук образует самостоятельный фонетический слог. Эти слова также пишутся целиком на предыдущей или следующей строке.
Скачать статью: PDFПравила переноса слов в русском языке
Основные правила переноса слов:
1. Слова переносят по слогам
Лам-па, сест-ра
2. Одну букву нельзя оставлять на строке и нельзя переносить на другую строку
Яма, ар-мия, Юлия
3. Буквы й, ъ, ь не отделяют от впереди стоящей буквы
Лай-ка, паль-то, се-мья, объ-езд
4. В словах с двойными согласными одну букву оставляют на строку, вторую переносят на другу строку
В словах с двойными согласными одну букву оставляют на строку, вторую переносят на другу строку
Ан-на, суб-бота
5. При переносе нельзя отрывать от приставки одну букву
Под-бросить, под-писать
6. Нельзя отрывать первую букву от корня
По-строить, при-учить, со-брать
Что ещё почитать?
Помимо основных правил существуют также исключения и уточнения. Разберём принципы словарного переноса с поясняющими примерами.
Нельзя оставлять ни в конце слова, ни в виде переноса на другую строку:
Верно: одеж-да
Неверно: о-дежда
- часть слова, не составляющую слога
Верно: про-смотр
Неверно: просмо-тр
- согласную, отрывая её от следующей за ней гласной
Верно: клено-вый, кле-новый
Неверно: клен-овый
- согласную в конце приставки, если за ней следует согласная
Верно: под-бегать
Неверно: по-дбегать
- начальную корневую часть, не составляющую слога
Верно: при-крыть
Неверно: прик-рыть
- начальную часть второй основы сложного слова
Верно: девяти-граммовый
Неверно: девятиг-раммовый
- две одинаковые согласные, находящиеся между гласными (кроме начальных двойных согласных корня: по-ссорить)
Верно: пожу-жжать
Неверно: пожуж-жать
- разбивать переносом односложную часть сложносокращённого слова
Верно: спец-служба
Неверно: спе-цслужба
- отделять Й, Ь, Ъ от предшествующих им букв
Верно: бой-ница
Неверно: бо-йница
- переносить часть слова, начинающуюся с Ы
Верно: ра-зыграть
Неверно: раз-ыграть
Русский язык. 2 класс. Учебник в 2-х частях. Ч. 1
2 класс. Учебник в 2-х частях. Ч. 1
В комплексе с учебником издаются: «Тетрадь для упражнений по русскому языку и речи» для учащихся, методическое пособие для учителя и справочник «Русский язык. 1-4 классы». Учебник соответствует Федеральному государственному образовательному стандарту начального общего образования.
МХАТ, МГОУ, ФИПС, СССР, ГОСТ, КЗоТ;
и т.д., и т.п., т.е., и пр.;
-
употребления сокращённых обозначений мер и числовых значений данных мер: 8 л, 10 кг, 100 м².
В помощь учителю для составления плана урока по теме «Правила переноса слов в русском языке» нами подобраны конспекты:
Планы урока являются частью сервиса «Классная работа», где с ними можно ознакомиться бесплатно онлайн.
#ADVERTISING_INSERT#
Звуки и слоги – Русский язык
Все традиции так или иначе описывали звуковой строй языка.
Нам кажется естественным и единственно возможным то представление, которое отражено в письменности родного языка и закреплено школьным обучением. Первичная единица — звук (или, точнее, фонема). Звуку в общем соответствует буква алфавита. Звуки группируются в слоги. Границы слогов не всегда ясны в отличие от границ звуков. Звуков всего несколько десятков, и их можно сосчитать. Слогов много, а количество слогов, например, в современном русском языке вряд ли может кто-либо точно назвать. Отметим, что в европейской традиции, начиная с античных руководств по стихосложению, выделяется ещё одна единица, именуемая м 6р о и, — промежуточная между звуком и слогом.

Представление о слоге как о единице, производной по отношению к звуку, вполне годится для русского языка, латыни или санскрита. В этих языках сочетаемость звуков между собой довольно свободна, а структура слога может быть очень сложной. Например, в русском языке вполне нормально сочетание четырёх согласных подряд: встреча, всхлип. Слово может состоять из любого количества слогов и звуков. Поэтому и индийская, и европейская традиции исходят из первичности звука.
Несколько по-иному рассуждают арабы. В арабском языке есть особенность, непривычная для нас. Арабский корень обычно состоит из трёх (изредка двух) согласных, разделённых гласными. Эти гласные изменяют грамматическое значение слова, выполняя ту же роль, что и окончания в русском языке.
 Таким образом, гласные передают грамматическое, а согласные — лексическое значение слова. Отсюда особенности арабской письменности и арабской традиции. Там тоже исходная единица — звук, но в качестве звуков рассматривают лишь согласные (а также долгие гласные, которые постоянно входят в состав корня), эти звуки обозначают буквами. Краткие гласные, напротив, рассматривают не как отдельные сущности, а как характеристику, присущую слогу или же слову в целом (примерно так же мы воспринимаем ударение). В арабском языке от согласного переходят прямо к слогу, а гласный отдельно не выделяют. На письме краткие гласные не обозначают вообще.
Таким образом, гласные передают грамматическое, а согласные — лексическое значение слова. Отсюда особенности арабской письменности и арабской традиции. Там тоже исходная единица — звук, но в качестве звуков рассматривают лишь согласные (а также долгие гласные, которые постоянно входят в состав корня), эти звуки обозначают буквами. Краткие гласные, напротив, рассматривают не как отдельные сущности, а как характеристику, присущую слогу или же слову в целом (примерно так же мы воспринимаем ударение). В арабском языке от согласного переходят прямо к слогу, а гласный отдельно не выделяют. На письме краткие гласные не обозначают вообще. Можно идти дальше и выделить фонемы: й-а-м-а, м-а-ц-у-р-и, но это членение уже трудно провести без специальной подготовки. Для нас эти рассуждения звучат странно, однако для японской традиции они вполне естественны. Первичная звуковая единица в этом языке, строго говоря, соответствует не слогу, а море: скажем, слово хогэн («диалект», о в этом слове долгое) принято членить так хо-о-гэ-н; соответствующим образом это слово и пишется. Японская поэзия, как и древнегреческая, основывалась на счете мор, а не слогов Однако если греки помимо мор выделяли звуки, то японцы не членили моры на части Понятие звука в нашем смысле появилось в Японии лишь после знакомства с европейской лингвистикой и латинским письмом, но и сейчас японцы считают латинскую письменность трудной, поскольку европейцы членят «звуки» на трудно воспринимаемые части Дело в языковой интуиции японцев В японском языке почти нет закрытых слогов и сочетаний согласных, мор ненамного больше, чем фонем Поэтому воспринимаются не единичные звуки, а их устойчивые сочетания — моры
Можно идти дальше и выделить фонемы: й-а-м-а, м-а-ц-у-р-и, но это членение уже трудно провести без специальной подготовки. Для нас эти рассуждения звучат странно, однако для японской традиции они вполне естественны. Первичная звуковая единица в этом языке, строго говоря, соответствует не слогу, а море: скажем, слово хогэн («диалект», о в этом слове долгое) принято членить так хо-о-гэ-н; соответствующим образом это слово и пишется. Японская поэзия, как и древнегреческая, основывалась на счете мор, а не слогов Однако если греки помимо мор выделяли звуки, то японцы не членили моры на части Понятие звука в нашем смысле появилось в Японии лишь после знакомства с европейской лингвистикой и латинским письмом, но и сейчас японцы считают латинскую письменность трудной, поскольку европейцы членят «звуки» на трудно воспринимаемые части Дело в языковой интуиции японцев В японском языке почти нет закрытых слогов и сочетаний согласных, мор ненамного больше, чем фонем Поэтому воспринимаются не единичные звуки, а их устойчивые сочетания — морыНаконец, в Китае первичной единицей считался целый слог, которому соответствовал иероглиф.
 Термин «цзы» означал и то и другое Количество слогов, конечно, больше количества фонем, но исчисляется сотнями и еще в древности было подсчитано Для китайского языкового сознания слог особенно важен и потому, что он, за редким исключением, имеет значение Вначале китайская наука вообще не членила слоги, а в VIII—X вв, как уже говорилось, появились фонетические таблицы Здесь слог делился на начальную нерифмующуюся — иници ал ъ, и конечную рифмующуюся —финаль Эти единицы больше сходны с нашими звуками (фонемами), но слог никогда не рассматривался как сочетание инициали с финалью (так могли рассуждать лишь европейцы) Наоборот, слог, объединенный общим тоном, был первичен, а инициаль и финаль, выделявшиеся лишь «разрезанием» иероглифа, считались его частями Но если инициаль обычно равняется одному согласному, то финаль очень часто имеет сложную структуру, например, слог -юань- делится на инициаль й- и финаль -уанъ. Однако вплоть до знакомства с европейской наукой и европейскими письменностями финаль в Китае никак не членили
Термин «цзы» означал и то и другое Количество слогов, конечно, больше количества фонем, но исчисляется сотнями и еще в древности было подсчитано Для китайского языкового сознания слог особенно важен и потому, что он, за редким исключением, имеет значение Вначале китайская наука вообще не членила слоги, а в VIII—X вв, как уже говорилось, появились фонетические таблицы Здесь слог делился на начальную нерифмующуюся — иници ал ъ, и конечную рифмующуюся —финаль Эти единицы больше сходны с нашими звуками (фонемами), но слог никогда не рассматривался как сочетание инициали с финалью (так могли рассуждать лишь европейцы) Наоборот, слог, объединенный общим тоном, был первичен, а инициаль и финаль, выделявшиеся лишь «разрезанием» иероглифа, считались его частями Но если инициаль обычно равняется одному согласному, то финаль очень часто имеет сложную структуру, например, слог -юань- делится на инициаль й- и финаль -уанъ. Однако вплоть до знакомства с европейской наукой и европейскими письменностями финаль в Китае никак не членилиУрок 11.
 Слоги и ударение.Урок 11. Слоги и ударение.
Слоги и ударение.Урок 11. Слоги и ударение.Слоги
в арабском языке всегда начинаются с согласной, и могут быть:1) краткие: согласная и следующая за ней краткая гласная (“ба”, “ти” и т.п.)
2) долгие: согласная + краткая гласная + согласная (“тун”, “бин”, и т.п.)
Есть еще другие долгие слоги (с долгими гласными), но их мы изучим позже.
Разложим по слогам слова из прошлого урока:ка-та-ба (все слоги краткие)
йак-ту-бу (первый слог долгий, остальные краткие)
Аналогично:
ля-би-са
йаль-ба-су
Если вы видите две согласных подряд – значит, они относятся к разным слогам, т.е. граница слогоделения проходит между ними.
В арабском языке невозможно стечение трех и более согласных подряд. Невозможность произнесения трех согласных звуков подряд – одна из самых характерных черт арабского акцента: например, в пиндостанском роботоязыке слово “world” араб произносит как “уорлит”, т. е. вставляет перед третьей согласной гласный звук. Им надо очень-очень долго тренироваться, чтобы избавиться от этой привычки.
е. вставляет перед третьей согласной гласный звук. Им надо очень-очень долго тренироваться, чтобы избавиться от этой привычки.
Арабы не сильно любят утруждать себя, поэтому правила ударения в арабском языке очень простые:
1) Ударение никогда не зависит от последнего слога, а зависит только от предпоследнего слога (от второго с конца).
2) Если предпоследний слог долгий, то ударение падает на него.
3) Если предпоследний слог краткий – ударение падает на предпредпоследний слог.
Другими словами:
Если второй слог с конца долгий, то ударение падает на него. Если второй слог с конца краткий, то ударение падает на третий слог с конца.
В двусложных словах ударение падает на первый слог (он же предпоследний, он же второй с конца).
Таким образом, вариантов ударения в слове всего два: второй или третий слог с конца, и зависит только от качества (долготы) предпоследнего слога.
Примеры (для наглядности даю два вида написания – обычное и с удлиненной связкой между буквами):
1) Ударение на предпоследний (второй с конца) слог, так как он долгий:
كَـسَـرْتُ | كَسَرْتُ | каса̀рту | я разбил |
كَـتَـبْـتُ | كَتَبْتُ | ката̀бту | я написа̀л |
لَـكُـمْ | لَكُمْ | ля̀кум | вам (строго говоря, здесь в арабском – предлог с местоимением) |
لَـكَ | لَكَ | ля̀ка | тебе (как и в предыдущем примере) |
2) Ударение на третий с конца слог (ибо предпоследний слог – краткий):
سَـيَـكْـتُـبُ | سَيَكْتُبُ | сайа̀ктубу | он будет писа̀ть |
يَـكْـسِـرُ | يَكْسِرُ | йа̀ксиру | он разбивает |
سَـيَـكْـسِـرُ | سَيَكْسِرُ | сайа̀ксиру | он будет разбивать |
كَـسَـرَ | كَسَرَ | ка̀сара | он разбил |
Примечание для лингвистических маньяков:
Описанные здесь правила ударения аналогичны правилам ударения в латыни, санскрите и многих других языках, особенно древних.
___
Оглавление
__
_
Все языки, поддерживаемые функциями иммерсивного средства чтения “Слоги” и “Части речи”
Надстройка “Средства обучения” для OneNote теперь поддерживает дополнительные языки при работе с функциями иммерсивного средства чтения “Слоги” и “Части речи” (“Существительные”, “Глаголы”, “Прилагательные”). Поддержка новых языков добавляется регулярно. Для экономии места при скачивании необходимые языки теперь можно выбрать во время установки надстройки “Средства обучения”.
В процессе установки или обновления надстройки “Средства обучения” для OneNote 2013 или OneNote 2016 вам будет предоставлена возможность выбора дополнительных языков. Чтобы узнать, как это сделать, выполните указанные ниже действия.
Первая установка надстройки “Средства обучения”
-
Закройте OneNote.
-
Скачайте надстройку “Средства обучения” и нажмите кнопку Выполнить.

-
Нажмите кнопку Добавить языки.
Выберите языки, которые вы хотите установить. Английский будет установлен по умолчанию. По умолчанию также будут выбраны французский, немецкий и испанский языки, но при этом их можно отобирать. Кроме того, установщик определяет, установлены ли у вас совпадающие языковые пакеты Office, и включает эти языки на выбор.
Примечание. Если пропустить этот шаг, установщик автоматически установит все языки, которые будут автоматически обнаружены по умолчанию.
-
Завершение установку и запустите OneNote. Надстройка “Средства обучения” появится на ленте OneNote в виде новой вкладки.
Обновление надстройки “Средства обучения” для добавления поддержки дополнительных языков
Если вы уже используете надстройку “Средства обучения” в OneNote 2013 или OneNote 2016 и хотите добавить функции “Слоги” и “Части речи”, проверьте, поддерживается ли ваш язык. Если ваш язык поддерживается, необходимо обновить или переустановить надстройку “Средства обучения”.
Если ваш язык поддерживается, необходимо обновить или переустановить надстройку “Средства обучения”.
На странице https://www.onenote.com/learningtools выберите ссылку Скачать. Если после нажатия кнопки Выполнить вы увидите начальный экран, следуйте указаниям по установке, приведенным в первом разделе этой статьи.
Если появится экран настройки, показанный ниже, необходимо удалить надстройку “Средства обучения”, а затем повторно установить ее вместе с последними обновлениями языковой поддержки. Нажмите кнопку Удалить, а затем снова запустите программу установки средств обучения для OneNote. Нажмите кнопку Добавить языки и следуйте указаниям, приведенным в первом разделе этой статьи.
Последующие обновления для надстройки “Средства обучения”
Иногда при использовании иммерсивного средства чтения попадаются страницы, содержащие текст на одном или нескольких языках, для которых не поддерживаются функции “Слоги” и “Части речи”. В этом случае вы получите уведомление при выделении на панели “Параметры грамматики”. Перейдите по ссылке , чтобы получить последние обновления языковой поддержки для надстройки “Средства обучения”.
В этом случае вы получите уведомление при выделении на панели “Параметры грамматики”. Перейдите по ссылке , чтобы получить последние обновления языковой поддержки для надстройки “Средства обучения”.
По мере добавления новых языков вы будете получать запросы на обновление надстройки. Для добавления дополнительных языков во время обновления нажмите кнопку Добавить языки. В противном случае никаких других действий не требуется, и языки будут переноситься автоматически.
В настоящее время надстройка “Средства обучения” поддерживает следующие языки при работе с функциями “Слоги” и “Части речи” (“Существительные”, “Глаголы”, “Прилагательные”):
-
Датский
-
Нидерландский
-
английский;
-
финский;
-
Французский
-
немецкий;
-
итальянский;
-
Норвежский букмол
-
Португальский (Бразилия)
-
Португальский (Португалия) (только “Слоги”)
-
русский;
-
испанский;
-
Шведский
Дополнительные сведения
Языки, поддерживаемые иммерсивным средством чтения
Дополнительные ресурсы для преподавателей
Таблица слогов китайского языка с русским чтением, максимально соответствующим китайскому произношению
В данной таблице приведены все слоги китайского языка. Запись китайских слогов буквами русского языка максимально соответствует стандартному китайскому произношению на путунхуа, хоть и не совсем соответствует нормативной транскрипции Палладия. Для грамотного написания китайских имен собственных по-русски используйте систему Палладия. А нижеприведенную таблицу рекомендуется использовать для выработки правильного китайского произношения.
Запись китайских слогов буквами русского языка максимально соответствует стандартному китайскому произношению на путунхуа, хоть и не совсем соответствует нормативной транскрипции Палладия. Для грамотного написания китайских имен собственных по-русски используйте систему Палладия. А нижеприведенную таблицу рекомендуется использовать для выработки правильного китайского произношения.
Также, лучше осваивать произношение с опытным преподавателем или носителем языка, чтобы с самого начала приучаться к произношению, максимально близкому к нормативному.
| А | |||
| a — а | ai — ай | an — ань | ang — ан |
| ao — ао | |||
| B | |||
| ba — ба | bai — бай | ban — бань | bang — бан |
| bao — бао | bei — бэй | ben — бэнь | beng — бэн |
| bi — би | bian — биень (“и” произносится едва заметно, а “ень” – как среднее между “ень” и “янь”) | biao — бияо (“и” произносится едва заметно) | bie — бие (“и” произносится едва заметно) |
| bin — бинь | bing — бин | bo — бо | bu — бу |
| C | |||
| ca — цха | cai — цхай | can — цхань | cang — цхан |
| cao — цхао | ce — цхэ | cen — цхэнь | ceng — цхэн |
| ci — цы | cong — цхун | cou — цхоу | cu — цху |
| cuan — цхуань | cui — цхуй | cun — цхунь | cuo — цхуо |
| CH | |||
| cha — чха | chai — чхай | chan — чхань | chang — чхан |
| chao — чхао | che — чхэ | chen — чхэнь | cheng — чхэн |
| chi — чши | chong — чхун | chou — чхоу | chu — чху |
| chuai — чхуай | chuan — чхуань | chuang — чхуан | chui — чхуй |
| chun — чхунь | chuo — чхуо | ||
| D | |||
| da — да | dai — дай | dan — дань | dang — дан |
| dao — дао | de — дэ | dei — дэй | deng — дэн |
| di — ди | dia — дя | dian — диень (“и” произносится едва заметно, а “ень” – как среднее между “ень” и “янь”) | diao — дияо (“и” произносится едва заметно) |
| die — дие | ding — дин | diu — диу | dong — дун |
| dou — доу | du — ду | duan — дуань | dui — дуй |
| dun — дунь | duo — дуо | ||
| E | |||
| e — э | ei — эй | en — энь | eng — эн |
| er — ар (реже эр) | |||
| F | |||
| fa — фа | fan — фань | fang — фан | fei — фэй |
| fen — фэнь | feng — фэн | fo — фо | fou — фоу |
| fu — фу | |||
| G | |||
| ga — га | gai — гай | gan — гань | gang — ган |
| gao — гао | ge — гэ | gei — гэй | gen — гэнь |
| geng — гэн | gong — гун | gou — гоу | gu — гу |
| gua — гуа | guai — гуай | guan — гуань | guang — гуан |
| gui — гуй | gun — гунь | guo — гуо | |
| H | |||
| ha — ха | hai — хай | han — хань | hang — хан |
| hao — хао | he — хэ | hei — хэй | hen — хэнь |
| heng — хэн | hm — хм | hng — хнг | hong — хун |
| hou — хоу | hu — ху | hua — хуа | huai — хуай |
| huan — хуань | huang — хуан | hui — хуй | hun — хунь |
| huo — хуо | |||
| J | |||
| ji — цзи | jia — цзя | jian — цзиень (“и” произносится едва заметно, а “ень” – как среднее между “ень” и “янь”) | jiang — цзян |
| jiao — цзяо | jie — цзие (“и” произносится едва заметно) | jin — цзинь | jing — цзин |
| jiong — цзюн | jiu — цзиу | ju — цзю | juan — цзюань |
| jue — цзюэ | jun — цзюнь | ||
| K | |||
| ka — кха | kai — кхай | kan — кхань | kang — кхан |
| kao — кхао | ke — кхэ | ken — кхэнь | keng — кхэн |
| kong — кхун | kou — кхоу | ku — кху | kua — кхуа |
| kuai — кхуай | kuan — кхуань | kuang — кхуан | kui — кхуй |
| kun — кхунь | kuo — кхуо | ||
| L | |||
| la — ла | lai — лай | lan — лань | lang — лан |
| lao — лао | le — лэ | lei — лэй | leng — лэн |
| li — ли | lia — ля | lian — лиень (“и” произносится едва заметно, а “ень” – как среднее между “ень” и “янь”) | liang — лян |
| liao — ляо | lie — лие (“и” произносится едва заметно) | lin — линь | ling — лин |
| liu — лиу | long — лун | lou — лоу | lu — лу |
| lü — люй | luan — луань | lüe — люэ | lun — лунь |
| luo — ло | |||
| M | |||
| m — м | ma — ма | mai — май | man — мань |
| mang — ман | mao — мао | me — мэ | mei — мэй |
| men — мэнь | meng — мэн | mi — ми | mian — миень (“и” произносится едва заметно, а “ень” – как среднее между “ень” и “янь”) |
| miao — миао | mie — мие (“и” произносится едва заметно) | min — минь | ming — мин |
| miu — миу | mm — мм | mo — мо | mou — моу |
| mu — му | |||
| N | |||
| n — н | na — на | nai — най | nan — нань |
| nang — нан | nao — нао | ne — нэ | nei — нэй |
| nen — нэнь | neng — нэн | ng — нг | ni — ни |
| nian — ниень (“и” произносится едва заметно, а “ень” – как среднее между “ень” и “янь”) | niang — нян | niao — нияо (“и” произносится едва заметно) | nie — ние (“и” произносится едва заметно) |
| nin — нинь | ning — нин | niu — ниу | nong — нун |
| nu — ну | nü — нюй | nuan — нуань | nüe — нюэ |
| nuo — нуо | |||
| O | |||
| o — о | ou — оу | ||
| P | |||
| pa — пха | pai — пхай | pan — пхань | pang — пхан |
| pao — пхао | pei — пхэй | pen — пхэнь | peng — пхэн |
| pi — пхи | pian — пхиень (“и” произносится едва заметно, а “ень” – как среднее между “ень” и “янь”) | piao — пхияо (“и” произносится едва заметно) | pie — пхие (“и” произносится едва заметно) |
| pin — пхинь | ping — пхин | po — пхо | pou — пхоу |
| pu — пху | |||
| Q | |||
| qi — ци (произносится мягко, не путать с “цы”) | qia — ця | qian — циень (“и” произносится едва заметно, а “ень” – как среднее между “ень” и “янь”) | qiang — цян |
| qiao — цяо | qie — цие (“и” произносится едва заметно) | qin — цинь | qing — цин |
| qiong — цюн | qiu — циу | qu — цюй | quan — цюань |
| que — цюэ | qun — цюнь | ||
| R | |||
| ran — жань | rang — жан | rao — жао | re — жэ |
| ren — жэнь | reng — жэн | ri — жи | rong — жун |
| rou — жоу | ru — жу | ruan — жуань | rui — жуй |
| run — жунь | ruo — жуо | ||
| S | |||
| sa — са | sai — сай | san — сань | sang — сан |
| sao — сао | se — сэ | sen — сэнь | seng — сэн |
| si — сы (не путать с “си”, частая ошибка) | song — сун | sou — соу | su — су |
| suan — суань | sui — суй | sun — сунь | suo — суо |
| SH | |||
| sha — ша | shai — шай | shan — шань | shang — шан |
| shao — шао | she — шэ | shei — шэй | shen — шэнь |
| sheng — шэн | shi — ши | shou — шоу | shu — шу |
| shua — шуа | shuai — шуай | shuan — шуань | shuang — шуан |
| shui — шуй | shun — шунь | shuo — шуо | |
| T | |||
| ta — тха | tai — тхай | tan — тхань | tang — тхан |
| tao — тхао | te — тхэ | ten — тхэнь | teng — тхэн |
| ti — тхи | tian — тхиень (“и” произносится едва заметно, а “ень” – как среднее между “ень” и “янь”) | ||
| tiao — тхяо | tie — тхие (“и” произносится едва заметно) | ting — тхин | |
| tong — тхун | tou — тхоу | tu — тху | tuan — тхуань |
| tui — тхуй | tun — тхунь | tuo — тхуо | |
| W | |||
| wa — ва | wai — вай | wan — вань | wang — ван |
| wei — вэй | wen — вэнь | weng — вэн | wo — во |
| wu — у | |||
| X | |||
| xi — си | xia — ся | xian — сиень (“и” произносится едва заметно, а “ень” – как среднее между “ень” и “янь”) | xiang — сян |
| xiao — сяо | xie — сие (“и” произносится едва заметно) | xin — синь | xing — син |
| xiong — сюн | xiu — сиу | xu — сю | xuan — сюань |
| xue — сюэ | xun — сюнь | ||
| Y | |||
| ya — я | yan — ень (среднее между “ень” и “янь”) | yang — ян | yao — яо |
| ye — е | yi — и | yin — инь | ying — ин |
| yong — юн | you — йоу | yu — юй | yuan — юань |
| yue — юэ | yun — юнь | ||
| Z | |||
| za — цза | zai — цзай | zan — цзань | zang — цзан |
| zao — цзао | ze — цзэ | zei — цзэй | zen — цзэнь |
| zeng — цзэн | zi — цзы | zong — цзун | zou — цзоу |
| zu — цзу | zuan — цзуань | zui — цзуй | zun — цзунь |
| zuo — цзуо | |||
| ZH | |||
| zha — чжа | zhai — чжай | zhan — чжань | zhang — чжан |
| zhao — чжао | zhe — чжэ | zhei — чжэй | zhen — чжэнь |
| zheng — чжэн | zhi — чжи | zhong — чжун | zhou — чжоу |
| zhu — чжу | zhua — чжуа | zhuai — чжуай | zhuan — чжуань |
| zhuang — чжуан | zhui — чжуй | zhun — чжунь | zhuo — чжуо |
Скачать в формате Excel
Поделиться в социальных сетях:
Добавить комментарий
Язык предпочитает одни слоги другим не только из-за удобства произношения
В языке существуют универсальные иерархии слогов по их встречаемости (предпочтительности). Например, в самых разных языках слог blog встречается чаще, чем lbog. Есть ли абстрактные правила, которые мешают закрепиться в языке таким слогам, как lbog, или же их более редкое употребление объясняется только неудобством произношения? Ученые выяснили, что, хотя в языке закрепляются слоги, оптимизирующие моторные затраты, но на отбор слогов влияют также и более абстрактные принципы, не связанные с удобством произношения слогов.
Например, в самых разных языках слог blog встречается чаще, чем lbog. Есть ли абстрактные правила, которые мешают закрепиться в языке таким слогам, как lbog, или же их более редкое употребление объясняется только неудобством произношения? Ученые выяснили, что, хотя в языке закрепляются слоги, оптимизирующие моторные затраты, но на отбор слогов влияют также и более абстрактные принципы, не связанные с удобством произношения слогов.
Речь состоит из слов, а слова представляют собой сочетания звуков, причем одни из этих сочетаний встречаются чаще, а другие — реже. Интересно, что существуют ряды слогов, которые различаются по встречаемости в самых разных языках одинаковым образом (J. H. Greenberg, 1964. Some generalizations concerning initial and final consonant clusters, русский перевод этой статьи «Некоторые обобщения, касающиеся возможных начальных и конечных последовательностей согласных» был опубликован в журнале «Вопросы языкознания» №4 за 1964 год).
Пример такой универсальной иерархии слогов: blif ≻ bnif ≻ bdif ≻ lbif. Слог bnif в самых разных языках встречается чаще, чем bdif, но реже, чем blif. Слоги в этом ряду отличаются не только по частоте, с которой они встречаются, но и по легкости распознавания. К примеру, ошибки в распознавании слога lbif будут возникать у испытуемых чаще, чем слога blif. Эта закономерность — общая и для взрослых, и для детей, и для носителей разных языков независимо от того, встречается ли такой слог в их родном языке, и верна даже для людей с дислексией (см. статьи I. Berent et al., 2008. Language universals in human brains; I. Berent et al., 2009. Listeners’ knowledge of phonological universals: Evidence from nasal clusters; I. Berent et al., 2013. Phonological generalizations in dyslexia: The phonological grammar may not be impaired).
Слог bnif в самых разных языках встречается чаще, чем bdif, но реже, чем blif. Слоги в этом ряду отличаются не только по частоте, с которой они встречаются, но и по легкости распознавания. К примеру, ошибки в распознавании слога lbif будут возникать у испытуемых чаще, чем слога blif. Эта закономерность — общая и для взрослых, и для детей, и для носителей разных языков независимо от того, встречается ли такой слог в их родном языке, и верна даже для людей с дислексией (см. статьи I. Berent et al., 2008. Language universals in human brains; I. Berent et al., 2009. Listeners’ knowledge of phonological universals: Evidence from nasal clusters; I. Berent et al., 2013. Phonological generalizations in dyslexia: The phonological grammar may not be impaired).
Почему существуют такие универсальные иерархии сочетаний звуков по их предпочтительности? Возможное объяснение — различия в сложности произношения слогов. Но слоги могут реже встречаться в языке не только потому, что их сложнее произносить, но и потому, что их сложнее распознавать. Ранее было показано, что в процессе восприятия звуков речи у человека активируются моторные области коры, ответственные за движения языка и губ. Такая активация точно воспроизводит то, что происходит в мозге человека, который сам произносит звуки. Так, во время восприятия губных согласных звуков (b, p, v, f) сильнее активируются моторные области мозга (см. Motor cortex), отвечающие за движения мышц губ, а при распознавании переднеязычных согласных (z, s, d, t, l, n) — области, отвечающие за движения языка (F. Pulvermüller et al., 2006. Motor cortex maps articulatory features of speech sounds). Таким образом, люди помогают себе распознать чужую речь, проигрывая в голове, как бы они сами произносили эти звуки.
Ранее было показано, что в процессе восприятия звуков речи у человека активируются моторные области коры, ответственные за движения языка и губ. Такая активация точно воспроизводит то, что происходит в мозге человека, который сам произносит звуки. Так, во время восприятия губных согласных звуков (b, p, v, f) сильнее активируются моторные области мозга (см. Motor cortex), отвечающие за движения мышц губ, а при распознавании переднеязычных согласных (z, s, d, t, l, n) — области, отвечающие за движения языка (F. Pulvermüller et al., 2006. Motor cortex maps articulatory features of speech sounds). Таким образом, люди помогают себе распознать чужую речь, проигрывая в голове, как бы они сами произносили эти звуки.
Ученые предположили, что простота или сложность «внутреннего проигрывания» слогов влияют на их предпочтительность. Менее удобные сочетания звуков должны требовать более активной работы моторной коры (мозгу приходится проигрывать «несуразные» движения), из-за чего их должно быть меньше. Поэтому ученые решили помочь моторным областям испытуемых, используя транскраниальную магнитную стимуляцию (ТМС). ТМС — неинвазивная техника, помогающая активировать или, наоборот, отключать определенные области мозга с помощью электромагнитных импульсов. Ранее было показано, что стимуляция активности определенных моторных областей улучшает распознавание звуков соответствующей группы. Так, стимуляция моторных областей, отвечающих за работу губных мышц, улучшала распознавание губных согласных, а стимуляция областей, отвечающих за функционирование мышц языка, — распознавание переднеязычных согласных (A. D’Ausilio et al., 2009. The motor somatotopy of speech perception).
Поэтому ученые решили помочь моторным областям испытуемых, используя транскраниальную магнитную стимуляцию (ТМС). ТМС — неинвазивная техника, помогающая активировать или, наоборот, отключать определенные области мозга с помощью электромагнитных импульсов. Ранее было показано, что стимуляция активности определенных моторных областей улучшает распознавание звуков соответствующей группы. Так, стимуляция моторных областей, отвечающих за работу губных мышц, улучшала распознавание губных согласных, а стимуляция областей, отвечающих за функционирование мышц языка, — распознавание переднеязычных согласных (A. D’Ausilio et al., 2009. The motor somatotopy of speech perception).
В ходе эксперимента испытуемые воспринимали звуковые стимулы на слух. Это были или слоги из иерархического ряда, или производные от них, состоящие из двух слогов (например, lbif–lebif). Участникам эксперимента нужно было определить, сколько слогов они слышат. При этом работу моторных областей их мозга, отвечающих за работу мышц губ, в некоторых экспериментах стимулировали с помощью ТМС.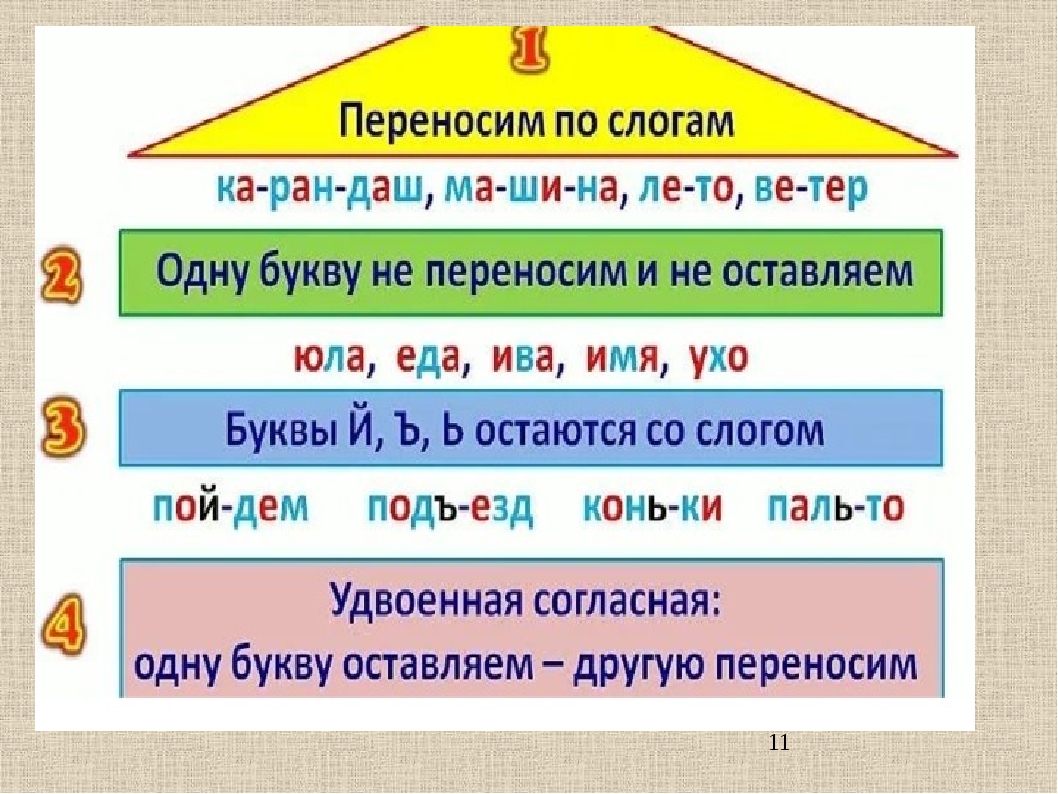 Затем ученые сравнили результаты, чтобы выяснить, сохранится ли иерархия слогов по качеству распознавания в случае, если моторным областям мозга «помогали» работать. Оказалось, что иерархия не изменилась, то есть, например, слог blif по-прежнему распознавался лучше, чем bdif. При этом распознавать наименее удобные сочетания звуков ТМС не помогала, а распознавать более удобные — даже мешала (рис. 2). То же было верно для других рядов слогов (не встречающихся в английском), составленных так, что за губным согласным всегда следовал переднеязычный. Иерархия слогов сохранялась, несмотря на изменение активности моторных областей искусственным образом. Получается, что различия в сложности произношения — не единственная причина иерархии слогов по предпочтительности.
Затем ученые сравнили результаты, чтобы выяснить, сохранится ли иерархия слогов по качеству распознавания в случае, если моторным областям мозга «помогали» работать. Оказалось, что иерархия не изменилась, то есть, например, слог blif по-прежнему распознавался лучше, чем bdif. При этом распознавать наименее удобные сочетания звуков ТМС не помогала, а распознавать более удобные — даже мешала (рис. 2). То же было верно для других рядов слогов (не встречающихся в английском), составленных так, что за губным согласным всегда следовал переднеязычный. Иерархия слогов сохранялась, несмотря на изменение активности моторных областей искусственным образом. Получается, что различия в сложности произношения — не единственная причина иерархии слогов по предпочтительности.
Исследователи также проверили методом МРТ, что происходит с обменом веществ в мозге во время обработки слогов, занимающих разные ступени иерархии. Ученые предполагали, что наименее удобные слоги требуют наибольших моторных затрат, но оказалось, что всё обстоит как раз наоборот. При распознавании менее удобных слогов моторные обрасти коры, ответственные за движения губ, менее активны, и ТМС им не помогает. Видимо, слоги с нижних ступеней иерархии (такие, как lbif) менее предпочтительны не потому, что связаны с наибольшими моторными затратами, а наоборот, их меньшая предпочтительность снижает активность моторных областей, что ведет к худшему распознаванию. То есть активность моторных областей — это не причина лингвистических предпочтений, а их следствие.
При распознавании менее удобных слогов моторные обрасти коры, ответственные за движения губ, менее активны, и ТМС им не помогает. Видимо, слоги с нижних ступеней иерархии (такие, как lbif) менее предпочтительны не потому, что связаны с наибольшими моторными затратами, а наоборот, их меньшая предпочтительность снижает активность моторных областей, что ведет к худшему распознаванию. То есть активность моторных областей — это не причина лингвистических предпочтений, а их следствие.
Интересно, что при распознавании звуков, замаскированных шумом, моторные области, наоборот, работают активнее всего, как бы стараясь помочь человеку разобрать их (Y. Du et al., 2014. Noise differentially impacts phoneme representations in the auditory and speech motor systems). Но когда необходимо распознать «неудобные» слоги, моторные области почему-то «умывают руки».
Получается, что существование универсальных рядов слогов с разной предпочтительностью объясняется не только различиями в сложности их произношения и в активности соответствующих областей мозга. По-видимому, базовые элементы, из которых состоит речь, подвергаются отбору и по другим критериям, например по продуктивности — способности хорошо сочетаться с множеством других слогов. На это наводят ошибки испытуемых, которые они делали при распознавании менее удобных слогов: испытуемые чаще принимали такой слог за два, добавляя между двумя согласными гласную (вместо lbif — lebif). Такие конструкции было бы легче комбинировать друг с другом, чем составлять сочетания из несколько слогов вроде lbif. По-видимому, в отборе слогов на уровне физиологии человека играют роль не только вопросы удобства произношения звуков и сложности их репрезентаций в мозге, но также и более абстрактные лингвистические законы.
По-видимому, базовые элементы, из которых состоит речь, подвергаются отбору и по другим критериям, например по продуктивности — способности хорошо сочетаться с множеством других слогов. На это наводят ошибки испытуемых, которые они делали при распознавании менее удобных слогов: испытуемые чаще принимали такой слог за два, добавляя между двумя согласными гласную (вместо lbif — lebif). Такие конструкции было бы легче комбинировать друг с другом, чем составлять сочетания из несколько слогов вроде lbif. По-видимому, в отборе слогов на уровне физиологии человека играют роль не только вопросы удобства произношения звуков и сложности их репрезентаций в мозге, но также и более абстрактные лингвистические законы.
Источник: Iris Berent, Anna-Katharine Brem, Xu Zhao, Erica Seligson, Hong Pan, Jane Epstein, Emily Stern, Albert M. Galaburda, and Alvaro Pascual-Leone. Role of the motor system in language knowledge // PNAS. 2015. DOI:10.1073/pnas.1416851112.
Юлия Кондратенко
слогов в языке | Разделить язык на слоги
Сколько слогов в языке? 2 слога
Разделить язык на слоги: язык
Как произносится , язык :
Американский английский акцент и произношение: Ваш браузер не поддерживает аудио элементы.
Британский английский акцент и произношение: Ваш браузер не поддерживает аудио элементы.
Определение: Язык (откроется новое окно)
Вы писатель-фрилансер? Если да, присоединяйтесь к нашему писательскому сообществу с возможностями фрилансера, уникальными рекламными возможностями и бесплатными инструментами для письма.
Возможности писателя-фрилансера
Language Poems : (Смотрите стихи с этим словом. Откроется новое окно)
Синонимы и слова, относящиеся к языку
языки (2 слога), лингвистическое общение (8 слогов), лингвистический процесс (5 слогов), лирика (2 слога), номенклатура (4 слога), устное общение (7 слогов), речь (1 слог), речь (1 слог), речевое общение (6 слогов) ), устное общение (7 слогов), устная речь (4 слога), терминология (5 слогов), голосовое общение (6 слогов) афразийский (3 слога), афроазиатский (6 слогов), алгонкинский (4 слога), алгонкинский (3 слога), алтайский (3 слога), американский (4 слога), америнд (3 слога), амхарский (3 слога), анатолийский ( 5 слогов), арабский (3 слога), арго (2 слога), армянский (4 слога), асл (2 слога), атабасканский (4 слога), атабасканский (4 слога),
Два слога, рифмующиеся с языкомязык |
Что вы думаете о нашем ответе на вопрос, сколько слогов в языке? Правильно ли подсчитано количество слогов, произношение, рифмуются слова и разделены слоги для языка? Внутри U. С. Английский язык. Можно ли произносить язык по-другому? Правильно ли мы разделили слоги? Влияют ли региональные различия в произношении языка на количество слогов? Изменился ли язык? Поделитесь своими комментариями или мыслями по поводу количества слогов для указанного ниже языка.
С. Английский язык. Можно ли произносить язык по-другому? Правильно ли мы разделили слоги? Влияют ли региональные различия в произношении языка на количество слогов? Изменился ли язык? Поделитесь своими комментариями или мыслями по поводу количества слогов для указанного ниже языка.
Комментарий к слогам в языке
Исчерпывающий ресурс для поиска слогов в языке, количества слогов в языке, слов, рифмующихся с языком, как разделить язык на слоги, как произносить язык в американском и британском английском, как разбивать язык на слоги.
Частота– наиболее частые слоги
Я ищу список наиболее часто встречающихся слогов всех языков, на которых говорят на Земле, отсортированных по частоте.
Я нашел такие списки для английского и немецкого языков, но хочу получить список на всех языках.
Предположим, вы можете сосчитать каждый слог, произносимый на Земле, в течение 24 часов. Слоги из языков, на которых много носителей, таких как китайский (мандаринский), английский или хинди, используются чаще, чем слоги из редких языков, таких как эсперанто или клингон, и поэтому занимают более высокое место в списке. И в одном языке есть слоги, которые используются чаще, чем другие.
И в одном языке есть слоги, которые используются чаще, чем другие.
Я знаю, то, что я хочу, будет сложно реализовать. Так что я также был бы доволен отдельными списками языков с большим количеством носителей, скажем, с топ-200 слогами. (Меня не интересуют редкие слоги, я сосредотачиваюсь на общих слогах. По той же причине меня не интересуют редкие языки.)
И мне действительно нужны разговорные слоги, а не письменные ди- и трехграфы (« the » – это триграф, а не слог.Это может быть письменное представление слога / ðə / , но также часть / ðɛn / )
Дополнение
Вот списки, которые я нашел:
Немецкий:
http://www.uni-potsdam.de/fileadmin/projects/treatmentlab/assets/Silbenfrequenzen_TreatmentLab.pdf
Столбцы слева направо:
- Стартовая позиция.
- Слог.
- Это число показывает, как часто этот слог можно услышать, когда произносится один миллион слов (что означает, что частые слова повторяются много раз и, следовательно, их слоги учитываются чаще)
- Возьмите словарь всех немецких слов, где изгибы одной и той же лексемы представляют собой разные слова ( запускает , запускает , запускает и запускает будет перечислено как четыре разных слова).
 Посчитайте, как часто этот слог встречается в этом словаре (сам словарь содержит 365,530 различных немецких слов).
Посчитайте, как часто этот слог встречается в этом словаре (сам словарь содержит 365,530 различных немецких слов).
Этот список отсортирован по столбцу 3 rd , и это именно то, что мне нужно. Эта колонка отвечает на этот вопрос:
Когда вы слушаете, как немцы произносят миллион слов, как часто вы можете слышать какой слог?
Меня не интересует 4 -я колонка .
Английский:
https: // medium.com/@rosson/high-frequency-syllables-in-english-ab75159618a0#.jaee1pxhq
В этом списке всего 3 столбца, где №1 и №2 идентичны первым двум столбцам немецкого списка. Столбец №3 такой же, как немецкий столбец №3, но в немецком списке у вас есть счетчики на миллион, в английском у вас есть проценты, что является еще одним представлением того же самого.
Как мне использовать эти списки для создания списка на всех языках?
В английском списке я бы преобразовал числа в столбце 3 в количество на миллион, как в немецком списке. Затем мне нужно количество носителей языка на каждом языке. Такой список можно найти здесь: https://en.wikipedia.org/wiki/List_of_languages_by_number_of_native_speakers
Затем мне нужно количество носителей языка на каждом языке. Такой список можно найти здесь: https://en.wikipedia.org/wiki/List_of_languages_by_number_of_native_speakers
Как видите, в 2010 году на английском языке было 360 миллионов носителей, а на немецком – 89 миллионов в том же году. Поэтому я умножаю (преобразованные) английские числа на 360 и умножаю числа в столбце № 3 немецкого списка на 89, а затем объединяю оба списка. Если есть слоги как в английском, так и в немецком языках (например, [ɪn]), я складываю оба числа с уменьшенным шрифтом.Затем я снова сортирую этот список по этим числам.
Результатом является список наиболее часто употребляемых слогов немецкой и английской разговорных частей мира.
И поскольку меня интересуют наиболее часто встречающихся слогов, можно смело игнорировать редкие языки, среди которых вы найдете все языки, которые не были изучены.
И чтобы дать вам пример, что я ищу , а не : http://www. sttmedia.com/syllablefrequency-english Здесь вы найдете номера биграмм и триграмм, но это не фонетические слоги!
sttmedia.com/syllablefrequency-english Здесь вы найдете номера биграмм и триграмм, но это не фонетические слоги!
Приложение 2 (март 2018 г.)
Думаю, мне лучше рассказать вам контекст.(Что мне делать с этим списком?)
Пишу фантастический рассказ. В космосе путешествовала небольшая группа инопланетян, и они заблудились. У них были технические проблемы, и они оказались на планете, которая оказалась нашей планетой Земля. Это произошло тысячи лет назад, и все люди на Земле являются потомками этой небольшой группы, и все языки, на которых сегодня говорят на Земле, произошли от языка этой небольшой группы захватчиков.
Я хочу создать язык, который мог бы стать протоязыком первых людей на Земле.
Моя вторая цель – сделать этот язык как можно более легким для произнесения всеми на этой планете. Я хочу, чтобы людям из Китая было так же легко произносить его, как людям из Саудовской Аравии, России, США, Намибии и так далее.
Я думаю, что мне нужен не набор общих фонем для объединения, а набор очень распространенных слогов, потому что даже широко распространенные фонемы могут быть трудно произносимыми, когда вы используете необычные комбинации.
Я хочу попытаться создать художественный язык, состоящий из общих слогов, и именно поэтому я ищу наиболее часто произносимые слоги на земле.
кстати: Когда два слога похожи, я хочу считать их идентичными. Например, английские слова «I, eye, ay, aye» и немецкие «Ei» – это один и тот же слог (/ aɪ /).
Фонология– Существуют ли языки, в которых разрешены только слоги резюме?
Хороший вопрос! Я также не смог найти никаких однозначных примеров с помощью короткого поиска, и я нашел один источник, который говорит, что не существует известных примеров языков, содержащих только слоги резюме.
Понимание фонологии (четвертое издание), Карлос Гуссенховен и Хайке Якобс, говорит:
Начало может быть обязательным. Нетрудно найти языки с обязательным началом, такие как арабский, дирбал и кламат, но языка, которые допускают только CV, то есть обязательное начало, за которым следует мономоральный гласный, должны быть редкими до такой степени, что у нас нет примера.
Аналитические проблемы могут возникать из-за фонетического начала в односложных слогах. Во многих языках, например, в немецком, в этих контекстах обычно есть гортанная остановка, например, в [ˈafə], произносится [ʔafə], «обезьяна», в то время как в языках мба и ндунга первые высокие гласные в начале слова, по-видимому, начинаются с переменной [ʔ], [ɦ] или гоморганический полуглазок (Pasch 1986: 32, 91).Хэнаньский мандарин имеет гоморганический полугласный звук, предшествующий гласному без малой буквы, как в [i 214 ], произносится [ji], «один, числительное»; [y 41 ], произносится [ɥy], «рыба»; [u 341 ], произносится [wu], «дом», [ɤ 341 ], произносится [ɰɤ], «голодный»; и голосовая остановка перед низкими гласными, как в [æɛ 341 ], [произносится [ʔæɛ], «любовь» (личные полевые заметки, CG, 2014). Фонематические глоттальные остановки легко различимы в таких языках, как гавайский, где они контрастируют с пустыми началами, такими как [aa] ‘челюсть’ и [ʔaa] ‘огненный’ (Elbert and Pukui 1979), или арабский [* см.
Мою заметку ниже ], который имеет такой же контраст в коде слога и имеет гортанную остановку в начале слов, как в [lawʔa] «печаль» (Thelwall and Sa’adeddin 1990).У немецкого нет ни одного из этих трех свойств.
(стр. 38)
Я думаю, что будет трудно найти четкие ответы на этот вопрос, потому что по теоретическим причинам в неоднозначных ситуациях CV-анализ часто предпочтительнее простого V-анализа. (Фактически, существует даже теоретическая традиция абстрактного анализа языков, которые, по-видимому, однозначно имеют слоги, отличные от CV, поскольку на самом деле имеют только слоги CV с пустыми позициями: «Строгая фонология резюме». Итак, с определенной теоретической точки зрения, ответ на ваш на самом деле вопрос может быть «все они»!) Иногда это может привести к путанице, когда источники не упоминают теоретические основы анализа определенного языка как имеющих обязательное начало.(User6726 поднял еще один теоретический момент, который может быть сложным, о котором я забыл, – анализ последовательностей скольжения C + (или коартикулированного скольжения C +) как фонем и кластеров согласных. )
)
Например (в любом случае это даже не язык CV, так как он позволяет использовать согласные коды, но только для иллюстрации). Можно сказать, что китайский китайский с определенной точки зрения имеет обязательные начала. Но на самом деле в мандаринском языке это достигается путем анализа того, что можно рассматривать как начальные гласные слоги, начинающиеся с «нулевого начала», имеющего переменную реализацию, и могут быть [ʔ], [ŋ] или [ɣ].Об этом упоминается в книге « Syllable Structure: The Limits of Variation», «» San Duanmu, 2008 (стр. 73). Фактически, Дуаньму выражает сомнение по поводу этого анализа и заканчивает тем, что говорит: «Таким образом, нулевой эффект начала в исходной позиции высказывания, вероятно, непреднамерен, а в медиальных позициях нет никаких доказательств нулевого начала или ресиллабификации через границу слова». (стр.76).
Я мог бы предположить, что во многих языках, которые, как говорят, имеют «обязательные» начала, некоторые из них могут быть согласными, которые могут рассматриваться как эпентетические, по крайней мере, в некоторых контекстах, таких как глоттальные остановки или скольжения, которые гоморганичны следующим или предшествующий гласный.
Даже приведенные Гуссенховеном и Якобсом примеры языков с обязательным началом не все полностью однозначны. У арабского языка есть начала гортанной остановки, которые можно анализировать как эпентетические, по крайней мере, некоторое время (см. Примечание ниже), а также / ji / и / wu /. У Дирбала есть / ji / и / wu /, и, согласно «Пересмотру фонологических обобщений в австралийских языках» Эмили Гассер и Клэр Бауэрн, возможно, что «некоторые авторы грамматик [австралийских языков] могли проанализировать / u- / или / i- / начальные слова как показывающие скользящее скольжение из-за ожидания, что австралийские языки имеют тенденцию отвергать слова с гласными начальными словами.У нас нет возможности исследовать эту проблему с текущими данными »(стр. 7). (Мне не удалось найти какой-либо соответствующей дополнительной информации о фонологии / фонотактике Klamath.)
Эти сложности, конечно же, не означают, что неправильно описывать эти языки как имеющие обязательные начала, но они поднимают некоторые вопросы о том, насколько просто разделить языки на два аккуратных класса: «разрешать односложные слоги» и «не разрешать». onsetless syllables », поскольку языки, которые часто описываются как имеющие V-начальные слоги, такие как английский или немецкий, могут также показывать аналогичные виды эпентетических согласных в начале« гласных-начальных »слогов по крайней мере в некоторых контекстах.
onsetless syllables », поскольку языки, которые часто описываются как имеющие V-начальные слоги, такие как английский или немецкий, могут также показывать аналогичные виды эпентетических согласных в начале« гласных-начальных »слогов по крайней мере в некоторых контекстах.
* мое примечание: даже в (современном стандарте **) арабском языке ситуация осложняется тем, что слова, которые произносятся изолированно с начальной гортанной остановкой, не все ведут себя одинаково в связной речи. Существует фонологическое различие между словами, которые начинаются со слов «слабая» или «разрешаемая» голосовая остановка и «сильная» голосовая остановка.
** Я ничего не знаю о фонологии голосовых связок в различных региональных вариантах арабского языка.
Некоторые вопросы по теме:
Что такое слог в английском языке?
Слог – это одна или несколько букв, представляющих единицу разговорной речи, состоящую из одного непрерывного звука.Прилагательное: слоговое .
Слог состоит либо из одного гласного звука (как в произношении oh ), либо из комбинации гласного и согласного (ых) (как в № и не ).
Отдельно стоящий слог называется односложным . Слово, состоящее из двух или более слогов, называется многосложным .
Слово , слог происходит от греческого «комбинировать».
«Носителям английского языка не составляет труда подсчитать количество слогов в слове», – говорит Р.W. Fasold и J. Connor-Linton, «но лингвистам труднее определить, что такое слог». В их определении слог – это «способ организации звуков вокруг пика звучности»
( An Introduction to Language and Linguistics , 2014).
Примеры и научные наблюдения
«Слово может произноситься [а]« слог за раз », как в nev-er-the-less , и хороший словарь определит, где эти слоговые деления встречаются в письменной форме, таким образом предоставляя информацию о том, как слово может быть расставлено через дефис. Силлабификация – это термин, который относится к разделению слова на слоги ».
Силлабификация – это термин, который относится к разделению слова на слоги ».
(Дэвид Кристал, Словарь лингвистики и фонетики . Blackwell, 2003)
«Слог – это вершина, выделяющаяся в цепочке произнесения. Если бы вы могли измерить акустическую мощность, выходящую из динамика, поскольку она меняется со временем, вы бы обнаружили, что она непрерывно идет вверх и вниз, образуя небольшие пики и впадины: пики Слова lair и здесь образуют только по одной вершине каждое, то есть только один слог, тогда как слова player и newer обычно произносятся с двумя вершинами и поэтому содержат два слога.Таким образом, желательно различать дифтонг (который представляет собой один слог) и последовательность из двух гласных (состоящих из двух слогов) ».
(Charles Barber, The English Language: A Historical Introduction . Cambridge University Press, 2000 )
«Слог – не сложное понятие для интуитивного понимания, и существует значительное согласие в подсчете слогов в словах.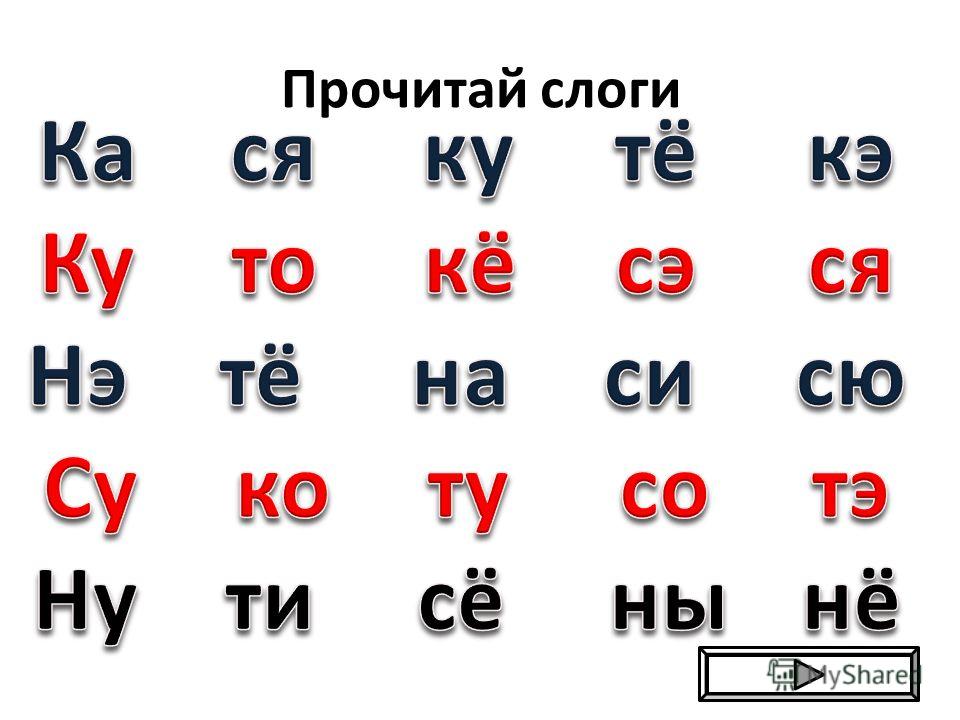 Вероятно, большинство читателей согласятся, что треска имеет один слог, ahi – два, а палтус – три.Но технические определения сложны. Тем не менее, есть согласие, что слог – это фонологическая единица, состоящая из одного или нескольких звуков, и что слоги делятся на две части – начало и рифму. Рифма состоит из пика или ядра и любых согласных, следующих за ним. Ядро обычно является гласным. . .. Согласные, которые предшествуют рифме в слоге, составляют начало . . .
Вероятно, большинство читателей согласятся, что треска имеет один слог, ahi – два, а палтус – три.Но технические определения сложны. Тем не менее, есть согласие, что слог – это фонологическая единица, состоящая из одного или нескольких звуков, и что слоги делятся на две части – начало и рифму. Рифма состоит из пика или ядра и любых согласных, следующих за ним. Ядро обычно является гласным. . .. Согласные, которые предшествуют рифме в слоге, составляют начало . . .
“[T] Единственный существенный элемент слога – это ядро.Поскольку один звук может составлять слог, а один слог может составлять слово, слово может состоять из единственной гласной, но вы уже знали это, зная слова a и I ».
(Эдвард Финеган, Язык: его структура и использование , 6-е изд. Wadsworth, 2012)
«Сила слова может иметь самую сложную структуру слогов среди любого английского слова:. . . с тремя согласными в начале и четырьмя в коде [согласные в конце рифмы]! »
(Кристин Денхэм и Энн Лобек, Лингвистика для всех . Уодсворт, 2010)
Уодсворт, 2010)
“Некоторые согласные могут произноситься отдельно ( mmm, zzz ) и могут рассматриваться или не рассматриваться как слоги, но обычно они сопровождают гласные, которые, как правило, занимают центральное положение в слоге (слоговое положение ), как в pap, pep, pip, pop, pup . Согласные занимают поля слога, как и ‘ p’ в только что приведенных примерах. Гласная на полях слога часто обозначается как glide , как в ebb и bay . Слоговые согласные встречаются во вторых слогах таких слов, как средний или midden , заменяя последовательность шва плюс согласный …
(Джеральд Ноулз и Том МакАртур, The Oxford Companion to English Language , под редакцией Тома МакАртура. Oxford University Press, 1992)
«Обычный слоговый процесс, особенно среди первых 50 слов ребенка, – это дублирование (повторение слога). Этот процесс можно увидеть в таких формах, как мама, папа, пипи и так далее. Также может иметь место частичное дублирование (повторение части слога); очень часто конечный гласный сегмент заменяется на / i /, как в мама и папа . )
Также может иметь место частичное дублирование (повторение части слога); очень часто конечный гласный сегмент заменяется на / i /, как в мама и папа . )
“Такие слова, как matinee и negligee , введенные после 1700 года, имеют ударение на первом слоге в британском английском и на последнем в американском английском.«
(Анн-Мари Свенссон,« О подчеркивании французских заимствований в английском », в Новые перспективы английской исторической лингвистики , изд. Кристиан Кей и др. Джон Бенджаминс, 2002)
Д-р Дик Соломон: Теперь я отправлю своего врага элегантным хайку.
Д-р Лиам Нисам: Пять слогов, семь слогов, пять слогов.
Доктор Дик Соломон: Я знаю это! … Ты мне так надоел. Вы думаете, что знаете все.Вы остановите это? Пожалуйста.
Доктор Лиам Нисам: Ну да. Технически это хайку, но скорее пешеходное, не так ли?
(Джон Литгоу и Джон Клиз в «Мэри любит Скучи: Часть 2. » 3-й камень от Солнца , 15 мая 2001 г.)
» 3-й камень от Солнца , 15 мая 2001 г.)
«Рабская забота о составе слов – признак обанкротившегося интеллекта. Уходи, гнусная оса! От тебя пахнет сгнившими слогами».
(Нортон Джастер, Призрачная переговорная будка , 1961)
Английский язык: язык с упором на время – Rachel’s English
В некоторых языках все слоги имеют одинаковую длину.По-английски делать слоги одинаковой длины очень неудобно. Важно иметь контраст, несколько длинных и несколько коротких слогов.
YouTube заблокирован? Нажмите здесь, чтобы посмотреть видео.
Видео Текст:
В этом видео с произношением в американском английском мы рассмотрим, почему некоторые слова звучат иначе, когда они произносятся сами по себе, чем когда они произносятся как часть предложения, например ‘for’, ‘fer’. .
.
Многие люди, когда они изучают язык и не знакомы с ним, думают, что им нужно произносить каждое слово полностью и четко, чтобы их хорошо понимали. Но на английском это совсем не так. Английский язык подвержен стрессу. Это означает, что некоторые слоги будут длиннее, а некоторые короче. Однако многие языки синхронизированы по слогам, что означает, что каждый слог имеет одинаковую длину. Примеры языков с синхронизацией по слогам: французский, испанский, кантонский диалект. Итак, когда американец слышит предложение на английском языке, в котором каждый слог имеет одинаковую длину, ему требуется немного больше времени, чтобы понять его значение.Это потому, что мы привыкли к ударным слогам, слогам, которые выскакивают из строки, потому что они длиннее и имеют большую форму. Наши уши, наши мозги обращаются к этим словам. Это слова содержания. Когда все слоги имеют одинаковую длину, ухо не может определить, какие слова наиболее важны.
Вот почему ударение так важно в американском английском. Это язык, рассчитанный на стресс. Когда вы придаете нам красивую форму в своих ударных слогах, вы передаете нам значение предложения.Это означает, что другие слоги должны быть безударными – более плоскими, более быстрыми, – чтобы ударные слоги воспринимались ухом. Вот почему так важно сократить число служебных слов, которые могут сокращаться в американском английском. Когда эти служебные слова являются частью целого, частью предложения, они произносятся по-разному. Давайте посмотрим на несколько примеров.
Это язык, рассчитанный на стресс. Когда вы придаете нам красивую форму в своих ударных слогах, вы передаете нам значение предложения.Это означает, что другие слоги должны быть безударными – более плоскими, более быстрыми, – чтобы ударные слоги воспринимались ухом. Вот почему так важно сократить число служебных слов, которые могут сокращаться в американском английском. Когда эти служебные слова являются частью целого, частью предложения, они произносятся по-разному. Давайте посмотрим на несколько примеров.
—-. Ты знаешь о чем я говорю? Носитель языка тоже не может. Но в контексте предложения «Я иду в магазин» носитель языка будет точно знать, что я говорю.Я иду в магазин. Я иду в магазин. Когда ‘to the’ произносится — (сокращается и связывается), «собираюсь» и «хранить» становятся очевидными словами в этом предложении. Я иду в магазин.
А как насчет —-? Вы понимаете, о чем я говорю? Носитель языка тоже не может. Но во фрагменте предложения «Из-за моей работы» «Из-за моей работы» носитель языка будет точно знать, что я говорю. Из-за моей работы. Из-за моей работы. «Потому что» и «из» настолько безударны, настолько сокращены и низко по тону, что слово «работа» действительно может выпрыгнуть из предложения.Из-за моей работы.
Из-за моей работы. Из-за моей работы. «Потому что» и «из» настолько безударны, настолько сокращены и низко по тону, что слово «работа» действительно может выпрыгнуть из предложения.Из-за моей работы.
Это действительно имеет первостепенное значение в американском английском произношении. Работая над произношением, помните, что слово является частью целого.
Слово «для»: часть слова превращается в fer, fer, fer you, fer me, fer обед. Практикуйте это таким образом. Сверлите это снова и снова. Другие слова, которые могут сокращаться: «и» может стать «н». «Они» могут стать «тум» или «эм». «Ат» может стать «ут». «То» может превратиться в «ту» или «ду». «Кан» может стать «кун», «кун».«Аре» может стать «эр», «эр». «Was» может стать «wuz», «wuz». «То» может превратиться в «там», «там». «Ваш» может стать «yer», «yer». «At the» может стать «ut the», «ut the». И так далее. Так что следите за этим, когда изучаете произношение и слушаете носителей языка.
Вот и все, и большое спасибо за использование Рэйчел английского.
Я рад сообщить, что провожу еще один онлайн-курс, так что за подробностями обращайтесь на мой сайт. Там вы найдете всевозможную информацию о курсе, о том, кто должен пройти курс, и о требованиях.Я очень надеюсь, что вы это попробуете и подумаете о регистрации. Я получил удовольствие от своего первого онлайн-курса и с нетерпением жду возможности познакомиться с вами.
Не останавливайтесь на достигнутом. Получайте удовольствие от моих реальных английских видео. Или почувствуйте себя более комфортно с IPA в этом плей-листе. Узнайте об онлайн-курсах, которые я предлагаю, или посмотрите мое последнее видео.
Видео:
WALS Online – Структура слогов главы
1. Введение
Размер наборов согласных и гласных, образующих сегментный инвентарь языков, обсуждался в главах 1 и 2.Помимо количества сегментов, используемых в языках, также важно учитывать способы, которыми сегменты могут сочетаться друг с другом при образовании более длинных структур, таких как слова и слоги. Некоторые языки позволяют очень свободно комбинировать сегменты, в то время как в других комбинации сильно ограничены. В этой главе будет обсуждаться сложность последовательности сегментов в слогах как средство изучения одного важного аспекта того, как комбинация отдельных звуков управляется в выбранном наборе языков.
Некоторые языки позволяют очень свободно комбинировать сегменты, в то время как в других комбинации сильно ограничены. В этой главе будет обсуждаться сложность последовательности сегментов в слогах как средство изучения одного важного аспекта того, как комбинация отдельных звуков управляется в выбранном наборе языков.
Слог – хорошо известная единица в лингвистическом анализе, которая довольно хорошо объясняет количество ритмических единиц, которые будут восприниматься в слове или более длинном высказывании. Это число обычно равно количеству гласных в высказывании. Хотя обычно легко прийти к соглашению о количестве слогов, присутствующих в слове, интуиция иногда расходится по поводу того, где следует разместить границы между одним слогом и другим. Несмотря на такие колебания, слог оказался очень полезным понятием при обсуждении общих правил распределения звуков в языках.В тех случаях, когда слушатели различаются по слогам отдельных слов, обычно обе возможные слоги могут быть показаны как разрешенные, поскольку могут быть найдены однозначные случаи каждого типа. Например, такое английское слово, как кондитерских изделий , может быть слоговым для разных говорящих как past.ry или как pas.try (где точка представляет собой разделение между слогами). Поскольку и paste , и tree являются вполне приемлемыми односложными словами английского языка, любое разделение согласуется с более широким правилом, касающимся возможных слогов английского языка.Широчайшие правила такого рода для любого данного языка описывают то, что называется каноническим слоговым паттерном языка. Это образец, который по сути характеризует, сколько согласных может стоять перед гласным слогом и сколько после гласного.
Например, такое английское слово, как кондитерских изделий , может быть слоговым для разных говорящих как past.ry или как pas.try (где точка представляет собой разделение между слогами). Поскольку и paste , и tree являются вполне приемлемыми односложными словами английского языка, любое разделение согласуется с более широким правилом, касающимся возможных слогов английского языка.Широчайшие правила такого рода для любого данного языка описывают то, что называется каноническим слоговым паттерном языка. Это образец, который по сути характеризует, сколько согласных может стоять перед гласным слогом и сколько после гласного.
2. Определение значений
Канонические слоги чаще всего представлены в виде цепочки символов C и V, где C обозначает согласный звук, а V – гласный звук (включая любые сложные гласные элементы, такие как дифтонги, которые могут встречаться в языке).Единственный вид слога, который встречается в каждом языке, – это CV, то есть слог, состоящий только из одного согласного, предшествующего гласному. В относительно небольшом количестве языков это единственный разрешенный тип слога. К таким языкам относятся гавайский и мба (адамава-убангийский, Нигер-Конго; Демократическая Республика Конго). Чаще встречаются языки, в которых разрешено не иметь начального согласного, как, например, в фиджийском, игбо (Нигер-Конго; Нигерия) и яребе (Яребан; Папуа-Новая Гвинея).Для этих языков канонический слог может быть представлен как (C) V, круглые скобки указывают, что начальный согласный является необязательным элементом. Если язык допускает только слоги, которые соответствуют этому шаблону, будет сказано, что язык имеет простую структуру слогов .
В относительно небольшом количестве языков это единственный разрешенный тип слога. К таким языкам относятся гавайский и мба (адамава-убангийский, Нигер-Конго; Демократическая Республика Конго). Чаще встречаются языки, в которых разрешено не иметь начального согласного, как, например, в фиджийском, игбо (Нигер-Конго; Нигерия) и яребе (Яребан; Папуа-Новая Гвинея).Для этих языков канонический слог может быть представлен как (C) V, круглые скобки указывают, что начальный согласный является необязательным элементом. Если язык допускает только слоги, которые соответствуют этому шаблону, будет сказано, что язык имеет простую структуру слогов .
Чуть более сложная структура слога добавила бы еще один согласный, либо в конце слога, либо в его начале, давая структуры CVC и CCV; это оба скромные расширения типа простого слога CV.Но стоит различать два типа двух согласных строк. В очень большом количестве языков, хотя два согласных разрешены в начале слога, существуют строгие ограничения на то, какие виды сочетаний разрешены. Второй из двух согласных обычно ограничивается одним из небольшого набора, принадлежащего либо к классу «жидкостей», либо к классу «скользящих». Жидкости – это звуки, которые обычно обозначаются буквами r и l , а скольжения – это согласные, подобные гласным, например, в начале английских слов wet и еще .Жидкости и скольжения объединяет то, что они производятся с такой конфигурацией органов речи, которая обеспечивает относительно беспрепятственный поток воздуха изо рта. Языки, которые допускают наличие единственной согласной после гласной и / или допускают появление двух согласных перед гласной, но подчиняются ограничению только для общих двух согласных структур, описанных выше, считаются имеющими умеренно сложную структуру слогов . Примером может служить Дараи (индоарийец; Непал). Здесь наиболее сложным разрешенным слогом является CCVC, например / bwak / «(его) отец», но единственный возможный второй согласный в последовательности из двух – / w /.
Второй из двух согласных обычно ограничивается одним из небольшого набора, принадлежащего либо к классу «жидкостей», либо к классу «скользящих». Жидкости – это звуки, которые обычно обозначаются буквами r и l , а скольжения – это согласные, подобные гласным, например, в начале английских слов wet и еще .Жидкости и скольжения объединяет то, что они производятся с такой конфигурацией органов речи, которая обеспечивает относительно беспрепятственный поток воздуха изо рта. Языки, которые допускают наличие единственной согласной после гласной и / или допускают появление двух согласных перед гласной, но подчиняются ограничению только для общих двух согласных структур, описанных выше, считаются имеющими умеренно сложную структуру слогов . Примером может служить Дараи (индоарийец; Непал). Здесь наиболее сложным разрешенным слогом является CCVC, например / bwak / «(его) отец», но единственный возможный второй согласный в последовательности из двух – / w /.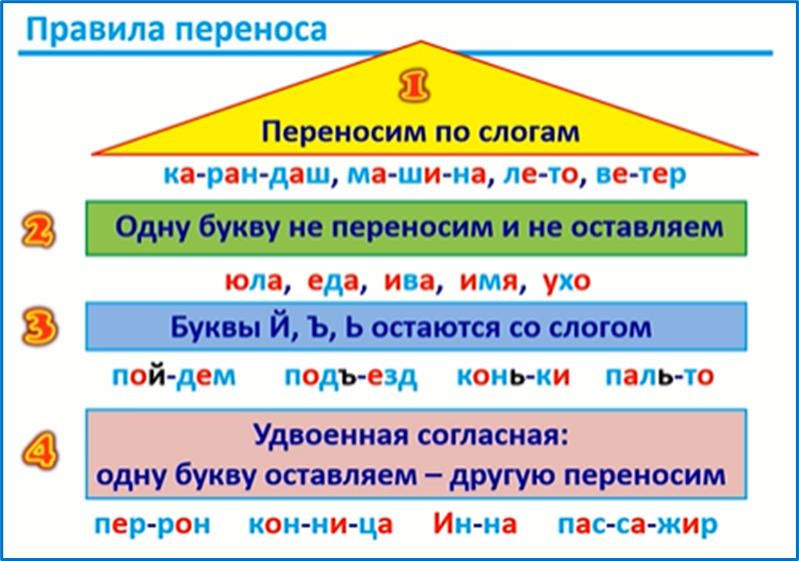
Языки, которые допускают более свободные комбинации двух согласных в позиции перед гласной или которые допускают три или более согласных в этой начальной позиции и / или два или более согласных в позиции после гласной, классифицируются как имеющие сложную структуру слогов. . Очевидным примером сложной структуры является английский язык, канонический слог которого часто цитируется как (C) (C) (C) V (C) (C) (C) (C). Полное раскрытие паттерна происходит только в нескольких словах, таких как силы , когда произносится / stɹɛŋkθs /, но относительно легко найти слоги, начинающиеся с трех согласных или заканчивающиеся четырьмя, как в , разделенном на тексты и . (/ tɛksts /).
Классификация языков на три категории слоговой сложности, простые, средние и сложные, естественно, не учитывает многие другие вопросы распределения сегментов (например, имеют ли слоги в начале и в конце слова такие же или разные ограничения по сравнению с теми, которые внутреннее по отношению к словам), и должен скрыть некоторые важные различия в отношении того, насколько редко или часто более сложные типы слогов встречаются в данном языке. При принятии решений относительно того, как классифицировать данный язык, использовалась определенная гибкость здравого смысла.Например, если некоторые виды согласных последовательностей только недавно были введены в язык в результате заимствования международных слов (таких как спорт или гольф ), язык будет классифицирован на основе того, что встречается в более устоявшейся лексике. . Несмотря на свой сводный характер, трехсторонняя классификация обеспечивает полезную группировку с интересными географическими характеристиками.
При принятии решений относительно того, как классифицировать данный язык, использовалась определенная гибкость здравого смысла.Например, если некоторые виды согласных последовательностей только недавно были введены в язык в результате заимствования международных слов (таких как спорт или гольф ), язык будет классифицирован на основе того, что встречается в более устоявшейся лексике. . Несмотря на свой сводный характер, трехсторонняя классификация обеспечивает полезную группировку с интересными географическими характеристиками.
| Перейти к карте | ||
|---|---|---|
| Значение | Представление | |
| Простая структура слогов | 61 | |
| Умеренно сложная слоговая структура | 274 | |
| Сложная слоговая структура | 151 | |
| Итого: | 486 | |
3.
 География распространения
География распространения Безусловно, наиболее распространенным типом являются языки с умеренно сложной структурой слогов, составляющие около 56,5% выборки. Этот тип, конечно, широко распространен, но особенно часто встречается в Африке, более восточной части Азии и большей части Австралии. Только 61 (около 12,5%) языков в выборке не ограничиваются ничем более сложным, чем универсальный слоговый тип CV. 150 языков (около 30,9% от общего числа) допускают сложные слоги одного или нескольких типов.Языки с простой слоговой структурой, как правило, распространены где-то недалеко от экватора, в Африке, Новой Гвинее и Южной Америке. Напомним, что это распределение довольно похоже на то, что было обнаружено для языков с небольшим набором согласных. Языки со сложной слоговой структурой преимущественно встречаются в северных двух третях северного полушария, то есть в северной части Северной Америки и северной Евразии, где этот тип фактически доминирует над другими. Здесь есть степень совпадения с областями, в которых большие запасы согласных обычно встречаются чаще, особенно в более северных частях североамериканского континента. Меньший кластер языков со сложной слоговой структурой находится в северной Австралии.
Меньший кластер языков со сложной слоговой структурой находится в северной Австралии.
4. Корреляции
Упомянутые выше пространственные совпадения между небольшими наборами согласных и простой структурой слогов, а также большими наборами согласных и сложными структурами слогов представляют собой интересный пример того, как сложность в различных областях фонологической структуры может работать вместе как взаимное усиление, а не взаимно компенсировать. В наборе из 484 языков, для которых включены данные как о размере согласных, так и о структуре слогов, существует значимая, хотя и не сильная корреляция между этими двумя показателями сложности (коэффициент корреляции составляет.203, а уровень статистической значимости очень высок, p <0,0001). Языки с простой канонической структурой слогов имеют в своем инвентаре в среднем 19,1 согласных, языки с умеренно сложной структурой слогов имеют в среднем 22,0 согласных, а языки со сложной структурой слогов имеют в среднем 25,8 согласных. Как обсуждалось в главе 13, сложность структуры слогов не демонстрирует аналогичного паттерна положительной корреляции со сложностью тональной системы.
Как обсуждалось в главе 13, сложность структуры слогов не демонстрирует аналогичного паттерна положительной корреляции со сложностью тональной системы.
Следует отметить, что установленные здесь закономерности ассоциации между структурой слогов и объемом согласных звуков несомненно, по крайней мере частично, являются отражением перекрывающегося географического распределения свойств, отмеченного в § 3, и это совпадение может быть связано с случайным распределением. генеалогически общих или ареальных особенностей.Анализ закономерностей внутри и между различными языковыми областями и языковыми семьями может потребоваться, чтобы решить, следует ли связывать эту ассоциацию с случайностями выживания и распространения определенных языков, или ее можно предложить как отражающую конструктивную особенность языка, рассматриваемого как единое целое.
Если вы хотите говорить свободно, думайте по слогам
Когда вы слышите речь, вы сначала обрабатываете звуки, а затем преобразовываете их в мысленные абстракции, называемые «словами». Другими словами (это не каламбур), слов – всего лишь плод нашего воображения .
Другими словами (это не каламбур), слов – всего лишь плод нашего воображения .
Поскольку слова не имеют физической реальности для них, это создает ряд сложностей для тех, кто сосредоточивает свои исследования иностранного языка исключительно на словах. Фактически, основная причина, по которой большинство людей борются с иностранными языками, заключается в том, что они слишком много внимания уделяют словам, а не звукам.
Позвольте мне объяснить…
Слова воображаемы
Это утверждение всегда вызывает у людей скептицизм, потому что наша система образования на самом деле основывается на идее, что слова являются фундаментальными строительными блоками языка.
Все дело в системе письма и ее предпочтении семантике (значению) над акустикой (звуком). В большинстве систем письма элементы семантически разделяются с помощью визуальных пространств. Итак, нас учат думать обо всем, что находится между пробелами (то есть о словах), как о связанных объектах.
- Символ «s» после апострофа предполагает звук / s / «ssssss», но если вы снова послушаете трек с пониженной скоростью, вы услышите, что я на самом деле издаю звук / z / (zzzz).
- Буква «c» в слове «doctrine» предполагает наличие звука / k /, но прислушайтесь внимательно, и вы заметите, что вместо / k / есть просто пауза между «do» и « трин ».
А теперь вот причудливая часть – , если бы перед всем этим анализом я спросил вас, издавал ли я звук / k / и / s /, вы бы сказали «да».
Вот что я имею в виду, когда говорю «слова воображаемы». Вы берете физическую реальность звуков и слогов и искажаете ее, чтобы она соответствовала «словам», которых на самом деле никогда не было.
Почему мы это делаем?
Грамотность и ее недостатки
Искажение звука речи связано с обучением грамоте. Любая «фонетическая» система письма, такая как английский, будет иметь только , примерно , в зависимости от того, как вещи действительно звучат. Итак, когда мы учимся обрабатывать язык только в рамках этих систем, у нас остается лишь слабое представление о том, что такое речевой звук на самом деле.
И мы действительно укоренились в этом непонятном понимании. С самого раннего возраста мы погружены в мир письменных слов. Каждый раз, когда мы видим слово в книге, на экране компьютера или уличном указателе, мы усиливаем эту свободную систему звука и сценария. К тому времени, когда мы станем взрослыми, система будет усилена триллионы раз!
Конечным результатом является то, что никто не знает, о чем они, черт возьми, говорят, когда говорят о звуках речи.
Как грамотные взрослые, мы разработали очень сильную концептуальную концепцию звука, которая в корне ошибочна. Поэтому неудивительно, что выучить совершенно новую систему звуков на иностранном языке так сложно.
Поэтому неудивительно, что выучить совершенно новую систему звуков на иностранном языке так сложно.
Слоги реальны
Что, если бы вместо того, чтобы думать о речи в терминах воображаемых слов, мы думали о ней в конкретных физических терминах? У каждого уникального звука будет свой уникальный символ, и группировка этих символов будет отражать акустические группировки в реальном мире.
Это то, что пытается сделать фонетическая транскрипция . Существует довольно много систем фонетической транскрипции, но я считаю, что большинство из них не подходят для изучения языка, поэтому я придумал свою собственную – «Ритмическую фонетическую нотацию».«Вы многое узнаете о RPN из будущих публикаций в блогах или если вы пройдете один из моих курсов Flow Series.
Вот как RPN расшифровывает более раннюю фразу «Мимикрия – моя доктрина»:
mɪ mɪ – kɹi zmaɪ dɑ – tɹɪn
Вы, вероятно, не знакомы с символы, но с интервалом вы должны услышать, как он совпадает с исходным звуком.
Ритмично пробелы обозначаются тире, а ударные слоги – подчеркиванием и подчеркиванием.Фонематически я использую в основном IPA для представления звуков, но иногда я использую свои собственные символы, когда я думаю, что символ IPA сбивает ученика с толку из-за его родного языка.
Здесь важно отметить, что, в отличие от английской письменной системы, каждый сценарий соответствует определенному звуку и мышечному движению в речевом органе.
Поскольку каждый звук имеет один уникальный символ, и каждый символ имеет один уникальный звук, нет двусмысленности . Идея состоит в том, чтобы человек, знакомый с символами и мышечными движениями, которые они изображают, мог повторить речь вслух почти безупречно, не слыша ее, точно так же, как музыкант может взять отрывок из нот и заново повторить его. точно создавать звуки.
Это чрезвычайно важно для изучающих язык, потому что не оставляет места для акустической двусмысленности, когда весь язык основан на звуке.
Мыслить по слогам
Часть моей способности к мимикрии проистекает из моей способности мысленно преобразовывать речь в ритмическую фонетическую нотацию. Когда я знаком с потоком языка, я знаком со всеми его звуковыми возможностями. Итак, когда мне предлагают фразу и я не понимаю, что она означает, я все равно могу ее разбить и воспроизвести.
Это незаменимый навык, связанный с повседневной «связанной речью», в которой «слова» часто рубятся, скручиваются и сливаются друг с другом, что делает их неузнаваемыми для любого, кто применяет «словесный подход» ко второму языку. обучение.
Однако, чтобы научиться мыслить слогами, нужно время и специальная подготовка. Это обучение, которое я даю людям на своих курсах Flow Series. На курсах студенты разучивают песни по слогам, не имея ни малейшего представления о границах слов или их значениях.Сначала они немного удивлены сложностью и уникальностью тренировки, но как только они преодолевают препятствия, они сразу же осознают ценность тренировки.