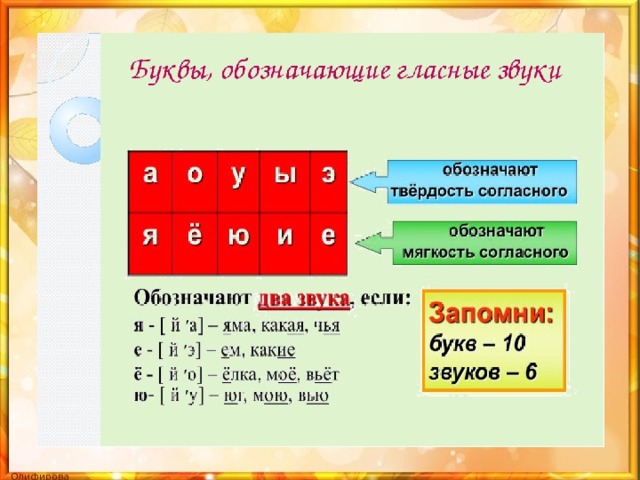
Таблица звуки и буквы в русском языке 2 класс: Звуки и буквы – таблица произношения и правописания (2 класс, русский язык)
Конспект урока русского языка “Звуки и буквы”; 2 класс – Русский язык – Начальные классы
Предмет-русский язык, 2 класс
Учитель- Ларионова Т.В., учитель высшей категории
Тема : Звуки и буквы
Педагогические цели:
Создать условия для повторения и уточнения представлений учащихся о звуках и буквах, ознакомления с правописанием словарного слова октябрь; способствовать формированию умения различать звуки и буквы, обозначать звуки буквами на письме, использовать условные звуковые обозначения слов
Тип урока
Решение частной задачи
Планируемые результаты (предметные)
Осваивают первоначальные представления о системе и структуре русского языка: фонетике и графике, лексике, об основных единицах языка, их признаках и особенностях употребления в речи
Личностные результаты:
Принимают и осваивают социальную роль обучающегося, имеют мотивацию к учебной деятельности и осознают личностный смысл учения
Универсальные учебные действия (метапредметные)
 , взаимовыручке
, взаимовыручкеПознавательные: общеучебные – извлекают необходимую информацию схем; знакомятся с базовыми предметными понятиями, отражающими существенные связи и отношения между объектами и процессами; логические – осуществляют сравнение, анализ.
Коммуникативные: проявляют готовность конструктивно разрешать конфликты посредством учёта интересов сторон и сотрудничества
Основное содержание темы, понятия и термины
Звуки и буквы. Различие звуков и букв. Звуки и их обозначение буквами на письме. Условные обозначения слов. Замена звука буквой и наоборот. Слово с непроверяемым написанием октябрь
Образовательные ресурсы
Схема «Звуки». Презентация к уроку. Электронное приложение по теме « Звуки и буквы», физминутки для глаз по Галкиной.
Оборудование:
Мультипроектор, интерактивная доска.
Комплект методических материалов программы УМК « Школа России»:
1. Канакина, В. П. Русский язык. 2 класс: учеб. для общеобразоват. организаций.В 2 ч. / В. П. Канакина, В. Г. Горецкий. – М.: Просвещение, 2015.
2 класс: учеб. для общеобразоват. организаций.В 2 ч. / В. П. Канакина, В. Г. Горецкий. – М.: Просвещение, 2015.
2. Ситникова Т.Н., Яценко И..Ф., Васильева Н.Ю.
Поурочные разработки по русскому языку.2 класс.-М.: ВАКО, 2015.-368с.- ( В помощь школьному учителю)
3. Диск по учебнику В.П. Канакиной, В.Г. Горецкого « Русский язык.2 класс» (М., 2014)
Ход урока
1 Орг. момент
Сегодня мы с вами продолжаем путешествие по Стране Русского Языка. Чтобы путешествие было полезным и интересным, а знания и умения вы могли бы применить в жизни, вам необходимо быть внимательными и активными.
Ну, а теперь мы все вместе отправляемся в путь.
Посмотрите, что это? ( Верно) Перед нами ворота в страну русского языка. Чтобы попасть в волшебную страну, надо всем писать красиво и аккуратно в своих тетрадках. Давайте приготовим пальчики к работе. Посмотрите на экран и повторяйте упражнения.
Ребята, открываем тетради и старательно пишем. Откройте тетради и запишите:
Откройте тетради и запишите:
22 октября.
Классная работа.
– Какие буквы записаны?
– Что мы о них знаем? ( Они не обозначают звуков. Мягкий знак – показатель мягкости)
( Верно, молодцы)
А теперь пропишите буквы, чередуя, до конца строчки.
… Молодцы. Постарались и как видите ворота в страну РУССКОГО ЯЗЫКА для нас открылись..
3. Постановка учебной задачи
Но дорогу нам преграждает стена, да необычная, а СТЕНА РАЗМЫШЛЕНИЙ. Мы вместе сможем преодолеть её, если, прослушав сказку, вы догадаетесь, о чём пойдёт речь на уроке. Сказку нам сегодня расскажет Катя.
Жили-были звуки… Надоело им летать по белому свету невидимками. «Что же это такое? -стали размышлять звуки. – Нас любят, без нас не могут обойтись ни звери, ни птицы, ни растения. А ведь человек и дня не может прожить без того, чтобы не использовать нас в речи. И как жаль, что при этом нас никто не видит! Надо что-то делать! » И решили звуки сшить себе костюмчики. Пусть они, хотя и будут невидимками, но в костюмчиках всегда будут видны. Не простые получились костюмчики, а с характером. Звуки назвали их буквами.
Пусть они, хотя и будут невидимками, но в костюмчиках всегда будут видны. Не простые получились костюмчики, а с характером. Звуки назвали их буквами.
Ребята, я надеюсь, что вы догадались, о чём мы будем говорить на уроке? ( О звуках и буквах)
Верно, тема нашего урока: « Звуки и буквы».
Как вы думаете, чему мы должны научиться?
В учебнике на стр.78 мы найдём главный вопрос, на который должны ответить на уроке.Откройте учебники. Прочитаем его хором
( Как различить звуки и буквы?)
Мы справились с этим заданием и можем двигаться дальше.
А что это перед нами? ( Город звуков и букв. ) Жители города готовились к встрече с вами и заранее приготовили для вас интересные, но непростые задания. Чтобы попасть в город, мы должны рассказать, что мы уже знаем о звуках и буквах.
4 .Работа по теме
1. Беседа о звуках и буквах
– А что вы знаете о буквах? ( Буквы мы видим и пишем).- Хорошо.

– А о звуках? (Звуки мы произносим и слышим.). Правильно
Сейчас я предлагаю вам следующее задание. Я начну, а вы должны продолжить предложения:
Звуки бывают….( гласные и согласные)
Гласные звуки бывают …..( ударные и безударные)
Согласные звуки бывают……( звонкие и глухие, твёрдые и мягкие,).
Молодцы, мы смогли войти в ГОРОД ЗВУКОВ и БУКВ
Физкультминутка для глаз
Давайте посмотрим , что там происходит
Слушайте и следите глазами за движущимися предметами. Дети, что вы увидели? ( В этой стране тоже осень ) А что услышали? ( Шум ветра)
Вижу, что вы готовы и смотреть, и слушать, значит ваши знания о звуках и буквах помогут вам узнать новое словарное слово
2.Словарная работа . Звуко-буквенный разбор
Слушайте внимательно и тогда обязательно справитесь
Произнеси второй звук слова « кот».
Произнесите первый звук в слове «карусель» («К»)
Произнесите второй слог в слове «утята»
Произнесите парный согласный звуку «П».
 («Б»)
(«Б»)Произнесите последний звук в слове «сентябрь» «Р»)
Какое опасное место в слове надо запомнить?(О) Попробуйте придумать , как эту букву можно запомнить.
Если трудно можете воспользоваться подсказкой на слайде.( В октябре холодно, мокро, октябрь -это уже осень. Во всех словах, связанных по смыслу с этим словом под ударением о. Так можно запомнить, что и в этом слове надо писать букву о)
Напишем слово октябрь с большой буквы, с красной строки также красиво и правильно.
У доски работает Карина. Комментируй.
– Разделите слово на слоги, поставьте ударение, подчеркните букву, которую надо запомнить.
Назови все буквы в слове правильно по порядку.
Продолжаем работу над словом. Звукобуквенный разбор на доске выполнит Володя, все остальные работают в тетрадях.
Почему звуков меньше? ( Мягкий знак звука не обозначает)
Дайте характеристику второму звуку, если надо, пользуйтесь памяткой ( Звук [к] – согласный, он глухой парный, твёрдый парный).
Мы с вами поработали над написанием названия ещё одного осеннего месяца. Давайте используем его в своей речи и придумаем с ним предложение.
( В октябре много холодных дождливых дней) Молодцы.
Осень вдохновляла многих поэтов, писателей и художников.
Посмотрите как изобразил осень народный художник Башкирии (Александр Данилович ) Бурзянцев в своей картине «Урал осенний. Осень в горах».
А вот какое замечательное стихотворение написала башкирская поэтесса Гульфия Юнусова. Послушайте
“Падают листья”
Первым вестником зимы
Снег кружится мелкий.
Листья падают с дубов
Рыжие, как белки.
Плотно, будто бы ковром,
Корни укрывают.
Так по-своему они
Землю утепляют.
Посмотрите на экран, перед вами отрывок из стихотворения знаменитого русского поэта А.С. Пушкина.
Вставьте подходящее по смыслу слово:
( Декабрь, май, октябрь) уж наступил- уж осень отряхает
Последние листы с нагих своих ветвей.
А.С. Пушкин
Послушайте.
– Все ли слова понятны? (Нет. Что означает нагие? Нагие ветви – это значит голые, без листьев)
– А с каким чувством я читала? ( С грустью)
– Какое чувство вызвали у вас эти строки? ( Чувство грусти) Передайте это чувство интонацией.
(Молодцы.)
Выполните такое же задание во втором предложении.
В октябре, в октябре частый ( снег, град ,дождик ) на дворе.
С. Маршак
– Кто был внимателен и заметил словарное слово в этих отрывках, поднимите руку. Назови слово так , как мы его произносим. .А теперь , проговаривая по слогам так, как надо писать.( Октябрь)
Запишем второе предложение с комментированием. Комментирует Станислава.
– Читая строки вы озвучивали письменную речь . Из чего состоят слова письменной речи?( Из букв)
А слова устной речи? ( Из звуков)
Впереди много трудных заданий, давайте отдохнём.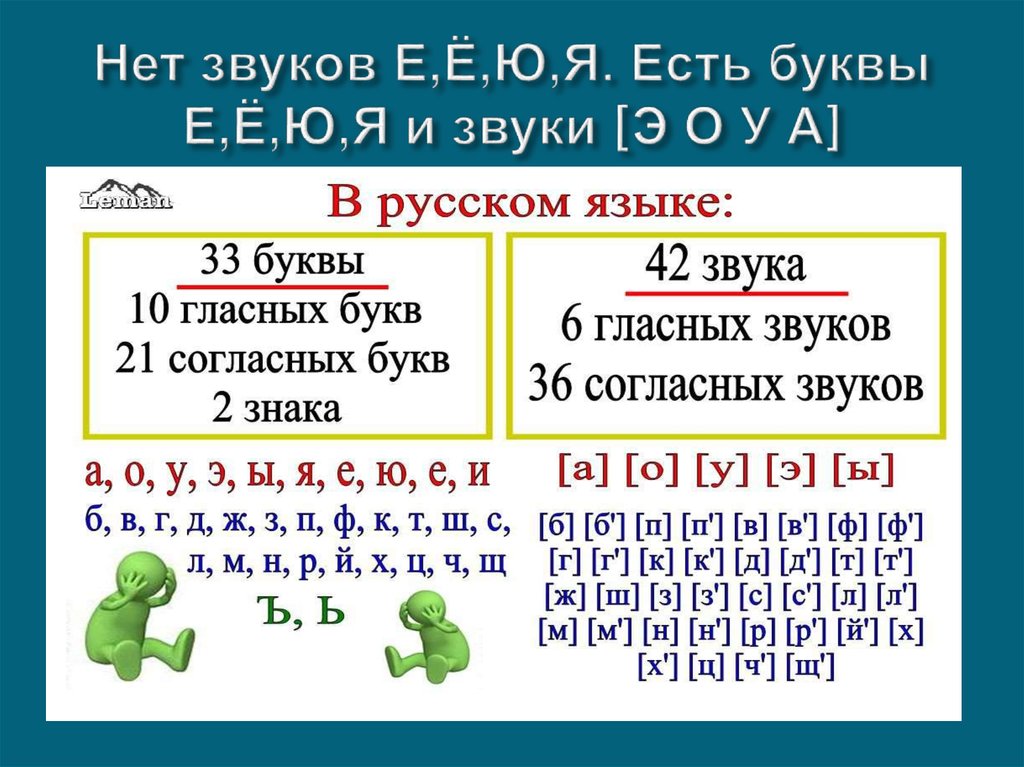
Продолжим работу по учебнику, будем тренироваться различать звуки
Найдите в учебнике упр.116 стр.78
Рассмотрите рисунки. Назовите предметы.
( шар, ложка, шарф, лодка)
Назовите слова, в которых встретились одинаковые звуки. Произнесите эти звуки (Шар и шарф
[ ш ], [ а ], [ р ] или лодка и ложка [ л ], [ о ], [ к ], [ а ])
Назовите слова, которые различаются одним звуком. Произнесите звуки, которыми различаются эти слова.
(лодка и ложка [ ш ], [ т ])
Теперь вы сможете помочь гномам починить дом.
Перетащите эти звуки к словам.
ложка лодка
[ д ], [ т ], [ ж ], [ ш ]
Орфографическая минутка
Звуки мы обозначаем буквами каждый раз, когда пишем под диктовку. Давайте потренируемся. Узнайте слова по транскрипции и напишите их. У доски будет работать Вика.
Помните, что в русском языке произношение и написание часто не совпадают.
Запись на карточках : [ лужы ], [ дажд’и ], [ гр’ас’ ]
Проверьте. Подчеркните опасное место.
Подчеркните опасное место.
На какое правило слово? Приведите свои примеры слов с таким сочетанием.
На какое оно правило? ( На проверяемую безударную гласную). Докажи. (Ударение падает на гласную и, безударная гласная О, потому что проверочное слово дождь)
А теперь вы возьмите веры с гласными буквами Е и И , покажите, что можете справиться с таким заданием.
Е/И
Река листва, земля, грибы.
Поднимите руку те, кто ни разу не ошибся.( Молодцы)
Ребята, тем, кто остался сидеть надо постараться быть внимательнее
Поставьте запятую и напишите последнее слово (грязь) На какое оно правило ? ( На проверяемую парную согласную.) Объясни написание опасного места.
( Парная согласная З, потому что , проверяю нет грязи)
Возьмите веры с согласными Ж и Ш , приготовьтесь правильно обозначать буквой последний звук и доказывать своё мнение.
Ж-Ш
Малыш, гараж, карандаш, ёж.
Вы справились с заданием и звуки приготовили для вас интересную игру» Эхо».
Сами звуки очень её любят. Я скажу слово, а вы хором вполголоса , как-будто вы эхо, назовите конец его так, чтобы у вас получилось новое слово
Смех, олень, клещ, сутки.
Молодцы, но пока мы играли со звуками..
Не давали буквам дело.
Им безделье надоело,
Надоело им скучать
И пошли озорничать.
И посмотрите, что из этого получилось.
Вы знаете, как важно, чтобы каждая буква стояла на своём месте. Давайте постараемся найти и вернуть на место заблудившуюся букву.
Сначала надо прочитать так, как написано, а потом, исправить ошибку.
« Буква заблудилась»
1) Утром бабушка к рубашке
Прибивала мне кармашки.( пришивала)
2)Закричал охотник : «Ой!»
Двери гонятся за мной. ( звери)
3) Сели в ложку и –айда!
По реке туда-сюда. ( лодку)
4) Мама с бочками пошла
По дороге вдоль села. ( дочками)
( дочками)
5) Тащит мышонок в норку
Огромную хлебную горку.( корку)
Молодцы, вы были внимательны и сумели помочь буквам вернуться на свои места. Продолжаем путь. Смотрите, что у нас впереди.
Работа над тестом « Звуки и буквы» в парах.
Впереди ВЕРШИНА ЗНАНИЙ, чтобы её покорить нам надо справиться с тестом.
Дети, скажите, как называют людей, которые покоряют горы? ( Альпинисты) Правильно.
А какие люди могут быть альпинистами? ( Смелые, отважные, которые всегда придут друг другу на помощь).
Друг за друга держаться, ничего не бояться.
Прочитайте пословицу. Скажите, как вы её понимаете? ( Вместе можно справиться с любой задачей)
Мы сейчас как альпинисты попытаемся покорить вершину знаний, а для этого нам надо справиться с тестом. Это самое сложное задание на уроке. Тесты мы только учимся делать, поэтому будем работать в парах, помните о взаимовыручке.
Обсудите и обведите правильные ответы. Кто выполнит работу, сядьте правильно.
Кто выполнит работу, сядьте правильно.
Тест по теме “Звуки и буквы”
1. Обведите слово, в котором количество букв и звуков совпадает: 1) уголь; 2) угол; 3) пеньки.
2 Обведите слово, в котором звуков больше, чем букв: 1) яма; 2) семья; 3) люк.
3 Обведите слово, в котором все согласные звуки твердые: 1) час; 2) щука; 3) жила.
4 Обведите слово, в котором все согласные звуки мягкие: 1) сияние; 2) цепи; 3) широко.
5. Обведите слово, в котором все согласные звуки глухие: 1) мышь; 2) степь; 3) затем.
6. Обведите слово, в котором все согласные звуки звонкие: 1) дома; 2) плащ; 3) гараж.
Проверяем. Если задание выполнено правильно, то перед цифрой ставьте плюс, если нет, то минус.
1 задание, правильный ответ угол…
Зажгите огоньки дружбы, если все задания выполнены без ошибок.
У кого была только одна ошибка?
Какое задание, которое показалось вам самым трудным? А какое было вас самым лёгким?
Те, кто сумел покорить вершину знаний молодцы. А те, у кого пока не всё получилось, не огорчайтесь на следующих уроках мы продолжим этому учиться.
А чтобы все задания получались, вы потренируетесь в домашнем упражнении. Откройте дневники, запишите : упр.119 стр.80 ( уч.), по желанию можно выполнить
звукобуквенный разбор выделенного слова.
Итог. Рефлексия
Сегодня наше путешествие по стране Русского Языка подошло к концу. Давайте подведем итог нашего урока.
Давайте подведем итог нашего урока.
На какой вопрос мы должны были ответить ?
Как же различить звуки и буквы?
Ребята, изучение этой темы не завершается на этом уроке, мы продолжим говорить о звуках и буквах и на следующих уроках
Давайте оценим свою работу на уроке. Если вы считаете, что со всеми заданиями на уроке вы легко справились, то для вас зажёгся зелёный свет, если не всё, то жёлтый. Если было очень трудно, то красный. Встаньте те, для кого зажёгся зелёный свет? .…жёлтый? …красный?
А я хочу отметить тех, кто на нашем уроке был особенно внимателен, активен, давал правильные ответы и помогал нам пройти все испытания. Это ……. Встаньте, пожалуйста.
Молодцы. Благодарю вас за работу. Садитесь
Ребята, вы были замечательными учениками. Спасибо за урок.
Конспект урока русского языка во 2 классе по теме “Звуки и буквы” | План-конспект урока по русскому языку (2 класс) на тему:
Урок русского языка во 2 классе
Тема: Звуки и буквы
Цель: обобщить и систематизировать знания о звуках и буквах, полученных в 1 классе
развитие умения различать звуки и буквы
Задачи урока:
- создать условия для обобщения знаний учащихся о звуках и буквах, их различии;
- создать условия для развития умения записывать транскрипцию слов и читать её;
- создать условия для развития умения работать в паре, для развития самоконтроля;
- создать условия для формирования приёмов умственных действий ( анализа, синтеза, сравнения, обобщения)
Планируемые предметные результаты:
- уметь различать букву и звук
- учиться записывать и читать транскрипцию слов
Планируемые метапредметные результаты:
- умение работать в паре ( коммуникативноеУУД)
- умение доказывать, аргументировать (познавательное УУД)
- умение осуществлять самоконтроль (регулятивное УУД)
Литература: учебник «Русский язык», автор В.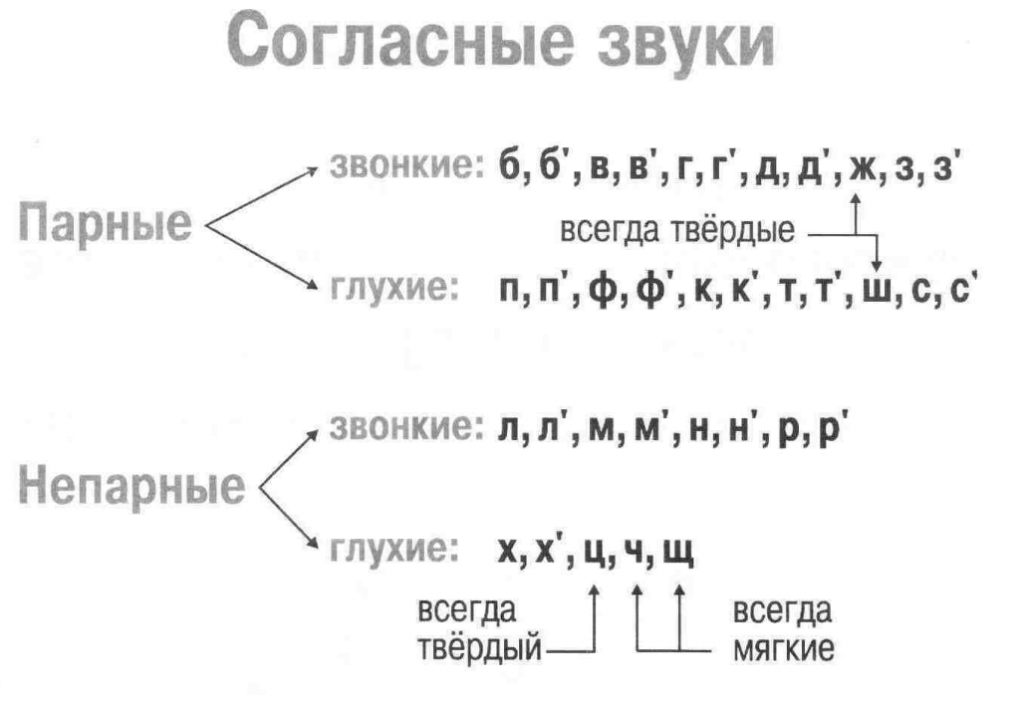 П.Канакина, В.Г.Горецкий, 2 класс, 1 часть
П.Канакина, В.Г.Горецкий, 2 класс, 1 часть
Ход урока
I.Организационный момент
Давайте настроимся на работу. Повторяйте за мной .
Мы – умные !
Мы – дружные !
Мы – внимательные !
Мы – старательные !
Мы отлично учимся !
Всё у нас получится !
– Повернитесь к гостям и поздоровайтесь с ними кивком головы.
Девиз: Грамоте учиться-всегда пригодится слайд
Вспомните, как правильно сидеть за партой при письме
II.Актуализация знаний.
1 Заглянула осень в сад –
Птицы улетели. На листах у детей + СЛАЙД
За окном с утра шуршат
Жёлтые метели.
– Подчеркните слова, которые употреблены в переносном значении. Объясните их значение.
Запишите слова, которые нельзя перенести с одной строки на другую. Докажите.
Какие правила переноса вы знаете? (пишем в тетрадях)
2. Словарная работа. слайд
– Отгадайте слово.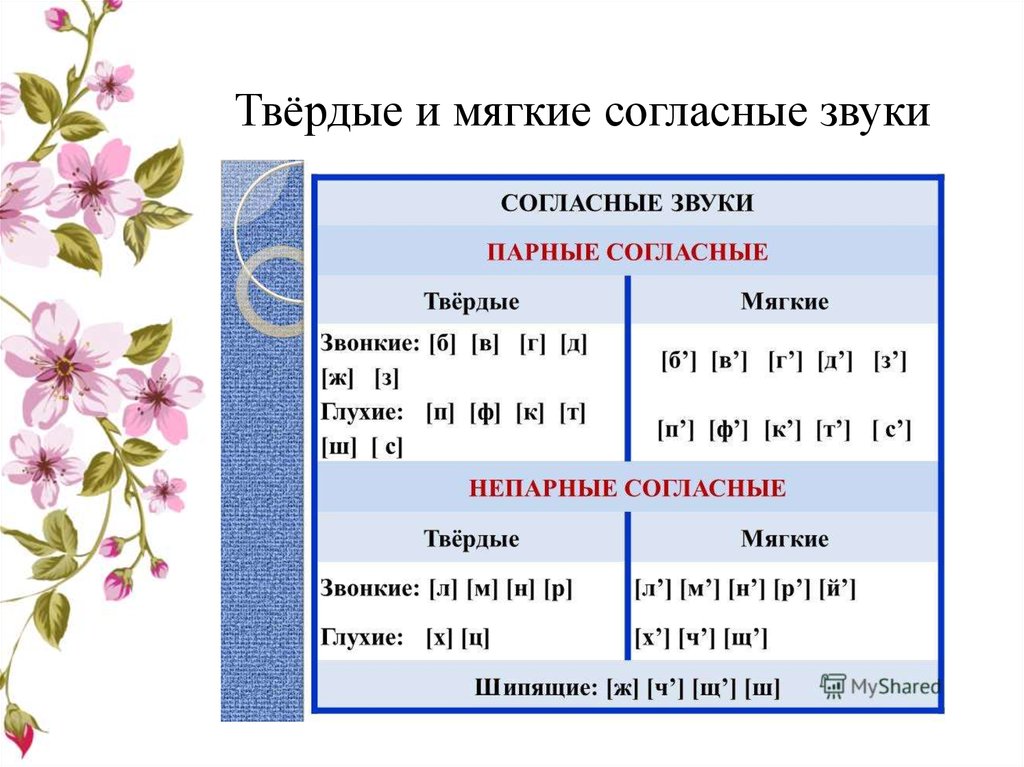
Первый слог, как в слове ОКНО
Второй слог, как в слове УТЯТА
Дальше идёт буква, обозначающая звонкий согласный, парный глухому П
Непарный звонкий согласный из слова ЖИРАФ
В конце слова буква ни гласная ни согласная.
– Назовите слово. ОКТЯБРЬ слайд
– Назовите лексическое значение этого слова ( десятый месяц в году, второй осенний месяц)
– Запишите, поставьте ударение, подчеркните безударную гласную.
– Разделите для переноса. ОК-ТЯБРЬ
Физминутка
III.Формулирование темы урока.
Загадки:
Его не видно,
В руки не взять,
Но зато слышно. (ЗВУК)
Чёрные, кривые,
От рождения немые.
Станут в ряд –
Враз заговорят. БУКВЫ
IV. Тема нашего урока: обобщить знания о звуках и буквах, их отличии.
1. Работа с учебником. Приём «инсерт», составление таблицы.
-Откройте учебник русского языка на стр.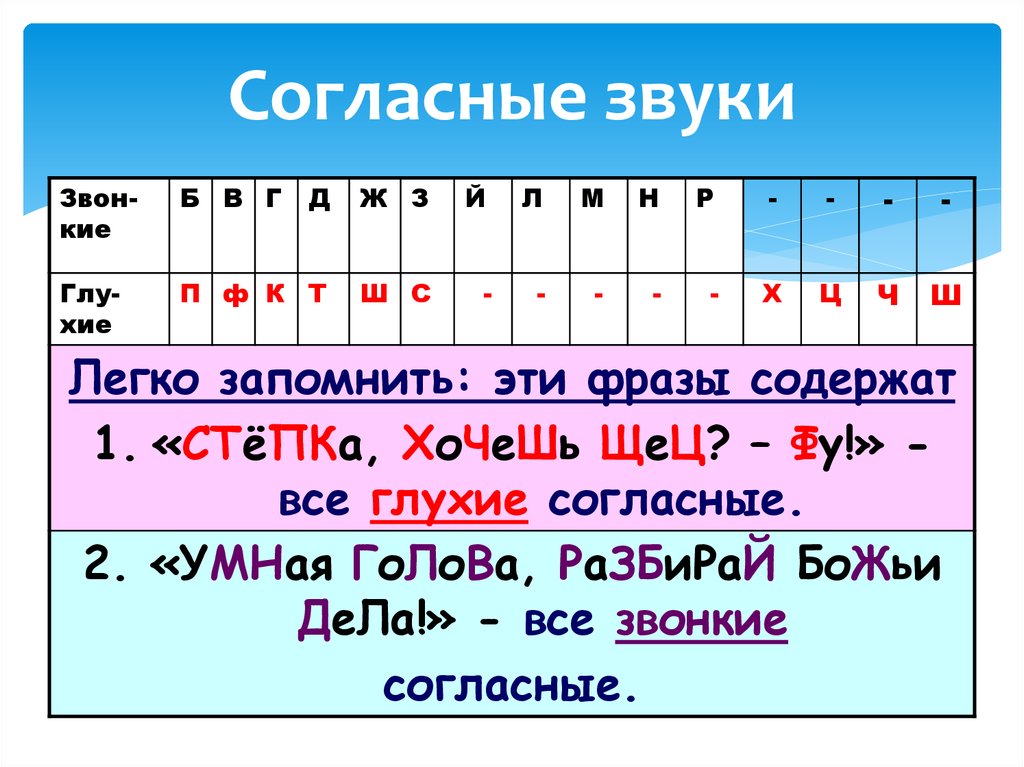 79.
79.
Прочитайте текст, делая пометки: «+» – знал, «!» – забыл. Найдите ответ на вопрос: «В чём различие буквы от звука».
Учащиеся читают текст.
– Поднимите руки, кто поставил знак «!». (Уточнить у детей, что именно они «забыли» и вспомнили после прочтения.)
-Нашли ли вы ответ на вопрос «В чём различие звука от буквы»?
После этого идёт обсуждение и заполнение таблицы: (СЛАЙД)
Звуки: Буквы:
произносим видим
слышим читаем
пишем
называем
2. Составление кластера.
– Давайте уточним все знания наши о звуках и буквах.
– На какие две группы делятся звуки русского языка? слайд
– Что вы знаете о гласных звуках? (их 6), а букв? (10).
– Почему? слайд
-Как вы думаете, чего больше: звуков ли букв и почему? (ребята отвечают и рассуждают)
3. Работа по учебнику (с.79, упр.118. Чтение, составление и запись слов с помощью букв и звуков (транскрипции).
-Как вы думаете, можно ли по- разному записать одно и тоже слово? (ребята делают свои предположения).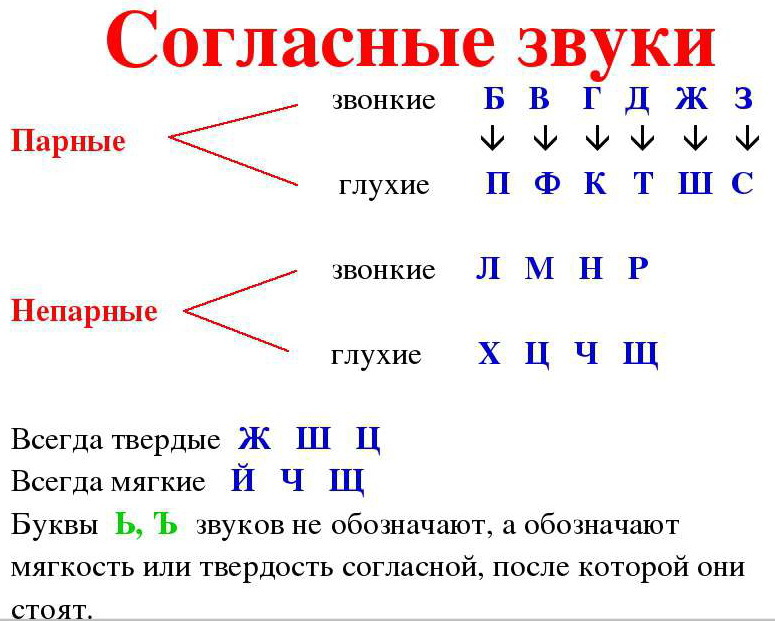
а)-Два ученика второго класса записали слова, но по-разному. Кто из них прав и одинаковые ли записаны слова? (слова записаны на листочках)
[й᾽олка] ёлка1
[м᾽ач᾽] мяч
[лошка] ложка
[пал᾽то] пальто
Ребята работают в парах и приходят к выводу, что правы оба ребёнка. Но один записал слова с помощью букв, а другой – звуками.
-Почему слова написаны по-разному? (произношение написание слов не совпадают)
Вывод: произношение и написание слов, количество звуков и букв могут не совпадать
-Как не допустить ошибки? (применить правила: обозначение йотированных гласных на письме, мягкости согласного звука с помощью гласной и ь знака, парной согласной, посмотреть в орфографическом словаре).
7.Физкультминутка
Хлопните в ладоши столько раз, сколько гласных в словах:
Дуб, пальто. Берёза, машина, дом,
б)- Попробуйте самостоятельно записать слова с помощью транскрипции. Определите количество букв и звуков. Упр.118
Определите количество букв и звуков. Упр.118
г) – Могут ли слова различаться одним звуком? слайд
– И что тогда измениться?
-Попробуйте составить в паре цепочку слов, различающихся только одним согласным звуком. Условие: можно заменять только один и тот же звук. (работа в тетради)
ДОМ – СОМ – СОН – ТОМ – ЛОМ
-Что изменилось при смене звука? (лексическое значение)
-А теперь измените гласный.
ДОМ – ДЫМ – ДАМ.
-Какой вывод мы сделаем?
-Проверьте, правильно ли мы сделали вывод? (стр. 80)
г)-Любое ли сочетание звуков можно назвать словом?
После ответов ребят им предлагается прочитать стихотворение Б Заходера (стр.80 упр. 120)
Было бы очень- очень мило,
Очень Умная Сова,
Если бы ты нам объяснила
Эти умные слова:
Энциклопедия!
Трагикомедия!
Кувырколлегия!
Рододендрон!
-Какие из выделенных «умных» слов настоящие, а какие нет? Как вы это определили?
Найдите в толковом словаре значение этих слов.
После обсуждения ребята получают задание придумать «ненастоящие» слова и попробовать их объяснить.
Вывод: любое слово обязательно несёт своё лексическое значение.
9.Рефлексия.
Закончите предложения:
Мы говорим и слышим……
Мы видим, пишем, читаем, называем…..
Слово можно записать ….. и …..
Д.зс.80, упр.119
1.Заглянула осень в сад –
Птицы улетели.
За окном с утра шуршат
Жёлтые метели.
В. Степанов
2.
Звуки | Буквы |
1.Заглянула осень в сад –
Птицы улетели.
За окном с утра шуршат
Жёлтые метели.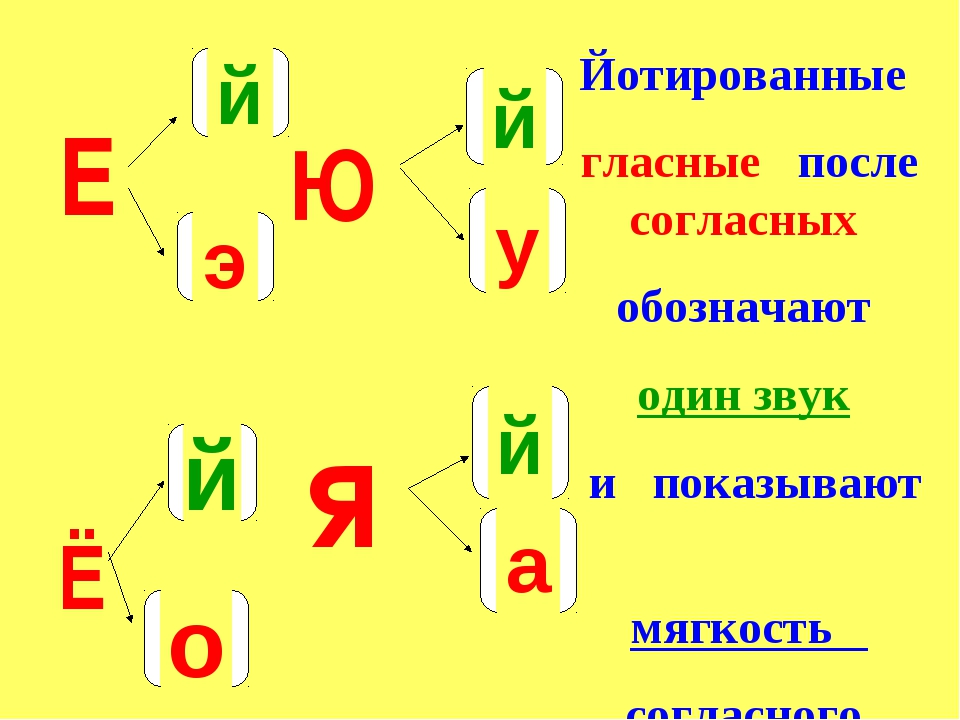
В. Степанов
2.
Звуки | Буквы |
1.Заглянула осень в сад –
Птицы улетели.
За окном с утра шуршат
Жёлтые метели.
В. Степанов
2.
Звуки | Буквы |
Конспект урока по русскому языку “СОГЛАСНЫЙ ЗВУК [Й’], БУКВА «И КРАТКОЕ»” 2 класс
МУНИЦИПАЛЬНОЕ БЮДЖЕТНОЕ ОБЩЕОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ
ОСНОВНАЯ ОБЩЕОБРАЗОВАТЕЛЬНАЯ ШКОЛА г. ЗЕРНОГРАДА
ЗЕРНОГРАДА
конспект
урока русского языка
во 2 классе
по теме:
Согласный звук [й’], буква «и краткое».
Учитель начальных классов
высшей квалификационной категории
ДОЛГАЛЕВа АЛЛа НИКОЛАЕВНа
Урок русского языка во 2 классе
Долгалева А. Н.
учитель начальных классов,
высшая квалификационная
категория
Тема урока: Согласный звук [й’], буква «и краткое».
Цели:
– дать более полное представление о согласном звуке [й’];
– написание слов с буквой «и краткое»;
– совершенствовать умение переносить слова с буквой «и краткое»;
– отрабатывать умение преобразовывать слова со звуком «й» и правильно их записывать;
– развивать внимание
– воспитывать культуру речи;
– поддерживать интерес к урокам русского языка
– формирование УУД:
Познавательные:
– высказывать предположения;
– воспроизводить по памяти информацию, необходимую для решения учебной задачи.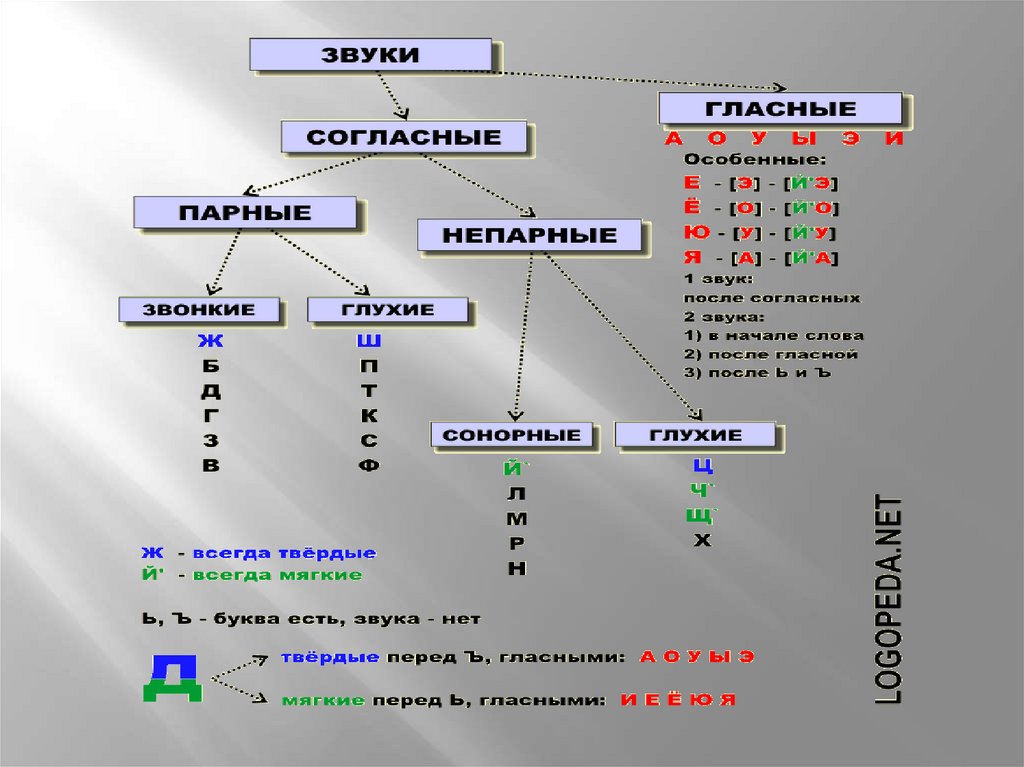
Регулятивные:
– самостоятельно организовывать свое рабочее место;
– определять цель учебной деятельности с помощью учителя и самостоятельно;
– обнаруживать и формулировать проблему с помощью учителя;
– находить и исправлять ошибки;
– соотносить выполненное задание с образцом;
– проводить самооценку своего задания по следующим параметрам: быстро, правильно, красиво.
Личностные:
– проявлять к одноклассникам доброжелательность, доверие, внимательность, оказывать помощь.
Коммуникативные:
– излагать свое мнение;
– составлять предложения для решения определенной задачи;
– работать в паре, проводить взаимопроверку.
Оборудование:
таблицы с напечатанными словами,
мультимедийный проектор,
электронное приложение к учебнику Русский язык 2 класс В. П. Канакиной,
П. Канакиной,
В.Г. Горецкого.
учебник Русский язык 2 класс В.П. Канакиной, В.Г. Горецкого,
Рабочие тетради В.П.Канакиной.
Ход урока:
I.Организационный момент
Долгожданный дан звонок,
Начинается урок.
Всё ль на месте,
Всё ль в порядке:
Ручка, книжка и тетрадка?
Все ли правильно сидят?
Все ль внимательно глядят?
– Начинаем урок русского языка.
Открываем тетради и записываем:
6 декабря.
Классная работа.
II. Актуализация знаний
1) – Наш любимый герой Незнайка сочинил стихотворение. Послушайте:
Я – поэт!
Зовусь Незнака!
От меня вам балалака!
– Какие ошибки допустил Незнайка? Помогите ему их исправить!
2) – У Незнайки ещё одна беда. Он хотел составить из слогов слова, но они у него рассыпались. Помогите ему их собрать.
по пу гай
лей ка
чай ник
чай ка
строй ка
му ра вей
во ро бей
3) – Что общего у этих слов?
– Давайте вспомним прошлый урок и дадим характеристику звуку Й.
III. Целеполагание (Открывается тема урока: Звук Й, буква Й)
Сегодня на уроке мы будем применять имеющиеся у нас знания и умения:
– правильно писать слова с буквой Й
– делить слова для переноса
– преобразовывать слова со звуком Й
Букву Й зовут И кратким
Й как И в твоей тетрадке
Чтобы Й не путать с И
Сверху галочку пиши
IV. Применение знаний в знакомой, в измененной и в новой ситуациях.
1) На доске две группы слов. Прочитайте слова 1-го столбика
шайба
чайка
гайка
зайка
сайка
– Что объединяет эти слова?
Прочитайте слова 2-го столбика
булка
слесарь
море
хоккей
лес
– Есть ли какой-то общий смысл в словах второго столбика?
2) Давайте попытаемся установить смысловые связи между словами 1-го и 2-го столбиков. Составим пары слов.
3) С каждой парой придумайте предложение
4) Запишите слова первого столбика в тетрадь, разделяя их чёрточкой для переноса
5) ВЗАИМОПРОВЕРКА
6) – Как правильно переносить слова с буквой Й?
7. Динамическая пауза. Игра «Лови звук!»
(хлопки над головой, перед собой, внизу)
Майка, трамвай, йогурт, ёлка, стой, йод, мой, яма, герой, пояс, юла, поёт, ёжик, поехали, твой, Юля, зайка, стой, лейка.
8) – А всегда ли мы будем писать букву, если услышим звук Й?
– Установите соответствие между буквами и звуками.
– Когда же эти буквы обозначают 2 звука?
9) – Откройте учебники на стр. 115. Прочитайте задание к упр. 184.
– Спишите слова и вставьте пропущенную букву. Подчерните букву простым карандашом
10) ФРОНТАЛЬНАЯ ПРОВЕРКА (РАБОТА С МУЛЬТИМЕДИНЫМ ПРОЕКТОРОМ)
11) Оцените свою работу по линеечкам БЫСТРО, ПРАВИЛЬНО, КРАСИВО
12) Самостоятельная работа по карточкам.
VI. Информация о домашнем задании.
VII этап. Рефлексия. Подведение итогов урока.
проектов соглашений России с НАТО и США: предназначены для отклонения?
Россия обладает крупнейшим в мире ядерным арсеналом и самыми мощными обычными вооруженными силами в Европе.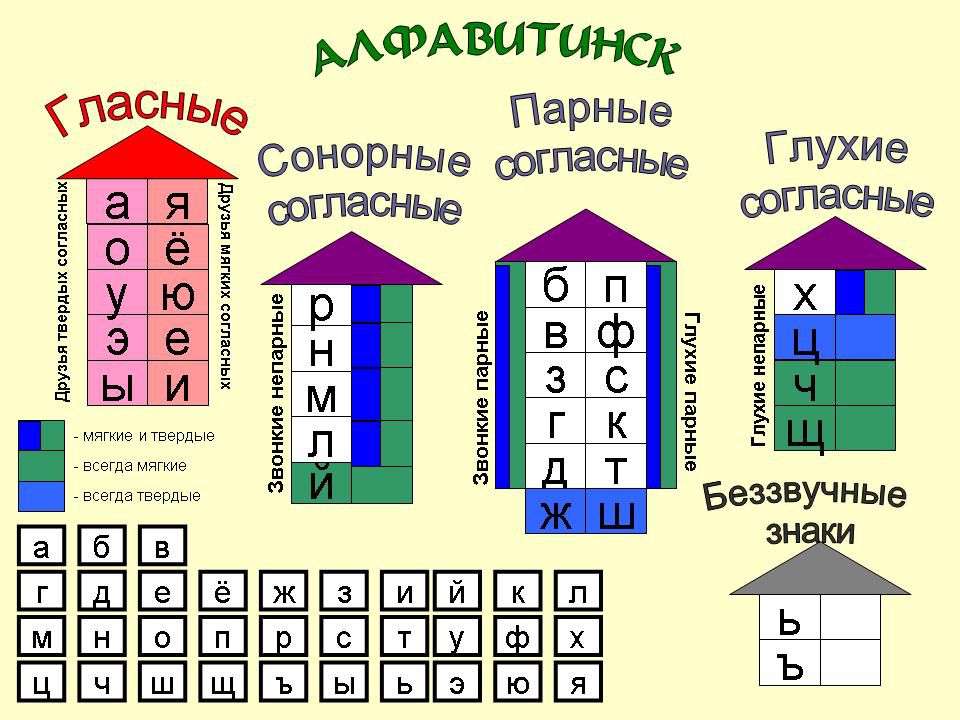 Российские воинские части в настоящее время дислоцированы — непрошенные и нежелательные — на Украине, в Грузии и Молдавии. Поскольку сосредоточение российской военной мощи вблизи Украины спровоцировало кризис, президент Владимир Путин потребовал юридически обязывающих гарантий безопасности для… России.
Российские воинские части в настоящее время дислоцированы — непрошенные и нежелательные — на Украине, в Грузии и Молдавии. Поскольку сосредоточение российской военной мощи вблизи Украины спровоцировало кризис, президент Владимир Путин потребовал юридически обязывающих гарантий безопасности для… России.
17 декабря Министерство иностранных дел России предприняло необычный шаг, опубликовав проекты соглашений между США и Россией, а также между НАТО и Россией, которые содержат желаемые гарантии Москвы. Суть проектов и то, как они были обнародованы русскими, не предполагают серьезных переговоров.
Если Кремль серьезно настроен на переговоры и деэскалацию ситуации вокруг Украины, Запад может заняться некоторыми элементами проектов. Многие, однако, никуда не денутся — о чем Москва наверняка знала.
Проект соглашения Россия-НАТО Российский проект «Соглашения о мерах по обеспечению безопасности Российской Федерации и государств-членов Организации Североатлантического договора» требует, чтобы члены НАТО обязались не допускать дальнейшего расширения альянса, включая в частности на Украину.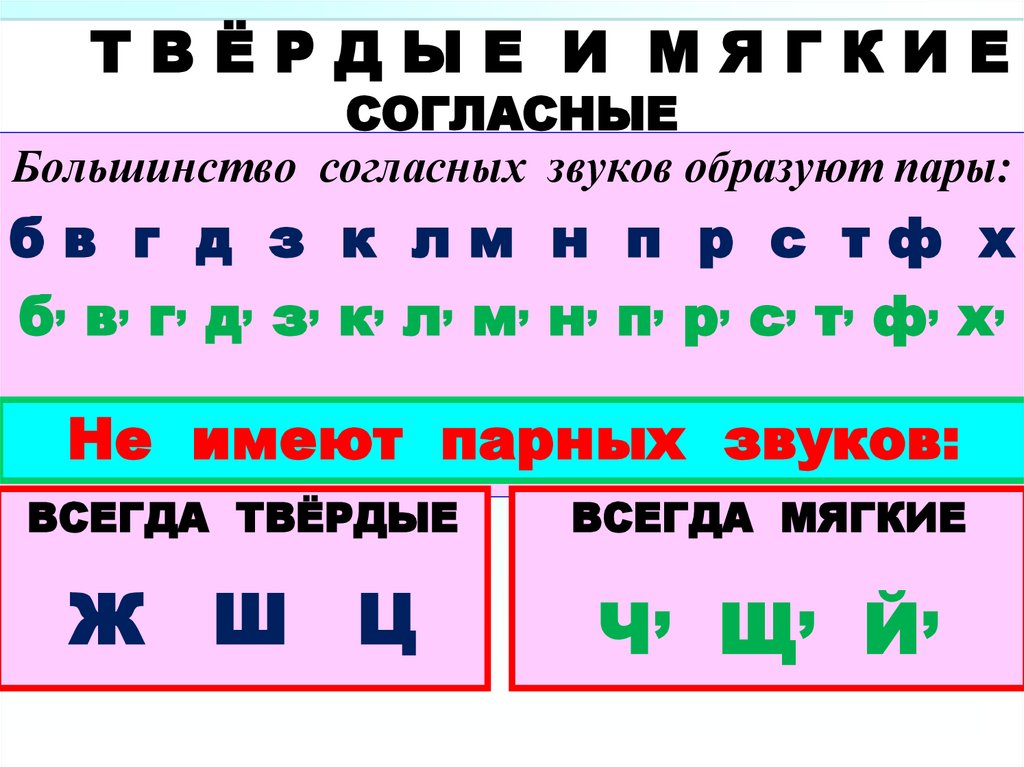 Сейчас в НАТО мало энтузиазма по поводу того, чтобы поставить Украину на путь членства, что, несомненно, понимают Путин и другие российские официальные лица. Однако альянс не откажется от своей давней политики «открытых дверей». Для этого потребуется консенсус, и мало кто из союзников, не говоря уже о всех 30, согласится с тем, что Россия может таким образом диктовать политику НАТО.
Сейчас в НАТО мало энтузиазма по поводу того, чтобы поставить Украину на путь членства, что, несомненно, понимают Путин и другие российские официальные лица. Однако альянс не откажется от своей давней политики «открытых дверей». Для этого потребуется консенсус, и мало кто из союзников, не говоря уже о всех 30, согласится с тем, что Россия может таким образом диктовать политику НАТО.
Это говорит о том, что золотая середина «не сейчас, но и никогда» может предложить способ отбросить этот тернистый путь. То есть, если Москва захочет разрядить обстановку.
Другая статья в российском проекте требовала, чтобы НАТО не размещала силы или оружие в странах, присоединившихся к альянсу после мая 1997 года. В том же месяце НАТО обязалась не размещать на постоянной основе значительные боевые силы в составе новых членов и заявила, что у нее «нет намерения, ни плана, ни причины» размещать ядерное оружие на своей территории. с 19С 97 по 2014 год НАТО разместила практически , а не военнослужащих или технику в новых государствах-членах.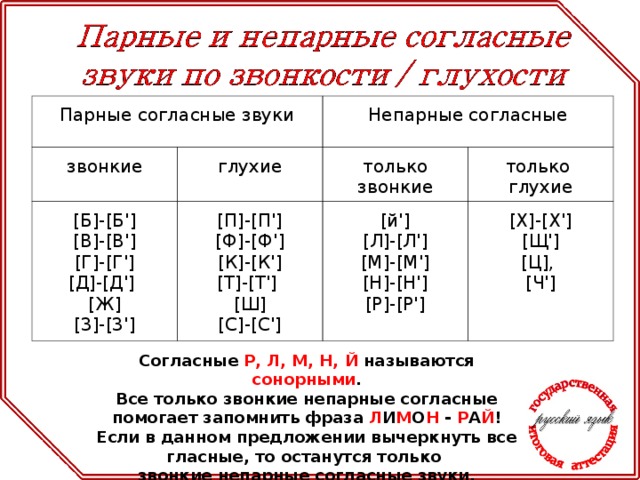
Ситуация изменилась после захвата Крыма Россией. В настоящее время НАТО развертывает на ротационной основе относительно небольшие многонациональные боевые группы в странах Балтии и Польше. Трудно предположить, что НАТО согласится их вывести, если не произойдет существенного изменения военной позиции России. Однако в проекте договора не содержится никаких требований по передислокации российских войск.
Такие условия не помогут альянсу. Другие могут получить более положительный прием. К ним относятся формулировки о консультативных механизмах, таких как Совет Россия-НАТО, и создание горячей линии между НАТО и Россией. Действительно, НАТО предложила провести встречи Совета Россия-НАТО, хотя в октябре Москва приостановила дипломатические отношения с НАТО.
Проект договора также запрещает размещение ракет средней дальности в районах, где они могут достичь территории другой стороны. Конечно, Договор о ликвидации ракет средней и меньшей дальности 1987 года запрещал все американские и российские ракеты средней дальности. Однако размещение Россией крылатой ракеты средней дальности 9М729 в нарушение договора привело к его краху.
Однако размещение Россией крылатой ракеты средней дальности 9М729 в нарушение договора привело к его краху.
Эта идея звучит как предложение Путина от 2019 года о моратории на размещение ракет средней дальности в Европе. В то время как НАТО отклонила это, возможно, стоит еще раз взглянуть на это, при условии, что Россия подтвердила, что это будет применяться к 9M729 и имел соответствующие меры проверки.
Предлагаемый в проекте договора запрет на любую военную деятельность НАТО на Украине, в Восточной Европе, на Кавказе или в Центральной Азии является чрезмерным, но некоторые меры по ограничению военных учений и действий на взаимной основе могут быть возможны. Есть история таких положений, например, меры укрепления доверия и безопасности Венского документа.
Проект договора между США и Россией Проект «Договора между Соединенными Штатами Америки и Российской Федерацией о гарантиях безопасности» также содержит неприемлемые положения. Вашингтон, вероятно, не согласится с требованием о том, чтобы две страны «не применяли меры безопасности… которые могут подорвать основные интересы безопасности другой стороны». Москва показала, что у нее очень широкое определение того, что, по ее мнению, может подорвать ее безопасность. Точно так же нереально просить Соединенные Штаты предотвратить дальнейшее расширение НАТО; Вашингтон не согласится закрыть «открытую дверь», а если бы и согласился, то не смог бы убедить всех 29другие союзники согласились изменить политику.
Вашингтон, вероятно, не согласится с требованием о том, чтобы две страны «не применяли меры безопасности… которые могут подорвать основные интересы безопасности другой стороны». Москва показала, что у нее очень широкое определение того, что, по ее мнению, может подорвать ее безопасность. Точно так же нереально просить Соединенные Штаты предотвратить дальнейшее расширение НАТО; Вашингтон не согласится закрыть «открытую дверь», а если бы и согласился, то не смог бы убедить всех 29другие союзники согласились изменить политику.
В то время как интерес может возникнуть к проекту положения соглашения между Россией и НАТО о ракетах средней дальности, не будет интереса к проекту положения договора между США и Россией, которое фактически запретит размещение американских ракет средней дальности в Европе, оставив России свободу развертывания таких ракет против стран НАТО. Положение, ограничивающее возможности тяжелых бомбардировщиков и надводных кораблей действовать в международных водах и над ними, не найдет поклонников ни в Вашингтоне, ни, если уж на то пошло, в российских вооруженных силах.

Связанные книги
Возможно обсуждение других положений, касающихся военной деятельности. Для Москвы неразумно искать вето в отношении внешнеполитического курса Киева. Однако озабоченность, высказанная Путиным ранее в декабре, а затем повторенная, по поводу американских наступательных ракет на Украине, способных нанести удар по Москве за считанные минуты, ставит другой вопрос. Эту озабоченность может оказаться легко решить, поскольку нет никаких признаков того, что Вашингтон когда-либо рассматривал ее. Могут быть рассмотрены и другие подобные опасения России, наряду с опасениями США (и НАТО) в отношении определенных российских военных действий.
Проект положения, требующего, чтобы все ядерное оружие было размещено на национальной территории, должен быть передан на рассмотрение другого форума. Чиновники администрации Байдена надеются начать переговоры с Россией, которые охватят все ядерное оружие США и России.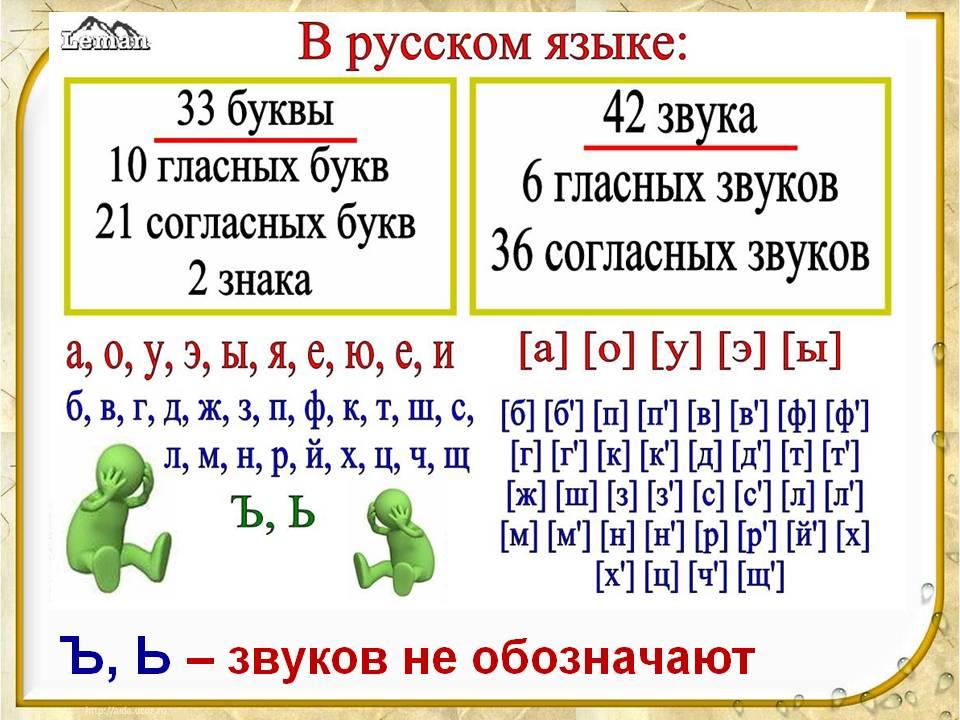 Это подходящее место для этого вопроса. Приемлемо ли для Вашингтона требование о том, чтобы все ядерное оружие базировалось на национальной территории, будет зависеть от общего согласия и консультаций с союзниками.
Это подходящее место для этого вопроса. Приемлемо ли для Вашингтона требование о том, чтобы все ядерное оружие базировалось на национальной территории, будет зависеть от общего согласия и консультаций с союзниками.
Неприемлемые положения двух проектов соглашений, их быстрая публикация российским правительством и безапелляционные формулировки, используемые российскими официальными лицами для описания требований Москвы, вызывают опасения, что Кремль может захотеть получить отказ. Москва могла бы сослаться на то, что рядом с Украиной находятся крупные силы, как на еще один предлог для военных действий против своего соседа.
Если, с другой стороны, эти проекты соглашений представляют собой вступительную заявку, и русские стремятся к серьезному обмену, который также решает проблемы безопасности других сторон, некоторые проекты положений могут стать основой для обсуждения и переговоров. На прошлой неделе Североатлантический совет заявил, что НАТО «готова к конструктивному диалогу с Россией». Советник по национальной безопасности США Джейк Салливан повторил эту мысль: «Мы вели диалог с Россией по вопросам европейской безопасности на протяжении последних 20 лет… Иногда это приводило к прогрессу, иногда — к тупику. Но мы принципиально готовы к диалогу».
Советник по национальной безопасности США Джейк Салливан повторил эту мысль: «Мы вели диалог с Россией по вопросам европейской безопасности на протяжении последних 20 лет… Иногда это приводило к прогрессу, иногда — к тупику. Но мы принципиально готовы к диалогу».
Деэскалация ситуации возле Украины очень помогла бы. Официальные лица США и НАТО не захотят вступать в бой, пока Россия создает военную угрозу над Киевом. Другой вопрос в формате. Вашингтон и Москва могут вести двусторонние переговоры, но в переговорах должны участвовать все заинтересованные стороны, включая Украину. США и Россия не могут заключить сделку по головам европейцев и украинцев. Как сказал Салливан, «ничего о тебе без тебя».
Стороны должны сесть за стол переговоров, готовые обсудить законные проблемы безопасности друг друга. На согласование значения слова «законный» уйдут долгие часы. Например, маловероятно, что США (или НАТО) пойдут на компромисс по принципу, на который согласилась Москва как участник 19-го75 Хельсинкского заключительного акта — государства имеют право выбирать свой внешнеполитический курс. Вопрос о военной деятельности в регионе Россия-НАТО — это другой вопрос, и НАТО уже продемонстрировала свою готовность взять на себя обязательства в этом отношении.
Вопрос о военной деятельности в регионе Россия-НАТО — это другой вопрос, и НАТО уже продемонстрировала свою готовность взять на себя обязательства в этом отношении.
Эти обсуждения и любые переговоры будут долгими, сложными и трудными. Именно такой работой занимаются дипломаты. Однако для того, чтобы начать двигаться по этому пути, потребуются совсем другие сигналы, чем те, которые Запад и Украина получали из Москвы в последние несколько недель.
Определенные и неопределенные артикли (a, an, the) — TIP Sheets
TIP Sheet
ОПРЕДЕЛЕННЫЕ И НЕОПРЕДЕЛЕННЫЕ АРТИКЛИ
Артикли используются перед существительными или эквивалентами существительных и являются типом прилагательного. Определенный артикль ( the ) ставится перед существительным, чтобы показать, что читателю известна идентичность существительного. Неопределенный артикль ( a , an ) используется перед существительным, которое является общим или когда его личность неизвестна. Есть определенные ситуации, в которых существительное не имеет артикля.
Есть определенные ситуации, в которых существительное не имеет артикля.
В качестве руководства следующие определения и таблица обобщают основное использование артикулов. Продолжайте читать для более подробного объяснения правил и примеров того, как и когда их применять.
Определенный артикль
the (перед существительным в единственном или множественном числе)
Неопределенный артикль
a (перед существительным в единственном числе, начинающимся с согласного звука)
an (перед существительным в единственном числе, начинающимся с гласного звука)
Исчисляемые существительные — относятся к предметам, которые можно посчитать, и имеют единственное или множественное число
Нет -исчисляемые существительные – относятся к элементам, которые не учитываются и всегда стоят в единственном числе
| СЧИТАЕМЫЕ СУЩЕСТВИТЕЛЬНЫЕ | НЕИСЧИСЛЯЕМЫЕ СУЩЕСТВИТЕЛЬНЫЕ | |
| Правило № 1 Конкретная принадлежность неизвестна | а, | (без артикула) |
| Правило № 2 Конкретная идентификация известна | ||
| Правило №3 Все вещи или вещи вообще | (без артикула) | (без артикула) |
Чтобы понять, как используются артикли, важно знать, что существительные могут быть либо count (можно пересчитать) или noncount (количество неопределенно и не поддается подсчету).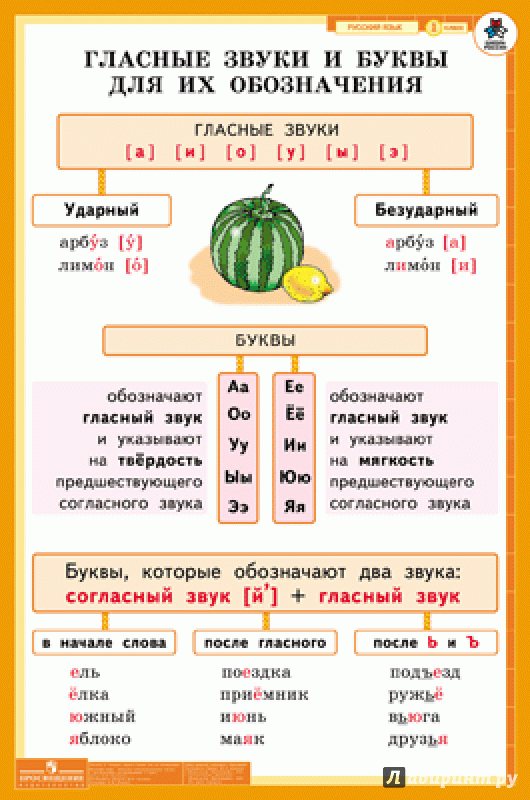 Кроме того, исчисляемые существительные имеют форму единственного числа (один) или множественного числа (более одного). Неисчисляемые существительные всегда находятся в форме единственного числа .
Кроме того, исчисляемые существительные имеют форму единственного числа (один) или множественного числа (более одного). Неисчисляемые существительные всегда находятся в форме единственного числа .
Например, если мы говорим о воде, которая была пролита на стол, на столе может быть одна капля ( единственного числа ) или две или более капель ( множественное число ) воды на столе. Слово drop в этом примере является существительным count , потому что мы можем подсчитать количество капель. Таким образом, в соответствии с правилами, применяемыми к count существительных, слово drop будет использовать артикли a или the .
Однако, если мы говорим о воде вообще, пролитой на стол, то было бы неуместно считать одной водой или двумя водами — на столе было бы просто воды .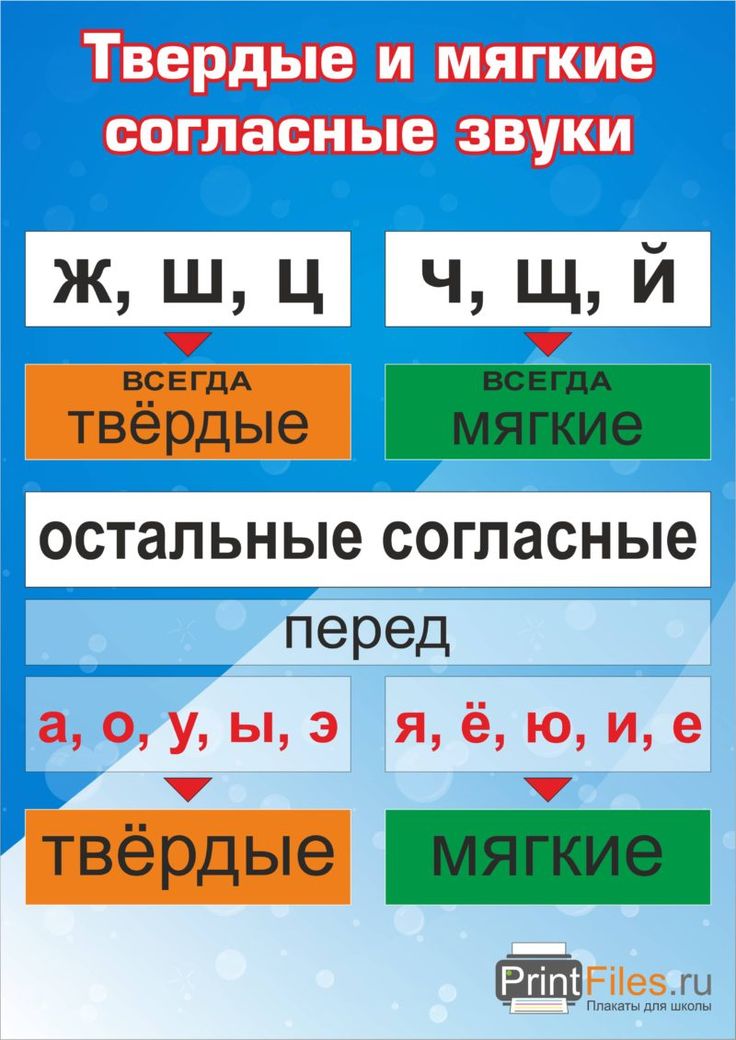 Вода это неисчисляемое существительное. Следовательно, в соответствии с правилами, применимыми к неисчисляемым существительным, слово вода будет использовать без артикля или вместо , но не как .
Вода это неисчисляемое существительное. Следовательно, в соответствии с правилами, применимыми к неисчисляемым существительным, слово вода будет использовать без артикля или вместо , но не как .
Ниже приведены три особых правила, которые объясняют использование определенного и неопределенного артиклей.
Правило № 1. Конкретное наименование неизвестно: Используйте неопределенный артикль a или an только с исчисляемым существительным в единственном числе, конкретное наименование которого читателю неизвестно. Используйте a перед существительными, которые начинаются с согласного звука, и используйте перед существительными, которые начинаются с гласного звука.
- Используйте артикул и или и для обозначения любого неуказанного члена группы или категории.
Я думаю животное в гараже
Этот человек негодяй.
Ищем квартиру .
- Используйте артикул и или и , чтобы указать один номер (в отличие от нескольких).
У меня есть кот и две собаки.
- Используйте артикль a перед согласным звуком и используйте артикль и перед гласным звуком.
мальчик , яблоко
◊ Иногда между артиклем и существительным стоит прилагательное:
несчастный мальчик, красное яблоко
- Множественное число от a или или это или . Используйте вместо , чтобы указать неопределенное, ограниченное количество (но более одного).
яблоко , несколько яблок
Правило № 2 – Известна конкретная идентичность: Используйте определенный артикль the с любым существительным (в единственном или множественном числе, исчисляемым или неисчисляемым), когда конкретная идентичность существительного известна читателю, как в следующих ситуациях:
- Используйте артикль и , когда конкретное существительное уже упоминалось ранее.

Вчера я съел и яблоко. Яблоко было сочным и вкусным.
- Используйте артикль the , когда прилагательное, фраза или предложение, описывающие существительное, уточняют или ограничивают его идентичность.
Мальчик , сидящий рядом со мной, поднял руку.
Спасибо за совет , который ты мне дал.
- Используйте артикль the , когда существительное относится к чему-то или кому-то уникальному.
теория относительности
федеральный бюджет на 2003 г. или вообще .
Осенью деревья прекрасны. (Все деревья осенью прекрасны.)
Он просил совета. (Он вообще просил совета.)
Я не люблю кофе. (Я вообще не люблю кофе.)
Дополнительная информация относительно употребления артиклей . Мой двоюродный брат искал совета у консультанта (не совет вообще или совет обо всем, а ограниченный совет). Я бы хотел выпить кофе прямо сейчас (не кофе вообще, а кофе в ограниченном количестве). Завтра может пойти дождь . Небольшой дождь был бы полезен для посевов (определенное количество дождя, в отличие от дождя в целом). На столе несколько капель воды (ограниченное количество, но больше одной капли). ◊ Определенные продукты питания и напитки : бекон, говядина, хлеб, брокколи, масло, капуста, конфеты, цветная капуста, сельдерей, хлопья, сыр, курица, шоколад, кофе, кукуруза, сливки, рыба, мука, фрукты, лед сливки, салат, мясо, молоко, масло, макаронные изделия, рис, соль, шпинат, сахар, чай, вода, вино, йогурт ◊ Некоторые непищевые вещества : воздух, цемент, уголь, грязь, бензин, золото, бумага, нефть, пластик, дождь, серебро, снег, мыло, сталь, дерево, шерсть ◊ Самые абстрактные существительные : совет, гнев, красота, уверенность, мужество, занятость, веселье, счастье, здоровье, честность, информация, интеллект, знание, любовь, бедность, удовлетворение, правда, богатство ◊ Области учеба : история, математика, биология и т. ◊ Спорт : футбол, бейсбол, хоккей и т. д. ◊ Языки : китайский, испанский, русский, английский и т. д.![]()
 д.
д.3
3 Другое : одежда, оборудование, мебель, домашние задания, ювелирные изделия, багаж, пиломатериалы, машины, почта, деньги, новости, поэзия, загрязнение, исследования, декорации, движение, транспорт, насилие, погода, работа
- Географические названия сбивают с толку, потому что некоторые требуют, а некоторые нет.
◊ Использование с : США, большие регионы, пустыни, полуострова, океаны, моря, заливы, каналы, реки, горные хребты, группы островов
пустыня Гоби
Объединенные Арабские Эмираты
река Сакраменто
Алеутские острова
◊ Не используйте с : улицы, парки, города, штаты, округа, большинство стран, континенты, заливы, отдельные озера, отдельные горы, острова
Япония
Чико
Эверест
Залив Сан-Франциско
Примеры использования артикулов
Я не хочу
0 пистолет в моем доме (0 пистолет).
Пистолет находится в его шкафу (подразумевается, что там есть определенный пистолет).
Я боюсь пушек (вообще всех пушек).
Она прислала мне открытку из Италии (неконкретная открытка – не письмо, не электронная почта).
Это открытка , которая лежит у меня в офисе (одна конкретная открытка).
Когда я получаю открытки, мне хочется путешествовать (любая открытка вообще).
У меня есть собака (одна собака).
Собака очень дружелюбна к (собака, о которой я уже упоминал).
Из собак получаются отличные домашние животные (собаки вообще).
Грете нужна мебель в квартире (мебель — неисчисляемое существительное).
Она собирается выбрать мебель, которая ей нужна (конкретная мебель, которая ей нужна).
Она надеется найти немного мебели в эти выходные (неопределенное, ограниченное количество мебели).
Мы собираемся увидеть Статую Свободы в эти выходные (единственную Статую Свободы).
Наборы данных машинного обучения | Бумаги с кодом
🔔 Поделитесь своим набором данных с сообществом машинного обучения!
СИФАР-10
Набор данных CIFAR-10 (Канадский институт перспективных исследований, 10 классов) является подмножеством набора данных Tiny Images и состоит из 60000 цветных изображений 32×32. Изображения помечены одним из 10 взаимоисключающих классов: самолет, автомобиль (но не грузовик или пикап), птица, кошка, олень, собака, лягушка, лошадь, корабль и грузовик (но не пикап). На класс приходится 6000 изображений, 5000 обучающих и 1000 тестовых изображений на класс.
9 563 ДОКУМЕНТА • 59 ПОКАЗАТЕЛЕЙ
Имиджнет
Набор данных ImageNet содержит 14 197 122 аннотированных изображения в соответствии с иерархией WordNet. С 2010 года набор данных используется в программе ImageNet Large Scale Visual Recognition Challenge (ILSVRC), эталоне классификации изображений и обнаружения объектов.
Публично выпущенный набор данных содержит набор аннотированных вручную обучающих изображений. Также выпущен набор тестовых изображений без ручных аннотаций.
Аннотации ILSVRC попадают в одну из двух категорий: (1) аннотация на уровне изображения двоичной метки для присутствия или отсутствия класса объектов на изображении, например, «на этом изображении есть автомобили», но «нет тигров, » и (2) аннотация на уровне объекта в виде узкой ограничивающей рамки и метки класса вокруг экземпляра объекта на изображении, например, «есть отвертка с центром в позиции (20, 25) с шириной 50 пикселей и высотой 30 пикселей ». Проект ImageNet не владеет авторскими правами на изображения, поэтому предоставляются только эскизы и URL-адреса изображений.
Проект ImageNet не владеет авторскими правами на изображения, поэтому предоставляются только эскизы и URL-адреса изображений.
9 111 ДОКУМЕНТОВ • 88 ПОКАЗАТЕЛЕЙ
КОКО (Общие объекты Microsoft в контексте)
Набор данных MS COCO (Microsoft Common Objects in Context) представляет собой крупномасштабный набор данных для обнаружения объектов, сегментации, обнаружения ключевых точек и подписей. Набор данных состоит из 328 тыс. изображений.
6454 ДОКУМЕНТА • 78 ПОКАЗАТЕЛЕЙ
МНИСТ
База данных MNIST (модифицированная база данных Национального института стандартов и технологий) представляет собой большой набор рукописных цифр. Он имеет обучающий набор из 60 000 примеров и тестовый набор из 10 000 примеров. Это подмножество более крупной специальной базы данных 3 NIST (цифры, написанные сотрудниками Бюро переписи населения США) и специальной базы данных 1 (цифры, написанные старшеклассниками), которые содержат монохромные изображения рукописных цифр. Цифры были нормализованы по размеру и центрированы на изображении фиксированного размера. Исходные черно-белые (двухуровневые) изображения из NIST были нормализованы по размеру, чтобы поместиться в поле 20×20 пикселей с сохранением соотношения сторон. Результирующие изображения содержат уровни серого из-за метода сглаживания, используемого алгоритмом нормализации. изображения были центрированы в изображении 28×28 путем вычисления центра масс пикселей и перемещения изображения таким образом, чтобы расположить эту точку в центре поля 28×28.
Он имеет обучающий набор из 60 000 примеров и тестовый набор из 10 000 примеров. Это подмножество более крупной специальной базы данных 3 NIST (цифры, написанные сотрудниками Бюро переписи населения США) и специальной базы данных 1 (цифры, написанные старшеклассниками), которые содержат монохромные изображения рукописных цифр. Цифры были нормализованы по размеру и центрированы на изображении фиксированного размера. Исходные черно-белые (двухуровневые) изображения из NIST были нормализованы по размеру, чтобы поместиться в поле 20×20 пикселей с сохранением соотношения сторон. Результирующие изображения содержат уровни серого из-за метода сглаживания, используемого алгоритмом нормализации. изображения были центрированы в изображении 28×28 путем вычисления центра масс пикселей и перемещения изображения таким образом, чтобы расположить эту точку в центре поля 28×28.
5 576 ДОКУМЕНТОВ • 42 ПОКАЗАТЕЛЯ
СИФАР-100
Набор данных CIFAR-100 (Канадский институт перспективных исследований, 100 классов) является подмножеством набора данных Tiny Images и состоит из 60000 цветных изображений 32×32. 100 классов в CIFAR-100 сгруппированы в 20 суперклассов. В каждом классе 600 изображений. Каждое изображение имеет метку «точно» (класс, к которому оно принадлежит) и метку «грубо» (надкласс, к которому оно принадлежит). В каждом классе есть 500 обучающих изображений и 100 тестовых изображений.
100 классов в CIFAR-100 сгруппированы в 20 суперклассов. В каждом классе 600 изображений. Каждое изображение имеет метку «точно» (класс, к которому оно принадлежит) и метку «грубо» (надкласс, к которому оно принадлежит). В каждом классе есть 500 обучающих изображений и 100 тестовых изображений.
4719 ДОКУМЕНТОВ • 35 ПОКАЗАТЕЛЕЙ
Городские пейзажи
Cityscapes — это крупномасштабная база данных, ориентированная на семантическое понимание городских уличных сцен. Он предоставляет семантические аннотации по экземплярам и плотным пикселям для 30 классов, сгруппированных в 8 категорий (плоские поверхности, люди, транспортные средства, конструкции, объекты, природа, небо и пустота).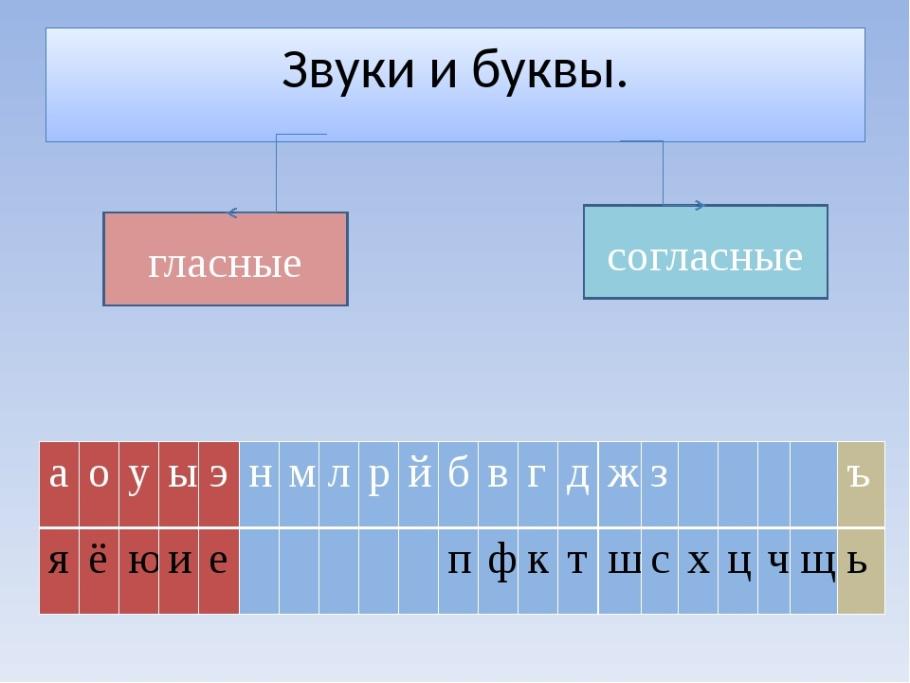 Набор данных состоит из примерно 5000 изображений с точной аннотацией и 20000 изображений с грубой аннотацией. Данные снимались в 50 городах в течение нескольких месяцев, в дневное время и при хороших погодных условиях. Первоначально он был записан как видео, поэтому кадры были выбраны вручную, чтобы иметь следующие особенности: большое количество динамических объектов, различное расположение сцен и меняющийся фон.
Набор данных состоит из примерно 5000 изображений с точной аннотацией и 20000 изображений с грубой аннотацией. Данные снимались в 50 городах в течение нескольких месяцев, в дневное время и при хороших погодных условиях. Первоначально он был записан как видео, поэтому кадры были выбраны вручную, чтобы иметь следующие особенности: большое количество динамических объектов, различное расположение сцен и меняющийся фон.
2359 ДОКУМЕНТОВ • 37 ПОКАЗАТЕЛЕЙ
СВХН (номера домов с просмотра улиц)
Street View House Numbers (SVHN) — это эталонный набор данных для классификации цифр, который содержит 600 000 32 × 32 RGB-изображений печатных цифр (от 0 до 9).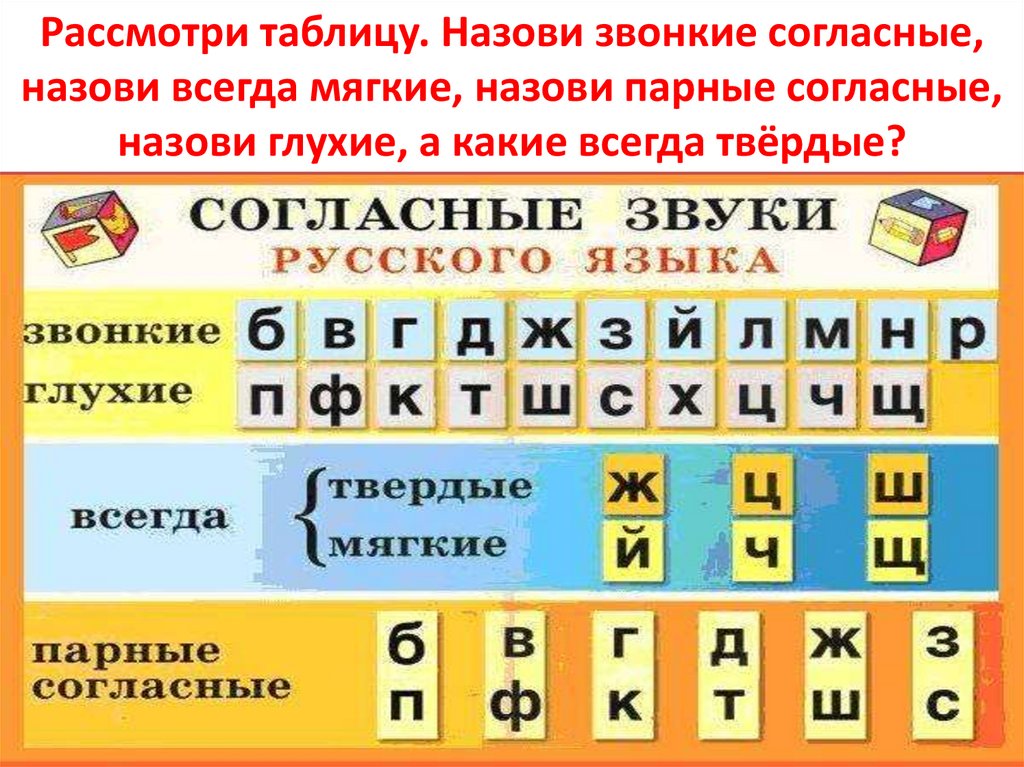 ) вырезано из фотографий номерных знаков домов. Обрезанные изображения располагаются по центру интересующей цифры, но близлежащие цифры и другие отвлекающие факторы остаются на изображении. SVHN имеет три набора: обучающий, тестовый и дополнительный набор из 530 000 изображений, которые менее сложны и могут быть использованы для помощи в процессе обучения.
) вырезано из фотографий номерных знаков домов. Обрезанные изображения располагаются по центру интересующей цифры, но близлежащие цифры и другие отвлекающие факторы остаются на изображении. SVHN имеет три набора: обучающий, тестовый и дополнительный набор из 530 000 изображений, которые менее сложны и могут быть использованы для помощи в процессе обучения.
2294 ДОКУМЕНТА • 11 ПОКАЗАТЕЛЕЙ
КИТТИ
KITTI (Технологический институт Карлсруэ и Технологический институт Toyota) — один из самых популярных наборов данных для использования в мобильной робототехнике и автономном вождении. Он состоит из часов сценариев дорожного движения, записанных с помощью различных датчиков, включая RGB с высоким разрешением, стереокамеры в оттенках серого и лазерный 3D-сканер. Несмотря на свою популярность, сам набор данных не содержит достоверных данных для семантической сегментации. Однако различные исследователи вручную аннотировали части набора данных, чтобы они соответствовали их потребностям. Альварес и др. сгенерировал наземную правду для 323 изображений из задачи обнаружения дорог с тремя классами: дорога, вертикаль и небо. Чжан и др. аннотировано 252 (140 для обучения и 112 для тестирования) снимков — сканов RGB и Velodyne — из задачи отслеживания для десяти категорий объектов: здание, небо, дорога, растительность, тротуар, автомобиль, пешеход, велосипедист, знак/столб и забор. Рос и др. помечены 170 тренировочных изображений и 46 тестовых изображений (из визуального одома
Несмотря на свою популярность, сам набор данных не содержит достоверных данных для семантической сегментации. Однако различные исследователи вручную аннотировали части набора данных, чтобы они соответствовали их потребностям. Альварес и др. сгенерировал наземную правду для 323 изображений из задачи обнаружения дорог с тремя классами: дорога, вертикаль и небо. Чжан и др. аннотировано 252 (140 для обучения и 112 для тестирования) снимков — сканов RGB и Velodyne — из задачи отслеживания для десяти категорий объектов: здание, небо, дорога, растительность, тротуар, автомобиль, пешеход, велосипедист, знак/столб и забор. Рос и др. помечены 170 тренировочных изображений и 46 тестовых изображений (из визуального одома
2284 ДОКУМЕНТА • 119 ПОКАЗАТЕЛЕЙ
CelebA (Набор данных атрибутов CelebFaces)
Набор данных CelebFaces Attributes содержит 202,599 изображений лиц размером 178×218 от 10 177 знаменитостей, каждое из которых снабжено 40 бинарными метками, указывающими такие атрибуты лица, как цвет волос, пол и возраст.
2230 ДОКУМЕНТОВ • 15 ПОКАЗАТЕЛЕЙ
Fashion-MNIST
Fashion-MNIST — это набор данных, состоящий из изображений в оттенках серого 28×28 70 000 модных товаров из 10 категорий, по 7 000 изображений в каждой категории. Учебный набор содержит 60 000 изображений, а тестовый — 10 000 изображений. Fashion-MNIST использует тот же размер изображения, формат данных и структуру тренировочных и тестовых разделов, что и исходный MNIST.
1961 ДОКУМЕНТ • 12 ПОКАЗАТЕЛЕЙ
КЛЕЙ (Эталон оценки общего понимания языка)
Тест General Language Understanding Evaluation (GLUE) представляет собой набор из девяти задач на понимание естественного языка, включая задачи с одним предложением CoLA и SST-2, задачи на сходство и перефразирование MRPC, STS-B и QQP, а также задачи на определение естественного языка MNLI, QNLI, РТЭ и ВНЛИ.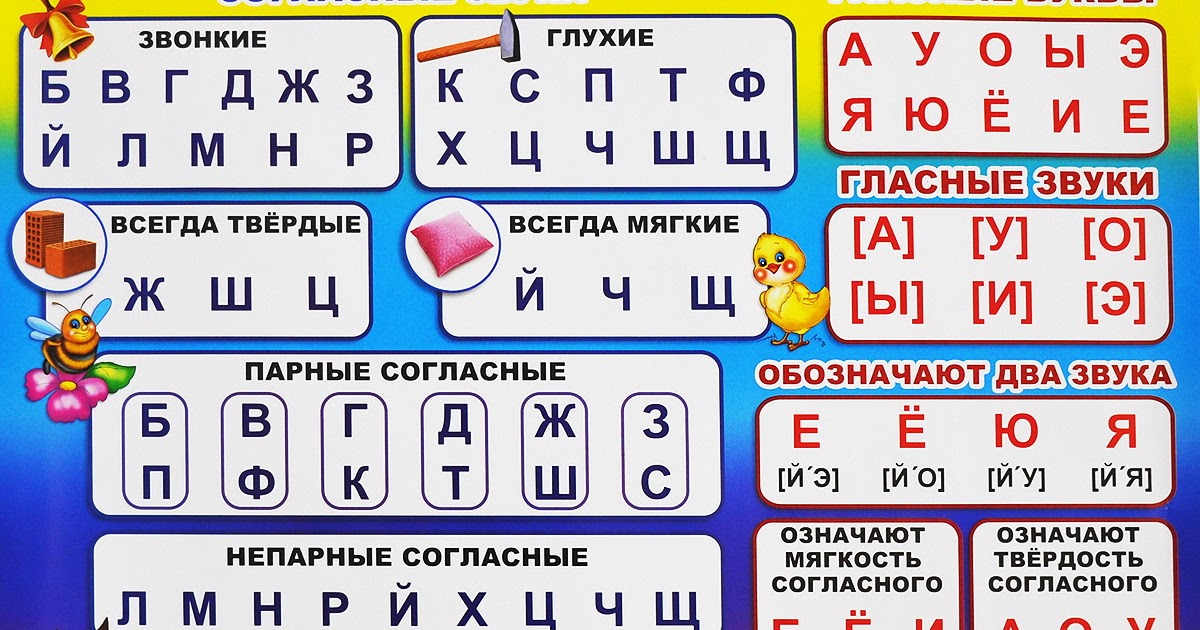
1557 ДОКУМЕНТОВ • 40 ПОКАЗАТЕЛЕЙ
Отряд (Стэнфордский набор данных ответов на вопросы)
Стэнфордский набор данных для ответов на вопросы (SQuAD) представляет собой набор пар вопросов и ответов, полученных из статей Википедии. В SQuAD правильными ответами на вопросы может быть любая последовательность жетонов в заданном тексте. Поскольку вопросы и ответы создаются людьми с помощью краудсорсинга, они более разнообразны, чем некоторые другие наборы данных для ответов на вопросы. SQuAD 1.1 содержит 107 785 пар вопросов и ответов по 536 статьям. SQuAD2.0 (SQuAD с открытым доменом, SQuAD-Open), последняя версия, объединяет 100 000 вопросов в SQuAD1.1 с более чем 50 000 вопросов, на которые нет ответов, написанных состязательно краудворкерами в формах, аналогичных тем, на которые можно ответить.
SQuAD2.0 (SQuAD с открытым доменом, SQuAD-Open), последняя версия, объединяет 100 000 вопросов в SQuAD1.1 с более чем 50 000 вопросов, на которые нет ответов, написанных состязательно краудворкерами в формах, аналогичных тем, на которые можно ответить.
1443 ДОКУМЕНТА • 13 ПОКАЗАТЕЛЕЙ
КУБ-200-2011 (Калтех-UCSD Birds-200-2011)
Набор данных Caltech-UCSD Birds-200-2011 (CUB-200-2011) является наиболее широко используемым набором данных для задач детальной визуальной категоризации. Он содержит 11 788 изображений 200 подкатегорий, принадлежащих птицам, 5,994 для обучения и 5794 для тестирования.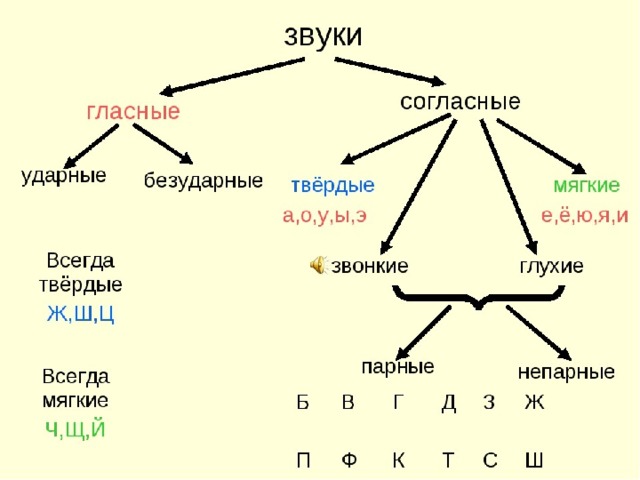 Каждое изображение имеет подробные аннотации: 1 метка подкатегории, 15 местоположений деталей, 312 бинарных атрибутов и 1 ограничительная рамка. Текстовая информация поступает от Reed et al. Они расширяют набор данных CUB-200-2011, собирая подробные описания на естественном языке. Для каждого изображения собираются десять описаний, состоящих из одного предложения. Описания на естественном языке собираются через платформу Amazon Mechanical Turk (AMT) и должны содержать не менее 10 слов без какой-либо информации о подкатегориях и действиях.
Каждое изображение имеет подробные аннотации: 1 метка подкатегории, 15 местоположений деталей, 312 бинарных атрибутов и 1 ограничительная рамка. Текстовая информация поступает от Reed et al. Они расширяют набор данных CUB-200-2011, собирая подробные описания на естественном языке. Для каждого изображения собираются десять описаний, состоящих из одного предложения. Описания на естественном языке собираются через платформу Amazon Mechanical Turk (AMT) и должны содержать не менее 10 слов без какой-либо информации о подкатегориях и действиях.
1367 ДОКУМЕНТОВ • 33 ПОКАЗАТЕЛЯ
SST (Стэнфордское дерево настроений)
Stanford Sentiment Treebank — это корпус с полностью размеченными деревьями синтаксического анализа, который позволяет
полный анализ композиционных эффектов
чувства в языке. Корпус основан на
набор данных, представленный Пангом и Ли (2005) и
состоит из 11 855 отдельных предложений, извлеченных из
обзоры фильмов. Он был проанализирован с помощью Стэнфордского
парсер и содержит в общей сложности 215 154 уникальных фразы
из этих деревьев синтаксического анализа, каждое из которых аннотировано тремя судьями-людьми.
Корпус основан на
набор данных, представленный Пангом и Ли (2005) и
состоит из 11 855 отдельных предложений, извлеченных из
обзоры фильмов. Он был проанализирован с помощью Стэнфордского
парсер и содержит в общей сложности 215 154 уникальных фразы
из этих деревьев синтаксического анализа, каждое из которых аннотировано тремя судьями-людьми.
1298 ДОКУМЕНТОВ • 6 ПОКАЗАТЕЛЕЙ
Пенн Трибэнк
Английский корпус Penn Treebank (PTB) и, в частности, раздел корпуса, соответствующий статьям Wall Street Journal (WSJ), является одним из наиболее известных и используемых корпусов для оценки моделей маркировки последовательностей.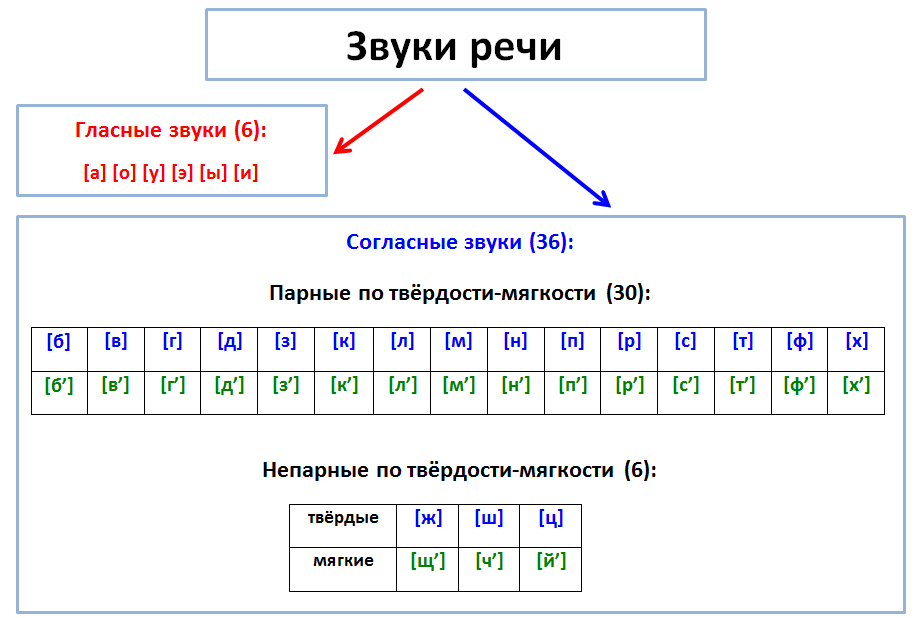 Задача состоит в том, чтобы аннотировать каждое слово его тегом Part-of-Speech. В наиболее распространенной разбивке этого корпуса для обучения используются секции с 0 по 18 (38 219предложения, 912 344 токена), разделы с 19 по 21 используются для проверки (5 527 предложений, 131 768 токенов), а разделы с 22 по 24 используются для тестирования (5 462 предложения, 129 654 токена).
Корпус также обычно используется для языкового моделирования на уровне символов и слов.
Задача состоит в том, чтобы аннотировать каждое слово его тегом Part-of-Speech. В наиболее распространенной разбивке этого корпуса для обучения используются секции с 0 по 18 (38 219предложения, 912 344 токена), разделы с 19 по 21 используются для проверки (5 527 предложений, 131 768 токенов), а разделы с 22 по 24 используются для тестирования (5 462 предложения, 129 654 токена).
Корпус также обычно используется для языкового моделирования на уровне символов и слов.
1241 ДОКУМЕНТ • 14 ПОКАЗАТЕЛЕЙ
ЛибриРечь
Корпус LibriSpeech представляет собой коллекцию примерно 1000 часов аудиокниг, являющихся частью проекта LibriVox.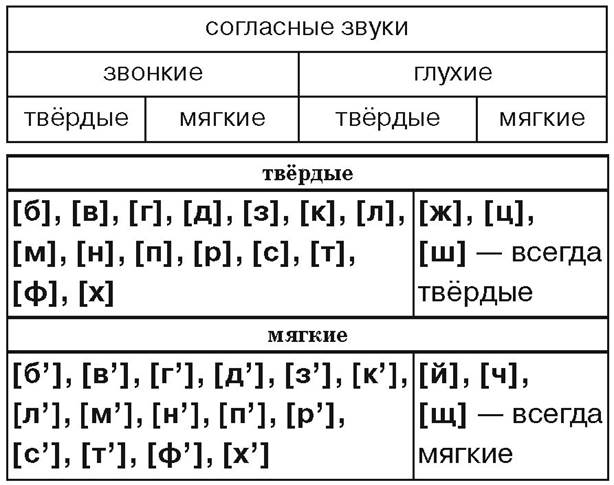 Большинство аудиокниг исходит от Project Gutenberg. Учебные данные разделены на 3 части по 100 часов, 360 часов и 500 часов, в то время как данные разработки и тестирования разделены на «чистые» и «другие» категории, соответственно, в зависимости от того, насколько хорошо или сложно будут работать системы автоматического распознавания речи. . Каждый из наборов для разработки и тестирования длится около 5 часов. Этот корпус также предоставляет языковые модели n-грамм и соответствующие тексты, взятые из книг Project Gutenberg, которые содержат 803 миллиона токенов и 977 тысяч уникальных слов.
Большинство аудиокниг исходит от Project Gutenberg. Учебные данные разделены на 3 части по 100 часов, 360 часов и 500 часов, в то время как данные разработки и тестирования разделены на «чистые» и «другие» категории, соответственно, в зависимости от того, насколько хорошо или сложно будут работать системы автоматического распознавания речи. . Каждый из наборов для разработки и тестирования длится около 5 часов. Этот корпус также предоставляет языковые модели n-грамм и соответствующие тексты, взятые из книг Project Gutenberg, которые содержат 803 миллиона токенов и 977 тысяч уникальных слов.
1201 ДОКУМЕНТ • 8 ПОКАЗАТЕЛЕЙ
UCF101 (Набор данных UCF101 Human Actions)
Набор данных UCF101 является расширением UCF50 и состоит из 13 320 видеоклипов, которые разбиты на 101 категорию. Эти 101 категорию можно разделить на 5 типов (движение тела, взаимодействие человека с человеком, взаимодействие человека с объектом, игра на музыкальных инструментах и спорт). Общая продолжительность этих видеороликов составляет более 27 часов. Все видео собраны с YouTube и имеют фиксированную частоту кадров 25 FPS при разрешении 320×240.
Эти 101 категорию можно разделить на 5 типов (движение тела, взаимодействие человека с человеком, взаимодействие человека с объектом, игра на музыкальных инструментах и спорт). Общая продолжительность этих видеороликов составляет более 27 часов. Все видео собраны с YouTube и имеют фиксированную частоту кадров 25 FPS при разрешении 320×240.
1174 ДОКУМЕНТА • 16 ПОКАЗАТЕЛЕЙ
МультиNLI (Многожанровый вывод на естественном языке)
Набор данных Multi-Genre Natural Language Inference (MultiNLI) содержит 433 000 пар предложений. Его размер и способ сбора моделируются точно так же, как SNLI.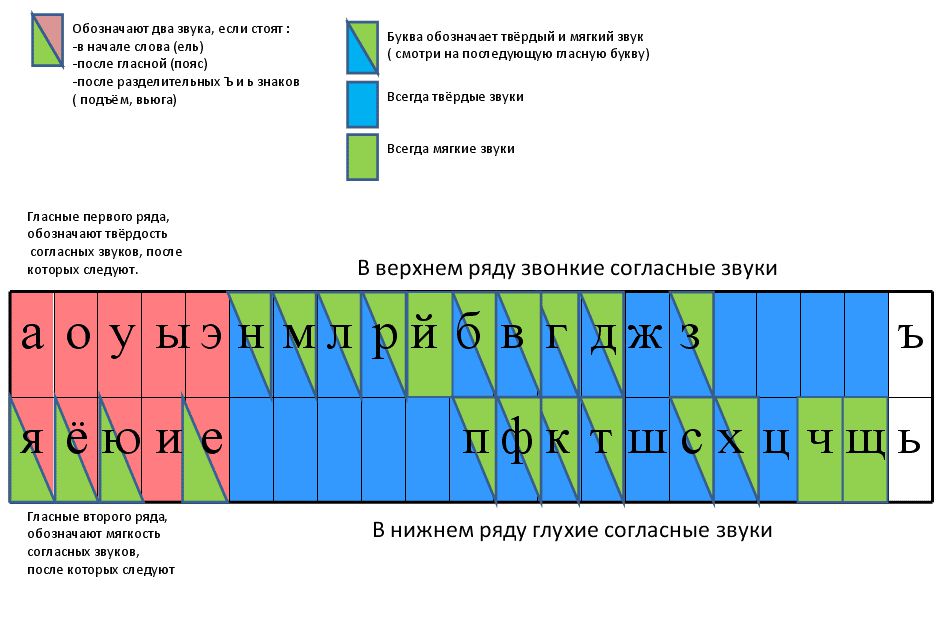 MultiNLI предлагает десять различных жанров (лицом к лицу, по телефону, 9/11, Travel, Letters, Oxford University Press, Slate, Verbatim, Goverment and Fiction) письменных и устных данных на английском языке. Существуют совпадающие наборы для разработки/тестирования, полученные из тех же источников, что и в обучающем наборе, и несовпадающие наборы, которые не очень похожи на те, что были видны во время обучения.
MultiNLI предлагает десять различных жанров (лицом к лицу, по телефону, 9/11, Travel, Letters, Oxford University Press, Slate, Verbatim, Goverment and Fiction) письменных и устных данных на английском языке. Существуют совпадающие наборы для разработки/тестирования, полученные из тех же источников, что и в обучающем наборе, и несовпадающие наборы, которые не очень похожи на те, что были видны во время обучения.
1111 ДОКУМЕНТОВ • 6 ПОКАЗАТЕЛЕЙ
IMDb Обзоры фильмов
Набор данных IMDb Movie Reviews представляет собой двоичный набор данных анализа настроений, состоящий из 50 000 обзоров из базы данных Internet Movie Database (IMDb), помеченных как положительные или отрицательные.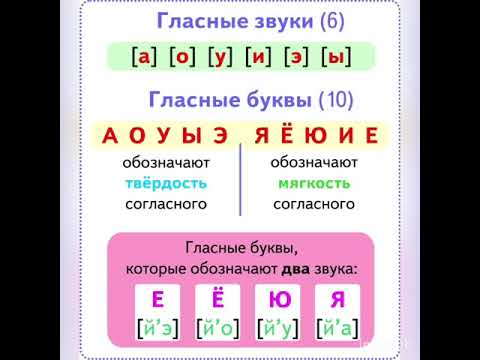 Набор данных содержит четное количество положительных и отрицательных отзывов. Учитываются только сильно поляризующие отзывы. Отрицательная рецензия имеет оценку ≤ 4 из 10, а положительная рецензия имеет оценку ≥ 7 из 10. На фильм включено не более 30 рецензий. Набор данных содержит дополнительные немаркированные данные.
Набор данных содержит четное количество положительных и отрицательных отзывов. Учитываются только сильно поляризующие отзывы. Отрицательная рецензия имеет оценку ≤ 4 из 10, а положительная рецензия имеет оценку ≥ 7 из 10. На фильм включено не более 30 рецензий. Набор данных содержит дополнительные немаркированные данные.
1092 ДОКУМЕНТА • 7 ПОКАЗАТЕЛЕЙ
Шейпнет
ShapeNet — это крупномасштабное хранилище 3D-моделей CAD, разработанное исследователями из Стэнфордского университета, Принстонского университета и Технологического института Toyota в Чикаго, США. Репозиторий содержит более 300 миллионов моделей, 220 000 из которых разделены на 3 135 классов, организованных с использованием отношений гипероним-гипоним WordNet.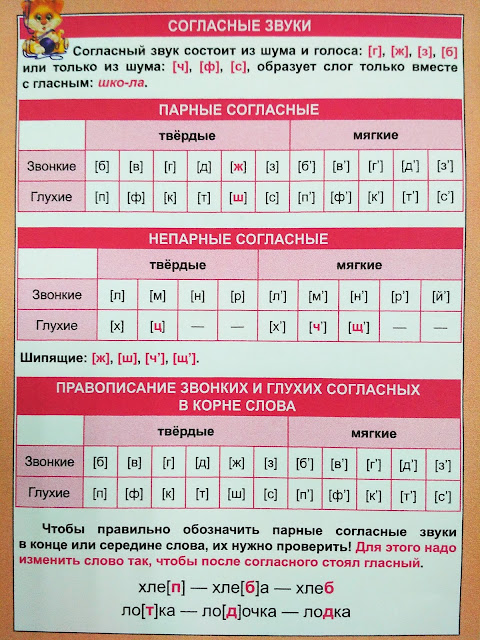 Подмножество частей ShapeNet содержит 31,693 сетки, разделенные на 16 общих классов объектов (например, стол, стул, самолет и т. д.). Наземная правда каждой формы содержит 2-5 частей (всего 50 классов деталей).
Подмножество частей ShapeNet содержит 31,693 сетки, разделенные на 16 общих классов объектов (например, стол, стул, самолет и т. д.). Наземная правда каждой формы содержит 2-5 частей (всего 50 классов деталей).
1092 ДОКУМЕНТА • 10 ПОКАЗАТЕЛЕЙ
Визуальный ответ на вопрос (ВКА)
Visual Question Answering (VQA) — это набор данных, содержащий открытые вопросы об изображениях. Эти вопросы требуют понимания видения, языка и знания здравого смысла, чтобы ответить. Первая версия набора данных была выпущена в октябре 2015 года. VQA v2.0 был выпущен в апреле 2017 года.
1078 ДОКУМЕНТОВ • 2 ПОКАЗАТЕЛЯ
СНЛИ (Стэнфордский вывод на естественном языке)
Набор данных SNLI (Stanford Natural Language Inference) состоит из 570 тысяч пар предложений, вручную помеченных как следствия, противоречия и нейтральные. Предпосылки — это подписи к изображениям из Flickr30k, а гипотезы были созданы аннотаторами из краудсорсинга, которым показывали предпосылку и просили составить подразумевающие, противоречащие и нейтральные предложения. Аннотаторам было поручено судить об отношении между предложениями, учитывая, что они описывают одно и то же событие. Каждая пара помечена как «последствия», «нейтральные», «противоречия» или «-», где «-» означает, что соглашение не может быть достигнуто.
Каждая пара помечена как «последствия», «нейтральные», «противоречия» или «-», где «-» означает, что соглашение не может быть достигнуто.
949 ДОКУМЕНТОВ • 3 ПОКАЗАТЕЛЯ
мини-Imagenet
мини-имиджнет
mini-Imagenet предлагается Matching Networks для One Shot Learning . В NeurIPS, 2016. Этот набор данных состоит из 50 000 обучающих изображений и 10 000 тестовых изображений, равномерно распределяется по 100 классам.
946 ДОКУМЕНТОВ • 18 ПОКАЗАТЕЛЕЙ
МуДжоКо
MuJoCo (многосуставная динамика с контактом) — это физический движок, используемый для реализации сред для оценки методов обучения с подкреплением.
939 ДОКУМЕНТОВ • 2 ПОКАЗАТЕЛЯ
Тренажерный зал OpenAI
OpenAI Gym — это набор инструментов для разработки и сравнения алгоритмов обучения с подкреплением. Он включает в себя такие среды, как Algorithmic, Atari, Box2D, Classic Control, MuJoCo, Robotics и Toy Text.
934 ДОКУМЕНТА • 3 ПОКАЗАТЕЛЯ
Модельнет
Набор данных ModelNet40 содержит облака точек синтетических объектов.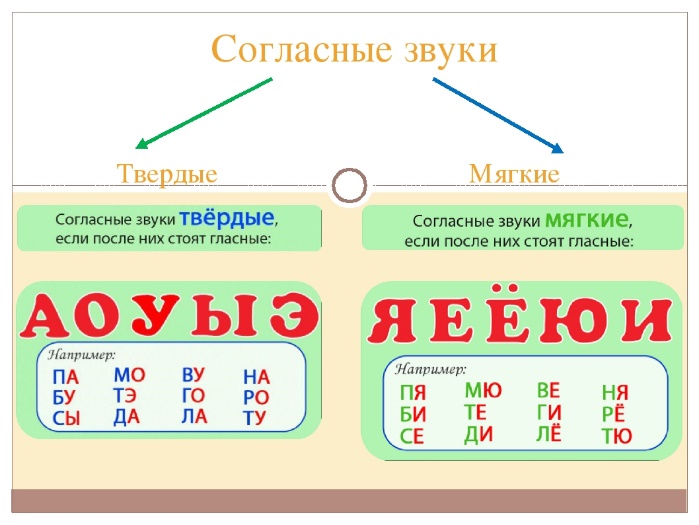 ModelNet40, как наиболее широко используемый эталонный тест для анализа облаков точек, популярен благодаря своим различным категориям, четким формам, хорошо структурированному набору данных и т. д. Первоначальный ModelNet40 состоит из 12 311 сгенерированных САПР сеток в 40 категориях (таких как самолет, автомобиль, растение, светильник), из них 9843 используются для обучения, а остальные 2468 зарезервированы для тестирования. Соответствующие точки данных облака точек равномерно выбираются из поверхностей сетки, а затем дополнительно обрабатываются путем перемещения к исходной точке и масштабирования в единичную сферу.
ModelNet40, как наиболее широко используемый эталонный тест для анализа облаков точек, популярен благодаря своим различным категориям, четким формам, хорошо структурированному набору данных и т. д. Первоначальный ModelNet40 состоит из 12 311 сгенерированных САПР сеток в 40 категориях (таких как самолет, автомобиль, растение, светильник), из них 9843 используются для обучения, а остальные 2468 зарезервированы для тестирования. Соответствующие точки данных облака точек равномерно выбираются из поверхностей сетки, а затем дополнительно обрабатываются путем перемещения к исходной точке и масштабирования в единичную сферу.
879 ДОКУМЕНТОВ • 7 ПОКАЗАТЕЛЕЙ
Кинетика (Набор видеоданных Kinetics Human Action)
Набор данных Kinetics — это крупномасштабный высококачественный набор данных для распознавания действий человека в видео. Набор данных состоит из около 500 000 видеоклипов, охватывающих 600 классов действий человека, по крайней мере, 600 видеоклипов для каждого класса действий. Каждый видеоклип длится около 10 секунд и помечен одним классом действий. Видео собраны с YouTube.
Набор данных состоит из около 500 000 видеоклипов, охватывающих 600 классов действий человека, по крайней мере, 600 видеоклипов для каждого класса действий. Каждый видеоклип длится около 10 секунд и помечен одним классом действий. Видео собраны с YouTube.
798 ДОКУМЕНТОВ • 19 ПОКАЗАТЕЛЕЙ
Визуальный геном
Visual Genome содержит данные визуальных ответов на вопросы в настройках с множественным выбором. Он состоит из 101 174 изображений от MSCOCO с 1,7 миллионами пар QA, в среднем 17 вопросов на изображение. По сравнению с набором данных Visual Question Answering, Visual Genome представляет собой более сбалансированное распределение по 6 типам вопросов: что, где, когда, кто, почему и как. Набор данных Visual Genome также представляет 108 000 изображений с густо аннотированными объектами, атрибутами и отношениями.
Набор данных Visual Genome также представляет 108 000 изображений с густо аннотированными объектами, атрибутами и отношениями.
793 ДОКУМЕНТА • 17 ПОКАЗАТЕЛЕЙ
ФильмОбъектив
Наборы данных MovieLens, впервые выпущенные в 1998 году, описывают выраженные предпочтения людей в отношении фильмов. Эти предпочтения имеют форму кортежей, каждый из которых является результатом выражения человеком предпочтения (рейтинг от 0 до 5 звезд) для фильма в определенное время. Эти настройки были введены через веб-сайт MovieLens1 — рекомендательную систему, которая просит своих пользователей давать оценки фильмам, чтобы получать персонализированные рекомендации фильмов.
756 ДОКУМЕНТОВ • 12 ПОКАЗАТЕЛЕЙ
Опубликовано
Опубликовано
Набор данных Pubmed состоит из 19717 научных публикаций из базы данных PubMed, касающихся диабета, отнесенного к одному из трех классов. Сеть цитирования состоит из 44338 ссылок. Каждая публикация в наборе данных описывается взвешенным вектором слов TF/IDF из словаря, состоящего из 500 уникальных слов.
715 ДОКУМЕНТОВ • 16 ПОКАЗАТЕЛЕЙ
Места
Набор данных Places предлагается для распознавания сцен и содержит более 2,5 миллионов изображений, охватывающих более 205 категорий сцен с более чем 5000 изображений в каждой категории.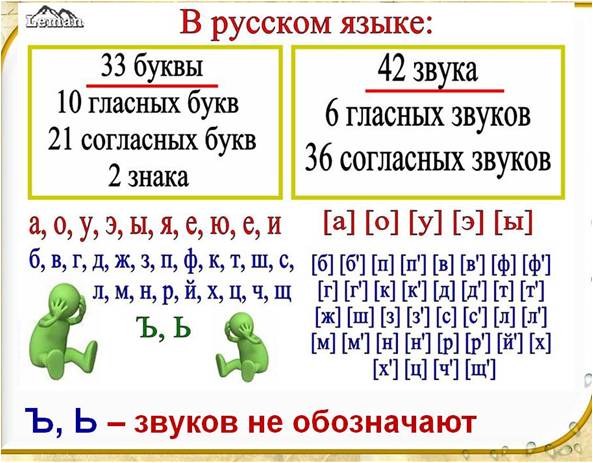
696 ДОКУМЕНТОВ • 4 ПОКАЗАТЕЛЯ
LFW (с надписью «Лица в дикой природе»)
Набор данных LFW содержит 13 233 изображения лиц, собранных из Интернета. Этот набор данных состоит из 5749удостоверения личности с 1680 людьми с двумя и более изображениями. В стандартном протоколе оценки LFW сообщается о точности проверки для 6000 пар лиц.
681 ДОКУМЕНТЫ • 6 ПОКАЗАТЕЛЕЙ
Рынок-1501
Market-1501 — это крупномасштабный общедоступный эталонный набор данных для повторной идентификации личности. Он содержит 1501 личность, захваченную шестью разными камерами, и 32 668 ограничивающих рамок изображений пешеходов, полученных с помощью детектора пешеходов моделей деформируемых частей. У каждого человека в среднем 3,6 изображения с каждой точки зрения. Набор данных разделен на две части: 750 идентификаторов используются для обучения, а оставшиеся 751 идентификатор используются для тестирования. В официальном протоколе тестирования 3368 изображений-запросов выбираются в качестве тестового набора, чтобы найти правильное совпадение среди 19 изображений.732 изображения галереи ссылок.
Он содержит 1501 личность, захваченную шестью разными камерами, и 32 668 ограничивающих рамок изображений пешеходов, полученных с помощью детектора пешеходов моделей деформируемых частей. У каждого человека в среднем 3,6 изображения с каждой точки зрения. Набор данных разделен на две части: 750 идентификаторов используются для обучения, а оставшиеся 751 идентификатор используются для тестирования. В официальном протоколе тестирования 3368 изображений-запросов выбираются в качестве тестового набора, чтобы найти правильное совпадение среди 19 изображений.732 изображения галереи ссылок.
680 ДОКУМЕНТОВ • 8 ПОКАЗАТЕЛЕЙ
СТЛ-10 (Самообучение 10)
STL-10 — это набор данных изображений, полученный из ImageNet и широко используемый для оценки алгоритмов неконтролируемого изучения признаков или самообучения.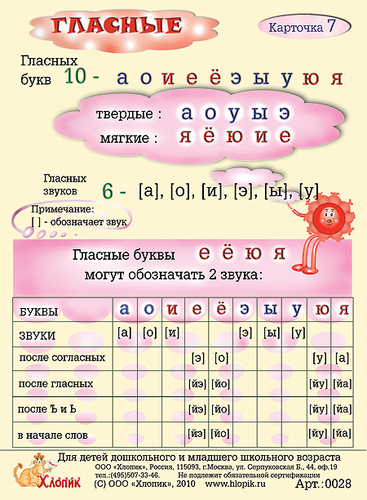 Помимо 100 000 немаркированных изображений, он содержит 13 000 помеченных изображений из 10 классов объектов (таких как птицы, кошки, грузовики), среди которых 5 000 изображений разделены для обучения, а остальные 8 000 изображений — для тестирования. Все изображения цветные с 9Размер 6×96 пикселей.
Помимо 100 000 немаркированных изображений, он содержит 13 000 помеченных изображений из 10 классов объектов (таких как птицы, кошки, грузовики), среди которых 5 000 изображений разделены для обучения, а остальные 8 000 изображений — для тестирования. Все изображения цветные с 9Размер 6×96 пикселей.
642 ДОКУМЕНТА • 13 ПОКАЗАТЕЛЕЙ
nuScenes
Набор данных nuScenes представляет собой крупномасштабный набор данных для автономного вождения. Набор данных содержит трехмерные ограничивающие рамки для 1000 сцен, собранных в Бостоне и Сингапуре. Каждая сцена длится 20 секунд и аннотируется с частотой 2 Гц. В итоге получается 28130 образцов для обучения, 6019образцы для проверки и 6008 образцов для тестирования. Набор данных содержит полный набор данных об автономных транспортных средствах: 32-лучевой лидар, 6 камер и радаров с полным охватом 360°. Задача обнаружения 3D-объектов оценивает производительность по 10 классам: автомобили, грузовики, автобусы, прицепы, строительные машины, пешеходы, мотоциклы, велосипеды, дорожные конусы и барьеры.
В итоге получается 28130 образцов для обучения, 6019образцы для проверки и 6008 образцов для тестирования. Набор данных содержит полный набор данных об автономных транспортных средствах: 32-лучевой лидар, 6 камер и радаров с полным охватом 360°. Задача обнаружения 3D-объектов оценивает производительность по 10 классам: автомобили, грузовики, автобусы, прицепы, строительные машины, пешеходы, мотоциклы, велосипеды, дорожные конусы и барьеры.
623 ДОКУМЕНТА • 12 ПОКАЗАТЕЛЕЙ
КАРЛА (Машина учится действовать)
CARLA (CAR Learning to Act) — это открытый симулятор вождения в городе, разработанный как слой с открытым исходным кодом поверх Unreal Engine 4.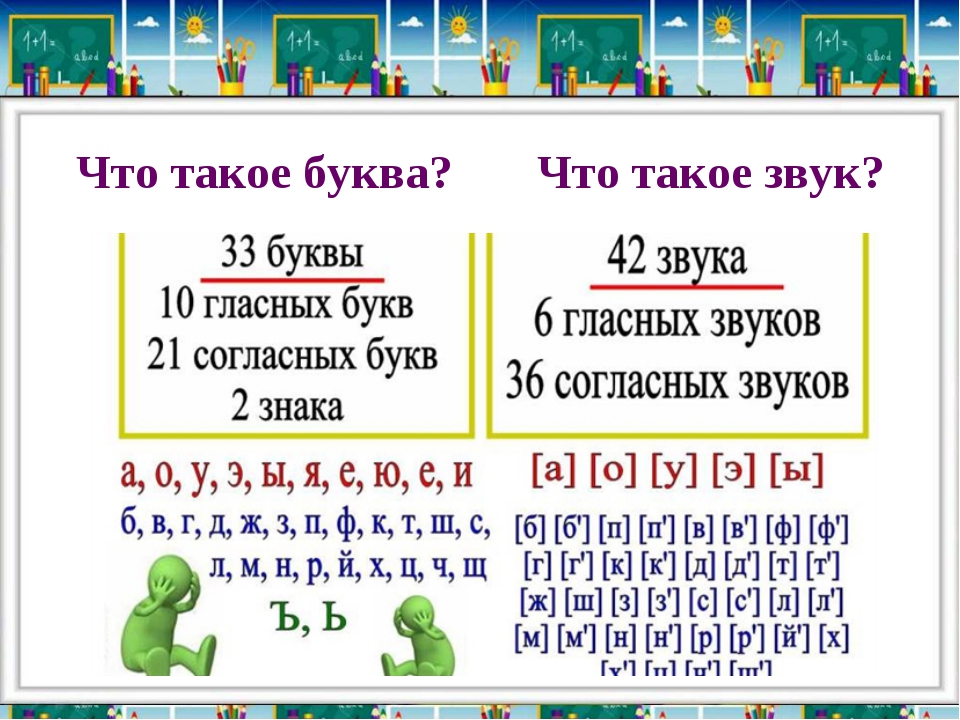 Технически он работает аналогично слою с открытым исходным кодом поверх Unreal Engine 4, который предоставляет датчики в виде Камеры RGB (с настраиваемыми позициями), карты глубины наземных правд, карты семантической сегментации наземных правд с 12 семантическими классами, предназначенными для вождения (дорога, разметка полосы движения, дорожный знак, тротуар и т. д.), ограничивающие рамки для динамических объектов в окружающей среде и измерения самого агента (местоположение и ориентация транспортного средства).
Технически он работает аналогично слою с открытым исходным кодом поверх Unreal Engine 4, который предоставляет датчики в виде Камеры RGB (с настраиваемыми позициями), карты глубины наземных правд, карты семантической сегментации наземных правд с 12 семантическими классами, предназначенными для вождения (дорога, разметка полосы движения, дорожный знак, тротуар и т. д.), ограничивающие рамки для динамических объектов в окружающей среде и измерения самого агента (местоположение и ориентация транспортного средства).
615 ДОКУМЕНТОВ • 2 ПОКАЗАТЕЛЯ
QNLI (вопросно-ответный НЛИ)
Набор данных QNLI (вопросно-ответный NLI) представляет собой набор данных для вывода на естественном языке, автоматически полученный из Стэнфордского набора данных для ответов на вопросы v1. 1 (SQuAD). SQuAD v1.1 состоит из пар вопрос-абзац, где одно из предложений в абзаце (взято из Википедии) содержит ответ на соответствующий вопрос (написанный комментатором). Набор данных был преобразован в классификацию пар предложений путем формирования пары между каждым вопросом и каждым предложением в соответствующем контексте и фильтрации пар с низким лексическим перекрытием между вопросом и контекстным предложением. Задача состоит в том, чтобы определить, содержит ли контекстное предложение ответ на вопрос. Эта модифицированная версия исходной задачи удаляет требование, чтобы модель выбирала точный ответ, но также удаляет упрощающие предположения о том, что ответ всегда присутствует во входных данных и что лексическое перекрытие является надежным сигналом. Набор данных QNLI является частью теста GLEU.
1 (SQuAD). SQuAD v1.1 состоит из пар вопрос-абзац, где одно из предложений в абзаце (взято из Википедии) содержит ответ на соответствующий вопрос (написанный комментатором). Набор данных был преобразован в классификацию пар предложений путем формирования пары между каждым вопросом и каждым предложением в соответствующем контексте и фильтрации пар с низким лексическим перекрытием между вопросом и контекстным предложением. Задача состоит в том, чтобы определить, содержит ли контекстное предложение ответ на вопрос. Эта модифицированная версия исходной задачи удаляет требование, чтобы модель выбирала точный ответ, но также удаляет упрощающие предположения о том, что ответ всегда присутствует во входных данных и что лексическое перекрытие является надежным сигналом. Набор данных QNLI является частью теста GLEU.
615 ДОКУМЕНТОВ • 3 ПОКАЗАТЕЛЯ
FFHQ (Flickr-Faces-HQ)
Flickr-Faces-HQ (FFHQ) состоит из 70 000 высококачественных изображений в формате PNG с разрешением 1024×1024 и содержит значительные различия с точки зрения возраста, этнической принадлежности и фона изображения.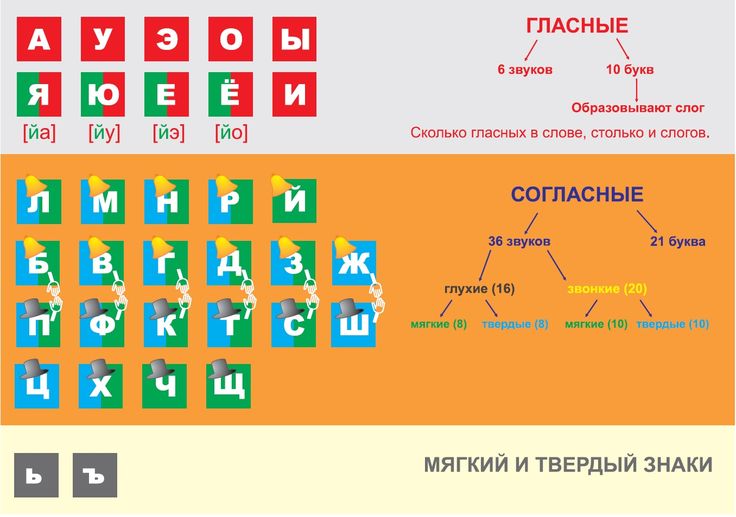 Он также хорошо охватывает такие аксессуары, как очки, солнцезащитные очки, головные уборы и т. д. Изображения были просканированы с Flickr, таким образом унаследовав все предубеждения этого веб-сайта, и автоматически выровнены и обрезаны с помощью dlib. Были собраны только изображения под разрешающими лицензиями. Для обрезки набора использовались различные автоматические фильтры, и, наконец, Amazon Mechanical Turk был использован для удаления случайных статуй, картин или фотографий с фотографий.
Он также хорошо охватывает такие аксессуары, как очки, солнцезащитные очки, головные уборы и т. д. Изображения были просканированы с Flickr, таким образом унаследовав все предубеждения этого веб-сайта, и автоматически выровнены и обрезаны с помощью dlib. Были собраны только изображения под разрешающими лицензиями. Для обрезки набора использовались различные автоматические фильтры, и, наконец, Amazon Mechanical Turk был использован для удаления случайных статуй, картин или фотографий с фотографий.
601 ДОКУМЕНТЫ • 12 ПОКАЗАТЕЛЕЙ
Сканнет
ScanNet — это набор данных RGB-D для помещений на уровне экземпляра, который включает в себя как 2D-, так и 3D-данные.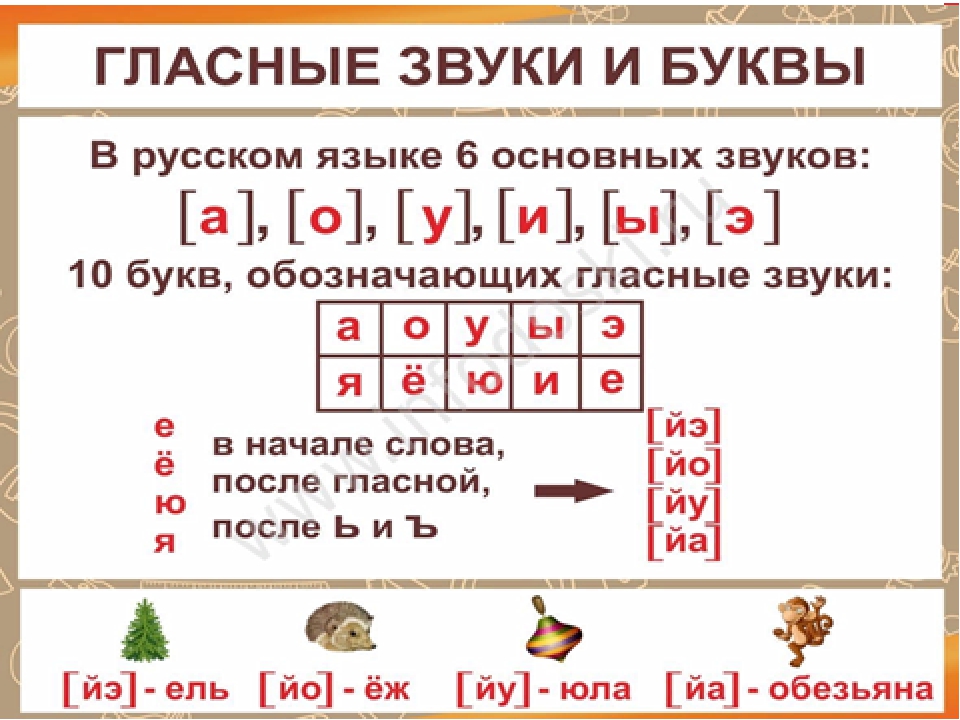 Это набор помеченных вокселей, а не точек или объектов. К настоящему времени ScanNet v2, новейшая версия ScanNet, собрала 1513 аннотированных сканов с примерно 90% покрытия поверхности. В задаче семантической сегментации этот набор данных размечается в 20 классах аннотированных трехмерных вокселизированных объектов.
Это набор помеченных вокселей, а не точек или объектов. К настоящему времени ScanNet v2, новейшая версия ScanNet, собрала 1513 аннотированных сканов с примерно 90% покрытия поверхности. В задаче семантической сегментации этот набор данных размечается в 20 классах аннотированных трехмерных вокселизированных объектов.
592 ДОКУМЕНТА • 14 ПОКАЗАТЕЛЕЙ
HMDB51
Набор данных HMDB51 представляет собой большую коллекцию реалистичных видеороликов из различных источников, включая фильмы и веб-видео. Набор данных состоит из 6849видеоклипы из 51 категории действий (например, «прыгать», «поцелуй» и «смех»), причем каждая категория содержит не менее 101 клипа. Первоначальная схема оценки использует три различных сплита обучения/тестирования. В каждом сплите у каждого класса действия есть 70 клипов для обучения и 30 клипов для тестирования. Средняя точность по этим трем разделениям используется для измерения окончательной производительности.
Первоначальная схема оценки использует три различных сплита обучения/тестирования. В каждом сплите у каждого класса действия есть 70 клипов для обучения и 30 клипов для тестирования. Средняя точность по этим трем разделениям используется для измерения окончательной производительности.
587 ДОКУМЕНТОВ • 13 ПОКАЗАТЕЛЕЙ
МИМИК-III (Магазин медицинской информации для интенсивной терапии III)
Набор данных Medical Information Mart for Intensive Care III (MIMIC-III) представляет собой большую, обезличенную и общедоступную коллекцию медицинских записей. Каждая запись в наборе данных включает МКБ-9.коды, которые идентифицируют диагнозы и выполненные процедуры. Каждый код разделен на подкоды, которые часто включают конкретные косвенные детали. Набор данных состоит из 112 000 записей клинических отчетов (средняя длина 709,3 токена) и 1159 кодов МКБ-9 верхнего уровня. Каждому отчету присваивается в среднем 7,6 кодов. Данные включают основные показатели жизнедеятельности, лекарства, лабораторные измерения, наблюдения и заметки медицинских работников, баланс жидкости, коды процедур, диагностические коды, отчеты о визуализации, продолжительность пребывания в больнице, данные о выживаемости и многое другое.
Каждая запись в наборе данных включает МКБ-9.коды, которые идентифицируют диагнозы и выполненные процедуры. Каждый код разделен на подкоды, которые часто включают конкретные косвенные детали. Набор данных состоит из 112 000 записей клинических отчетов (средняя длина 709,3 токена) и 1159 кодов МКБ-9 верхнего уровня. Каждому отчету присваивается в среднем 7,6 кодов. Данные включают основные показатели жизнедеятельности, лекарства, лабораторные измерения, наблюдения и заметки медицинских работников, баланс жидкости, коды процедур, диагностические коды, отчеты о визуализации, продолжительность пребывания в больнице, данные о выживаемости и многое другое.
585 ДОКУМЕНТОВ • 7 ПОКАЗАТЕЛЕЙ
НеРФ (Поля нейронного излучения)
Neural Radiance Fields (NeRF) — это метод синтеза новых представлений сложных сцен путем оптимизации лежащей в основе функции непрерывной объемной сцены с использованием разреженного набора входных представлений. Набор данных состоит из трех частей, первые две из которых представляют собой синтетические визуализации объектов, называемые Diffuse Synthetic 360◦ и Realistic Synthetic 360◦, а третья — реальные изображения сложных сцен. Diffuse Synthetic 360◦ состоит из четырех ламбертовских объектов с простой геометрией. Каждый объект визуализируется с разрешением 512×512 пикселей с точек обзора, выбранных в верхней полусфере. Realistic Synthetic 360◦ состоит из восьми объектов сложной геометрии и реалистичных неламбертовских материалов. Шесть из них визуализируются из точек обзора, выбранных в верхней полусфере, а два левых — из точек обзора, выбранных в полной сфере, причем все они имеют разрешение 800×800 пикселей. Реальные изображения сложных сцен состоят из 8 сцен, обращенных вперед, снятых мобильным телефоном, размером 1008×756 пикселей.
Набор данных состоит из трех частей, первые две из которых представляют собой синтетические визуализации объектов, называемые Diffuse Synthetic 360◦ и Realistic Synthetic 360◦, а третья — реальные изображения сложных сцен. Diffuse Synthetic 360◦ состоит из четырех ламбертовских объектов с простой геометрией. Каждый объект визуализируется с разрешением 512×512 пикселей с точек обзора, выбранных в верхней полусфере. Realistic Synthetic 360◦ состоит из восьми объектов сложной геометрии и реалистичных неламбертовских материалов. Шесть из них визуализируются из точек обзора, выбранных в верхней полусфере, а два левых — из точек обзора, выбранных в полной сфере, причем все они имеют разрешение 800×800 пикселей. Реальные изображения сложных сцен состоят из 8 сцен, обращенных вперед, снятых мобильным телефоном, размером 1008×756 пикселей.
572 ДОКУМЕНТА • 1 ЭТАЛОН
NYUv2 (NYU-Глубина V2)
Набор данных NYU-Depth V2 состоит из видеопоследовательностей различных внутренних сцен, записанных камерами RGB и Depth от Microsoft Kinect. Особенности:
Особенности:
564 ДОКУМЕНТА • 17 ПОКАЗАТЕЛЕЙ
Концептнет
ConceptNet — это граф знаний, который соединяет слова и фразы естественного языка с помеченными ребрами. Его знания собираются из многих источников, включая ресурсы, созданные экспертами, краудсорсинг и целенаправленные игры. Он предназначен для представления общих знаний, связанных с пониманием языка, улучшения приложений на естественном языке, позволяя приложению лучше понимать значения слов, которые люди используют.
560 ДОКУМЕНТОВ • ПОКА НЕТ ЭТАЛОННЫХ
Оксфорд 102 цветок (Набор данных цветов 102 категорий)
Oxford 102 Flower — это набор данных для классификации изображений, состоящий из 102 категорий цветов. В качестве цветов выбраны цветы, обычно произрастающие в Соединенном Королевстве. Каждый класс состоит из от 40 до 258 изображений.
В качестве цветов выбраны цветы, обычно произрастающие в Соединенном Королевстве. Каждый класс состоит из от 40 до 258 изображений.
552 ДОКУМЕНТА • 12 ПОКАЗАТЕЛЕЙ
Офис-Дом
Office-Home — это эталонный набор данных для адаптации домена, который содержит 4 домена, каждый из которых состоит из 65 категорий. Четыре домена: Искусство – художественные образы в виде эскизов, картин, орнаментов и т. д.; Клипарт – коллекция клипартов; Продукт — изображения объектов без фона и Real-World — изображения объектов, снятые обычной камерой. Он содержит 15 500 изображений, в среднем около 70 изображений на класс и максимум 9 изображений. 9 изображений в классе.
9 изображений в классе.
542 ДОКУМЕНТА • 9 ПОКАЗАТЕЛЕЙ
LSUN (Масштабная задача понимания сцены)
Целью задачи «Понимание крупномасштабных сцен» (LSUN) является предоставление другого эталона для классификации и понимания крупномасштабных сцен. Набор данных классификации LSUN содержит 10 категорий сцен, таких как столовая, спальня, курица, церковь под открытым небом и так далее. Для обучающих данных каждая категория содержит огромное количество изображений, от 120 000 до 3 000 000. Данные проверки включают 300 изображений, а данные тестирования содержат 1000 изображений для каждой категории.