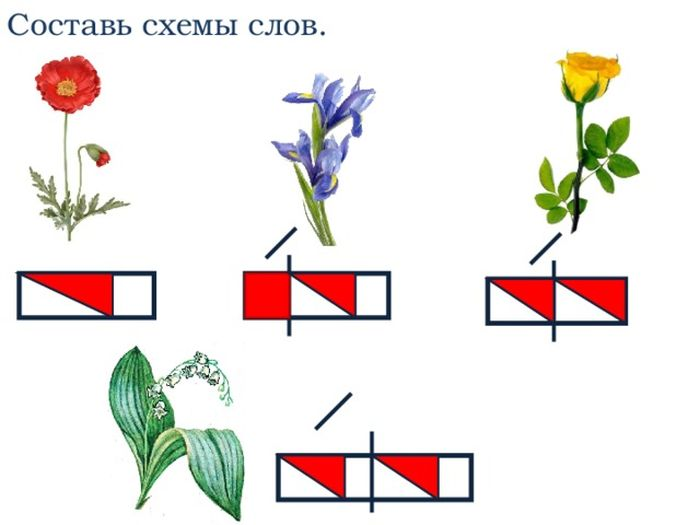
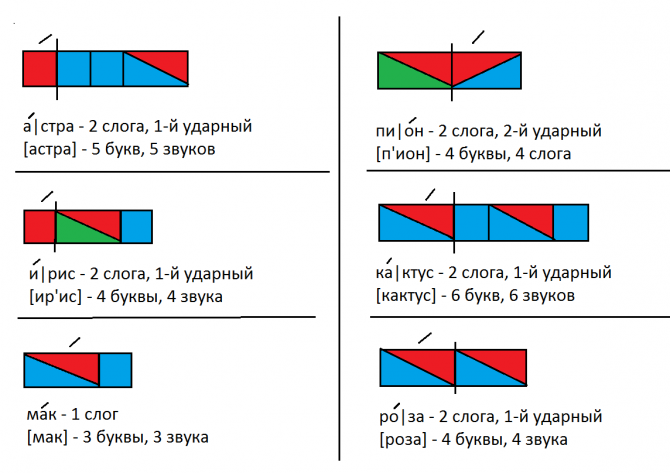
Схема слова 1 класс ирис: Фонетический разбор слова ирис — звуки и буквы, транскрипция
“Чтение слов и предложений с буквой Р”
Цель урока:
1) Закрепление знания детей о звуках [р],[ р’].
2) Упражнять детей в чтении слов с буквой Р.
3) Развивать умение производить звуко-буквенный
анализ слов.
4) Развивать речь детей.
Оборудование: “Русская азбука” Горецкого В.Г., иллюстрации: мальчик, девочка, ирисы, астры, сыроежка, боровик, мухомор, подберёзовик, сорока, кот, крот, аудиозапись пения сороки.
I. Проверка домашнего задания.
1. Беседа по изученному материалу.
У. С какой буквой познакомились на прошлом уроке?
Д. С буквой Р.
У. Какие звуки обозначает эта буква?
Д. [р],[ р’].
У. Дайте характеристику звуку [р].
Д. Согласный, твёрдый, звонкий.
У. Дайте характеристику звуку [ р’].
Д. Согласный, мягкий, звонкий.
У. Подберите слова со звуками [р],[ р’].
2. Чтение столбиков слов и текста на с. 69.
3. Выборочное чтение.
– У кого растут кактусы?
- Почему у Иры ранка?
- Чтение слов и текстов на с. 70-71
– Кто раскрасил астры? Ирисы? Лилии?
II. Закрепление изученного.
1. Сообщение темы.
У. Сегодня мы продолжим работу со звуками [р], [р’], будем упражняться в чтении слов с буквой Р.
2. Упражнение в подборе слов со звуками [р], [р’]. Игра “Строим дом”.
У. Давайте представим, что мы художники и будем рисовать картину, на которой изображён домик за городом, в деревне. Стены уже готовы, остаётся подрисовать детали.
Рис. 1
У. Какие части дома имеют в своём названии
звуки [р], [р’]?
Д. Крыша, труба, дверь, ручка, рама, крыльцо,
порог, чердак.
Крыша, труба, дверь, ручка, рама, крыльцо,
порог, чердак.
Рис. 2.
3. Звуко-буквенный анализ.
У. Гостями нашего урока будут дети: брат и сестра, которые отдыхают в деревне. Прочитайте, как их зовут. ( Рисунки на доске)
Рис. 3.
У. Составьте схему слова Лариса. (Дети выкладывают карточки у себя на столах)
У. Дайте характеристику изученному звуку.
Д. Согласный, мягкий, звонкий.
У. Составьте схему слова Тарас.
У. Дайте характеристику изученному звуку.
Д. Согласный, твёрдый, звонкий.
4. Физкультминутка.
– Мальчики – друзья Тараса, девочки – друзья Ларисы. Мальчики встают, если слышат твёрдый звук [р], девочки встают, если слышат мягкий звук [р’]. (Река, рак, труба, просо, тревога, речь, ручка, горшок)
5.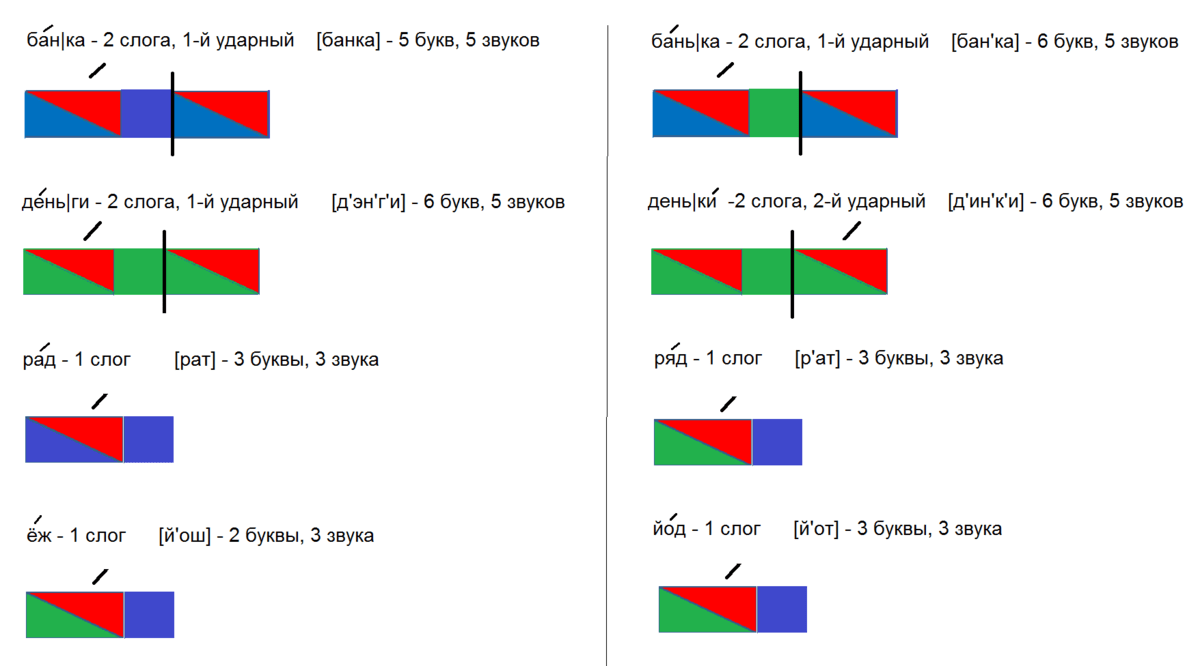 Чтение слов, написанных на доске.
Чтение слов, написанных на доске.
У. Каждый год на летние каникулы Лариса и Тарас отправляются к бабушке в деревню. Они любят гулять во дворе. Давайте прочитаем, кого они там встретили.
Рис. 4.
6. Составление слов из разрозненных слогов и букв.
У. Девочки занимаются цветоводством. У каждой девочки своя грядка. Собрав слоги и буквы, вы узнаете, какие цветы выращивают девочки. (лилии, ирисы, астры). <Рисунок 5>
7. Чтение текста, напечатанного на доске.
У. А теперь, прочитав текст, мы узнаем, кто какие цветы вырастил.
У Аллы росли ирисы. У Раисы – астры. У Ирины – лилии.
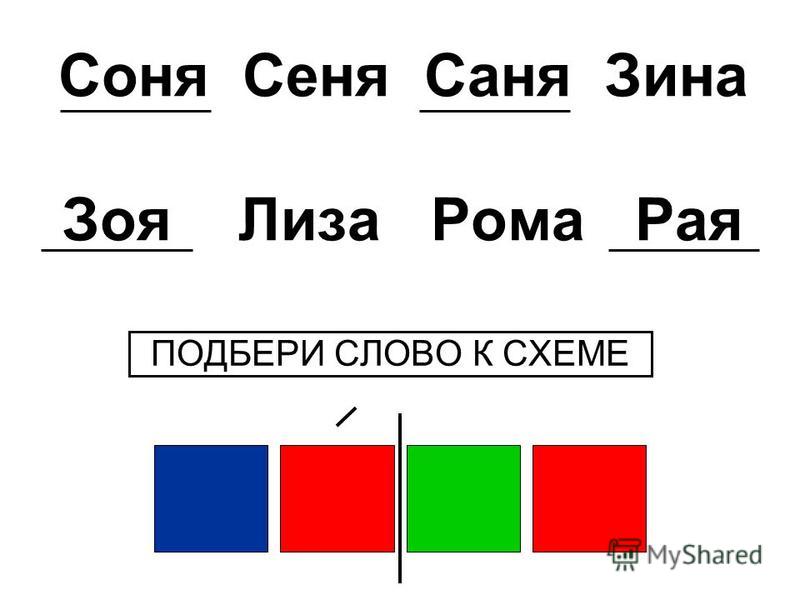
8. Соотнесение схем со словами.
У. Подберите схему к каждому из слов — названий цветов.
Рис. 5.
9. Физкультминутка.
– Дети часто ходят в лес за грибами. Отправимся
вместе с ними.
Отправимся
вместе с ними.
Тарас шёл, шёл, шёл,
Белый гриб нашёл.
Раз — грибок,
два — грибок,
Три — грибок,
Положил в свой кузовок.
10. Беседа о грибах.
У. Какие грибы они соберут? В названии
грибов должны быть звуки [р], [р’].
У. Посмотрите, какие грибы набрали дети? (рис
6.)
Д. Сыроежка, боровик, мухомор, подберёзовик .
У. Какой гриб здесь лишний? Почему?
Д. Мухомор, потому что он несъедобный.
Рис. 6.
У. Нужно ли собирать мухоморы?
Д. Нет. Мухоморами лечатся различные животные.
У. Из красного мухомора приготавливают разные гомеопатические средства для лечения многих заболеваний.
11. Прослушивание аудиозаписи “Птичьи голоса”(голос сороки).
У. Дети долго бродили по лесу. Устали. Сели
отдохнуть. Прислушайтесь, чей голос раздаётся в
лесу? (сорока ) А вот и сама сорока. (появляется
иллюстрация)
Дети долго бродили по лесу. Устали. Сели
отдохнуть. Прислушайтесь, чей голос раздаётся в
лесу? (сорока ) А вот и сама сорока. (появляется
иллюстрация)
У. Часто её называют сорокой-белобокой. Почему?
У. А ещё её называют сорокой- воровкой. Почему?
Д. Она подбирает блестящие предметы и несёт их к себе в гнездо. Монетки, блестящие пуговицы, осколки стёкол и даже ложки находят в их гнезде.
12. Сказка о приключениях буквы Р. Упражнение в составлении слов.
У. Во многих сказках говорится, что сорока
новости на хвосте приносит. А наша сорока
принесла на хвосте сказку… Давно это было. Буквы
из азбуки не хотели оставаться одинокими и стали
жить вместе, образуя разные слова. Только одна
буква Р не могла найти себе места. То ей слово не
нравилось, то стоять на краю не хотелось. Совсем
холодно букве. Не может она найти подходящего
слова. Решила забраться в слово КОМ.
Рис.7.
Хоть и холодное это слово, а внутри не так дует. Раздвинула легонечко буквы О и М и встала. Что за чудо? Это уже не КОМ , а … (КОРМ). Поела, отдохнула, выбралась из слова, соединила опять буквы и отправилась дальше. Идёт по дороге, смотрит — лежит каска. Чем не жилище? Хоть и старая каска, но согреться можно. Встала буква Р сразу буквой К, довольна. Но что это? Вся она какими-то пятнышками покрылась!
Рис. 8
Оказывается каска превратилась в слово … (КРАСКА).Убежала буква Р из этого слова, умылась снегом, стёрла все пятна — и снова в путь. А вот и ещё одно слово — КОТ.
Рис. 9.
Буквы ласковые, приветливо машут руками, зовут
к себе. Буква К даже встречать пошла, взяла за
руку. С другой стороны буква О руку подаёт,
понравилось здесь букве Р, и осталась она в слове
. . . (КРОТ). Забилась в нору, да там и провела всю
зиму.
Забилась в нору, да там и провела всю
зиму.
13. Упражнение в составлении предложений.
У. Составьте предложение о том, как Лариса и Тарас отдыхали летом в деревне.
III. Домашнее задание: чтение с. 70-71.
4 метода кластеризации данных на Python
Описаны четыре популярных метода обучения без учителя для кластеризации данных с соответствующими примерами программного кода на Python.
Обучение без учителя (unsupervised learning, неконтролируемое обучение) – класс методов машинного обучения для поиска шаблонов в наборе данных. Данные, получаемые на вход таких алгоритмов обычно не размечены, то есть передаются только входные переменные X без соответствующих меток y. Если в контролируемом обучении (обучении с учителем, supervised learning) система пытается извлечь уроки из предыдущих примеров, то в обучении без учителя – система старается самостоятельно найти шаблоны непосредственно из приведенного примера.
На левой части изображения представлен пример контролируемого обучения: здесь для того, чтобы найти лучшую функцию, соответствующую представленным точкам, используется метод регрессии. В то же время при неконтролируемом обучении входные данные разделяются на основе представленных характеристик, а предсказание свойств основывается на том, какому кластеру принадлежит пример.
В то же время при неконтролируемом обучении входные данные разделяются на основе представленных характеристик, а предсказание свойств основывается на том, какому кластеру принадлежит пример.
Методы кластеризации данных являются одним из наиболее популярных семейств машинного обучения без учителя. Рассмотрим некоторые из них подробнее.
- Feature (Особенности): входная переменная, используемая для создания прогнозов.
- Predictions (Прогнозы): выходные данные модели при наличии входного примера.
- Example (Пример): строка набора данных. Пример обычно содержит один или несколько объектов.
- Label (Метки): результат функции.
Для составления прогнозов воспользуемся классическим набором данных ирисов Фишера. Датасет представляет набор из 150 записей с пятью атрибутами в следующем порядке: длина чашелистика (sepal length), ширина чашелистика (sepal width), длина лепестка (petal length), ширина лепестка (petal width) и класс, соответствующий одному из трех видов: Iris Setosa, Iris Versicolor или Iris Virginica, обозначенных соответственно 0, 1, 2.
Для решения задач кластеризации данных в этой статье мы используем Python, библиотеку scikit-learn для загрузки и обработки набора данных и matplotlib для визуализации. Ниже представлен программный код для исследования исходного набора данных.
# Импортируем библиотеки from sklearn import datasets import matplotlib.pyplot as plt # Загружаем набор данных iris_df = datasets.load_iris() # Методы, доступные для набора данных print(dir(iris_df)) # Признаки print(iris_df.feature_names) # Метки print(iris_df.target) # Имена меток print(iris_df.target_names) # Разделение набора данных x_axis = iris_df.data[:, 0] # Sepal Length y_axis = iris_df.data[:, 1] # Sepal Width # Построение plt.xlabel(iris_df.feature_names[0]) plt.ylabel(iris_df.feature_names[1]) plt.scatter(x_axis, y_axis, c=iris_df.target) plt.show()

В результате запуска программы вы увидим следующие текст и изображение.
['DESCR', 'data', 'feature_names', 'target', 'target_names'] ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'] [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2] ['setosa' 'versicolor' 'virginica']
На диаграмме фиолетовым цветом обозначен вид Setosa, зеленым – Versicolor и желтым – Virginica. При построении были взяты лишь два признака. Вы можете проанализировать как разделяются классы при других комбинациях параметров.
Цель кластеризации данных состоит в том, чтобы выделить группы примеров с похожими чертами и определить соответствие примеров и кластеров. При этом исходно у нас нет примеров такого разбиения. Это аналогично тому, как если бы в приведенном наборе данных у нас не было меток, как на рисунке ниже.
При этом исходно у нас нет примеров такого разбиения. Это аналогично тому, как если бы в приведенном наборе данных у нас не было меток, как на рисунке ниже.
Наша задача – используя все имеющиеся данные, предсказать соответствие объектов выборки их классам, сформировав таким образом кластеры.
Наиболее популярным алгоритмом кластеризации данных является метод k-средних. Это итеративный алгоритм кластеризации, основанный на минимизации суммарных квадратичных отклонений точек кластеров от центроидов (средних координат) этих кластеров.
Первоначально выбирается желаемое количество кластеров. Поскольку нам известно, что в нашем наборе данных есть 3 класса, установим параметр модели n_clusters равный трем.
Теперь случайным образом из входных данных выбираются три элемента выборки, в соответствие которым ставятся три кластера, в каждый из которых теперь включено по одной точке, каждая при этом является центроидом этого кластера.
Далее ищем ближайшего соседа текущего центроида.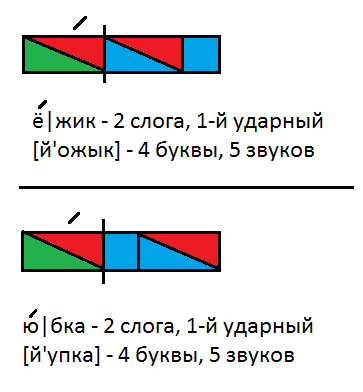 Добавляем точку к соответствующему кластеру и пересчитываем положение центроида с учетом координат новых точек. Алгоритм заканчивает работу, когда координаты каждого центроида перестают меняться. Центроид каждого кластера в результате представляет собой набор значений признаков, описывающих усредненные параметры выделенных классов.
Добавляем точку к соответствующему кластеру и пересчитываем положение центроида с учетом координат новых точек. Алгоритм заканчивает работу, когда координаты каждого центроида перестают меняться. Центроид каждого кластера в результате представляет собой набор значений признаков, описывающих усредненные параметры выделенных классов.
# Импортируем библиотеки from sklearn import datasets from sklearn.cluster import KMeans # Загружаем набор данных iris_df = datasets.load_iris() # Описываем модель model = KMeans(n_clusters=3) # Проводим моделирование model.fit(iris_df.data) # Предсказание на единичном примере predicted_label = model.predict([[7.2, 3.5, 0.8, 1.6]]) # Предсказание на всем наборе данных all_predictions = model.predict(iris_df.data) # Выводим предсказания print(predicted_label) print(all_predictions)
Результат:
[1] [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 2 2 2 2 0 2 2 2 2 2 2 0 0 2 2 2 2 0 2 0 2 0 2 2 0 0 2 2 2 2 2 0 2 2 2 2 0 2 2 2 0 2 2 2 0 2 2 0]
При выводе данных нужно понимать, что алгоритм не знает ничего о нумерации классов, и числа 0, 1, 2 – это лишь номера кластеров, определенных в результате работы алгоритма. Так как исходные точки выбираются случайным образом, вывод будет несколько меняться от одного запуска к другому.
Так как исходные точки выбираются случайным образом, вывод будет несколько меняться от одного запуска к другому.
Характерной особенностью набора данных ирисов Фишера является то, что один класс (Setosa) легко отделяется от двух остальных. Это заметно и в приведенном примере.
Иерархическая кластеризация, как следует из названия, представляет собой алгоритм, который строит иерархию кластеров. Этот алгоритм начинает работу с того, что каждому экземпляру данных сопоставляется свой собственный кластер. Затем два ближайших кластера объединяются в один и так далее, пока не будет образован один общий кластер.
Результат иерархической кластеризации может быть представлен с помощью дендрограммы. Рассмотрим этот тип кластеризации на примере данных для различных видов зерна.
# Импортируем библиотеки from scipy.cluster.hierarchy import linkage, dendrogram import matplotlib.pyplot as plt import pandas as pd # Создаем датафрейм seeds_df = pd.read_csv( "http://qps.ru/jNZUT") # Исключаем информацию об образцах зерна, сохраняем для дальнейшего использования varieties = list(seeds_df.pop('grain_variety')) # Извлекаем измерения как массив NumPy samples = seeds_df.values # Реализация иерархической кластеризации при помощи функции linkage mergings = linkage(samples, method='complete') # Строим дендрограмму, указав параметры удобные для отображения dendrogram(mergings, labels=varieties, leaf_rotation=90, leaf_font_size=6, ) plt.show()
Можно видеть, что в результате иерархической кластеризации данных естественным образом произошло разбиение на три кластера, обозначенных на рисунке различным цветом. При этом исходно число кластеров не задавалось.
- Иерархическая кластеризация хуже подходит для кластеризации больших объемов данных в сравнении с методом k-средних. Это объясняется тем, что временная сложность алгоритма линейна для метода k-средних (O(n)) и квадратична для метода иерархической кластеризации (O(n2))
- В кластеризации при помощи метода k-средних алгоритм начинает построение с произвольного выбора начальных точек, поэтому, результаты, генерируемые при многократном запуске алгоритма, могут отличаться.
 В то же время в случае иерархической кластеризации результаты воспроизводимы.
В то же время в случае иерархической кластеризации результаты воспроизводимы. - Из центроидной геометрии построения метода k-средних следует, что метод хорошо работает, когда форма кластеров является гиперсферической (например, круг в 2D или сфера в 3D).
- Метод k-средних более чувствителен к зашумленным данным, чем иерархический метод.
Метод t-SNE (t-distributed stochastic neighbor embedding) представляет собой один из методов обучения без учителя, используемых для визуализации, например, отображения пространства высокой размерности в двух- или трехмерное пространство. t-SNE расшифровывается как распределенное стохастическое соседнее вложение.
Метод моделирует каждый объект пространства высокой размерности в двух- или трехкоординатную точку таким образом, что близкие по характеристикам элементы данных в многомерном пространстве (например, датасете с большим числом столбцов) проецируются в соседние точки, а разнородные объекты с большей вероятностью моделируются точками, далеко отстоящими друг от друга.
Вернемся к примеру с ирисами и посмотрим, как произвести моделирование по этому методу при помощи библиотеки sklearn.
# Импорт библиотек from sklearn import datasets from sklearn.manifold import TSNE import matplotlib.pyplot as plt # Загрузка датасета iris_df = datasets.load_iris() # Определяем модель и скорость обучения model = TSNE(learning_rate=100) # Обучаем модель transformed = model.fit_transform(iris_df.data) # Представляем результат в двумерных координатах x_axis = transformed[:, 0] y_axis = transformed[:, 1] plt.scatter(x_axis, y_axis, c=iris_df.target) plt.show()
В этом случае каждый экземпляр представлен четырьмя координатами – таким образом, при отображении признаков на плоскость размерность пространства понижается с четырех до двух.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise, плотностной алгоритм пространственной кластеризации с присутствием шума) – популярный алгоритм кластеризации, используемый в анализе данных в качестве одной из замен метода k-средних.
Метод не требует предварительных предположений о числе кластеров, но нужно настроить два других параметра: eps и min_samples. Данные параметры – это соответственно максимальное расстояние между соседними точками и минимальное число точек в окрестности (количество соседей), когда можно говорить, что эти экземпляры данных образуют один кластер. В scikit-learn есть соответствующие значения параметров по умолчанию, но, как правило, их приходится настраивать самостоятельно.
# Импортируем библиотеки from sklearn.datasets import load_iris import matplotlib.pyplot as plt from sklearn.cluster import DBSCAN from sklearn.decomposition import PCA # Загружаем датасет iris = load_iris() # Определяем модель dbscan = DBSCAN() # Обучаем dbscan.fit(iris.data) # Уменьшаем размерность при помощи метода главных компонент pca = PCA(n_components=2).fit(iris.data) pca_2d = pca.transform(iris.data) # Строим в соответствии с тремя классами for i in range(0, pca_2d.shape[0]): if dbscan.labels_[i] == 0: c1 = plt.scatter(pca_2d[i, 0], pca_2d[i, 1], c='r', marker='+') elif dbscan.labels_[i] == 1: c2 = plt.scatter(pca_2d[i, 0], pca_2d[i, 1], c='g', marker='o') elif dbscan.labels_[i] == -1: c3 = plt.scatter(pca_2d[i, 0], pca_2d[i, 1], c='b', marker='*') plt.legend([c1, c2, c3], ['Кластер 1', 'Кластер 2', 'Шум']) plt.title('DBSCAN нашел 2 кластера и шум') plt.show()
Об устройстве алгоритма простыми словами и о математической подноготной можно прочитать в этой статье.
Источник
- Актуальная математика: самый понятный курс по анализу данных
- 11 must-have алгоритмов машинного обучения для Data Scientist
- 27 шпаргалок по машинному обучению и Python в 2017
мл | Одно горячее кодирование для обработки параметров категориальных данных
Большинство алгоритмов машинного обучения не могут работать с категориальными данными и должны быть преобразованы в числовые данные.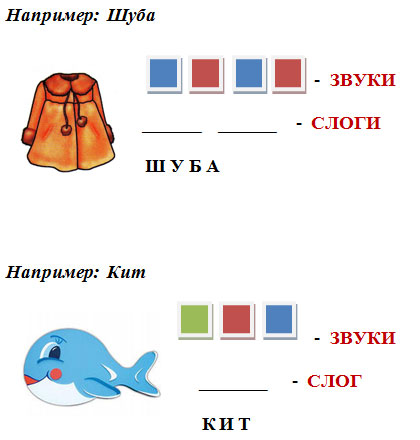 Иногда в наборах данных мы сталкиваемся со столбцами, которые содержат категориальные признаки (строковые значения), например, параметр Пол будет иметь такие категориальные параметры, как Мужской , Женский . Эти метки не имеют определенного порядка предпочтения, а также, поскольку данные представляют собой строковые метки, модели машинного обучения неправильно интерпретируют наличие в них какой-то иерархии.
Иногда в наборах данных мы сталкиваемся со столбцами, которые содержат категориальные признаки (строковые значения), например, параметр Пол будет иметь такие категориальные параметры, как Мужской , Женский . Эти метки не имеют определенного порядка предпочтения, а также, поскольку данные представляют собой строковые метки, модели машинного обучения неправильно интерпретируют наличие в них какой-то иерархии.
Одним из подходов к решению этой проблемы может быть кодирование меток, при котором мы назначаем числовое значение этим меткам, например, Мужской и Женский , сопоставленные с 0 и 1 . Но это может внести смещение в нашу модель, поскольку она начнет отдавать большее предпочтение параметру Женский , поскольку 1>0, и в идеале обе метки одинаково важны в наборе данных. Чтобы решить эту проблему, мы будем использовать метод One Hot Encoding.
Одно горячее кодирование:
В этом методе категориальные параметры подготавливают отдельные столбцы для мужских и женских меток. Таким образом, везде, где есть мужчина, значение будет 1 в столбце мужчины и 0 в столбце женщины, и наоборот. Давайте разберемся на примере: рассмотрим данные, в которых даны фрукты и соответствующие им категориальные значения и цены.
Таким образом, везде, где есть мужчина, значение будет 1 в столбце мужчины и 0 в столбце женщины, и наоборот. Давайте разберемся на примере: рассмотрим данные, в которых даны фрукты и соответствующие им категориальные значения и цены.
| Фрукты | Категориальная стоимость фруктов | Цена |
|---|---|---|
| яблоко | 1 | 5 |
| mango | 2 | 10 |
| apple | 1 | 15 |
| orange | 3 | 20 |
The output after one-hot Кодирование данных приведено следующим образом,
| Apple | MANGO | Orange | Цена | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0039 5 |
| 0 | 1 | 0 | 10 | |||||||||||
| 1 | 0 | 0 | 15 | |||||||||||
| 0 | 0 | 1 | 20 |
Код: Реализация кода Python для метода ручного горячего кодирования Загрузка данных0009
import pandas as pd
data = pd. 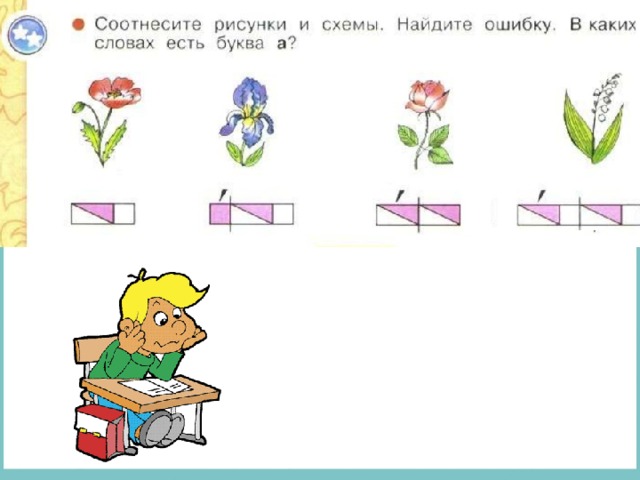 read_csv(
read_csv( "employee_data.csv" )
print (data.head() )
Output:
Checking for the labels in the categorical parameters
Python3
|
Output:
массив (['Мужчина', 'Женщина'], dtype=object) array(['Хорошо', 'Хорошо', 'Отлично'], dtype=object)
Проверка количества меток в категориальных параметрах
 value_counts ()
value_counts ()  Например, если мы сохраним только столбец Gender_Female и удалим столбец Gender_Male , тогда мы также можем передать всю информацию, так как когда метка равна 1, это означает женский пол, а когда метка равна 0, это означает мужской. Таким образом, мы можем кодировать категориальные данные и также уменьшить количество параметров.
Например, если мы сохраним только столбец Gender_Female и удалим столбец Gender_Male , тогда мы также можем передать всю информацию, так как когда метка равна 1, это означает женский пол, а когда метка равна 0, это означает мужской. Таким образом, мы можем кодировать категориальные данные и также уменьшить количество параметров.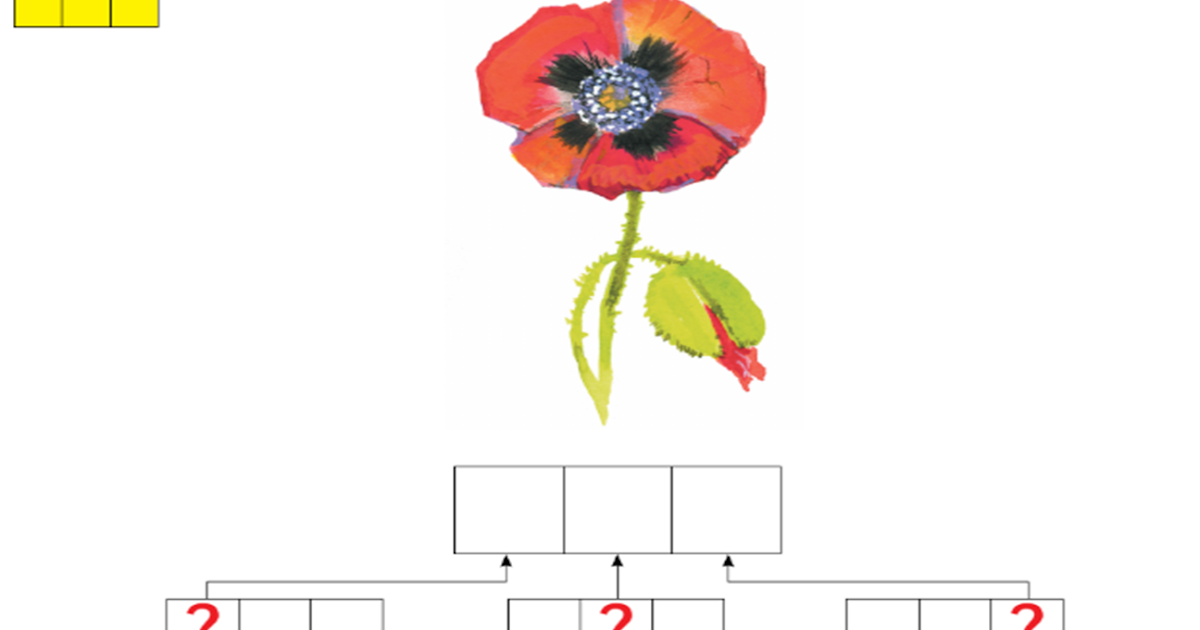 preprocessing
preprocessing 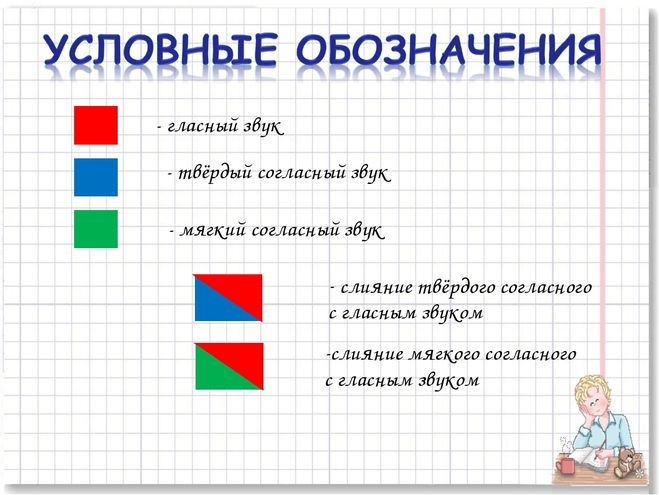 cat.codes
cat.codes  0142
0142  Технология в основном используется для идентификации и контроля доступа или для идентификации лиц, находящихся под наблюдением. Основная предпосылка биометрической аутентификации заключается в том, что каждого человека можно точно идентифицировать по внутренним физическим или поведенческим чертам. Срок биометрия происходит от греческих слов био , что означает жизнь , и метрика , что означает для измерения .
Технология в основном используется для идентификации и контроля доступа или для идентификации лиц, находящихся под наблюдением. Основная предпосылка биометрической аутентификации заключается в том, что каждого человека можно точно идентифицировать по внутренним физическим или поведенческим чертам. Срок биометрия происходит от греческих слов био , что означает жизнь , и метрика , что означает для измерения .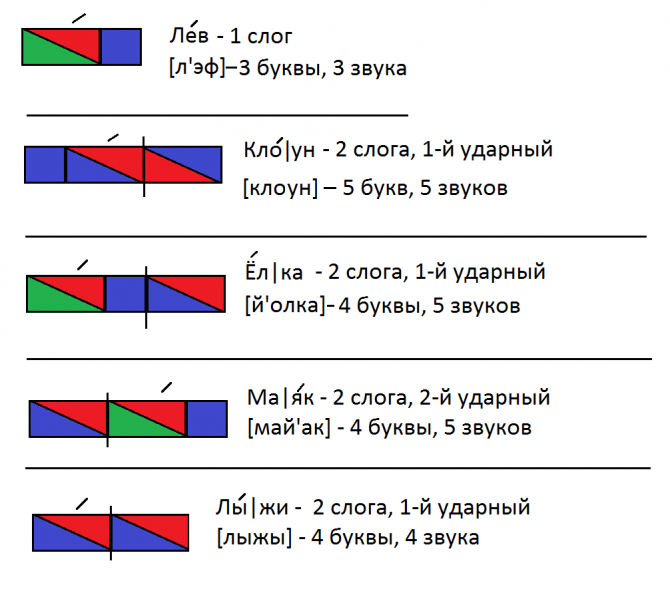



 Например, биометрия используется в следующих сферах и организациях:
Например, биометрия используется в следующих сферах и организациях: Например, некоторые системы правосудия не будут использовать биометрические данные, чтобы избежать возможных ошибок.
Например, некоторые системы правосудия не будут использовать биометрические данные, чтобы избежать возможных ошибок. Отпечатки пальцев не меняются на протяжении всей жизни, а внешний вид лица может резко измениться с возрастом, болезнью или другими факторами.
Отпечатки пальцев не меняются на протяжении всей жизни, а внешний вид лица может резко измениться с возрастом, болезнью или другими факторами.

 Оцените шесть сертификатов и взвесьте...
Оцените шесть сертификатов и взвесьте...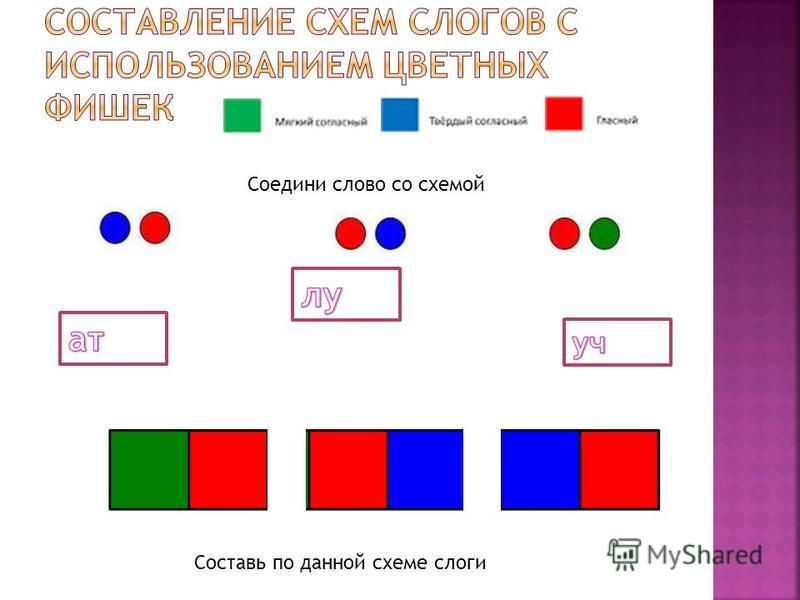 Узнайте, почему ИТ-операции должны...
Узнайте, почему ИТ-операции должны... Насыщение рынка после пандемии является значительным...
Насыщение рынка после пандемии является значительным...