Таблица умножения тренажер распечатать без ответов в разброс: Таблица умножения: тренажер в разброс – скачать и распечатать
Окно в Мир
| |||
Распечатать | Таблица умножения
Обратите внимание! На сайте есть новый вариант тренажёра для распечатывания двусторонних карточек с примерами для самопроверки таблицы умножения и деления. Это один из очень удобных способов выучить таблицу умножения быстро и легко. Подробнее о нем в конце статьи.
Это один из очень удобных способов выучить таблицу умножения быстро и легко. Подробнее о нем в конце статьи.
Онлайн тест можно выбрать на отдельной странице.
Но сначала здесь выложен обычный тренажёр с упражнениями для распечатывания, в котором примеры из таблицы представлены без ответов, а ответы нужно вписать (есть картинки и файлы Word)
Картинки с тренажером таблицы умножения, примеры для распечатывания.Картинки представлены в нескольких вариантах оформления: с заданиями вразброс, с заданиями по порядку (этот вариант значительно легче, он подходит для того, чтобы потренироваться считать двойками (2,4,6,8), тройками (3,6,9,12 ) и т.д.).
Для того же, чтобы проверить знание всей таблицы, больше подойдет вариант, в котором задания идут вразброс (иногда такой вид расположения примеров в упражнении называют “вразнобой”).
Картинка: тренажер таблицы умножения, примеры для распечатывания без ответов, по порядку.
Картинка: тренажер таблицы умножения, примеры для распечатывания без ответов, вразброс.
Как обычно, мы не выделяем тренажер с упражнениями для 2 класса или для 3 класса и т.д., но на сайте есть большой выбор материалов, чтобы каждый сам мог выбрать подходящие. Более того, на сайте есть онлайн – тренажер с большим разнообразием интерактивных заданий и упражнений (от простого поиска ответа до интерактивных двусторонних карточек, которые можно перевернуть прямо на экране монитора, они также как и бумажные двусторонние карточки подходят для самопроверки. Если же нужен тест-тренажер с автоматической проверкой, то для этого также есть широкий выбор от заданий с необходимость вписать ответ, до еще одного варианта карточек – тренажера, но уже с автоматической проверкой. Подробнее об этом написано на странице выбора онлайн-теста.
Также есть картинка и файлы Word тренажера таблицы Пифагора.
Таблицей Пифагора сейчас называют таблицу умножения в виде квадрата, поделенного на ячейки, где столбцы и строки озаглавлены множителями по порядку, а в ячейке на пересечении соответствующих столбцов и строк расположены результаты умножения заголовка столбца на заголовок строки, произведения.
Таблица Пифагора, тренажер без ответов.
Таблица Пифагора до 20 умножить на 20, тренажер без ответов.
Таблица Пифагора с частью ответов. 1.
Таблица Пифагора с частью ответов. 2.
Таблица Пифагора цветная до 12 с диагональю без ответов, 2 на листе. Тренажер.
Двусторонние карточки для распечатывания. Тренажер для самопроверки.
Пользоваться им очень просто. С одной стороны карточки – вопрос (например 2 умножить на 2), с другой – ответ (4). Карточки можно скачать на этой странице или сделать самостоятельно: вырезать на картоне и написать от руки вопросы и ответы или же сделать электронную версию и напечать.
Обычно для изучения таблицы с помощью этих карточек нужно положить их заданиями вверх в стопочку и по очереди брать по одной карточке, решать пример (мысленно или записывая ответ на бумагу). Карточки с неправильными ответами, если такие будут, нужно складывать в отдельную стопку, так можно будет потом повторить самые сложные задания.
В новой компактной версии весь тренажер помещается на листе А4, иногда на двух листах A4, при чем даже при печати на простом тонком листе бумаги при аккуратном использовании карточки хорошо сохраняются. После распечатывания лист нужно разрезать, чтобы отделить каждое задание. Очень удобно после этого скрепить для хранения каждую часть таблицы (на 2, на 3 и т.
Размер карточек подобран так, что весь тренажер можно положить в маленький пенал (достаточно размера 3 на 4 см, т.е. самой маленькой сумочки или самого маленького кошелёчка). Для удобства карточки лучше разделить на части (карточки – тренажер умножения на 2, умножения на 3, 4, 5, 6, 7, 8, 9, 10), так, изучая таблицу по частям, Вы сможете сразу найти нужную часть.
Файл для скачивания бесплатно будет в конце этой статьи. В этом видео показано, как удобнее распечатывать карточки.
Как сделать такие карточки таблицы умножения в текстовом редакторе самостоятельно своими руками.
Файлы Word с двусторонним карточками тренажером (с одной стороны – задание, с другой – ответ).
Вместе с файлами по таблице умножения ниже будут представлены и файлы для скачивания и распечатывания с тренажером таблицы деления.
Также в списке ниже есть файлы с тренажером в формате Word (.doc), в котором нужно просто вписать ответы. Скачав нижепредставленные файлы, Вы сможете либо сразу напечатать тренажёр полностью со всей таблицей, либо же самостоятельно отредактировать файл, чтобы и напечатать отдельно тренажер умножения на 2, на 3, на 4 и т.д. или, например, часть таблицы (умножение до 5, до 6, до 7 и т.д.).
Тренажер. Умножение на 1, примеры (отдельно для распечатывания без ответов, вразброс). 3 х 1 = |
Тренажер. Умножение на 2, примеры (отдельно для распечатывания без ответов, вразброс). 3 х 2 = |
Тренажер. 3 х 3 = |
Тренажер. Умножение на 4, примеры (отдельно для распечатывания без ответов, вразброс). 3 х 4 = |
Тренажер. Умножение на 5, примеры (отдельно для распечатывания без ответов, вразброс). 3 х 5 = |
Тренажер. Умножение на 6, примеры (отдельно для распечатывания без ответов, вразброс). 3 х 6 = |
Тренажер. 3 х 7 = |
Тренажер. Умножение на 8, примеры (отдельно для распечатывания без ответов, вразброс). 3 х 8 = |
Тренажер. Умножение на 9, примеры (отдельно для распечатывания без ответов, вразброс). 3 х 9 = |
Тренажер. Умножение на 10, примеры (отдельно для распечатывания без ответов, вразброс). 3 х 10 = |
 Умножение на 3, примеры (отдельно для распечатывания без ответов, вразброс).
Умножение на 3, примеры (отдельно для распечатывания без ответов, вразброс).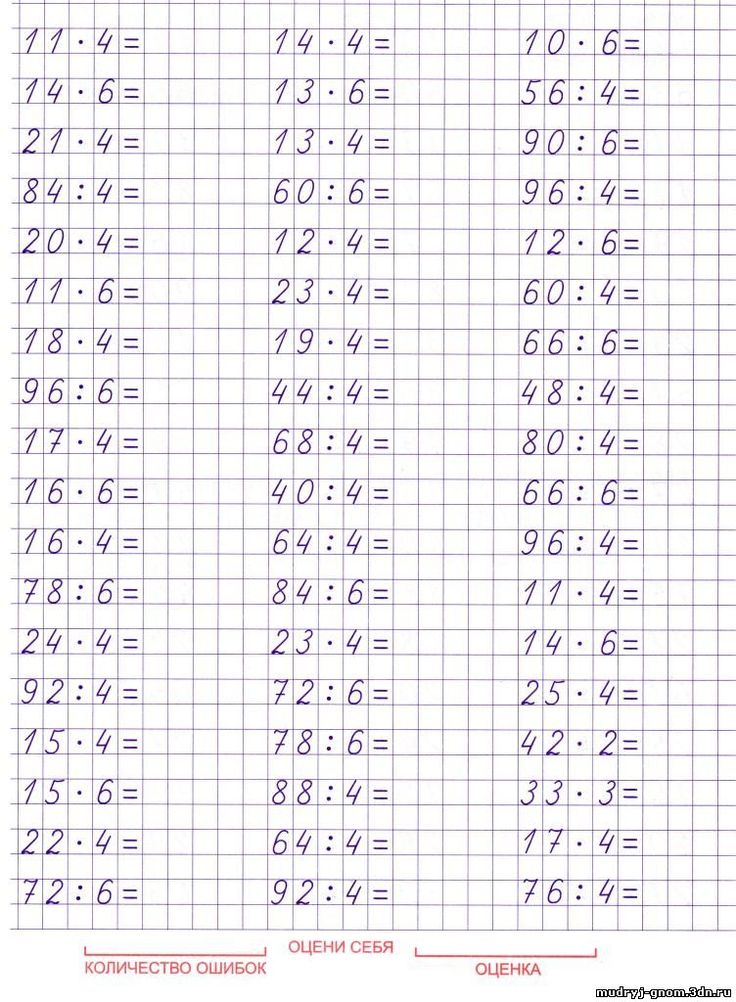 Умножение на 7, примеры (отдельно для распечатывания без ответов, вразброс).
Умножение на 7, примеры (отдельно для распечатывания без ответов, вразброс).Тренажер. Деление на 1 ( упражнения отдельно для распечатывания без ответов, по порядку)
Деление на 1 ( упражнения отдельно для распечатывания без ответов, по порядку)
Тренажер. Деление на 2 (отдельно для распечатывания без ответов, по порядку) 2 : 2 = | ||||||||||
| 4 : 2 = | ||||||||||
| 6 : 2 = | ||||||||||
| 8 : 2 = | ||||||||||
| 10 : 2 = | ||||||||||
| 12 : 2 = | ||||||||||
| 14 : 2 = | ||||||||||
| 16 : 2 = | ||||||||||
| 18 : 2 = | ||||||||||
| 20 : 2 = | ||||||||||
Тренажер. Деление на 3 (отдельно для распечатывания без ответов, по порядку) 3 : 3 = | ||||||||||
| 6 : 3 = | ||||||||||
| 9 : 3 = | ||||||||||
| 12 : 3 = | ||||||||||
| 15 : 3 = | ||||||||||
| 18 : 3 = | ||||||||||
| 21 : 3 = | ||||||||||
| 24 : 3 = | ||||||||||
| 27 : 3 = | ||||||||||
| 30 : 3 = | ||||||||||
Тренажер. 4 : 4 = | ||||||||||
| 8 : 4 = | ||||||||||
| 12 : 4 = | ||||||||||
| 16 : 4 = | ||||||||||
| 20 : 4 = | ||||||||||
| 24 : 4 = | ||||||||||
| 28 : 4 = | ||||||||||
| 32 : 4 = | ||||||||||
| 36 : 4 = | ||||||||||
| 40 : 4 = | ||||||||||
Тренажер. Деление на 4 (отдельно для распечатывания без ответов, по порядку) 5 : 5 = | ||||||||||
| 10 : 5 = | ||||||||||
| 15 : 5 = | ||||||||||
| 20 : 5 = | ||||||||||
| 25 : 5 = | ||||||||||
| 30 : 5 = | ||||||||||
| 35 : 5 = | ||||||||||
| 40 : 5 = | ||||||||||
| 45 : 5 = | ||||||||||
| 50 : 5 = | ||||||||||
Тренажер. Деление на 6 (отдельно для распечатывания без ответов, по порядку) 6 : 6 = | ||||||||||
| 12 : 6 = | ||||||||||
| 18 : 6 = | ||||||||||
| 24 : 6 = | ||||||||||
| 30 : 6 = | ||||||||||
| 36 : 6 = | ||||||||||
| 42 : 6 = | ||||||||||
| 48 : 6 = | ||||||||||
| 54 : 6 = | ||||||||||
| 60 : 6 = | ||||||||||
Тренажер. 7 : 7 = | ||||||||||
| 14 : 7 = | ||||||||||
| 21 : 7 = | ||||||||||
| 28 : 7 = | ||||||||||
| 35 : 7 = | ||||||||||
| 42 : 7 = | ||||||||||
| 49 : 7 = | ||||||||||
| 56 : 7 = | ||||||||||
| 63 : 7 = | ||||||||||
| 70 : 7 = | ||||||||||
Тренажер. Деление на 8 (отдельно для распечатывания без ответов, по порядку) 8 : 8 = | ||||||||||
| 16 : 8 = | ||||||||||
| 24 : 8 = | ||||||||||
| 32 : 8 = | ||||||||||
| 40 : 8 = | ||||||||||
| 48 : 8 = | ||||||||||
| 56 : 8 = | ||||||||||
| 64 : 8 = | ||||||||||
| 72 : 8 = | ||||||||||
| 80 : 8 = | ||||||||||
Тренажер. Деление на 9 (отдельно для распечатывания без ответов, по порядку) 9 : 9 = | ||||||||||
| 18 : 9 = | ||||||||||
| 27 : 9 = | ||||||||||
| 36 : 9 = | ||||||||||
| 45 : 9 = | ||||||||||
| 54 : 9 = | ||||||||||
| 63 : 9 = | ||||||||||
| 72 : 9 = | ||||||||||
| 81 : 9 = | ||||||||||
| 90 : 9 = | ||||||||||
Тренажер. 10 : 10 = | ||||||||||
| 20 : 10 = | ||||||||||
| 30 : 10 = | ||||||||||
| 40 : 10 = | ||||||||||
| 50 : 10 = | ||||||||||
| 60 : 10 = | ||||||||||
| 70 : 10 = | ||||||||||
| 80 : 10 = | ||||||||||
| 90 : 10 = | ||||||||||
| 100 : 10 = |
 Деление на 4 (отдельно для распечатывания без ответов, по порядку)
Деление на 4 (отдельно для распечатывания без ответов, по порядку) Деление на 7 (отдельно для распечатывания без ответов, по порядку)
Деление на 7 (отдельно для распечатывания без ответов, по порядку) Деление на 10 (отдельно для распечатывания без ответов, по порядку)
Деление на 10 (отдельно для распечатывания без ответов, по порядку)Визуализация данных в Python с помощью plt.scatter() — Real Python
Смотреть сейчас Это руководство содержит соответствующий видеокурс, созданный командой Real Python. Посмотрите его вместе с письменным учебным пособием, чтобы углубить свое понимание: Использование plt.scatter() для визуализации данных в Python
Важной частью работы с данными является возможность визуализировать их. В Python есть несколько сторонних модулей, которые вы можете использовать для визуализации данных. Одним из самых популярных модулей является Matplotlib и его подмодуль pyplot , часто упоминаемый с использованием псевдонима plt . Matplotlib предоставляет очень универсальный инструмент под названием
Matplotlib предоставляет очень универсальный инструмент под названием plt.scatter() , который позволяет создавать как базовые, так и более сложные точечные диаграммы.
Ниже вы ознакомитесь с несколькими примерами, которые покажут вам, как эффективно использовать эту функцию.
В этом уроке вы узнаете, как:
- Создать точечную диаграмму с использованием
plt.scatter() - Использовать обязательные и необязательные входные параметры
- Настройка точечных диаграмм для базовых и более сложных графиков
- Представление более чем двух измерений на точечной диаграмме
Чтобы получить максимальную отдачу от этого руководства, вы должны быть знакомы с основами программирования Python и основами NumPy и его объекта ndarray . Вам не нужно быть знакомым с Matplotlib, чтобы следовать этому руководству, но если вы хотите узнать больше о модуле, ознакомьтесь с Python Plotting With Matplotlib (Руководство).
Бесплатный бонус: Нажмите здесь, чтобы получить доступ к бесплатному руководству по ресурсам NumPy, в котором вы найдете лучшие учебные пособия, видео и книги для улучшения ваших навыков работы с NumPy.
Создание точечных диаграмм
Точечная диаграмма — это визуальное представление того, как две переменные связаны друг с другом. Вы можете использовать точечные диаграммы, чтобы исследовать взаимосвязь между двумя переменными, например, ища любую корреляцию между ними.
В этом разделе руководства вы познакомитесь с созданием базовых диаграмм рассеивания с помощью Matplotlib. В последующих разделах вы узнаете, как дополнительно настраивать графики для представления более сложных данных с использованием более двух измерений.
Удалить рекламу
Начало работы с
plt.scatter() Прежде чем вы сможете начать работать с plt.scatter() , вам необходимо установить Matplotlib. Вы можете сделать это с помощью стандартного диспетчера пакетов Python,
Вы можете сделать это с помощью стандартного диспетчера пакетов Python, pip , выполнив в консоли следующую команду:
$ python -m pip установить matplotlib
Теперь, когда вы установили Matplotlib, рассмотрите следующий вариант использования. Кафе продает шесть различных видов апельсиновых напитков в бутылках. Владелец хочет понять взаимосвязь между ценой напитков и количеством каждого из них, которое он продает, поэтому он отслеживает, сколько каждого напитка он продает каждый день. Вы можете визуализировать эту связь следующим образом:
импортировать matplotlib.pyplot как plt цена = [2,50, 1,23, 4,02, 3,25, 5,00, 4,40] продаж_за_день = [34, 62, 49, 22, 13, 19] plt.scatter (цена, продажи_за_день) plt.show()
В этом сценарии Python вы импортируете подмодуль pyplot из Matplotlib, используя псевдоним plt . Этот псевдоним обычно используется по соглашению для сокращения имен модулей и подмодулей. Затем вы создаете списки с ценой и средними продажами в день для каждого из шести проданных апельсиновых напитков.
Наконец, вы создаете точечную диаграмму, используя plt.scatter() с двумя переменными, которые вы хотите сравнить, в качестве входных аргументов. Поскольку вы используете сценарий Python, вам также необходимо явно отобразить фигуру с помощью plt.show() .
Когда вы используете интерактивную среду, такую как консоль или Jupyter Notebook, вам не нужно вызывать plt.show() . В этом уроке все примеры будут в виде скриптов и будут включать вызов plt.show() .
Вот результат этого кода:
Этот график показывает, что, как правило, чем дороже напиток, тем меньше товаров продается. Однако напиток, который стоит 4,02 доллара, является исключением, что может свидетельствовать о том, что это особенно популярный продукт. При таком использовании точечных диаграмм тщательная проверка может помочь вам изучить взаимосвязь между переменными. Затем вы можете провести дальнейший анализ, используя линейную регрессию или другие методы.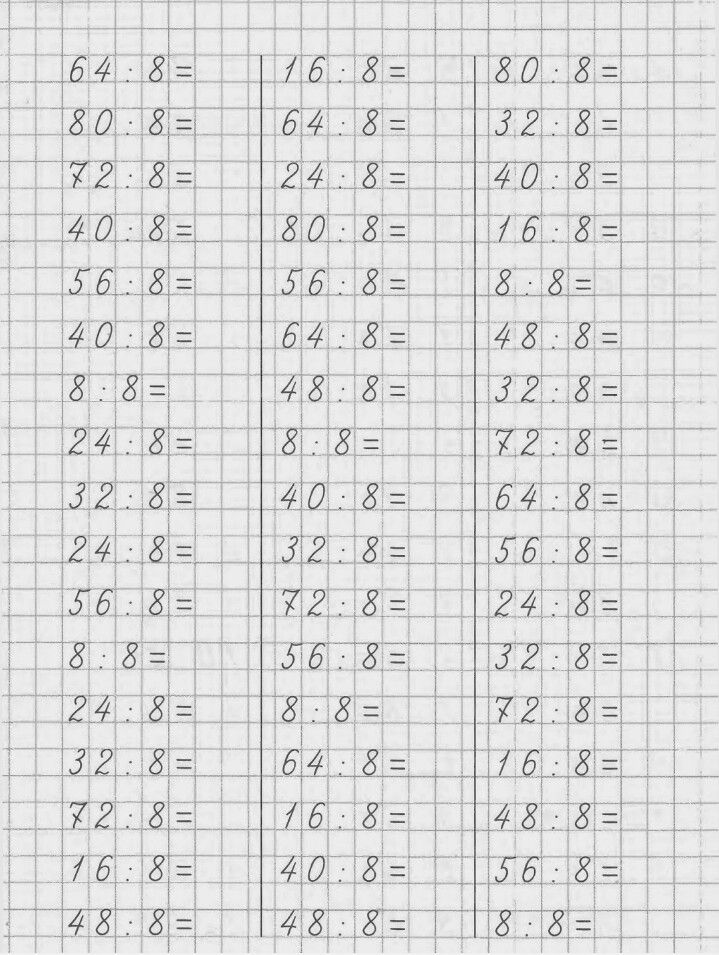
Сравнение
plt.scatter() и plt.plot() Вы также можете создать диаграмму рассеяния, показанную выше, с помощью другой функции в matplotlib.pyplot . Matplotlib plt.plot() — это функция построения графиков общего назначения, которая позволит вам создавать различные линейные или маркерные графики.
Вы можете получить тот же точечный график, что и в предыдущем разделе, с помощью следующего вызова plt.plot() , используя те же данные:
plt.plot(цена, продажи_за_день, "o") plt.show()
В этом случае вы должны были включить маркер "o" в качестве третьего аргумента, иначе plt.plot() построит линейный график. График, который вы создали с помощью этого кода, идентичен графику, который вы создали ранее с помощью plt.scatter() .
В некоторых случаях для базовой диаграммы рассеяния, которую вы строите в этом примере, может быть предпочтительнее использовать plt.. Вы можете сравнить эффективность двух функций, используя 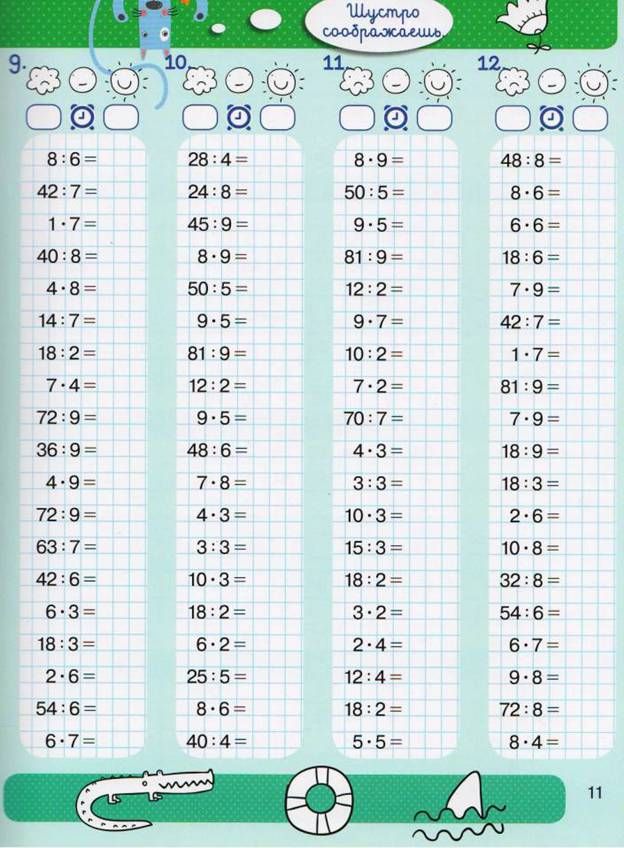 plot()
plot() модуль timeit :
время импорта
импортировать matplotlib.pyplot как plt
цена = [2,50, 1,23, 4,02, 3,25, 5,00, 4,40]
продаж_за_день = [34, 62, 49, 22, 13, 19]
Распечатать(
"plt.scatter()",
время.время(
"plt.scatter(цена, продажи_за_день)",
число=1000,
глобальные = глобальные(),
),
)
Распечатать(
"plt.plot()",
время.время(
"plt.plot(цена, продажи_за_день, 'o')",
число=1000,
глобальные = глобальные(),
),
)
Производительность будет разной на разных компьютерах, но когда вы запустите этот код, вы обнаружите, что plt.plot() значительно эффективнее, чем plt.scatter() . При выполнении приведенного выше примера в моей системе plt.plot() работало более чем в семь раз быстрее.
Если вы можете создавать точечные диаграммы с помощью plt.plot() , и это намного быстрее, зачем вам вообще использовать plt. ? Вы найдете ответ в оставшейся части этого руководства. Большинство настроек и расширенных возможностей, о которых вы узнаете в этом руководстве, возможны только при использовании  scatter()
scatter() plt.scatter() . Вот эмпирическое правило, которое вы можете использовать:
- Если вам нужна базовая точечная диаграмма, используйте
plt.plot(), особенно если вы хотите отдать приоритет производительности. - Если вы хотите настроить точечную диаграмму, используя более продвинутые функции построения графиков, используйте
plt.scatter().
В следующем разделе вы начнете изучать более сложные способы использования plt.scatter() .
Удалить рекламу
Настройка маркеров на точечных диаграммах
Вы можете визуализировать более двух переменных на двумерной диаграмме рассеяния, настроив маркеры. Существует четыре основных функции маркеров, используемых в точечной диаграмме, которые можно настроить с помощью plt. : scatter()
scatter()
- Размер
- Цвет
- Форма
- Прозрачность
В этом разделе руководства вы узнаете, как изменить все эти свойства.
Изменение размера
Вернемся к владельцу кафе, которого вы встретили ранее в этом уроке. Различные апельсиновые напитки, которые он продает, поступают от разных поставщиков и имеют разную норму прибыли. Вы можете отобразить эту дополнительную информацию на точечной диаграмме, отрегулировав размер маркера. Маржа прибыли указана в процентах в этом примере:
импортировать matplotlib.pyplot как plt импортировать numpy как np цена = np.asarray([2,50, 1,23, 4,02, 3,25, 5,00, 4,40]) sales_per_day = np.asarray([34, 62, 49, 22, 13, 19]) profit_margin = np.asarray([20, 35, 40, 20, 27,5, 15]) plt.scatter(x=цена, y=продажи_за_день, s=прибыль_маржа * 10) plt.show()
Вы можете заметить несколько изменений по сравнению с первым примером. Вместо списков теперь вы используете массивы NumPy.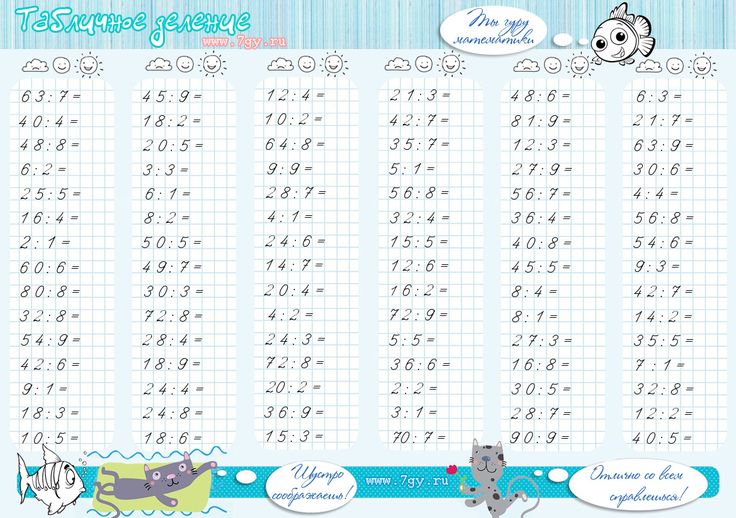 Для данных можно использовать любую структуру данных, подобную массиву, и массивы NumPy обычно используются в приложениях такого типа, поскольку они позволяют поэлементных операций , которые выполняются эффективно. Модуль NumPy зависит от Matplotlib, поэтому вам не нужно устанавливать его вручную.
Для данных можно использовать любую структуру данных, подобную массиву, и массивы NumPy обычно используются в приложениях такого типа, поскольку они позволяют поэлементных операций , которые выполняются эффективно. Модуль NumPy зависит от Matplotlib, поэтому вам не нужно устанавливать его вручную.
Вы также использовали именованных параметра в качестве входных аргументов в вызове функции. Параметры x и y являются обязательными, но все остальные параметры являются необязательными.
Параметр s обозначает размер маркера. В этом примере вы используете размер прибыли в качестве переменной для определения размера маркера и умножаете его на 9.0015 10 для более четкого отображения разницы в размерах.
Вы можете увидеть точечную диаграмму, созданную этим кодом ниже:
Размер маркера указывает размер прибыли для каждого продукта. Два апельсиновых напитка, которые продаются больше всего, также приносят наибольшую прибыль. Хорошая новость для владельца кафе!
Хорошая новость для владельца кафе!
Изменение цвета
Многие посетители кафе любят внимательно читать этикетки, особенно чтобы узнать содержание сахара в напитках, которые они покупают. Владелец кафе хочет подчеркнуть свой выбор здоровых продуктов в своей следующей маркетинговой кампании, поэтому он классифицирует напитки на основе содержания в них сахара и использует систему светофора, чтобы указать низкое, среднее или высокое содержание сахара в напитках.
Вы можете раскрасить маркеры на точечной диаграмме, чтобы показать содержание сахара в каждом напитке:
# ...
низкий = (0, 1, 0)
средний = (1, 1, 0)
высокий = (1, 0, 0)
сахар_содержание = [низкий, высокий, средний, средний, высокий, низкий]
plt.scatter(
х=цена,
у=продажи_за_день,
с=прибыль_маржа * 10,
c=sugar_content,
)
plt.show()
Вы определяете переменные low , medium и high как кортежи, каждый из которых содержит три значения, представляющие компоненты красного, зеленого и синего цветов в указанном порядке.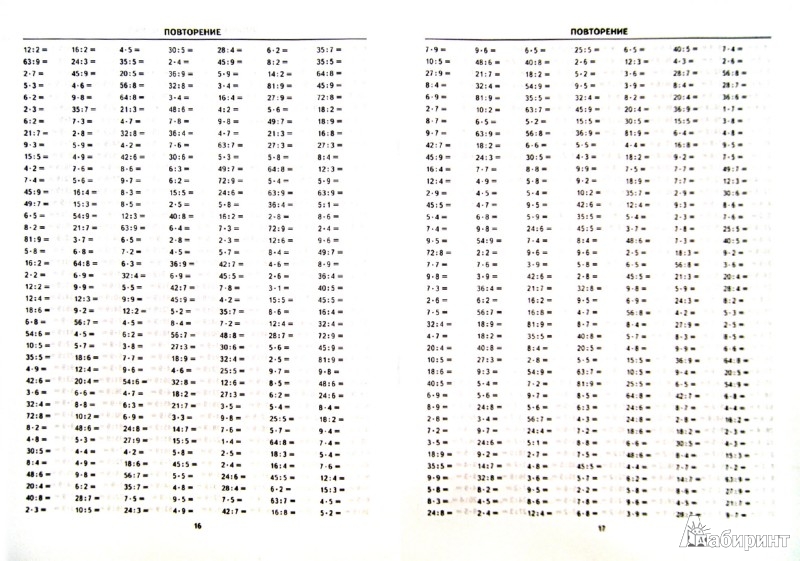 Это значения цвета RGB. Кортежи для
Это значения цвета RGB. Кортежи для низкий , средний и высокий представляют зеленый, желтый и красный соответственно.
Затем вы определили переменную «сахар_содержание» для классификации каждого напитка. Вы используете необязательный параметр c в вызове функции, чтобы определить цвет каждого маркера. Вот точечная диаграмма, созданная этим кодом:
Владелец кафе уже решил убрать из меню самый дорогой напиток, так как он плохо продается и имеет высокое содержание сахара. Должен ли он также прекратить закупать самые дешевые напитки, чтобы повысить репутацию бизнеса в отношении здоровья, даже несмотря на то, что они хорошо продаются и приносят хорошую прибыль?
Удалить рекламу
Изменение формы
Владелец кафе нашел это упражнение очень полезным и хочет исследовать другой продукт. В дополнение к апельсиновым напиткам вы теперь также нанесете аналогичные данные для ассортимента зерновых батончиков, доступных в кафе:
.
импортировать matplotlib.pyplot как plt
импортировать numpy как np
низкий = (0, 1, 0)
средний = (1, 1, 0)
высокий = (1, 0, 0)
price_orange = np.asarray([2,50, 1,23, 4,02, 3,25, 5,00, 4,40])
sales_per_day_orange = np.asarray([34, 62, 49, 22, 13, 19])
profit_margin_orange = np.asarray([20, 35, 40, 20, 27,5, 15])
Sugar_content_orange = [низкий, высокий, средний, средний, высокий, низкий]
price_cereal = np.asarray([1,50, 2,50, 1,15, 1,95])
sales_per_day_cereal = np.asarray([67, 34, 36, 12])
profit_margin_cereal = np.asarray([20, 42,5, 33,3, 18])
сахара_content_cereal = [низкий, высокий, средний, низкий]
plt.scatter(
х=цена_оранжевый,
y=продажи_за_день_оранжевый,
s=profit_margin_orange * 10,
c=sugar_content_orange,
)
plt.scatter(
х = цена_зерновых,
y=продажи_за_день_зерновых,
s=прибыль_прибыль_зерновые * 10,
c=сахар_содержание_хлопья,
)
plt.show()
В этом коде вы реорганизуете имена переменных, чтобы учесть, что теперь у вас есть данные для двух разных продуктов. Затем вы строите оба графика рассеяния на одном рисунке. Это дает следующий вывод:
Затем вы строите оба графика рассеяния на одном рисунке. Это дает следующий вывод:
К сожалению, вы больше не можете понять, какие точки данных относятся к апельсиновым напиткам, а какие к зерновым батончикам. Вы можете изменить форму маркера для одной из точечных диаграмм:
импортировать matplotlib.pyplot как plt
импортировать numpy как np
низкий = (0, 1, 0)
средний = (1, 1, 0)
высокий = (1, 0, 0)
price_orange = np.asarray([2,50, 1,23, 4,02, 3,25, 5,00, 4,40])
sales_per_day_orange = np.asarray([34, 62, 49, 22, 13, 19])
profit_margin_orange = np.asarray([20, 35, 40, 20, 27,5, 15])
Sugar_content_orange = [низкий, высокий, средний, средний, высокий, низкий]
price_cereal = np.asarray([1,50, 2,50, 1,15, 1,95])
sales_per_day_cereal = np.asarray([67, 34, 36, 12])
profit_margin_cereal = np.asarray([20, 42,5, 33,3, 18])
сахара_content_cereal = [низкий, высокий, средний, низкий]
plt.scatter(
х=цена_оранжевый,
y=продажи_за_день_оранжевый,
s=profit_margin_orange * 10,
c=sugar_content_orange,
)
plt. scatter(
х = цена_зерновых,
y=продажи_за_день_зерновых,
s=прибыль_прибыль_зерновые * 10,
c=сахар_содержание_хлопья,
маркер = "д",
)
plt.show()
scatter(
х = цена_зерновых,
y=продажи_за_день_зерновых,
s=прибыль_прибыль_зерновые * 10,
c=сахар_содержание_хлопья,
маркер = "д",
)
plt.show()
Вы сохраняете форму маркера по умолчанию для данных апельсинового напитка. Маркером по умолчанию является "o" , что представляет собой точку. Для данных зернового батончика вы устанавливаете форму маркера на "d" , что представляет собой ромбовидный маркер. Вы можете найти список всех маркеров, которые вы можете использовать на странице документации по маркерам. Вот два графика рассеяния, наложенные на одну и ту же цифру:
Теперь вы можете отличить точки данных для апельсиновых напитков от точек данных для злаковых батончиков. Но есть одна проблема с последним созданным вами графиком, которую вы исследуете в следующем разделе.
Изменение прозрачности
Исчезла одна из точек данных апельсиновых напитков. Оранжевых напитков должно быть шесть, но на рисунке видно только пять круглых маркеров. Одна из точек данных зернового батончика скрывает точку данных апельсинового напитка.
Одна из точек данных зернового батончика скрывает точку данных апельсинового напитка.
Вы можете решить эту проблему визуализации, сделав точки данных частично прозрачными, используя альфа-значение:
# ...
plt.scatter(
х=цена_оранжевый,
y=продажи_за_день_оранжевый,
s=profit_margin_orange * 10,
c=sugar_content_orange,
альфа=0,5,
)
plt.scatter(
х = цена_зерновых,
y=продажи_за_день_зерновых,
s=прибыль_прибыль_зерновые * 10,
c=сахар_содержание_хлопья,
маркер = "д",
альфа=0,5,
)
plt.title("Продажи и цены на апельсиновые напитки и зерновые батончики")
plt.legend(["Апельсиновые напитки", "Злаковые батончики"])
plt.xlabel("Цена (денежная единица)")
plt.ylabel("Средние продажи за неделю")
пл.текст(
3.2,
55,
"Размер маркера = размер прибыли\n" "Цвет маркера = содержание сахара",
)
plt.show()
Вы установили значение alpha обоих наборов маркеров на 0,5 , что означает, что они полупрозрачны. Теперь вы можете увидеть все точки данных на этом графике, включая совпадающие:
Теперь вы можете увидеть все точки данных на этом графике, включая совпадающие:
Вы также добавили заголовок и другие метки к графику, чтобы дополнить рисунок дополнительной информацией о том, что отображается.
Настройка цветовой карты и стиля
На созданных вами диаграммах рассеяния вы использовали три цвета для обозначения низкого, среднего или высокого содержания сахара в напитках и зерновых батончиках. Теперь вы измените это, чтобы цвет напрямую отображал фактическое содержание сахара в продуктах.
Сначала вам нужно реорганизовать переменные Sugar_content_orange и Sugar_content_cereal , чтобы они представляли значение содержания сахара, а не только значения цвета RGB:
Sugar_content_orange = [15, 35, 22, 27, 38, 14] сахар_содержание_зерна = [21, 49, 29, 24]
Теперь это списки, содержащие процент рекомендуемого ежедневного количества сахара в каждом продукте. Остальной код остается прежним, но теперь вы можете выбрать цветовую карту для использования. Это сопоставляет значения цветам:
Это сопоставляет значения цветам:
# ...
plt.scatter(
х=цена_оранжевый,
y=продажи_за_день_оранжевый,
s=profit_margin_orange * 10,
c=sugar_content_orange,
смап = "струя",
альфа=0,5,
)
plt.scatter(
х = цена_зерновых,
y=продажи_за_день_зерновых,
s=прибыль_прибыль_зерновые * 10,
c=сахар_содержание_хлопья,
смап = "струя",
маркер = "д",
альфа=0,5,
)
plt.title("Продажи и цены на апельсиновые напитки и зерновые батончики")
plt.legend(["Апельсиновые напитки", "Злаковые батончики"])
plt.xlabel("Цена (денежная единица)")
plt.ylabel("Средние продажи за неделю")
пл.текст(
2,7,
55,
"Размер маркера = размер прибыли\n" "Цвет маркера = содержание сахара",
)
plt.colorbar()
plt.show()
Цвет маркеров теперь основан на непрерывной шкале, и вы также отобразили цветовую полосу , которая действует как легенда для цвета маркеров. Вот результирующая диаграмма рассеяния:
Все графики, которые вы построили до сих пор, были отображены в собственном стиле Matplotlib. Вы можете изменить этот стиль, используя один из нескольких вариантов. Вы можете отобразить доступные стили с помощью следующей команды:
Вы можете изменить этот стиль, используя один из нескольких вариантов. Вы можете отобразить доступные стили с помощью следующей команды:
>>>
>>> пл.стиль.доступно
[
"Соляризация_Свет2",
"_classic_test_patch",
"бмх",
"классический",
"темный_фон",
"быстрый",
"пять тридцать восемь",
"ггплот",
"оттенки серого",
"морской",
"морской яркий",
"морской дальтоник",
"морской темный",
"морская-темная-палитра",
"мореборн-темная сетка",
"морская глубина",
"морской приглушенный",
"морской блокнот",
"морская бумага",
"морская пастель",
"морской постер",
"морской разговор",
"морские клещи",
"бело-морской",
"сиборн-белая сетка",
"таблица-дальтоник10",
]
Теперь вы можете изменить стиль графика при использовании Matplotlib, используя следующий вызов функции перед вызовом plt.scatter() :
импортировать matplotlib.pyplot как plt импортировать numpy как np plt.style.use («морской рожденный») # ...
Это меняет стиль на стиль Seaborn, еще одного стороннего пакета визуализации. Вы можете увидеть другой стиль, построив окончательный график рассеяния, показанный выше, с использованием стиля Seaborn:
Вы можете узнать больше о настройке графиков в Matplotlib, а также есть дополнительные руководства на страницах документации Matplotlib.
Использование plt.scatter() для создания точечных диаграмм позволяет отображать более двух переменных. Вот переменные, представленные в этом примере:
| Переменная | Представлен |
|---|---|
| Цена | Ось X |
| Среднее количество проданных | Ось Y |
| Маржа прибыли | Размер маркера |
| Тип продукта | Форма маркера |
| Содержание сахара | Цвет маркера |
Возможность представления более двух переменных делает plt. очень мощным и универсальным инструментом. scatter()
scatter()
Удалить рекламу
Изучение
plt.scatter () Далее plt.scatter() предлагает еще большую гибкость в настройке точечных диаграмм. В этом разделе вы узнаете, как маскировать данные с помощью массивов NumPy и точечных диаграмм на примере. В этом примере вы сгенерируете случайные точки данных, а затем разделите их на две отдельные области на одном графике рассеяния.
Жительница пригородной зоны, увлекающаяся сбором данных, сопоставила время прибытия автобусов на своей местной автобусной остановке за шестимесячный период. Время прибытия по расписанию составляет 15 минут 45 минут первого часа, но она заметила, что истинное время прибытия следует нормальному распределению вокруг этого времени:
Этот график показывает относительную вероятность прибытия автобуса каждую минуту в течение часа. Это распределение вероятностей может быть представлено с помощью NumPy и np. : linspace()
linspace()
импортировать matplotlib.pyplot как plt
импортировать numpy как np
среднее = 15, 45
сд = 5, 7
x = np.linspace(0, 59, 60) # Представляет каждую минуту в течение часа
first_distribution = np.exp(-0,5 * ((x - среднее [0]) / sd[0]) ** 2)
second_distribution = 0,9 * np.exp (-0,5 * ((x - среднее [1]) / sd [1]) ** 2)
y = первое_распределение + второе_распределение
у = у / макс (у)
plt.plot(x, y)
plt.ylabel("Относительная вероятность прибытия автобуса")
plt.xlabel("Минуты после часа")
plt.show()
Вы создали два нормальных распределения с центром в 15 и 45 минут после часа и просуммировали их. Вы устанавливаете наиболее вероятное время прибытия в значение 1 путем деления на максимальное значение.
Теперь вы можете смоделировать время прибытия автобуса, используя это распределение. Для этого можно создавать случайные времена и случайные относительные вероятности с помощью встроенного модуля random . В приведенном ниже коде вы также будете использовать списки:
В приведенном ниже коде вы также будете использовать списки:
случайный импорт
импортировать matplotlib.pyplot как plt
импортировать numpy как np
n_автобусов = 40
bus_times = np.asarray([random.randint(0, 59) для _ в диапазоне (n_buses)])
bus_likelihood = np.asarray([random.random() for _ in range(n_buses)])
plt.scatter(x=автобус_время, y=автобус_вероятность)
plt.title("Случайно выбранное время прибытия автобуса и относительная вероятность")
plt.ylabel("Относительная вероятность прибытия автобуса")
plt.xlabel("Минуты после часа")
plt.show()
Вы смоделировали 40 прибывающих автобусов, которые можно визуализировать с помощью следующей диаграммы рассеяния:
Ваш график будет выглядеть по-другому, поскольку данные, которые вы генерируете, случайны. Однако не все из этих моментов, вероятно, будут близки к реальности, которую пассажирка наблюдала на основе собранных и проанализированных ею данных. Вы можете построить распределение, которое она получила из данных смоделированных прибытий автобусов:
случайный импорт импортировать matplotlib.pyplot как plt импортировать numpy как np среднее = 15, 45 сд = 5, 7 х = np.linspace (0, 59, 60) first_distribution = np.exp(-0,5 * ((x - среднее [0]) / sd[0]) ** 2) second_distribution = 0,9 * np.exp (-0,5 * ((x - среднее [1]) / sd [1]) ** 2) y = первое_распределение + второе_распределение у = у / макс (у) n_автобусов = 40 bus_times = np.asarray([random.randint(0, 59) for _ in range(n_buses)]) bus_likelihood = np.asarray([random.random() for _ in range(n_buses)]) plt.scatter(x=автобус_время, y=автобус_вероятность) plt.plot(x, y) plt.title("Случайно выбранное время прибытия автобуса и относительная вероятность") plt.ylabel("Относительная вероятность прибытия автобуса") plt.xlabel("Минуты после часа") plt.show()
Это дает следующий вывод:
Чтобы моделирование было реалистичным, необходимо убедиться, что случайные прибытия автобусов соответствуют данным и распределению, полученному из этих данных. Вы можете отфильтровать случайно сгенерированные точки, оставив только те, которые попадают в распределение вероятностей. Вы можете добиться этого, создав маску для точечной диаграммы:
Вы можете добиться этого, создав маску для точечной диаграммы:
# ...
in_region = автобус_вероятность < y[автобус_время]
out_region = автобус_вероятность >= y[автобус_время]
plt.scatter(
x=автобусное_время[в_регионе],
y=автобус_вероятность[в_регионе],
цвет = "зеленый",
)
plt.scatter(
x=bus_time[out_region],
y=автобус_вероятность[out_region],
цвет = "красный",
маркер = "х",
)
plt.plot(x, y)
plt.title("Случайно выбранное время прибытия автобуса и относительная вероятность")
plt.ylabel("Относительная вероятность прибытия автобуса")
plt.xlabel("Минуты после часа")
plt.show()
Переменные in_region и out_region представляют собой массивы NumPy, содержащие логические значения в зависимости от того, находятся ли случайно сгенерированные вероятности выше или ниже распределения y . Затем вы строите два отдельных графика рассеяния, один с точками, попадающими в распределение, а другой — с точками, не входящими в распределение. Точки данных, находящиеся выше распределения, не являются репрезентативными для реальных данных:
Точки данных, находящиеся выше распределения, не являются репрезентативными для реальных данных:
Вы сегментировали точки данных из исходной диаграммы рассеяния на основе того, попадают ли они в распределение, и использовали другой цвет и маркер для идентификации двух наборов данных.
Удалить рекламу
Просмотр основных входных параметров
Вы узнали об основных входных параметрах для создания точечных диаграмм в разделах выше. Вот краткое изложение ключевых моментов, которые следует помнить об основных входных параметрах:
| Параметр | Описание |
|---|---|
х и у | Эти параметры представляют две основные переменные и могут быть любыми типами данных, подобными массивам, например списками или массивами NumPy. Это обязательные параметры. |
с | Этот параметр определяет размер маркера. Это может быть число с плавающей запятой, если все маркеры имеют одинаковый размер, или структура данных, подобная массиву, если маркеры имеют разные размеры. Это может быть число с плавающей запятой, если все маркеры имеют одинаковый размер, или структура данных, подобная массиву, если маркеры имеют разные размеры. |
с | Этот параметр представляет цвет маркеров. Обычно это либо массив цветов, таких как значения RGB, либо последовательность значений, которые будут отображены на карту цветов с помощью параметра cmap . |
маркер | Этот параметр используется для настройки формы маркера. |
смап | Если для параметра c используется последовательность значений, то этот параметр можно использовать для выбора сопоставления между значениями и цветами, обычно с использованием одной из стандартных карт цветов или пользовательской карты цветов. |
альфа | Этот параметр представляет собой число с плавающей запятой, которое может принимать любое значение от 9 до0015 0 и 1 и представляет прозрачность маркеров, где 1 представляет непрозрачный маркер.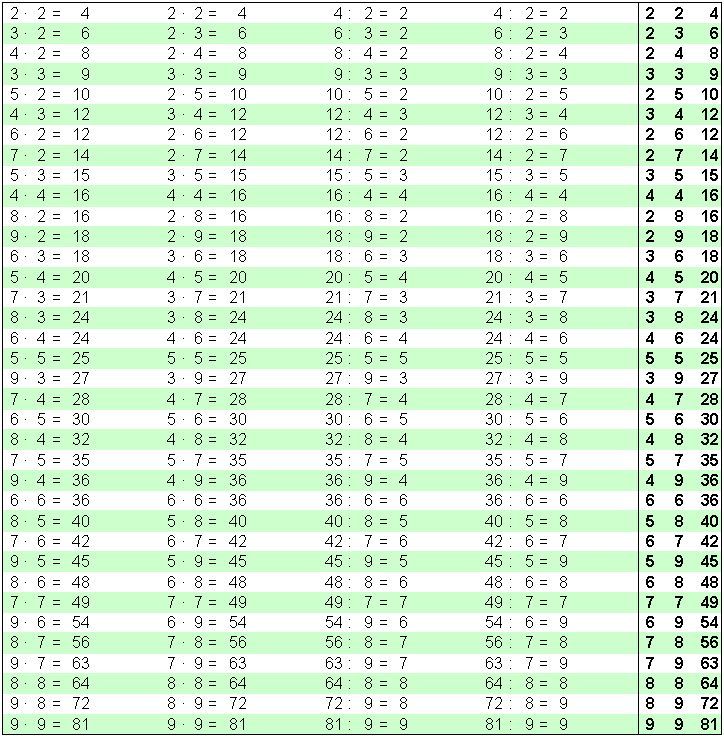 |
Это не единственные входные параметры, доступные с plt.scatter() . Вы можете получить доступ к полному списку входных параметров из документации.
Заключение
Теперь, когда вы знаете, как создавать и настраивать точечные диаграммы с помощью plt.scatter() , вы готовы приступить к практике с собственными наборами данных и примерами. Эта универсальная функция дает вам возможность исследовать ваши данные и представлять результаты в ясной форме.
В этом уроке вы узнали, как:
- Создайте точечную диаграмму , используя
plt.scatter() - Использовать обязательные и необязательные входные параметры
- Настройка точечных диаграмм для базовых и более сложных графиков
- Представление более чем двух измерений с
plt.scatter()
Вы можете получить максимальную отдачу от визуализации, используя plt., узнав больше обо всех функциях Matplotlib и работая с данными с помощью NumPy. scatter()
scatter()
Смотреть сейчас Это руководство содержит связанный с ним видеокурс, созданный командой Real Python. Посмотрите его вместе с письменным учебным пособием, чтобы углубить свое понимание: Использование plt.scatter() для визуализации данных в Python
Виджет точечной диаграммы (CX)
- Обслуживание клиентов
- Опыт сотрудников
- Знакомство с брендом
- Опыт продукта
- Core XM
- Дизайн ХМ
О виджетах точечной диаграммы
Виджет точечной диаграммы отображает данные из нескольких полей в виде отдельных точек. Это полезно при поиске тенденций в ваших данных. Помимо выбора полей для осей X и Y, на график можно добавить третье измерение в виде размера точки или цвета. Это обеспечивает высокий уровень настраиваемости.
Это обеспечивает высокий уровень настраиваемости.
Совместимость типов полей
Виджет точечной диаграммы совместим со следующими типами полей:
- Числовое значение
- Набор номеров
При выборе полей для оси X и оси Y на точечной диаграмме будут доступны только поля указанных выше типов.
Базовая настройка
- Выберите числовое значение или поле набора чисел, которое будет использоваться в качестве меры по оси X.
- Выберите другое числовое значение или поле набора чисел, которое будет использоваться в качестве меры по оси Y.
Оттуда вы можете дополнительно настроить диаграмму рассеяния, выбрав меру, соответствующую размеру и/или цвету пузырьков.
Настройка виджета
Основные инструкции и настройки виджетов см. на странице поддержки Building Widgets. Продолжайте читать для настройки виджета.
Point Color
Нажатие Установить размер цвета под Point Color позволяет выбрать поле данных, значения которого будут отображаться разными цветами на графике.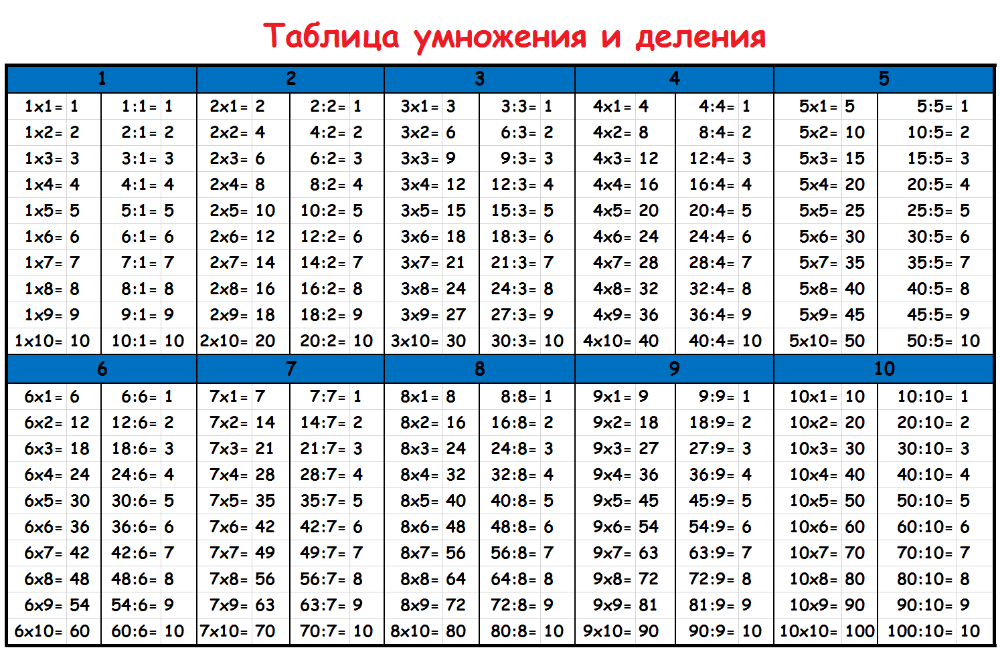 После выбора поля для этого измерения можно установить цвета для каждого значения в разделе Значения легенды . Цвета точек будут определяться подсчетами для каждого значения. Чем выше количество определенного значения в точке, тем ближе оно будет к цвету этого значения.
После выбора поля для этого измерения можно установить цвета для каждого значения в разделе Значения легенды . Цвета точек будут определяться подсчетами для каждого значения. Чем выше количество определенного значения в точке, тем ближе оно будет к цвету этого значения.
Qtip : В отличие от осей X и Y, как текстовое, так и числовое поля могут использоваться для измерения цвета.
Размер пузыря
Щелкнув Set Size Dimensions под Bubble Size , вы можете выбрать поле данных, значения которого будут определять размер точек данных на графике. В дополнение к полю данных количество может также использоваться для размера пузырька. После того, как для этого параметра будет сделан выбор, размеры точек будут скорректированы, чтобы отразить количество для каждого значения (для поля данных) или общее количество (если выбрано количество метрик).
Qtip: Если вы установите размер пузырьков на «количество», вы больше не сможете устанавливать цвет пузырьков в соответствии с другим полем, и вам придется использовать только один цвет для всех пузырьков.