Буквы англ алфавита: Английский алфавит. English Alphabet
Английский алфавит — буквы, звуки, правильное произношение
Начиная изучение иностранного языка, в первую очередь надо выучить его буквы – их название, произношение, написание. Особенно это важно, если используется не привычная кириллица, а латиница. Как выучить английский алфавит с нуля, причем без чрезмерных усилий? Существует несколько эффективных способов, применяемых для детей или взрослых. Рассмотрим особенности английской азбуки, а также эффективные варианты ее запоминания.
Зачем нужно знать алфавит
С чего начинается обучение английскому детей и взрослых? Конечно, с азбуки. Знать порядок букв в алфавите, их правильное произношение очень важно: без этого невозможно полноценно читать или писать по-английски, а иногда – и понять собеседника. Многие сочетания букв образуют особые звуки – дифтонги, читаются по-другому, не так, как каждая из них по отдельности. В таком случае может возникнуть путаница, вы не поймете собеседника. Простой пример: глагол think (думать) и существительное sink (раковина). Если читать буквосочетание th не по правилам, вместо «думать» получится «раковина» по произношению. Чтобы прояснить ситуацию, нередко просят произнести слово по буквам. Для этого и надо знать английский алфавит с произношением. Выучить его может даже ребенок, причем за несколько дней.
Если читать буквосочетание th не по правилам, вместо «думать» получится «раковина» по произношению. Чтобы прояснить ситуацию, нередко просят произнести слово по буквам. Для этого и надо знать английский алфавит с произношением. Выучить его может даже ребенок, причем за несколько дней.
Английский и американский алфавит: особенности и различия
В чем же особенности азбуки? Современный английский алфавит состоит из 26 букв, из них шесть – гласных, остальные – согласные. Основан он на латинской азбуке. Первые записи алфавита датируют пятым веком нашей эры, однако тогда английские буквы обозначали руническими знаками. Латиницу стали использовать только через 200 лет, с приходом христианских миссионеров. Долгое время в Британии использовали оба варианта написания.
Рассмотрим гласные буквы английского алфавита. Это a, u, e, o, i, y. Обратите внимание: буква «y» может означать и гласный, и согласный звуки. Остальные буквы: w, s, z, q, x, r, d, c, t, f, v, g, b, h, n, j, m, k, p, l – согласные.
Американский вариант алфавита – такой же, разница между ним и британским вариантом – в произношении буквы z. Англичане произносят ее как [zed], американцы – как [zi].
Как правильно учить английские буквы и звуки
Зачастую обучение английскому начинается именно с изучения алфавита. Это основа, своеобразные кирпичики, из которых выстраивается знание иностранного языка. На первом уроке нужно запомнить, сколько букв в английском алфавите, количество гласных и согласных.
Изучение азбуки стоит проводить в нескольких плоскостях: запоминать написание, произношение, порядок букв. Если вы хотите говорить по-английски свободно, понимать носителей языка, не стоит игнорировать этот этап.
Важно сразу учить английский алфавит с правильным произношением букв. Для этого понадобится транскрипция, которая показывает, как называется каждая буква. Новичкам будет проще изучать английский алфавит с произношением по-русски. Однако для правильного произношения лучше использовать и русскую (кириллическую), и английскую (латинскую) транскрипцию. Это связано с различиями в фонетике языков.
Это связано с различиями в фонетике языков.
Советы по изучению английских букв
- Попробуйте разбить алфавит на три части. Первая – это гласные буквы, их немного, поэтому запомнить их название и написание достаточно просто. Учтите, что читаться они могут по-разному, в зависимости от ударения, типа слога (открытый или закрытый). Вторая группа – это буквы, напоминающие русские по произношению: t, p, s, d, f, k, l, c, v, b, n, m. Наконец, третья группа английских букв – это q, w, r, y, g, h, j, z, x. Они пишутся и произносятся непривычно для русскоязычных студентов.
- Запомнив названия букв, учите английский алфавит по порядку. Так вы сможете сориентироваться в документах или в библиотеке, в картотеке. Хорошо, если вы будете знать порядковый номер буквы. Для закрепления можно выучить алфавит английского языка наоборот, то есть начать не с A, а с Z.
- Старайтесь сразу запоминать написание строчных и заглавных букв.
- Занимайтесь ежедневно.

Эффективные методы и способы запоминания английского алфавита
Разобравшись с основными правилами, которые помогут выучить азбуку, рассмотрим основные способы изучения. Они подойдут и для тех, кто осваивает азы языка самостоятельно, и для тех, кто занимается с ребенком.
Учим английский алфавит быстро и с правильным произношением
Один из самых простых вариантов – это песенка, в которой необходимо пропеть все буквы в том порядке, в котором они расположены в алфавите. Существует несколько ее вариантов, поэтому вы можете выбрать тот жанр и темпоритм, который вам нравится – от фольклорных напевов и детских мотивов до тяжелого рока.
Это один из наиболее быстрых и простых способов, который эффективен даже при работе с маленькими детьми. Во время пения порядок букв английского алфавита запоминается очень легко, как и их правильные названия.
Во время пения порядок букв английского алфавита запоминается очень легко, как и их правильные названия.
Как учить?
- Найдите песенку в формате аудио или видео. Прослушайте ее несколько раз.
- Подпевайте или пойте ее самостоятельно по мере запоминания.
Используя видеоряд во время занятия, вы сможете запомнить не только правильное произношение, но и написание букв, подключив зрительную память.
Простой способ учить английский алфавит
Хотите не только выучить азбуку, но и запомнить, как пишутся английские буквы? Используйте карточки. Их можно сделать из плотной бумаги или выбрать готовые. Варианты карточек:
- черно-белые, разрезные, с изображением заглавных и прописных письменных букв;
- цветные, яркие, с печатными буквами – с их помощью с удовольствием занимаются даже дети;
- с картинками, на которых изображены предметы или животные, названия которых начинаются на определенную букву.
Вместо карточек можно использовать таблицы или плакаты с алфавитом – лучше, если они будут с транскрипцией.
Как учить?
- За одно занятие не стоит прорабатывать все карточки – вы утомитесь, и результат будет не слишком заметным. Используйте до 5-6 карточек.
- Внимательно рассмотрите каждую букву, произнесите вслух ее название. Можно попробовать написать ее в тетради или на листочке: заглавный, прописной вариант.
- По мере изучения английского алфавита ищите знакомые буквы в словах.
Как научиться писать буквы английского алфавита
Для полноценной письменной речи важно знать, как пишется та или иная буква. Занимаясь с детьми, можно начать с печатного варианта написания – это немного проще, ребенку будет легче запомнить. В дальнейшем переходите к прописям. Это классический способ выучить «письменный» алфавит английского языка. Прописями могут пользоваться и взрослые – копирование букв на листе способствует их запоминанию, поскольку подключается мелкая моторика. Впрочем, вместо прописей можно использовать обычную тетрадь в линейку.
Как учить?
- Как и при работе с карточками, не пытайтесь за одно занятие запомнить правильное написание всех букв английского алфавита.
 Напишите по несколько строк одной буквы: сначала строчного, потом заглавного варианта.
Напишите по несколько строк одной буквы: сначала строчного, потом заглавного варианта. - Одновременно с написанием произносите название буквы – так вы быстрее ее выучите. При таком способе работает зрительная и слуховая память, мелкая моторика, вырабатываются динамические рефлексы.
- Сопоставьте письменный и печатный вариант обозначения одной и той же буквы.
Если вы занимаетесь по прописи, лучше выбрать комплект одного производителя, поскольку существует несколько вариантов написания английских букв.
Веселый способ закрепления знаний
Если вы уже выучили буквы, закрепить полученные знания можно на практике – например, в играх. Их очень много, поэтому выбор зависит от возраста и уровня знаний игроков.
- Самая простая игра для детей – ведущий пишет (лепит, рисует, вырезает) букву, а участники называют ее.
- Интересная игра, в которую можно играть даже на прогулке – ассоциации. Ведущий называет букву, а игроки говорят, что она напоминает или ищут предметы, схожие с ней по форме.

- Классический вариант – игра в слова. Ведущий называет букву, а игроки – слово, которое на нее начинается или слово, в котором она встречается.
- Spelling bee – популярная в Америке и Великобритании игра. Ее суть в том, чтобы произнести по буквам услышанное от ведущего слово. Можно немного видоизменить правила: играть без ведущего, по очереди называя слова и разбирая их по буквам. С подростками или взрослыми можно играть так: ведущий называет слово, а игроки записывают его на листочках. Выигрывает игрок, написавший слова правильно.
- «Виселица» – еще одна интересная игра, которая поможет запоминанию и алфавита, и слов. В нее играют вдвоем. Один игрок загадывает слово, на листе указывая количество букв в нем. Для этого на месте каждой буквы рисуется черта. Второй игрок угадывает слово, поочередно произнося каждую букву алфавита. Если она встречается в загаданном слове, ее указывают над соответствующей чертой. Если не встречается – на том же листе рисуется один элемент виселицы.
 Для победы необходимо назвать слово раньше, чем виселица будет дорисована.
Для победы необходимо назвать слово раньше, чем виселица будет дорисована.
| A a | A a | [ei] | эй | |
| B b | B b | [bi:] | би | |
| C c | C c | [si:] | си | |
| D d | D d | [di:] | ди | |
| E e | E e | [i:] | и | |
| F f | F f | [ef] | эф | |
| G g | G g | [dʒi:] | джи | |
| H h | H h | [eitʃ] | эйч | |
| I i | I i | [ai] | ай | |
| J j | J j | [dʒei] | джей | |
| K k | K k | [kei] | кей | |
| L l | L l | [el] | эл | |
| M m | M m | [em] | эм | |
| N n | N n | [en] | эн | |
| O o | O o | [ou] | оу | |
| P p | P p | [pi] | пи | |
| Q q | Q q | [kju:] | кью | |
| R r | R r | [a:] | а | |
| S s | S s | [es] | эс | |
| T t | T t | [ti:] | ти: | |
| U u | U u | [ju:] | ю: | |
| V v | V v | [vi:] | ви | |
| W w | W w | [‘dʌblju:] | даблъю | |
| X x | X x | [eks] | экс | |
| Y y | Y y | [wai] | уай | |
| Z z | Z z | [zed] | зэд | |
 Очень немногие примеры этого письменного старого алфавита сохранились.
Очень немногие примеры этого письменного старого алфавита сохранились. Буквы «U» и «J», в отличие от «V» и «I», были введены в 16-м веке. И буква «W» приобрела статус самостоятельной буквы, так что английский алфавит в настоящее время состоит из следующих 26 символов, которые вы все знаете:
Буквы «U» и «J», в отличие от «V» и «I», были введены в 16-м веке. И буква «W» приобрела статус самостоятельной буквы, так что английский алфавит в настоящее время состоит из следующих 26 символов, которые вы все знаете:
| Буква | Транскрипция (произношение) | Название | Название на русском | Частота |
|---|---|---|---|---|
| A a | [eɪ] | a | эй | 8.17% |
| B b | [biː] | bee | би | 1. 49% 49% |
| C c | [siː] | cee | си | 2.78% |
| D d | [diː] | dee | ди | 4.25% |
| E e | [iː] | e | и | 12.7% |
| F f | [ef] | ef | эф | 2.23% |
| G g | [dʒiː] | gee | джи | 2.02% |
| H h | [eɪtʃ] | aitch | эйч | 6.09% |
| I i | [aɪ] | i | ай | 6.97% |
| J j | [dʒeɪ] | jay | джей | 0.15% |
| K k | [keɪ] | kay | кей | 0.77% |
| L l | [el] | el | эл | 4.03% |
| M m | [em] | em | эм | 2.41% |
| N n | [ɛn] | en | эн | 6.75% |
| O o | [əʊ] | o | оу | 7.51% |
| P p | [piː] | pee | пи | 1.93% |
| Q q | [kjuː] | cue | кью | 0.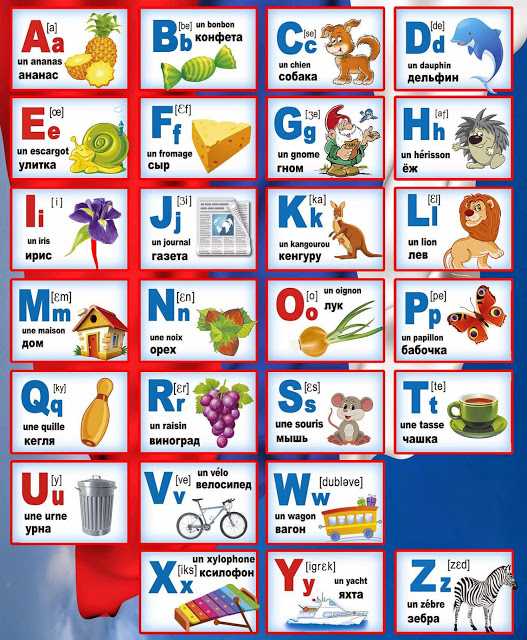 1% 1% |
| R r | [ɑː, ar] | ar | а, ар | 5.99% |
| S s | [es] | ess | эс | 6.33% |
| T t | [tiː] | tee | ти | 9.06% |
| U u | [juː] | u | ю | 2.76% |
| V v | [viː] | vee | ви | 0.98% |
| W w | [‘dʌbljuː] | double-u | дабл-ю | 2.36% |
| X x | [eks] | ex | экс | 0.15% |
| Y y | [waɪ] | wy | уай | 1.97% |
| Z z | [zɛd, ziː] | zed, zee | зед, зи | 0.05% |
Скачать и распечатать алфавит:
Самая известная английская панграмма, содержащая все 26 букв английского алфавита: The quick brown fox jumps over the lazy dog.
Источник
Английский алфавит
Начав изучение английского языка, первое, с чем вы встречаетесь – это английский алфавит (english alphabet [ˈalfəbɛt ]). Написание английских букв не является чем-то абсолютно новым даже на самом начальном этапе обучения, ведь любой современный человек ежедневно сталкивается с английскими буквами на клавиатуре компьютера и телефона. Да и английские слова встречаются на каждом шагу: в рекламе, на этикетках разнообразных товаров, в витринах магазинов.
Написание английских букв не является чем-то абсолютно новым даже на самом начальном этапе обучения, ведь любой современный человек ежедневно сталкивается с английскими буквами на клавиатуре компьютера и телефона. Да и английские слова встречаются на каждом шагу: в рекламе, на этикетках разнообразных товаров, в витринах магазинов.
Но при том, что буквы кажутся знакомыми, правильное их произношение по-английски иногда представляет трудность даже для тех, кто вполне сносно говорит на английском. Всем знакома ситуация, когда нужно произнести английское слово по буквам – например, продиктовать адрес электронной почты или название сайта. Вот тут и начинаются чудесные названия: i – «как палочка с точкой», s – «как доллар», q – «где русская й».
Английский алфавит с произношением по-русски, транскрипцией и озвучкой
Английский алфавит с произношением по-русски предназначен только для самых начинающих. В дальнейшем, когда вы будете знакомиться с правилами чтения английского языка и учить новые слова, вам необходимо будет изучить транскрипцию. Она используется во всех словарях, и если вы будете ее знать, это раз и навсегда снимет для вас проблему правильного произношения новых слов. Советуем уже на этом этапе сравнить значки транскрипции в квадратных скобках с русским эквивалентом. Возможно, на этих коротеньких примерах, вы запомните некоторые соотношения английских и русских звуков.
Она используется во всех словарях, и если вы будете ее знать, это раз и навсегда снимет для вас проблему правильного произношения новых слов. Советуем уже на этом этапе сравнить значки транскрипции в квадратных скобках с русским эквивалентом. Возможно, на этих коротеньких примерах, вы запомните некоторые соотношения английских и русских звуков.
Ниже приведена таблица, где дан английский алфавит с транскрипцией и русским произношением. Обратите внимание, как выглядят заглавные и строчные буквы.
← Двигайте таблицу влево, чтобы посмотреть полностью
Ниже, Вы можете прослушать все буквы английского алфавита сразу:
Тренажер для отработки алфавита
Выберите букву, соответствующую ее произношению.
Карточки английского алфавита
Очень эффективны карточки английского алфавита при его изучении. Яркие и крупные буквы будут легче запоминаться. Смотрите сами:
Такие карточки можно изготовить самостоятельно, например, по приведенному выше образцу. Далее распечатайте, вырежьте буквы и раскладывайте в правильной последовательности.
Далее распечатайте, вырежьте буквы и раскладывайте в правильной последовательности.
Для детей, на карточках английского алфавита можно дополнително к буквам изобразить животных, чтобы сразу запоминать новые слова, а процесс обучения не был скучным.
Особенности некоторых букв английского алфавита.
В алфавите английского языка 26 букв: 20 согласных и 6 гласных.
В английском языке есть несколько букв, на которые мы хотим обратить особое внимание, поскольку у них есть определенные особенности, которые нужно учитывать при изучении алфавита.
Слушать песенку про английский алфавит:
Несколько слов о спеллинге
Итак, мы выучили алфавит английского языка. Знаем, как по отдельности произносятся английские буквы. Но перейдя к правилам чтения, вы сразу же увидите, что многие буквы в разных сочетаниях читаются совсем по-другому. Возникает резонный вопрос – как сказал бы кот Матроскин – какая от заучивания алфавита польза? На самом деле практическая польза есть.
Источник
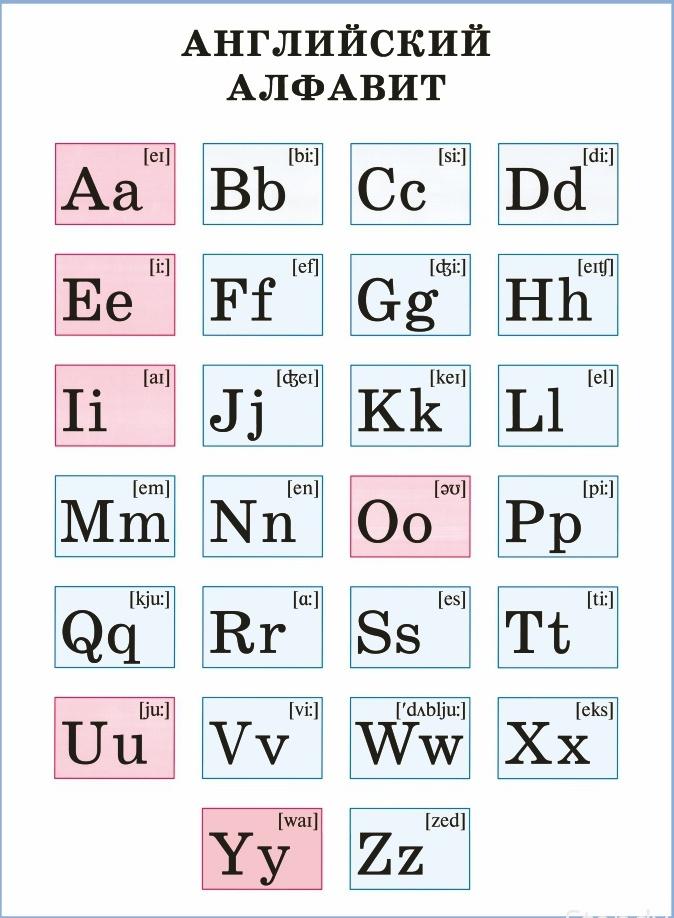
Английский алфавит: таблица с транскрипцией и русским произношением
Если вы только приступаете к освоению английского языка, начинайте обучение с основных тем, в числе которых, конечно же, присутствует English alphabet [ˈɪŋɡlɪʃ ˈalfəbɛt] или английский алфавит. При экспресс-обучении эту тему часто опускают, мол, придет сама со временем. Однако если вы не будете знать весь список букв, их произношение и написание, ничего путевого из вашего процесса обучения не выйдет. А потому давайте разберем, что собой представляют и как используются буквы английского алфавита.
Экскурс в историю английского алфавита
Но для начала посмотрим, как формировался английский алфавит. Сказать точно, когда он появился достаточно тяжело, но самые первые найденные фрагменты английского алфавита относятся к V веку. Тогда для его написания использовались латинские буквы в сочетании с рунами, а потому буквы абсолютно не походили на те, которые используются в современном английском языке. В последующем, однако, этот алфавит менялся, все руны заменились латинскими буквами, количество которых к XI веку составило 23 знака, которые были упорядочены для нумерологических целей. После этого алфавит уже значительно не менялся, однако к нему добавилось еще 3 буквы, которые также использовались в создании современного алфавита.
В последующем, однако, этот алфавит менялся, все руны заменились латинскими буквами, количество которых к XI веку составило 23 знака, которые были упорядочены для нумерологических целей. После этого алфавит уже значительно не менялся, однако к нему добавилось еще 3 буквы, которые также использовались в создании современного алфавита.
Английский алфавит: состав
Сколько букв используется в современном английском посчитать, пожалуй, было не сложно. Букв в английском 26. В разных ситуациях они могут звучать по-разному, так как их произношение меняется в зависимости от сочетаний. Всего же в английском языке 44 звука. Однако каждая буква имеет свое стандартное произношение, которое используется при изучении алфавита. Пишутся английские буквы не так как произносятся, а потому при их изучении необходимо использовать транскрипцию во избежание дальнейших ошибок. Стоит также отметить, что каждая буква английского алфавита имеет порядковый номер. Нумерология английского, как и в русском, создана исключительно для удобства и как такой важности не имеет.
| Список английских букв с нумерацией, транскрипцией и произношением | ||||
| № | Буква | Название | Транскрипция | Произношение |
| 1. | A a | a | [eɪ] | эй |
| 2 | B b | bee | [biː] | би |
| 3 | C c | cee | [siː] | си |
| 4 | D d | dee | [diː] | ди |
| 5 | E e | e | [iː] | и |
| 6 | F f | ef | [ef] | эф |
| 7 | G g | gee | [dʒiː] | джи |
| 8 | H h | aitch | [eɪtʃ] | эйч |
| 9 | I i | i | [aɪ] | ай |
| 10 | J j | jay | [dʒeɪ] | джей |
| 11 | K k | kay | [keɪ] | кей |
| 12 | L l | el | [el] | эл |
| 13 | M m | em | [em] | эм |
| 14 | N n | en | [ɛn] | эн |
| 15 | O o | o | [əʊ] | оу |
| 16 | P p | pee | [piː] | пи |
| 17 | Q q | cue | [kjuː] | кью |
| 18 | R r | ar | [ɑː] | а |
| 19 | S s | ess | [es] | эс |
| 20 | T t | tee | [tiː] | ти |
| 21 | U u | u | [juː] | ю |
| 22 | V v | vee | [viː] | ви |
| 23 | W w | double-u | [‘dʌbljuː] | дабл-ю |
| 24 | X x | ex | [eks] | экс |
| 25 | Y y | wy | [waɪ] | уай |
| 26 | Z z | zed | [zɛd] | зед |
Буква Z в американском английском произносится как zee [ziː] (зи).
Обратите внимание, что произношение, написанное русскими буквами, является приблизительным. Передать точное английское звучание с помощью русских букв не получится. Указано же оно здесь для облегчения изучения на начальном этапе. Тем не менее, вариант в транскрипции является более предпочтительным. Если же вы еще не совсем хорошо знакомы со звуками, старайтесь слушать и имитировать носителей.
Английский алфавит: частота использования
Все буквы в английском алфавите имеют свою частоту использования. Так, цифры на 2000 год показывают, что самой популярной буквой английского языка является гласная E. Второй по частоте использования является согласная T. Объяснить подобные результаты не так уж сложно. Обе эти буквы встречаются в определенном артикле «the», который является самым употребляемым словом английского языка. Самой непопулярной же является буква Z, которая известна разве что зеброй (zebra), молнией (zip) и зигзагом (zigzag).
Другие буквы расположились следующим образом:
| Буквы английского языка по порядку частоты их использования | ||
| № | Буква | Частота ( %) |
1. | E | 12,7 |
| 2. | T | 9,1 |
| 3. | A | 8,2 |
| 4. | O | 7,5 |
| 5. | I | 7,0 |
| 6. | N | 6,8 |
| 7. | S | 6,3 |
| 8. | H | 6,1 |
| 9. | R | 6,0 |
| 10. | D | 4,3 |
| 11. | L | 4,0 |
| 12. | C | 2,8 |
| 13. | U | 2,8 |
| 14. | M | 2,4 |
| 15. | W | 2,4 |
| 16. | F | 2,2 |
| 17. | G | 2,0 |
| 18. | Y | 2,0 |
| 19. | P | 1,9 |
| 20. | B | 1,5 |
| 21. | V | 1,0 |
| 22. | K | 0,8 |
| 23. | J | 0,2 |
| 24. | X | 0,2 |
25. | Q | 0,1 |
| 26. | Z | 0,1 |
Этот нумерованный список определяет приблизительную частоту появления букв, что означает, что в каком-то конкретном отрывке частота букв может меняться в зависимости от использованных в нем слов.
Английский алфавит: гласные буквы
Как вы могли заметить, гласных букв в английском языке всего 5. Это буквы: A, E, I, O, U. Периодически к списку добавляется буква Y, которая может передавать как согласный, так и гласный звуки. Кстати, что касается звуков: английские гласные могут менять свое звучание в зависимости от двух аспектов:
Рассмотрим подобные изменения на примере буквы A:
| Звук | Пример | Транскрипция / Произношение | Перевод |
| ɑː | artist | [ˈɑːtɪst] – (атист) | художник |
| a | apple | [ˈap(ə)l] – (апл) | яблоко |
| ɔː | all | [ɔːl] – (оул) | все |
| ɛ | any | [ˈɛni] – (эни) | любой |
| a | cat | [kat] – (кэт) | кот |
| eɪ | safety | [ˈseɪfti] – (сэйфти) | безопасность |
Некоторые звуки имеют в своем составе двоеточие. Дело в том, что английские гласные звуки делятся на краткие и долгие. Краткие произносятся обычно, долгие же тянутся в 2, а то и в 3 раза дольше. Знать произношение буквы в слове по этому принципу необходимо, иначе можно исказить свою мысль. Примеры:
Дело в том, что английские гласные звуки делятся на краткие и долгие. Краткие произносятся обычно, долгие же тянутся в 2, а то и в 3 раза дольше. Знать произношение буквы в слове по этому принципу необходимо, иначе можно исказить свою мысль. Примеры:
| ant [ant] (ант) — муравей | aunt [ɑːnt] (ант) — тетя |
| fit [fɪt] (фит) — соответствовать | feet [fiːt] (фит) — ступни |
| still [stɪl] (стил) – до сих пор | steal [stiːl] (стил) — воровать |
Касаясь особенностей гласных, можно также добавить, что буква E на конце обычно не произносится. Например:
| prejudice [ˈprɛdʒʊdɪs] (прэджюдис) | предубеждение |
| demonstrate [ˈdɛmənstreɪt] (дэмонстрэйт) | демонстрировать |
| paradise [ˈparədʌɪs] (парадайс) | рай |
Помимо этого, гласные буквы могут иметь дифтонги или сочетание двух гласных звуков, но во избежание слишком большого объема свалившейся информации рассмотрим этот вопрос в отдельной теме.
Можно добавить, что диакритических знаков гласные буквы, как в прочем и согласные, не имеют. К таким знакам относятся всякие черточки, закорючки, волнистые линии над и под буквами, которые характерны, например, французскому или испанскому языкам. Однако в очень редких случаях подобные знаки могут использоваться с заимствованными словами. Самыми популярными среди них считаются:
| café | кафе |
| resumé | резюме |
Английский алфавит: согласные буквы
Количество согласных букв в алфавите равняется 21. Несмотря на то, что эти буквы отличаются от русских, некоторые из них имеют похожее произношение. К ним относятся буквы: B, F, G, M, P, S, V, Z. Говоря о сходствах с русским языком, можно также отметить, что если английские слова имеют двойной согласный, он произносятся одним звуком:
| progress [ˈprəʊɡrɛs] (прогресс) | прогресс |
| illness [ˈɪlnəs] (илнэс) | заболевание |
| spelling [ˈspɛlɪŋ] (спэлинг) | правописание |
| irritation [ɪrɪˈteɪʃn] (иритэйшн) | раздражение |
Помимо простых букв в английском присутствуют диграфы или знаки, образующиеся с помощью двух английских букв. К ним относятся:
К ним относятся:
| Диграф | Транскрипция | Произношение |
| ch | [tʃ] | ч |
| sh | [ʃ] | ш |
| th | [ð] или [θ] | с / з |
| kh | [x] | х |
| zh | [ʒ] | ж |
Стоит отметить, что буква ch в заимствованных из греческого языка словах произносится как [k].
| [tʃ] | [k] |
| chop [tʃɒp] (чоп) — рубить | ache [eɪk] (эйк) — боль |
| change [tʃeɪn(d)ʒ] (чэндж) — изменение | chaos [ˈkeɪɒs] (кэйос) — хаос |
| achievement [əˈtʃiːvm(ə)nt] (эчивмэнт) — достижение | stomach [ˈstʌmək] (стомак) — живот |
| challenge [ˈtʃalɪn(d)ʒ] (чэлэндж) — вызов | technology [tɛkˈnɒlədʒi] (тэкнолоджи) — технология |
| cheerleader [ˈtʃɪəliːdə] (чилидэ) — чирлидер | choreography [ˌkɒrɪˈɒɡrəfi] (кориографи) — хореография |
Как звук [k] буква ch читается и в очень распространенном за рубежом имени Майкл:
| [k] | |
| Michael [maɪkl] (майкл) | Майкл |
Исключение, не относящееся к вариантам выше:
| [ʃ] | |
| champagne [ʃamˈpeɪn] (шампэйн) | шампанское |
Сочетание th произносится как «с» и «з» в русском, только для их произношения вам необходимо правильно расположить язык. Прикусите, а потом опустите его, сохраняя положение между зубов. А теперь попробуйте произнести обе эти буквы.
Прикусите, а потом опустите его, сохраняя положение между зубов. А теперь попробуйте произнести обе эти буквы.
Диграфы kh и zh употребляются в английском с иностранными фамилиями. Иностранные фамилии также часто могут содержать диграф sh, который, однако, используется и в обычных английских словах.
| Khalilov | Халилов |
| Akhedzhakova | Ахеджакова |
| Khmelnytskyi | Хмельницкий |
| Dzhanabaev | Джанабаев |
| Zhvanetsky | Жванецкий |
| Zhukovsky | Жуковский |
| Kozhevnikov | Кожевников |
| Sholokhov | Шолохов |
| Sharapova | Шарапова |
| Shepelev | Шепелев |
Английский алфавит: как выучить
Сколько букв и как они используются, разобрали, но как же их выучить? В современном мире этот вопрос решить достаточно легко, потому как материалов по изучению английского и в печатном, и в электронном вариантах ну очень много. Однако выбор в пользу электронного материала в случае изучения алфавита будет, пожалуй, более правильным.
Однако выбор в пользу электронного материала в случае изучения алфавита будет, пожалуй, более правильным.
Во-первых, английский алфавит – это то, что учится очень быстро. После того, как вы его освоите, вам не придется вновь и вновь возвращаться к этой теме, а значит, купленные азбуки будут лежать без дела на самых верхних полках.
Во-вторых, в интернете можно найти наибольшее разнообразие программ, видео, песен, которые помогут вам выучить алфавит за максимально короткий срок. Используйте только один способ или совмещайте сразу несколько: напевайте песенки, прописывайте каждую букву на листочке, запоминайте последовательность букв в английском и слова, в которых они используются.
Вот и все. Как видите, ничего страшного в английском языке нет. Единственное, что может понадобиться при его изучении – немного терпения, приправленного мотивацией. Не воспринимайте язык как что-то неподъемное, а вместо этого получайте от него удовольствие.
Источник
Видео
АНГЛИЙСКИЙ АЛФАВИТ за 5 минут!
Alphabet. Английский алфавит. Песня про алфавит. Alphabet Song. Учим Алфавит. Learn Alphabet.
Английский алфавит. Песня про алфавит. Alphabet Song. Учим Алфавит. Learn Alphabet.
Алфавит Английский язык учим буквы
Таблица гласных МФА – IPA Vowel Chart – транскрипция и произношение. Часть 1
Английский на 5! Урок 2. Гласные буквы и звуки английского алфавита
Таблица с английским алфавитом.
АЛФАВИТ Английский.НАУЧУ ЧИТАТЬ ЛЮБОГО ЗА 15 уроков! Уроки английского чтения с нуля. Урок 1.
(Английский язык) 3. Английский алфавит
Английский алфавит для детей ABS SOUNDS
Звуки английского языка (чтение транскрипции)
Учим писать буквы английского алфавита
Английский алфавит: печатные и прописные буквы
В настоящее время не только у родителей, но и у преподавателей английского языка все чаще возникает вопрос о том, как правильно писать прописные буквы английского алфавита. Такая ситуация сложилась в связи с тем, что в англоязычных странах уже довольно длительное время не только дети, но и взрослые пишут полу печатными или печатными буквами. России учителя продолжают преподавать детям письменную каллиграфию.
России учителя продолжают преподавать детям письменную каллиграфию.
Прописи английского алфавита — плюсы и минусы
Тем, кто не хочет в век глобальной компьютеризации тратить время на обучение прописные буквы английского алфавита, вполне достаточно знания печатного алфавита. При таком способе письма надо обращать внимание на то, чтобы между буквами одного слова расстояния были минимальными, поскольку печатные буквы между собой не соединяются, и зачастую текст трудно читать, так как внутри слова промежутки больше, чем интервал между словами. Каждая буква должна писаться слитно, не разделяясь на части, иначе написанное будет тяжело понять. При этом необходимо учесть, что печатный способ написания букв в значительной степени увеличивает время, необходимое на написание текста. Помимо этого, человек, усвоивший только печатный алфавит, не сможет прочитать рукописные тексты или их электронную имитацию.
Для того чтобы приступить к занятию запаситесь шариковой ручкой и листком бумаги (желательно в линейку). Помните, очень важно правильно повторить траекторию написания английских прописных букв. Это следует делать для того чтобы в дальнейшем можно было достичь высокой скорости написания английских слов.
Помните, очень важно правильно повторить траекторию написания английских прописных букв. Это следует делать для того чтобы в дальнейшем можно было достичь высокой скорости написания английских слов.
Прописные буквы английского алфавита
Если ваш ребёнок начинает учить английский язык — вам понадобится плакат не только с печатными английскими буквами, но и с прописными буквами английского алфавита.
Обратите внимание на новую тенденцию написания большой буквы A. Сегодня принято ее писать также как и маленькую, хотя ранее она писалась похоже на русскую большую A.
В настоящее время, пожалуй, стоит смириться с тем, что большинство носителей английского языка (особенно — американцы, австралийцы) уже давно в своем повседневном обиходе не используют классическую пропись, поскольку изобразить «корявые» печатные буквы гораздо проще.
Каллиграфический английский алфавит
Каждый может научиться каллиграфии.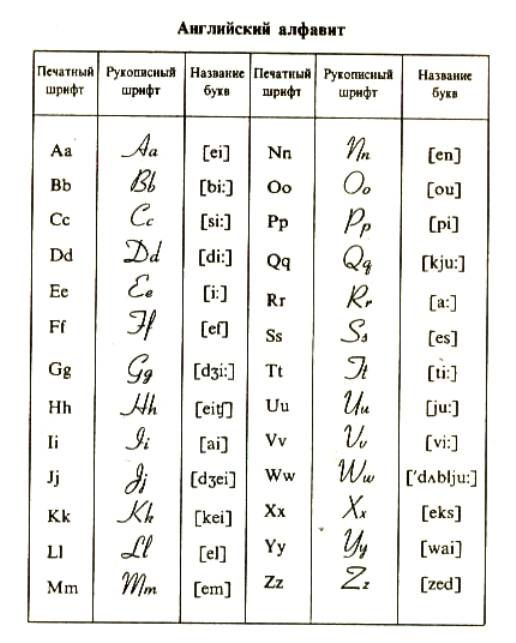 Даже если вы думаете, что ваш почерк отвратителен, найдется тот человек, который захочет, чтобы именно вы подписали свадебные приглашения перьевой ручкой. Особенно людям нравится современная каллиграфия, потому что она откровенно игнорирует традиционные правила и подчеркивает индивидуальность.
Даже если вы думаете, что ваш почерк отвратителен, найдется тот человек, который захочет, чтобы именно вы подписали свадебные приглашения перьевой ручкой. Особенно людям нравится современная каллиграфия, потому что она откровенно игнорирует традиционные правила и подчеркивает индивидуальность.
Английский алфавит: таблица с транскрипцией и русским произношением
Если вы только приступаете к освоению английского языка, начинайте обучение с основных тем, в числе которых, конечно же, присутствует English alphabet [ˈɪŋɡlɪʃ ˈalfəbɛt] или английский алфавит. При экспресс-обучении эту тему часто опускают, мол, придет сама со временем. Однако если вы не будете знать весь список букв, их произношение и написание, ничего путевого из вашего процесса обучения не выйдет. А потому давайте разберем, что собой представляют и как используются буквы английского алфавита.
Экскурс в историю английского алфавита
Но для начала посмотрим, как формировался английский алфавит. Сказать точно, когда он появился достаточно тяжело, но самые первые найденные фрагменты английского алфавита относятся к V веку.![]() Тогда для его написания использовались латинские буквы в сочетании с рунами, а потому буквы абсолютно не походили на те, которые используются в современном английском языке. В последующем, однако, этот алфавит менялся, все руны заменились латинскими буквами, количество которых к XI веку составило 23 знака, которые были упорядочены для нумерологических целей. После этого алфавит уже значительно не менялся, однако к нему добавилось еще 3 буквы, которые также использовались в создании современного алфавита.
Тогда для его написания использовались латинские буквы в сочетании с рунами, а потому буквы абсолютно не походили на те, которые используются в современном английском языке. В последующем, однако, этот алфавит менялся, все руны заменились латинскими буквами, количество которых к XI веку составило 23 знака, которые были упорядочены для нумерологических целей. После этого алфавит уже значительно не менялся, однако к нему добавилось еще 3 буквы, которые также использовались в создании современного алфавита.
Английский алфавит: состав
Сколько букв используется в современном английском посчитать, пожалуй, было не сложно. Букв в английском 26. В разных ситуациях они могут звучать по-разному, так как их произношение меняется в зависимости от сочетаний. Всего же в английском языке 44 звука. Однако каждая буква имеет свое стандартное произношение, которое используется при изучении алфавита. Пишутся английские буквы не так как произносятся, а потому при их изучении необходимо использовать транскрипцию во избежание дальнейших ошибок. Стоит также отметить, что каждая буква английского алфавита имеет порядковый номер. Нумерология английского, как и в русском, создана исключительно для удобства и как такой важности не имеет.
Стоит также отметить, что каждая буква английского алфавита имеет порядковый номер. Нумерология английского, как и в русском, создана исключительно для удобства и как такой важности не имеет.
Английский алфавит подробно для начинающих
Первое, что нужно выучить тому, кто мечтает овладеть английским, — это, конечно, английский алфавит. О нем и поговорим. Так как информации много, я разбила ее на разделы.
Содержание статьи Английский алфавит.
Буквы английского алфавита.
Современный английский алфавит имеет 26 букв (по-английски буквы называют letters или characters – chars для краткости). Каждая буква может быть прописной (uppercase / large) и строчной (lowercase / small). Основой для английского алфавита стали латинские буквы.
Точная форма печатных букв зависит от шрифта.
Начертание букв английского алфавита.
Красным я выделила гласные, синим – согласные.
Звучание букв английского алфавита отличается в разных вариантах. Так последняя буква Z в английском варианте произношения звучит [зэд] / [zed], а в американском – [зи] / [zı:]. Британцы произносят “zed”, потому что данная буква произошла от греческой буквы “Zeta”, которая перешла в старофранцузский как “zede”, откуда перекочевала в английский алфавит в 15-м веке в качестве “zed”.
Так последняя буква Z в английском варианте произношения звучит [зэд] / [zed], а в американском – [зи] / [zı:]. Британцы произносят “zed”, потому что данная буква произошла от греческой буквы “Zeta”, которая перешла в старофранцузский как “zede”, откуда перекочевала в английский алфавит в 15-м веке в качестве “zed”.
Американцы произносят букву “z” как [zı:] по аналогии с названием других букв: В [bı:], С [sı:], D [dı:] и пр. Впервые американское произношение буквы “z” как [zı:] было запротоколировано в Lye’s New Spelling Book в 1677 г. Данное решение долго оспаривалось, но было полностью принять в 1827 после публикаций Вебстера.
Сегодня большинство из тех, кто изучает английский алфавит, также называют эту букву [zı:]. Скорее всего данная тенденция объясняется тем, что в большинстве песенок про алфавит поется именно [zı:], так как для данного варианта произношения легче подобрать рифму.
[zı:] — Now I know my A-B-Cs
[zı:] — Next time won’t you sing with me?
Но англичане не отстают, и сегодня распространено также окончание песенки
[zed] — Sugar on your bread. Eat it all up before you are dead.
Eat it all up before you are dead.
Английский юмор, не правда ли?
Английский алфавит прописные буквы.
Обратите внимание на новую тенденцию написания большой буквы A. Сегодня принято ее писать также как и маленькую, хотя ранее она писалась похоже на русскую большую A. Вот вариант старого написания.
Стоит сказать, что среди изучающих английский алфавит в других странах мало кто пользуется прописными буквами. Данная тенденция намечается и в странах, где английский является родным. Посмотрите на два рукописных текста. В первом варианте для письма использованы обычные буквы, соединенные в письме так, как удобно пишущему. Во втором варианте использованы прописные буквы английского алфавита, конечно, с особенностями почерка.
А вот как выглядит каллиграфически выверенный вариант рукописного английского. Письменный английский алфавит выглядит изыскано.
А так пишут английские врачи. Кое-что напоминает, не правда ли?
Прописи английского алфавита.

Предлагаю Вам набор прописей английского алфавита. Нажмите, чтобы увеличить.
Английский алфавит прописью.
Английский алфавит с транскрипцией и произношением
Гласные английского алфавита.
В английском алфавите 6 гласных. Не принять говорить “гласные буквы английского алфавита”. Буква – это начертание звука. Гласным или согласным, также как звонким, твердым, мягким, шипящим и пр. может быть только звук. OK, переходим к буквам английского алфавита, которые передают гласный звук. Это A, E, I, O, Y, U – итого 6. Каждая буква может выражать несколько звуков.
- [eı] – эй;
- [æ] – широкий э;
- [α:] – долгий a;
- [ᴐ:] – долгий о;
- [ɒ] – краткий прикрытый о;
- [ə] – краткий прикрытый э.
- [ı:] – долгий и;
- [ı] – краткий и;
- [ɜ:] – широкий э;
- [ıə] – иэ;
- [α:] – долгий
- [e] — краткий Э
- [aı] – ай;
- [ı] – краткий и;
- [ı:] – долгий и;
- [ɜ:] – широкий э.
- [əυ] – эу;
- [ɒ] – краткий о;
- [u:] – долгий у;
- [ʌ] – краткий а;
- [ᴐ:] – долгий о.
- [aı] – ай;
- [ı] – краткий и;
- [j] – согласный й.
- [ju:] – йу;
- [ʌ] – краткий а;
- [u] – краткий у.
Так читаются гласные английского алфавита. Переходим к согласным.
Согласные английского алфавита.
В английском алфавите 20 согласных.
[s] / [c] перед гласными i, e, y
[dʒ] / [дж] перед e, i, y
[h] / [x] простой выдох
[ŋ] / [носовой / заднеязычный н] перед g и иногда перед k
[kw] / [кв] в сочетании qu
[r] — звук, нечто среднее между р и очень твердым русским ж; произносится без вибрации. Часто и вовсе не произносится
[z] / [з] в конце слова после гласного или звонкого согласного, иногда в середине слова между 2-мя гласными
[w] — звук, похожий на [ув]
[gz] / [гз] перед ударным гласным
[z] / [з] – иногда в начале слова
История английского алфавита.

Эволюция английского алфавита очевидна за последние 1500 лет. Хотя современный английский алфавит содержит 26 букв, раньше их было больше.
После 6-го века, когда христианские монахи начали транслитерацию англо-саксонского с помощью латинских символов, они столкнулись с некоторыми сложностями. Англо-саксонский содержал несколько звуков, которые невозможно было записать латиницей. Потому монахи позаимствовали три старые руны: ð (межзубной звонкий з), þ (межзубной глухой с), и Ƿ (уинн, аналог современной W). Наличие этих рун, лигатур (соединения букв) æ и œ, а также отсутствие J и Y – одна из характерных особенностей англо-саксонского алфавита. Посмотрите на рукопись Беовульфа.
Под влиянием норманнского письма рунический характер английского алфавита постепенно угасал и буквы ð, þ и Ƿ вскоре исчезли. Вместо Ƿ стали использовать двойную V ->VV, которая постепенно стала самостоятельной буквой W в результате использования печатных станков.
Как же Y и J присоединились к английскому алфавиту? Y и U произошли от V, в результате дифференциации согласных и гласных. J произошла от I.
J произошла от I.
С характерной для него изобретательностью, Бенджамин Франклин пытался улучшить английский алфавит. Он предложил убрать c, j, q, w, x, и y, так как их можно заменить другими буквами. Он также предлагал добавить шесть букв собственного изобретения. Но алфавит Франклина не прижился.
Сегодня самыми частыми буквами английского алфавита являются e, t, a, o. Самые редкие – х, q, z.
Понравилось? Сохраните на будущее и поделитесь с друзьями!
10 Комментариев для «Английский алфавит подробно для начинающих»
Источники: http://englandlearn.com/abc/propisnye-bukvy-anglijskogo-alfavita, http://speakenglishwell.ru/anglijskij-alfavit-english-alphabet/, http://grammar-tei.com/anglijskij-alfavit-podrobno-dlya-nachinayushhix/
ОТКУДА ПРИШЛА КАЖДАЯ БУКВА — School Englishpapa на vc.ru
25 просмотров
У английского алфавита интересное происхождение, и каждая его буква тоже имеет свою историю. На становление английского алфавита повлияли германские племена со своим руническим письмом и христианские миссионеры, принесшие с собой латиницу.
История каждой буквы английского алфавита
Английский алфавит в его современном виде из 26 букв сформировался в XVI веке. На его развитие оказали влияние семитские письмена, финикийское письмо, греческий и латинский алфавит. Кстати, само слово alphabet происходит от двух первых букв греческого алфавита: «альфа» и «бета».
Буква A
Первоначальная, в египетских иероглифах, эта буква была перевернутой формы и выглядела она как голова животного с рогами. В семитских письменах эта буква имела значение «бык». И только в греческом и латинском алфавите ее перевернули, и она обрела свою современную форму.
Буква B
В своем первоначальном виде буква B была заимствована из египетской пиктограммы, обозначающей «убежище». В первоначальном виде она выглядела как дом с дверью, крышей и комнатой. До современного вида была адаптирована греками и римлянами.
Буква C
Имеет финикийское происхождение. Первоначальная форма — в виде бумеранга. Греки называл эту букву «гамма», и они же повернули ее в другую сторону, а римляне придали более удобную форму в виде полумесяца.
Буква D
«Далет» — так называли современную букву D финикийцы в 800 году до нашей эры. Тогда она выглядела как треугольник со смещенным верхним углом влево и обозначала «дверь». Когда греки переняли этот алфавит, они дали этой букве название «дельта». Позже пиктограмму перевернули, а римляне придали правой стороне буквы форму полукруга.
Буква E
Подобно многим другим буквам, она пришло в английский язык через латинский, который перенял греческую букву «эпсилон», происходящую из семитских языков. Оригинальный египетский иероглиф, послуживший источником, имел форму человека с поднятыми руками. В настоящее время буква E является наиболее часто используемой буквой в английском.
Буква F
Эта буква пришла от финикийцев, и тогда она больше походила на Y, а когда ее произносили, издаваемый звук был близок к «wow». Древние греки переименовали ее в «дигамма» и сделали похожей на современную F. Римляне пошли дальше, придав букве четкую форму и изменив звук на «fff».
Буква G
Буква G произошла от греческой «дзета». Римляне немного изменили ее форму около 250 г. до н. э., сделав верхнюю и нижнюю части более четкими, а также стали называть ее звуком «г».
Буква H
Буква H появилась на основе египетского иероглифа, обозначавшего «забор». При ее произнесении получался хриплый звук, поэтому к 500 году н. э. британские ученые-лингвисты того времени решили, что ей не место в английском алфавите. Но постепенно буква H вернулась в английский алфавит, найдя в нем себе место.
Буква I
Будучи заимствованной из финикийской буквы «йод», I изменила свою форму в греческом алфавите и превратилась в букву «йота». Нынешнюю форму в виде прямой линии эта буква получила в 700 г. до н. э.
Буква J
Появилась как отдельная буква, четко отличающаяся от I в английском алфавите, только в XVI веке. Значительное влияние на ее развитие оказали романские языки, особенно французский и испанский.
Буква K
Эта буква произошла от семитской буквы «каф», которая, в свою очередь, произошла от египетского иероглифа, означающего «рука». Далее она перешла в греческий алфавит, став буквой «каппа», а затем через латинский — в английский.
Далее она перешла в греческий алфавит, став буквой «каппа», а затем через латинский — в английский.
Буква L
В древнем семитском языке современная буква L была перевернутой, называлась она «эль», что означало «Бог». Финикийцы перевернули ее влево, немного поправили крючок и назвали «лах-мед», что означало «погонщик для скота». Греки переименовали ее в «лямбда» и повернули вправо. Окончательный вид буквы L с прямой линией и прямым углом появился благодаря римлянам.
Буква M
Первоисточник — египетский иероглиф в виде волнистой линии с пятью вершинами, обозначавший слово «вода». В 1800 г. до н. э. семиты сократили вершины до трех, а финикийцы убрали еще одну. В 800 г. до н. э. линии стали более острыми, образуя букву М, которую мы знаем сегодня.
Буква N
И снова первоначальным вариантом является египетский иероглиф, состоящий из двух волнистых линий, который обозначал слово «змея». Древние семиты придали ему звук «н», что символизировало на их языке «рыбу». Около 1000 г. до н. э. осталась только одна волна, и греки назвали ее «ню». В таком виде она дошла до англичан.
Около 1000 г. до н. э. осталась только одна волна, и греки назвали ее «ню». В таком виде она дошла до англичан.
Буква O
Она не сильно изменила свою первоначальную форму, поскольку исходный египетский иероглиф был похож на глаз и обозначал то же понятие. Финикийцы оставили только контур зрачка, в таком виде буква О и дошла до современного английского.
Буква P
На древнем семитском языке сегодняшняя буква P выглядела как перевернутая буква V, как «пe», что означало «рот». Финикийцы сделали крючок из ее верхушки, а в 200 г. до н. э. римляне перевернули букву вправо и замкнули петлю, образовав современную Р.
Буква Q
У этрусков звук иероглифа Q был похож на «qoph», что переводится как «клубок шерсти» или «обезьяна». Изображался иероглиф как круг, пересекаемый вертикальной линией. В римских письменах около 520 г. до н. э. буква Q стала такой, какой мы ее знаем сегодня.
Буква R
В семитских письменах профиль человека, обращенного влево, был первоначальной формой буквы R. Она произносилось как «реш», что означало «голова». Римляне повернули ее вправо и добавили наклонную «ногу».
Она произносилось как «реш», что означало «голова». Римляне повернули ее вправо и добавили наклонную «ногу».
Буква S
Буква S раньше представляла собой горизонтальную волнистую букву W, которая обозначала «лук лучника» у финикийцев. Римляне придали ей вертикальное положение и назвали «сигма». В таком виде она дошла до наших времен.
Буква T
Одна из наиболее последовательных букв, имевшая сходную форму и обозначавшая один и тот же звук в финикийском, этрусском, греческом и латинском языках. Финикийцы называли букву «ти», греки — «тау».
Буква U, V и Y
Наряду с F, эти три буквы имеют одинаковое происхождение, восходящее к финикийскому алфавиту и букве Waw. Отличие U от V появилось в XIV веке, а U выглядела, как Y, до 1000 года до н. э.
Буква W
Буква W появилась в средние века, когда писцы Карла Великого изображали рядом две буквы U, разделенные пробелом. В то время издаваемый звук был похож на «v». Буква появилась в печати как уникальная W в 1700 году.
Буква Х
Буква «кси» у древних греков звучала как современная Х. У этой буквы древнегреческие корни, но в английский алфавит она попала из латинского.
Буква Z
У финикийцев была буква «заин», что означало «топор». Первоначально она выглядела как I, но с засечками вверху и внизу. Около 800 г. до н. э. букву переняли греки, но звучала она у них как «зета» и передавала звук «дз». Активно ее использовать стали нормандцы, которые и принесли эту букву в английский алфавит.
Как вы видите, большинство букв английского алфавита пришло из латинского (хотя первоначальное происхождение было разным), остальные буквы и сочетания — результат рунического влияния. Диграфы (ch, th, gh, wh, zh,) звуки æ, œ в современном английском не включены в алфавит, но продолжают активно использоваться.
Курсы английского языка в Минске
Английский алфавит с произношением и транскрипцией
13.10.2020
Практические занятия 15.1K
В английском алфавите 26 букв. Однако, не всегда они обозначают такие же звуки. В этом, пожалуй, и состоит основная сложность английского произношения. Английские слова не всегда читаются так, как пишутся.
В этом, пожалуй, и состоит основная сложность английского произношения. Английские слова не всегда читаются так, как пишутся.
Но обо всём по порядку. В этой статье мы разберёмся как правильно произносить отдельные буквы английского алфавита.
Английское слово alphabet берёт начало от двух букв греческого алфавита: alpha и beta.
Всего в английском языке 5 гласных букв: A, E, I, O, U. Иногда в этот список включают Y. В зависимости от чтения в том или ином слове. К примеру, эта буква читается как гласная в слове sky [skaɪ] и как согласная в слове yes [jes].
В британском и американском вариантах английского языка все буквы произносятся одинаково, кроме Z. Вариант [zed] – британский, вариант [zi] – американский.
Если необходимо помочь малышу выучить алфавит, очень хорошо подойдут детские песенки с повторением букв или яркие красочные картинки с изображением букв английского алфавита.
К каждой карточке можно добавить рисунок с предметом или животным, название которого начинается на эту букву. Так будет легче запоминать.
Знание алфавита поможет, если будет необходимость произнести по буквам отдельные слова. Например, вы регистрируетесь в отеле или принимаете участие в каком-то мероприятии, где могут попросить произнести имя или фамилию по буквам, чтобы правильно записать. Могут сказать: How do you spell your name?
Что касается слов, то буквы в разнообразных сочетаниях произносятся по-разному. С этим разберемся в следующих статьях. А пока практика!
Далее вы можете прослушать, как звучат буквы английского алфавита.
| # | Озвучка | Заглавная буква | Строчная буква | Транскрипция |
|---|---|---|---|---|
| 1 | A | a | /eɪ/, /æ/ | |
| 2 | B | b | /biː/ | |
| 3 | C | c | /siː/ | |
| 4 | D | d | /diː/ | |
| 5 | E | e | /iː/ | |
| 6 | F | f | /ɛf/ | |
| 7 | G | g | /dʒiː/ | |
| 8 | H | h | /(h)eɪtʃ/ | |
| 9 | I | i | /aɪ/ | |
| 10 | J | j | /dʒeɪ/ | |
| 11 | K | k | /keɪ/ | |
| 12 | L | l | /ɛl/ | |
| 13 | M | m | /ɛm/ | |
| 14 | N | n | /ɛn/ | |
| 15 | O | o | /oʊ/ | |
| 16 | P | p | /piː/ | |
| 17 | Q | q | /kjuː/ | |
| 18 | R | r | /ɑːr/ | |
| 19 | S | s | /ɛs/ | |
| 20 | T | t | /tiː/ | |
| 21 | U | u | /juː/ | |
| 22 | V | v | /viː/ | |
| 23 | W | w | /ˈdʌbəl. juː/ juː/ | |
| 24 | X | x | /ɛks/ | |
| 25 | Y | y | /waɪ/ | |
| 26 | Z | z | /zi/zɛd/ |
Тренируйте алфавит на нашей платформе LingvoHabit!
Зарегистрируйтесь или авторизуйтесь на сайте, чтобы пройти квизы по теме и проверить себя: тест 1, тест 2, тест 3.
Нравится статья? Поддержи наш проект и поделись с друзьями!
Оставьте свой комментарий
Проект Карла III Ребане и хорошей компании | Раздел недели: Перевод единиц измерения величин. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Техническая информация тут Поиск на сайте DPVA Полезные ссылки О проекте Обратная связь Оглавление | Адрес этой страницы (вложенность) в справочнике DPVA.xyz: главная страница / / Техническая информация/ / Алфавиты, номиналы, единицы/ / Алфавиты, в т.ч. греческий и латинский. Символы. Коды. Альфа, бета, гамма, дельта, эпсилон… / / Алфавит английский. Английский алфавит (26 букв). Алфавит английский нумерованный (пронумерованный) в обоих порядках. (“латинский алфавит”, буквы латинского алфавита, латинский международный алфавит) Поделиться:
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Если Вы не обнаружили себя в списке поставщиков, заметили ошибку, или у Вас есть дополнительные численные данные для коллег по теме, сообщите , пожалуйста. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Коды баннеров проекта DPVA.xyz Консультации и техническая | Проект является некоммерческим. Информация, представленная на сайте, не является официальной и предоставлена только в целях ознакомления. Владельцы сайта www.DPVA.xyz не несут никакой ответственности за риски, связанные с использованием информации, полученной с этого интернет-ресурса. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 Перевод единиц измерения физических величин. Таблицы перевода единиц величин. Перевод химических и технических единиц измерения величин. Величины измерения. Таблицы соответствия величин.
Перевод единиц измерения физических величин. Таблицы перевода единиц величин. Перевод химических и технических единиц измерения величин. Величины измерения. Таблицы соответствия величин.лучших советов, которые помогут вам легко выучить английский язык
Вы начинаете свой путь в изучении английского языка? Всегда лучше начинать сначала. А что может быть лучше начальной основы, чем изучение английского алфавита?Алфавиты повсюду. Эти последовательные наборы символов и букв представляют собой фонетику любого данного языка и составляют основу многих языков мира.
В этой статье вы узнаете о важности алфавита, произношении букв английского алфавита и фонетическом алфавите английского языка. Мы также рассмотрим несколько забавных (и полезных!) песен и советов, которые помогут вам освоить алфавит.
Продолжайте читать, чтобы получить некоторые конкретные знания английского алфавита, практические советы о том, как выучить английский алфавит и научиться уверенно читать, произносить и писать английские буквы. Давайте начнем.
Зачем учить английский алфавит?
Английский алфавит является основой разговорного английского языка, позволяя учащимся понять, как произносить слова и буквы, думать и писать на языке.
Три главные причины для изучения английского алфавита:
1. Чтобы научиться произносить слова
Изучение и овладение алфавитом поможет вам свободно говорить по-английски. Это поможет вам или другим учащимся произносить полные слова. Это отличный способ выучить звуки букв и правильно их освоить.
2. Думать на английском языке
Когда вы думаете на английском языке, вам не нужны переводы с вашего родного языка. Это упростит общение и сделает разговор более похожим на бегло говорящего по-английски.
Знание английского алфавита и изучение звуков каждой буквы поможет вам читать слова так, как они произносятся.
3. Научиться писать по буквам
Изучение букв алфавита может помочь вам освоить правописание слов на английском языке и даже составлять грамматически правильные предложения.
Зная, как писать слова на английском языке, вам будет легче общаться на нем. Вы также можете научиться произносить по буквам полезные слова, такие как ваше имя и адрес.
Произношение английского алфавита
Так же, как вы научитесь произносить слова на английском языке, вы также выучите произношение каждой буквы алфавита в этом языке. Когда буквы произносятся как часть слова, их произношение меняется.
Например, буква «y» произносится как /waɪ/. Однако оно произносится как /i:/, когда является частью слова, например, «семья».
Английская фонетическая орфография помогает учащимся научиться понимать, как произносятся буквы и слова. Это поможет вам научиться произносить буквы алфавита быстрее и легче их запоминать. Например, /waɪ/ — фонетическое написание буквы «у».
English Phonetic Spelling for Each Alphabet Letter and Relevant Pronunciation
| Upper case letter | Lower case letter | English alphabet pronunciation |
| A | a | [eɪ] |
| B | B | [BIː] |
| C | C | [SIː] |
| D | D | |
| D | D | |
| D | D | 0050 [diː]|
| E | e | [iː] |
| F | f | [ɛf] |
| G | g | [dʒiː] |
| H | h | [eɪtʃ] |
| I | i | [aɪ] |
| J | j | [dʒeɪ] |
| K | k | [keɪ] |
| L | л | [ɛl] |
| M | m | [ɛm] |
| N | n | [ɛn] |
| O | o | [oʊ] |
| P | p | [piː] |
| Q | q | [kjuː] |
| R | r | [ɑr] |
| S | s | [ɛs] |
| T | т | [tiː] |
| U | u | [juː] |
| V | v | [viː] |
| W | w | [ˈdʌbəl juː] |
| X | x | [ɛKS] |
| Y | Y | [WAɪ] |
| Z | Z | [ZIː] |
PHIPONETIC ALPHABET
The Phisonetic Alphabet
The Phisonetic Alphabet
666.
Фонетический алфавит использует Международный фонетический алфавит (IPA) для индивидуального написания букв. Это позволяет учащимся точно представлять звуки языка в письменных символах и символах.
Алфавит правописания использует для общения фонетический алфавит НАТО. Набор слов для устного общения использует кодовое слово, представляющее начальный буквенный символ или букву. Фонетический алфавит имеет 26 кодовых слов, присвоенных английскому алфавиту от первой до последней буквы.
| Символ или буква | Кодовое слово | Звуковое произношение | |||
| 3 Альфа/Альфа | 0053Al Fah | ||||
| B | Bravo | Brah Voh | |||
| C | Charlie | Char Lee | |||
| D | Delta | Dell Tah | |||
| E | Echo | Eck OH | |||
| F | Foxtrot | Foks Trot | |||
| G | Golf | Golf | |||
| H | Отель | HOH. 0053 | |||
| I | India | In Dee Ah | |||
| J | Juliett | Jew Lee Ett | |||
| K | Kilo | Key Loh | |||
| L | Lima | Lee Mah | |||
| M | Mike | MIke | |||
| N | November | No Vember | |||
| O | Oscar | Oss Cah | |||
| P | Papa | Pah Pah | |||
| Q | Quebec | Keh Beck | |||
| R | Romeo | Row Me Oh | |||
| S | Sierra | See Airrah | |||
| T | Tango | Tang OH | |||
| U | Устройство | You Nee Form | |||
| V | VICTOR | VIK TAH | 999999.W | Whiskey | Wiss Key |
| X | X-Ray | Ecks Ray | |||
| Y | Yankee | Yang Key | |||
| Z | Zulu | Zoo Loo |
Песни с английским алфавитом
Наука утверждает, что музыка и изучение языка идут рука об руку! Имея это в виду, песни с английским алфавитом могут быть практичным способом закрепить буквы английского алфавита в вашей памяти при изучении английского алфавита.
Некоторые популярные песни на английском языке включают:
See It, Say It, Sign it by Jack Hartmann – Children’s Music
Эта песня на английском языке учит языку жестов (американскому языку жестов) каждой буквы английского алфавита, включая соответствующие буквы звучат.
The ABC Song – поп-музыка для детей
Эта песня помогает детям выучить английский алфавит с соответствующей акустикой.
Азбука для взрослых, изучающих английский как второй язык
С помощью этой песни с английским алфавитом взрослые учащиеся могут освоить буквы алфавита, такие как ABC на английском языке, включая их звуки и фонетику.
Часто задаваемые вопросы по английскому алфавиту
Какие упражнения по английскому алфавиту я могу выполнять, чтобы помочь себе в обучении?Вот некоторые упражнения по английскому алфавиту, которые помогут вам выучить:
- гласные: аудирование и математика;
- алфавит: слушай и пиши, слушай: расставь буквы по порядку; и
- напишите, среди прочего, пропущенные буквы.
Семитскоязычные жители Ближнего Востока разработали алфавит около 1700 г. до н.э. прежде чем был распространен финикийцами около 700 лет спустя. Именно из этого алфавита был разработан современный алфавит.
Сколько букв в английском алфавите? В английском алфавите 26 букв, в том числе 21 согласная и 5 гласных.
Как выучить английский алфавит: советы и рекомендации
Английский язык широко используется во всем мире, и произношение букв и слов может помочь вам исправить сильный акцент.
Также известный как современная латиница, английский алфавит обеспечивает прочную основу для изучения английского языка как первого или второго языка.
Хотите ли вы выучить английский как второй язык или хотите стать полиглотом с другим языковым алфавитом, следующие советы помогут вам освоить основы английского алфавита:
1. Изучите алфавит в игровой формеВо-первых, научитесь правильно произносить свое имя по буквам — это одно из самых распространенных слов, которое вам придется повторять часто.
Свяжите объекты со звуками первой буквы слов, которые вы уже знаете на английском языке, чтобы помочь вам освоить буквы алфавита. Например, «c» для «автомобиля» или «d» для «собаки».
Учите слова и правописание группами по 4 или 5 букв, чтобы избежать перегрузки информацией.
Алфавитные игры помогут вам выучить буквы алфавита в увлекательной игровой форме, избавят от скуки и повысят ваш моральный дух. Некоторые забавные игры для запоминающегося и приятного обучения включают:
- Алфавитные головоломки
- Поиски сокровищ
- Сопоставление предметов — случайные объекты или картинки помогают вам выучить звучание первых букв в словах или именах. Игра позволяет соревноваться между учащимися.
Визуальные материалы помогут вам запомнить, как буквы формируются и правильно пишутся, а аудио поможет вам выучить звуки каждой буквы алфавита.
Хотя вы можете повторять отдельные буквы алфавита и запоминать их, видеотехнологии упростили процесс обучения. YouTube и другие бесплатные онлайн-платформы являются полезными источниками видео для изучения английского алфавита.
3. Написание или чтение букв Громко произносите слова по буквам и повторяйте их буквы, чтобы освоить английский алфавит. Вы также можете учиться на ошибках других учащихся, когда они повторяют буквы и пишут слова.
В результате вы освоите буквы уже знакомых вам слов и даже выучите новые. Используйте словарный запас и грамматику на своем уровне обучения, чтобы легко осваивать слова.
4. Сначала выучите простые словаПроизношение английского алфавита, правописание, грамматика и словарный запас являются столпами изучения английского языка. Вы можете выучить базовую лексику, например дни недели, по мере изучения алфавита, чтобы быстрее продвигаться в обучении.
После освоения символов и слов вы можете приступить к изучению более сложной грамматики. Научившись произносить свое имя по буквам, сосредоточьтесь на словах, в которых используются распространенные буквы английского алфавита A, B, D, N и E.
Из этих букв можно составить различные слова, например:
- Bad
- Den
- Bed
- Dan
- Ben и т. д.
На этом этапе вы также можете научиться произносить звуки с помощью согласных и гласных.
Изучение английского алфавита — отличная основа
Английский алфавит является основой изучения языка для изучающих ESL. Знание этих 26 букв поможет вам в изучении английского языка онлайн, в том числе в том, как произносить каждую букву и использовать ее для создания слов.
Так что, если вы хотите начать свое собственное путешествие, ищете несколько советов, которые помогут вашим знакомым начать свое путешествие, помните – практика делает совершенным. Вскоре вы сможете петь азбуки лучше, чем Jackson 5, а затем переходить к более сложным английским темам – все время веселится!
Расшифровка букв английского алфавита с использованием информации о фазах ЭЭГ
Введение
В последнее десятилетие произошли большие изменения в интерфейсах мозг-компьютер (BCI), цель которых помочь пациентам с тяжелыми физическими недостатками взаимодействовать с внешним миром посредством таких задач, как набор букв английского алфавита на компьютере для общения. В исследованиях применялись вызванные стимулом сигналы электроэнцефалограммы (ЭЭГ) или электрокортикографии (ЭКоГ) головного мозга, особенно связанные с событием потенциалы (ERP) с ответами P300 (Zhang et al., 2013) и стационарные зрительно вызванные потенциалы (SSVEP) (Won et al. al., 2014; Nezamfar et al., 2016), чтобы различать характеристики стимула, такие как буквы. Появляется все больше свидетельств того, что частотно-зависимая фазовая картина и мощность нейронных колебаний могут кодировать важную сенсорную информацию, относящуюся к восприятию человеком внешнего мира, особенно в низкочастотных диапазонах (Luo and Poeppel, 2007; Schyns et al., 2011; Wang et al., 2012; ten Oever and Sack, 2015). Луо и др. (Luo and Poeppel, 2007) продемонстрировали, что фазовая картина активности тета-диапазона (5–8 Гц) слуховой коры человека содержит информацию, используемую для различения сигналов произнесенных предложений. Их результаты указывают на временное окно примерно в 200 мс (примерно 5 Гц в пределах тета-ритма), которое может иметь решающее значение для дискретных процессов восприятия. Последующие исследования фазового декодирования при восприятии звука показали, что аналогичный диапазон частот колебаний (3–7 Гц) является доминирующим при распознавании устных предложений (Luo and Poeppel, 2007; Howard and Poeppel, 2010; Wang et al., 2012; Ng et al.). и др., 2013; тен Овер и Сак, 2015). Нг и др. (2013) продемонстрировали, что стимулы можно различать по частоте импульсов и фазовым паттернам, но не по амплитуде колебаний. Другое недавнее исследование представило доказательства того, что слоги с разной зрительно-слуховой задержкой предпочтительно обрабатываются на разных фазах колебаний (ten Oever and Sack, 2015). Ван и др. (2012) использовали тангенциальное электрическое поле скальпа и поверхностный оператор Лапласа вокруг слуховой области коры, чтобы улучшить скорость распознавания английских фонем. Они создали сложный метод на основе бутстрапа, который достиг 53% точности для всех восьми фонем и показал, что фазовые последовательности работают лучше. также выявили, что изменения амплитуды (Worden et al. , 2000; van Dijk et al., 2008) и фазы (Vanrullen et al., 2011) текущей альфа-активности (9–12 Гц) за несколько сотен миллисекунд до того, как стимул сможет модулировать уровень визуального различения. Фактически, более свежие данные свидетельствуют о том, что снижение мощности альфа-канала может быть тесно связано с увеличением исходного уровня зрительной возбудимости, что может способствовать улучшению выполнения задач (Lange et al., 2013; Iemi et al., 2017).
Вышеупомянутые исследования предполагают важность частоты, фазы и амплитуды медленных колебательных активностей в репрезентации и категоризации объектов (Fries et al., 2007; Schyns et al., 2011). Например, колебательная мощность различных частотных диапазонов может служить для модуляции сенсорной возбудимости и внимания (Klimesch, 19).99; Энгель и др., 2001; van Dijk et al., 2008), в то время как колебательные фазовые паттерны в тета- и гамма-диапазонах могут быть задействованы в обработке информации, зрительном внимании и рабочей памяти (Lisman and Idiart, 1995; Siegel et al. , 2009; Heusser et al., 2016). ).
В этом исследовании мы изучили возможность использования сигналов фазы и мощности ЭЭГ для различения входных стимулов для подхода интерфейса мозг-компьютер (BCI). Мы выбрали английский алфавит в качестве визуального стимула, поскольку он является «модельным» стимулом в исследованиях НКИ. На основании приведенных выше экспериментальных исследований (Luo and Poeppel, 2007; van Dijk et al., 2008; Busch et al., 2009); Канолти и Найт, 2010 г .; Шинс и др., 2011; ВанРуллен и Макдональд, 2012 г.; Ван и др., 2012 г.; тен Овер и Сак, 2015 г.; Уотрус и др., 2015 г.; Хойссер и др., 2016; Tomassini et al., 2017), в котором представлены данные о том, как колебательные параметры (фаза, мощность и частота) могут кодировать визуальную и слуховую информацию, мы выдвигаем гипотезу о том, что информация от визуального представления различных букв английского алфавита может быть закодирована в Низкочастотные фазовые паттерны ЭЭГ. Фазовое декодирование и статистический анализ машинного обучения могут быть новым методом в дополнение к традиционному методу ERP для распознавания визуализированных букв. Это может иметь большое значение для разработки методов BCI. Кроме того, считается, что зрительная информация сначала проходит через первичную зрительную кору, а затем поднимается на более высокие уровни, такие как V3/4 TEO и TE, которые в задачах распознавания объектов называются вентральными путями (Tanaka, 19).96; Крюгер и др., 2013). Считалось, что вентральный путь особенно важен для чтения, включая распознавание слов и букв (Price and Devlin, 2011). Поэтому мы задались вопросом, существует ли разница в точности классификации между затылочной и височно-затылочной областями скальпа. Для изучения вышеуказанных проблем был разработан простой протокол BCI, в котором испытуемые наблюдали за случайно выбранными буквами на мониторе компьютера. Данные ЭЭГ были собраны у каждого субъекта, и был применен анализ, чтобы определить, можно ли различить визуальные буквенные стимулы на основе фазового паттерна ЭЭГ и амплитуды мощности.
Материалы и методы
Испытуемые
Четырнадцать студентов-правшей из Шанхайского университета Фудань были приняты на работу, предоставив денежную компенсацию. Праворукость определяли с помощью Эдинбургского опросника праворукости (Oldfield, 1971). Все испытуемые (симпатичные мужчины и пять женщин, средний возраст 25,4 года, диапазон: 21–32 года) имели нормальное цветовое зрение, скорректированную остроту зрения и не имели неврологических или психических проблем в анамнезе. Это исследование было одобрено и проводилось под контролем Комитета по этике Школы наук о жизни Университета Фудань (№ 29).0). Все участники подписали письменное информированное согласие.
Записи ЭЭГ и план эксперимента
Данные ЭЭГ записывали с частотой дискретизации 500 Гц в звуконепроницаемом помещении с использованием 64-канальной системы регистрации actiCHamp Brain Products (Brain Products GmbH, Inc., Мюнхен, Германия) относительно опорный сигнал Cz. Заземляющий электрод располагался на электроде Fz. Уровни импеданса поддерживались ниже 10 кОм.
Стимулы предъявлялись с использованием предварительно запрограммированного протокола e-prime. Пять строчных букв «а», «е», «и», «о» и «т» были выбраны в качестве букв, которые будут визуально представлены на экране компьютера. Буква «т» была выбрана для исключения особенностей произношения, поскольку остальные четыре буквы были гласными. Буквы были напечатаны белым шрифтом Times New Roman и представлены на черном фоне размером примерно 12 см * 12 см в поле зрения (FOV) 6,88 градусов. Испытуемые сидели на расстоянии одного метра от 23-дюймового экрана. Экран был отрегулирован на высоту сидящего испытуемого, чтобы испытуемые могли держать глаза горизонтально. Испытуемым было предложено сосредоточиться на экране и не двигать головой. Когда предъявляли письмо, испытуемым предлагалось прочитать его молча, не двигая ртом. Это было сделано для того, чтобы удерживать объект в фокусе и избегать любых миоэлектрических артефактов. Участников просили свести к минимуму движения глаз во время визуальной презентации и зафиксировать внимание на центре.
На рисунке 1 представлен экспериментальный протокол. В каждом испытании на экране на 1 с появлялась случайно отображаемая буква, после чего следовал пустой интервал в 3 с. Перед появлением буквы испытуемым предлагалось сосредоточить взгляд на белом кресте на экране в течение 1 с. В ходе исследования испытуемый наблюдал, как пять букв появляются по отдельности в случайном порядке в течение 450 попыток. 450 испытаний были разделены на три блока по 150 испытаний в каждом. В начале каждого блока на экране предъявлялась инструкция, и программа останавливалась до тех пор, пока испытуемый не нажимал кнопку «ввод» для продолжения. В каждом блоке буквы случайным образом появлялись 150 раз, при этом каждая буква по 30 раз. Между каждым блоком испытуемый делал небольшой перерыв, а затем выбирал, когда продолжить следующий блок исследования. На прохождение трех блоков ушло примерно 60 минут. Между каждым блоком запись останавливалась и проверялась проводимость электрода. Среднее значение успешных испытаний, использованных для анализа, составляет 351 ± 55 9 .0657 (среднее значение и стандартное отклонение) по всем субъектам.
Рисунок 1 . Методика эксперимента и обработка данных. (A) Буквы отображались случайным образом в центре экрана белым цветом на черном фоне. Буквы были примерно 12 см * 12 см. Буквы предъявлялись в течение 1 с, после чего следовал 3-секундный период покоя. Перед предъявлением письма на экране демонстрировался белый крест, чтобы испытуемые сохраняли фиксацию взгляда. (B) Обучающие наборы были извлечены из отфильтрованных сигналов мощности/фазы ЭЭГ с фиксированной длиной окна 200 мс. Окно начиналось за 100 мс до появления письма и заканчивалось через 500 мс.
Анализ предварительной обработки данных
Анализ предварительной обработки данных был выполнен с использованием EEGLAB (Delorme and Makeig, 2004) и включал полосовую фильтрацию (0,5–220 Гц), выделение эпохи, привязанное к началу букв (от −500 до 1000 мс), и базовый уровень коррекция (от −500 до 0 мс). Чтобы избежать путаницы, мы назвали эти данные «широкополосными данными», чтобы отличить их от более поздних узкополосных отфильтрованных данных, таких как данные ЭЭГ в альфа-диапазоне. Артефакты сигнала удалялись в два этапа. Во-первых, данные были проверены визуально, и эпохи, содержащие артефакты, такие как чрезвычайно высокоамплитудные колебания электродного кабеля, вызванные движением кабеля, были отклонены. Во-вторых, эпохи, содержащие типичные движения глаз и артефакты моргания, которые возникали в течение первых 800 мс после появления букв, отбрасывались. Для декомпозиции данных ЭЭГ был применен анализ независимых компонентов (ICA). После декомпозиции было получено 63 временных ряда активаций компонентов, соответствующих 63 каналам записи для каждого субъекта. Активация этих компонентов была идентифицирована как активность ЭЭГ или артефакты, не связанные с мозгом, путем визуального осмотра их топографии скальпа, временных характеристик и частотных спектров. Компоненты артефакта, связанные с сердцебиением, движением височной мышцы, движением глаз и морганием, были удалены. Критерии классификации активаций компонентов как активности ЭЭГ включали следующее: (1) спектральные пики на типичных частотах ЭЭГ и (2) сходные ответы в каждом испытании; т. е. ответ ЭЭГ не должен возникать только в небольшом количестве испытаний (Delorme and Makeig, 2004). На основании этих критериев были удалены активации компонентов, представляющие артефакты, не связанные с мозгом (удаленные ICA составляют 11,07 ± 8,62, среднее значение и стандартное отклонение, для 14 испытуемых), а данные ЭЭГ были реконструированы по оставшимся активациям компонентов.
Затем мы использовали преобразование Гильберта для преобразования очищенной от артефактов последовательности ЭЭГ в реальном времени в сложную временную последовательность. Каждое комплексное число содержит информацию об амплитуде и угле. Мы получили последовательность амплитуд A(t) и последовательность фаз P(t) отдельно. Затем мы применили анализ машинного обучения на основе данных об амплитуде или фазовой последовательности. Формула преобразования Гильберта представлена здесь:
Y(t) =H(x(t)) = ∫-∞+∞x(τ)*1t-τdτ
Преобразование Гильберта преобразует необработанный реальный сигнал в мнимый аналог, и эти две части составляют сложный сигнал. Последовательность мощности определяется как величина этого сложного сигнала, а последовательность фаз – как его фазовый угол.
Более того, дельта (1–4 Гц), тета (4–8 Гц), альфа (8–14 Гц), бета (14–30 Гц) и гамма (30 Гц выше) колебания диапазонов являются пятью типичными наблюдаемыми ритмами. в коре головного мозга и, как считается, тесно связаны с процессами познания (Kahana et al., 2001; Colgin et al., 2009; Fries, 2015). Кроме того, гамма-колебания можно разделить на низкие гамма-колебания (30–50 Гц) и высокие гамма-колебания (50–150 Гц). Чтобы исследовать функциональную роль этих колебаний в характеристиках буквенной классификации, исходный ответ ЭЭГ эпохи был отфильтрован в эти шесть диапазонов с использованием КИХ-фильтра с линейной фазой окна Кайзера в наборе инструментов MATLAB FDA. Полосы заграждения были установлены для ослабления амплитуды сигнала на уровне -30 дБ с краевой полосой 1 Гц. Затем к отфильтрованным данным применялось преобразование Гильберта.
Многоклассовый анализ классификации и подход с градиентным восхождением
Классификация по пяти классам использовалась для различения пяти букв и исследования возможности использования фазовой диаграммы или диаграммы мощности ЭЭГ в качестве признака в ИМК на основе ЭЭГ. Алгоритм контролируемого машинного обучения, LIBSVM, библиотека для классификаторов машины опорных векторов (SVM) (Chang and Lin, 2011), был использован и реализован в наборе инструментов MATLAB. Классификации были пятеричными с вероятностью 20 процентов, и результаты этих пятерных предсказаний оценивались электрод за электродом. Функция Гаусса использовалась в качестве функции нелинейного преобразования в классификаторе SVM, а ее критическая сигма параметра определялась с использованием подхода градиентного восхождения, который аналогичен алгоритму наискорейшего спуска, в котором параметр адаптивно настраивается в соответствии с изменениями в классификации. точность, чтобы гарантировать, что это может быть максимальным. Согласно предыдущим исследованиям (Schyns et al., 2011), ЭЭГ-ответы, вызванные зрительными стимулами, были наиболее информативны в затылочной и затылочно-височной коре. Поэтому основное внимание уделялось этим 17 электродным узлам: P7, P5, P3, P1, Pz, P2, P4, P6, P8, PO7, PO3, POz, PO4, PO8, O1, Oz и O2. Дополнительные методологические шаги, охватывающие вычислительную стратегию для проверки результатов классификации (перекрестная проверка и обучающие наборы с закрытыми метками), описаны ниже.
Подходы перекрестной проверки и обучающие наборы с перемешанными метками
Перекрестная проверка анализа многоклассовой классификации была проведена для получения надежных оценок точности различения и проверки способности нашего классификатора к обобщению. В этом исследовании был принят подход с 30-кратной перекрестной проверкой. Наборы сигналов ЭЭГ были случайным образом разделены на 30 частей, и 29 частей были выбраны для обучения SVM, который впоследствии использовался для проверки оставшегося набора для получения точности различения (Обратите внимание, что всего имеется 450 испытаний, соответствующих пяти буквам для одной буквы). 450 проб были разделены на 30 частей, каждая из которых содержит 15 проб на пять букв). Эту процедуру повторяли 30 раз, усредняя точность каждого повторения, чтобы получить окончательную точность. Чтобы исключить эффект искусственной классификации, вызванный принятием классификатора SVM, и оценить достоверность результата классификации, метки, указывающие букву для каждого испытания, были случайным образом перетасованы 100 раз, чтобы сформировать 100 случайных обучающих наборов меток. Для этих случайных обучающих наборов меток был использован многоклассовый классификационный анализ с 30-кратной перекрестной проверкой, и был получен ансамбль результатов обучения случайных меток. На каждом ходу случайным образом выбирался предмет и случайным образом перетасовывались метки букв. После этого мы выбрали самую высокую точность классификации по электродам. И затем мы проделали этот процесс сто раз. Это означает, что у нас было 100 случайных пометок точности. Мы назвали это ансамблем точности классификации со случайными метками. Для этого ансамбля был проведен тест Колмогорова-Смирнова (тест KS), чтобы определить, удовлетворяет ли ансамбль предполагаемому распределению, например, распределению нормы, и если да, то определить его среднее значение и дисперсию. Наконец, была рассчитана статистическая значимость ( p < 0,0013, стандарт трех сигм) на основе среднего значения и дисперсии этой измененной точности.
Для сравнения разницы в точности классификации между данными групп фазы и мощности 17 электродов с 12 субъектами мы выполнили двусторонний анова-анализ, а затем выполнили все попарные сравнения, используя метод множественного сравнения Тьюки-Крамера (в частности, мы сначала применили [ p,~,stats] = anova2(data,12) в Matlab Данные представляют собой матрицу 24 * 17, где первые 12 строк представляют собой значения точности мощности от 12 субъектов, а строки с 13 по 24 представляют собой значения фазовой точности от 12 субъектов. ; и 17 соответствует электродам 17. Затем мы выполнили множественное сравнение с помощью: C = multcompare(stats) в Matlab, по умолчанию используется метод Турции-Крамера). Метод множественных сравнений Тьюки-Крамера является одним из лучших методов для всех возможных попарных сравнений групповых средних, чтобы определить, какие из них существенно отличаются от других. Для значимого анализа результатов попарных сравнений была проведена процедура множественного сравнения.
Для ясного понимания процедуры анализа см. блок-схему на рисунке S2.
Результаты
Точность классификации для широкополосных последовательностей фаз и мощности ЭЭГ
Последовательности мощности и фазы составляли 1500 мс (начиная с -500 мс до появления «буквы» и заканчивая в конце «буквы») , а для анализа точности классификации был выбран короткий участок в 200 мс (начиная со 100-й мс после появления «буквы»). Причина, начинающаяся с момента 100-й мс, основана на следующем результате анализа.
Время появления «письма» установлено как 0-я мс. Используя это время 0-й мс в качестве отправной точки, мы выбрали последовательность временных окон различных размеров, чтобы проверить, где начинается кодирование ценной информации. Тестируемый период времени составляет от 0 до 600 мс с шагом по времени, равным 2 мс. Мы заметили, что точность классификации находится на уровне случайности для периода времени <100 мс, в то время как точность быстро возрастала до высокого значения 31% при увеличении периода времени до 200 мс, а затем колебалась, достигая уровня насыщения, когда время период был дополнительно увеличен до 600 мс (см. рисунок S1). Этот анализ предполагает, что последовательность ЭЭГ <100-й мс может не содержать ценной информации. Поэтому в дальнейшем значения точности классификации были получены путем обучения классификатора SVM с использованием 200-мс последовательностей мощности/фазы ЭЭГ, которые начинались на 100-й миллисекунде после предъявления буквы. Среднее значение и дисперсия точности классификации каждого из 17 электродов для всех 12 субъектов показаны на рисунке 2А (данные для оставшихся 2 субъектов без значительной мощности классификации показаны отдельно на рисунке S3). Наивысшая точность составила 46,61% (уровень вероятности 20%) для широкополосной (0,5–220 Гц) последовательности фаз ЭЭГ (рис. 2А). Последовательность фаз ЭЭГ в 17 электродах 12 субъектов (28,42 ± 3,21, среднее ± стандартное отклонение) показала значительно более высокие правильные показатели, чем последовательность мощности ЭЭГ (22,89).± 3,02, среднее значение ± стандартное отклонение) при доверительном уровне p < 10 -9 (двусторонний анализ ANOVA с коррекцией множественных сравнений Тьюки-Крамера, проведенный в MATLAB). Это означает, что часть фазы ЭЭГ содержит больше информации, чем часть мощности ЭЭГ. Процедура множественного сравнения была проведена для значимого анализа результатов попарных сравнений, и было обнаружено, что PO8 имеет значительно более высокую точность, чем P1, P2, P5, Pz (0,01 < P < 0,05), в то время как между любой парой значений точности не наблюдалось существенной разницы. другие электроды для чередования фаз. Доверительный интервал был определен с использованием дисперсии точности классификации полностью случайного перетасованного обучающего набора меток. На рисунке 2B показана нормальная диаграмма для результатов классификации обучающего набора случайных меток. Ось Y указывает логарифм кумулятивной функции плотности (CDF). Анализ линейной подгонки регрессии предполагает, что значения точности классификации <29% в основном из нормального распределения (тест KS p = 0,038). Среднее значение составило 23,81%, а дисперсия — 1,76%; таким образом, уровень трех сигм составил 29,09%. Это значение было установлено как доверительный интервал с односторонним доверительным уровнем P = 0,0013 (см. красную пунктирную линию на рисунке 2А). Мы заметили, что 12 из 14 испытуемых, прошедших 450 тестов, имели значительную классификационную способность выше уровня трех сигм с точностью 29,09% по крайней мере для одного электрода; кроме того, у 8 испытуемых было три электрода, а у семи испытуемых было пять мощных электродов, которые показали значительную мощность классификации> 29.0,09%. Мы также провели анализ декодирования фазы и мощности данных от 2 субъектов, у которых не было данных электродов со значительными классификационными эффектами (см. Рисунок S3). Наивысшая точность для этих испытуемых составила всего 29% для фазовой классификации (рис. S3A, B) и 27% для классификации мощности (рис. S3C). Среднее значение точности фазового декодирования для всех 17 электродов у 12 испытуемых составило 28,42 ± 3,21 (среднее ± стандартное отклонение) и 27,71 ± 3,45 у всех 14 испытуемых. Следовательно, следующий анализ результатов был в основном основан на 12 субъектах. Анализ двух субъектов без значительных эффектов показан отдельно на рисунках S3, S4.
Рисунок 2 . Результаты классификации и топография точности. (A) Средняя точность классификации по 12 субъектам на 17 электродах. Полоса ошибок указывает верхний и нижний пределы точности. Показатели фазы и мощности ЭЭГ представлены фиолетовым и зеленым цветом соответственно. Красная пунктирная линия представляет уровень на три сигмы выше уровня вероятности. (B) Рисунок Normplot для результатов классификации обучающего набора случайных меток. Ось Y указывает логарифм кумулятивной функции плотности (CDF). Если набор выборок происходит из нормального распределения, он будет линейным. (C) Точность топографии мощности ЭЭГ. Маленькие черные точки обозначают электроды. Точные скорости на других участках были определены с использованием функции интерполяции MATLAB Triangle. (D) Точность топографии фазовой части ЭЭГ.
Как показано на рисунках 2C,D для усредненного спектра 12 субъектов, имеющих как минимум 1 электрод со значительной мощностью классификации, относительно высокая точность классификации проявилась при размещении электродов в левой и правой задних областях.
Различные частотные диапазоны ЭЭГ и результаты классификации по конкретным периодам
Для изучения критического периода для классификации было применено сдвиговое окно длиной 200 мс (от −100 до 500 мс, 40 мс на шаг) к мощности, отфильтрованной по частоте. и поэтапные временные курсы для извлечения обучающих и тестовых наборов. Мы наблюдали, что точность различения в первые 100 мс после предъявления буквы всегда примерно равна случайности, а большая часть ценной декодируемой информации приходится на первые полсекунды (100–600 мс) после предъявления стимулов. (см. рис. 3, 4). Следовательно, наш анализ показал, что начало с отметки 100 миллисекунд после предъявления буквы может привести к более высокой мощности классификации, чем анализ, начиная с 0 мс после предъявления буквы (van Gerven et al. , 2013; Watrous et al. , 2015).
Рисунок 3 . Диаграмма значимости частотно-временной классификации и сравнение диапазонов. (A) Значение классификации для фазовой части ЭЭГ в разных диапазонах и периодах времени. для 12 субъектов, показанных на рисунке 2. Каждый небольшой блок представляет собой тренировочный набор 200 мс. Для определенного диапазона и периода времени выбирали самую высокую точность среди всех 17 электродов и рассчитывали соответствующее значение P . Метки X указывают среднюю точку каждого периода от 0 до 600 мс. (B) Сравнение эффективности классификации фазовой части ЭЭГ для всех диапазонов за выбранный оптимальный период времени. Одна звездочка соответствует уровню значимости P < 0,05 для двух связанных полос, а три звездочки соответствуют P < 0,001. (C) Значимость классификации для части мощности ЭЭГ в разных диапазонах и периодах времени. (D) Сравнение эффективности классификации части мощности ЭЭГ всех диапазонов.
Рисунок 4 . Точность топографии временных рядов. Для построения графика были выбраны три специальных набора: тета-мощность ЭЭГ, тета-фаза и альфа-фаза, поскольку они имели значительно более сильную классификационную способность, чем другие. Сигналы тета-фазы ЭЭГ явно имели наилучшие характеристики с длительной классификационной мощностью, большей полезной площадью и наивысшей степенью точности.
Процессы обучения и классификации были применены к этим частотно-временным фазовым сигналам и наборам мощности для расчета средней точности по 12 субъектам, у которых мы получили значимые результаты на предыдущем этапе анализа. Была получена 2-мерная матрица точности с отметками X, представляющими средний момент времени каждого окна сдвига, и отметками Y, представляющими все шесть полос. Точность классификации была преобразована в их P – представление значений. Значение P было рассчитано как вероятность того, что степень точности частотно-фильтрованной мощности и фазового временного хода может быть получена из нормального распределения, которое мы получили из перетасованных обучающих наборов меток. Для более высокой степени точности будет получено меньшее значение P . Был рассчитан десятичный логарифм 1/P, который был выбран в качестве представления эффективности классификации для целей иллюстрации. Затем мы сравнили производительность каждой полосы частот. Мы выбрали лучший временной блок для каждой группы. На рисунках 3A,C показана расчетная значимость классификации как функция времени для шести полос. С помощью расчета был выбран наиболее эффективный временной блок на основе наивысшего уровня значимости классификации для каждой полосы частот, и для того же временного блока было получено соответствующее значение точности. Затем мы применили набор инструментов MATLAB ANOVA, чтобы проверить, имеют ли сигналы этих шести полос существенно разные характеристики классификации. Фрагменты фазового сигнала ЭЭГ и сигнала мощности обрабатывались отдельно.
Также была изучена информация о фазе и мощности в различных частотах колебательного диапазона ЭЭГ, которые вносят вклад в классификацию. На рисунке 3A показаны результаты расчета значимости классификации на основе фазового сигнала ЭЭГ, а на рисунке 3B показана количественная оценка его эффективности классификации для 12 субъектов, которые имели значительную классификационную способность (данные для оставшихся 2 субъектов без значительной способности классификации являются показано на рисунке S4). Отметки X представляют среднюю точку времени каждого смещающегося окна длиной 200 мс, которое начиналось с 0 мс и заканчивалось с 600 мс. Как показано на рисунке 3A, чем выше значение логарифма, тем выше уровень точности, который он представляет. Мы также рассчитали значимость классификации и значения производительности на основе информации о мощности ЭЭГ (рис. 3C). Как для мощности ЭЭГ, так и для характеристик фазового кодирования полоса тета-частот показала более высокую эффективность классификации, чем остальные пять полос, а критический период времени начался с 60–580 мс (со средней временной точкой 160–480 мс). . Мы обнаружили, что для тета-диапазона фазовая часть и мощность не имеют существенной разницы (MATLAB ttest2, Р = 0,89). Находясь в альфа-диапазоне, последовательность фаз имела значительно более высокую точность, чем ее аналог мощности (ttest2, P = 0,0341). Также бета-диапазон работал иначе ( P <0,001).
Как для тета-, так и для альфа-диапазонов уровни значимости и производительности обычно относительно ниже при кодировании мощности, чем при кодировании фазы (рис. 3C). Наибольшая точность проявлялась в период от 220 до 420 мс для фазового кодирования в тета-диапазоне и от 180 до 380 мс для альфа-диапазона.
На рисунках 3B,D показана рассчитанная точность классификации для различных частотных диапазонов на основе колебательной фазы ЭЭГ и компонентов мощности. Ритмические частоты ЭЭГ существенно влияли на точность классификации [ F (5,96) = 22,64, P < 10 -6 MATLAB ANOVA1]. На рисунке 3B показано, что для фазового кодирования ЭЭГ не было существенной разницы в классификации между тета (36,70 ± 4,43, среднее ± стандартное отклонение) и альфа-диапазоном (35,4 ± 4,21), но была значительная разница между альфа (35,40 ± 4,21). 4,21) и бета-полосы (30,74 ± 4,32) ( p = 0,0037, ANOVA1) для 12 субъектов. Рисунок 3D показывает, что для кодирования мощности точность тета-диапазона ЭЭГ (35,08 ± 5,32) была значительно выше, чем точность альфа-диапазона (31,67 ± 4,29), и что точность альфа-диапазона была значительно выше, чем у других четырех частотных диапазонов. Остальные четыре полосы не показали значительного эффекта классификации. Кроме того, если анализ данных включает двух незначимых субъектов, значение точности фазового декодирования для тета-диапазона для всех 14 субъектов составило 35,50 ± 5,08, что было немного ниже результата 36,70 ± 4,43 для 12 субъектов.
Карта топологии точности для данных временного окна сдвига
Основываясь на наших текущих методах декодирования, мы хотели бы исследовать пространственно-временное распределение значений точности классификации. Здесь мы сосредоточимся на альфа- и тета-диапазонах, потому что они показали значительно высокую точность классификации (рис. 3B, D). Значения точности от 12 субъектов были усреднены и представлены в цвете (см. Рисунок 4). На рис. 4 показана карта точности классификации, полученная на основе информации о фазе и мощности в альфа- и тета-диапазонах для 17 электродов в зависимости от времени.
В отличие от результатов, показанных на рис. 2D, не было высокой точности латерализации для электродов правого полушария, только немного более длительная мощность классификации (например, фазовый сигнал альфа-диапазона от 260 до 460 мс и фазовый сигнал тета-диапазона от 300 до 500 мс). РС). Классификационная способность электрода PO7 уменьшилась, но осталась в электроде PO8). Интересно, что электроды O1, O2 и O3 также показали очень высокие показатели точности, как и PO7 и PO8 в фазовом сигнале тета-диапазона, но показали низкие значения в альфа-диапазоне. Это различие подразумевает, что тета- и альфа-сигналы могут играть разные роли в распознавании и иметь разное происхождение (Fries, 2015).
Мощность классификации во всех 17 электродах явно исчезла через 380 мс, а точность снизилась до уровня случайности. Поэтому остальные топографические карты не показаны.
Обсуждение
Сравнение с существующими методами BCI и другими исследованиями фазового кодирования
Это исследование показало, что фазовые паттерны и мощность в тета- и альфа-диапазонах могут содержать ценную информацию о характеристиках входного стимула. Этот ценный подход временного фазового кодирования был подтвержден заключением, согласующимся с самыми последними исследованиями декодирования других визуальных и слуховых сигналов в множественных поведенческих и когнитивных задачах (Luo and Poeppel, 2007; Schyns et al., 2011; Vanrullen et al., 2011). ; Wang et al., 2012; ten Oever and Sack, 2015). Кроме того, декодирование последовательностей фаз и мощностей в разных полосах частот предполагает разную мощность классификации. Расшифровка фазовых моделей в тета- и альфа-колебаниях обеспечивала относительно более высокую точность распознавания, чем в дельта-, бета- и гамма-колебаниях. Предыдущие исследования предполагали, что вентральная затылочно-височная кора (vOT) участвует в восприятии визуально представленных объектов и письменных слов (Dahaene, 19). 95; Прайс и Девлин, 2011 г.; Мацуо и др., 2015). Наш анализ декодирования показал более высокую мощность классификации для электродов, размещенных в затылочно-височных областях, по сравнению с другими областями, хотя мы должны иметь в виду, что электроды ЭЭГ не обязательно улавливают активность непосредственно под электродами. Эти результаты предоставляют больше доказательств в поддержку фазового кодирования ЭЭГ при зрительном восприятии. В этом процессе пространственно распределенные электроды могут кодировать различные предпочтительные признаки стимула.
Используемый здесь метод не является таким общим, как классические существующие методы BCI, такие как SSVEP и P300 (Zhang et al., 2013; Nezamfar et al., 2016). Он также зависит от обучения классификатора SVM. Традиционный подход BCI часто проводит процесс декодирования в режиме реального времени. В нашем подходе мы сначала собрали достаточное количество данных ответа ЭЭГ на вводимые стимулы, а затем выполнили процессы обучения и декодирования. В будущих исследованиях мы ожидаем, что более высокая скорость компьютеров и улучшенные алгоритмы позволят использовать этот подход к декодированию в режиме реального времени. Кроме того, по сравнению с существующими подходами BCI, наш подход больше зависит от субъектов. Показатели сильно различались между субъектами, как и в подходе ERD / ERS. Это означает, что мы можем обучить субъекта в будущих исследованиях, чтобы улучшить эффективность классификации, как в некоторых исследованиях ERD / ERS.
Несмотря на то, что несколько исследований посвящены фазовому декодированию ЭЭГ, и его производительность недостаточна, чтобы привлечь больше внимания, метод фазового декодирования показал многообещающие перспективы для декодирования активности человеческого мозга с использованием массового электромагнитного поля. Как недавно было предложено (Panzeri et al., 2015, 2016), этот новый метод и другие родственные методы могут широко использоваться для улучшения ИМТ, а его эффективность может быть дополнительно улучшена за счет более сложных конструкций.
Наши экспериментальные результаты согласуются с предыдущим исследованием декодирования, связанным с экспериментом по различению эмоциональных лиц на ЭЭГ (Schyns et al., 2011). Были получены практически аналогичные пространственно расположенные электроды в диапазоне тета-частот и аналогичное критическое временное окно. Это может указывать на аналогичный корковый путь, участвующий в процессе визуализации букв алфавита и человеческих лиц. Это сходство также проявилось в записи фМРТ человека (Dehaene and Cohen, 2011). Однако, в отличие от процесса распознавания лиц, наши экспериментальные результаты могут включать эффект слухового кодирования в дополнение к процессу визуализации. Участников попросили сидеть спокойно, не произнося буквы, однако они могли читать визуализированные буквы с воображаемым произношением во время задания на визуализацию букв алфавита. Продолжительность и интенсивность звука воображаемого произношения могут быть связаны с возникновением тета-осцилляций ЭЭГ в височной коре (Luo and Poeppel, 2007; Howard and Poeppel, 2010; Wang et al. , 2012; Ng et al., 2013; ten Oever and Sack). , 2015) и повышение психоакустической чувствительности (Goswami et al., 2011). Необходимо провести дополнительные эксперименты, чтобы определить, какая часть декодированной информации получена исключительно из процесса визуализации, а какая — из воображаемого речевого процесса. В отличие от метода Schyns et al. (2011), мы обучили SVM выполнять классификацию. Достоинством этого подхода является то, что он может иметь потенциальное применение в ИМК, хотя настоящий метод не может различить, как и в какой степени характеристики стимулов кодируются в фазовых паттернах колебаний ЭЭГ, которые могут быть ограничены пространственным и временным разрешением сигналы ЭЭГ. Поскольку SVM и другие методы машинного обучения представляют собой своего рода черный ящик, в будущих исследованиях необходимо использовать более подробные аналитические методы и экспериментальные планы, чтобы изучить потенциальную ценность и ограничения этого подхода.
Вопрос о том, как низкочастотные колебательные фазы представляют информацию в зрительном восприятии, остается открытым. При восприятии звука данные указывают на то, что тета-колебания имитируют огибающую входной речи (Giraud and Poeppel, 2012; Gross et al., 2014). В этом случае пик (нулевая фаза) колебания может представлять высокую амплитуду огибающей речи, а впадина (фаза π) связана с тишиной.
Кроме того, недавние исследования показали, что различные нейронные колебания не являются преднамеренными и изолированными (Canolty et al., 2006). Они могут взаимодействовать друг с другом, модулируя амплитуду и фазу колебаний, что приводит к эффекту межчастотной связи. Кросс-частотная связь может включать в себя несколько взаимодействий, таких как фазовая синхронизация, амплитудная комодуляция и фазово-амплитудная связь (PAC). Считается, что PAC отражает нейронное кодирование сигналов в локальных микро- и макромасштабных сетях мозга (Canolty and Knight, 2010). Появляется все больше экспериментальных данных, свидетельствующих о том, что PAC может предоставить более полезную информацию для расшифровки категорий объектов (Watrous et al. , 2015; Jafakesh et al., 2016), которые необходимо будет глубоко изучить в будущем, когда будут получены высококачественные данные ЭЭГ или ЭКоГ. запись доступна.
Заключение
Результаты наших экспериментов убедительно подтверждают, что информация о частоте, фазе и мощности параметров корковых колебаний содержит важную информацию о свойствах стимула. Во-первых, мы обнаружили, что декодирование фазовых паттернов ЭЭГ дает более высокие значения точности различения, чем декодирование части мощности ЭЭГ. Во-вторых, частотный диапазон и корковое пространственное положение имеют решающее значение для декодирования. Мы заметили, что фазовые паттерны тета- и альфа-ритмов, зарегистрированные в зрительной и височной областях затылочной части головы, содержат более богатую информацию, которая ценна для декодирования различных входных зрительных стимулов, по сравнению с другими областями. Последовательности мощности ЭЭГ в тета-колебаниях показали значительно более высокую скорость различения, чем случайный уровень, хотя его эффективность классификации была немного ниже, чем фазовый паттерн ЭЭГ. Декодирование фазы ЭЭГ и последовательности мощности в гораздо более низкочастотном дельта-диапазоне или гораздо более высоких бета- и гамма-диапазонах частот не приводит к значительным показателям различения. В-третьих, важно время. Большая часть ценной декодируемой информации находится в течение первого полусекундного периода (100–600 мс) после предъявления стимулов, и эта информация практически не улавливается методом функциональной магнитно-резонансной томографии (с временным разрешением около 1 с).
Таким образом, наши экспериментальные результаты подтверждают, что низкочастотные корковые колебания активно участвуют в кодировании сенсорной информации. Непосредственное декодирование последовательностей фазы и мощности сигналов ЭЭГ в тета-диапазоне может иметь большой потенциал в приложениях интерфейса мозг-компьютер для распознавания букв английского алфавита. Хотя настоящее исследование ЭЭГ показало, что электроды, расположенные в зрительной и височной областях затылочной части черепа, имеют более высокие показатели точности и всегда достигают пика первыми, будущие исследования с комбинированными экспериментами ЭЭГ и функциональной МРТ могут обеспечить лучшее пространственное разрешение при различении точных корковых положений в зрительных областях. сайты, кодирующие стимул.
Вклад авторов
YY, PW и YW разработали исследование, YY и YW провели исследование, а YW и YY написали статью. Все авторы рассмотрели рукопись.
Заявление о конфликте интересов
Авторы заявляют, что исследование проводилось при отсутствии каких-либо коммерческих или финансовых отношений, которые могли бы быть истолкованы как потенциальный конфликт интересов.
Благодарности
Мы благодарны доктору Ин Мао и Лян Чену за их большую помощь в обсуждениях и экспериментальном протоколе. YY благодарит за поддержку Национальный фонд естественных наук Китая (31571070, 81761128011), поддержку Шанхайского комитета по науке и технологиям (16410722600), программу профессора специального назначения (Eastern Scholar SHh2140004) в Шанхайских высших учебных заведениях, Исследовательский фонд для докторской программы высшего образования Китая (1322051) и прецизионной медицины эпилепсии на основе Omics, порученной ключевому исследовательскому проекту Министерства науки и технологий Китая (грант № 2016YFC09). 04400) за их поддержку.
Дополнительный материал
Дополнительный материал к этой статье можно найти в Интернете по адресу: https://www.frontiersin.org/articles/10.3389/fnins.2018.00062/full#supplementary-material
Ссылки
, Busch, N.A. Дюбуа, Дж., и Ванруллен, Р. (2009). Фаза продолжающихся колебаний ЭЭГ предсказывает зрительное восприятие. J. Neurosci. 29, 7869–7876. doi: 10.1523/JNEUROSCI.0113-09.2009
PubMed Abstract | Полный текст перекрестной ссылки | Академия Google
Канолти, Р. Т., Эдвардс, Э., Далал, С. С., Солтани, М., Нагараджан, С. С., Кирш, Х. Э., и др. (2006). Высокая мощность гамма-излучения синхронизирована по фазе с тета-колебаниями в неокортексе человека. Наука 313, 1626–1628. doi: 10.1126/science.1128115
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Канолти, Р. Т., и Найт, Р. Т. (2010). Функциональная роль кросс-частотной связи. Познание тенденций. науч. 14, 506–515. doi: 10.1016/j.tics.2010.09.001
Реферат PubMed | Полный текст перекрестной ссылки | Google Scholar
Chang C.-C. и Lin C.-J. (2011). LIBSVM: библиотека для машин опорных векторов. ACM Trans. Интел. Сист. Технол. 2, 1–27. doi: 10.1145/1961189.1961199
CrossRef Full Text
Colgin, L.L., Denninger, T., Fyhn, M., Hafting, T., Bonnevie, T., Jensen, O., et al. (2009). Частота гамма-колебаний направляет поток информации в гиппокамп. Природа . 462, 353–357. doi: 10.1038/nature08573
Реферат PubMed | Полный текст перекрестной ссылки | Google Scholar
Дахаэне С. (1995). Электрофизиологические данные об обработке текстов, специфичных для категорий, в нормальном человеческом мозгу. Нейронный отчет . 6, 2153–2157. doi: 10.1097/00001756-199511000-00014
Полный текст CrossRef | Google Scholar
Дехане С. и Коэн Л. (2011). Уникальная роль зрительной области словоформы в чтении. Познание тенденций. науч. (Регул. Ред.). 15, 254–262. doi: 10.1016/j.tics.2011.04.003
Реферат PubMed | Полный текст перекрестной ссылки | Google Scholar
Делорм А. и Макейг С. (2004). EEGLAB: набор инструментов с открытым исходным кодом для анализа динамики ЭЭГ в одной попытке, включая анализ независимых компонентов. J. Neurosci. Методы 134, 9–21. doi: 10.1016/j.jneumeth.2003.10.009
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Энгель А.К., Фрайс П. и Сингер В. (2001). Динамические прогнозы: колебания и синхронность в нисходящей обработке. Нац. Преподобный Нейроски. 2, 704–716. doi: 10.1038/35094565
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Фрайс, П. (2015). Ритмы для познания: общение через когерентность. Нейрон 88, 220–235. doi: 10.1016/j.neuron.2015.09.034
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Фрайс П., Николич Д. и Сингер В. (2007). Гамма-цикл. Trends Neurosci. 30, 309–316. doi: 10.1016/j.tins.2007.05.005
Реферат PubMed | Полный текст перекрестной ссылки | Google Scholar
Жиро, А.-Л., и Поппель, Д. (2012). Корковые колебания и обработка речи: новые вычислительные принципы и операции. Nat Neurosci. 15, 511–517. doi: 10.1038/nn.3063
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Госвами У., Ван Х.-Л. С., Круз А., Фоскер Т., Мид Н. и Хасс М. (2011). Универсальный языковой сенсорный дефицит при дислексии развития: английский, испанский и китайский языки. Дж. Когн. Неврологи. 23, 325–337. doi: 10.1162/jocn.2010.21453
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Гросс Дж., Хугенбум Н., Тут Г., Шинс П., Панцери С., Белин П. и др. (2014). Речевые ритмы и мультиплексное колебательное сенсорное кодирование в мозге человека. PLoS Биол. 11:e1001752. doi: 10.1371/journal.pbio.1001752
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Heusser, A. C., Poeppel, D., Ezzyat, Y., and Davachi, L. (2016). Память эпизодической последовательности поддерживается фазовым тета-гамма-кодом. Нац. Неврологи. 19, 1374–1380. doi: 10.1038/nn.4374
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Ховард, М. Ф., и Поппель, Д. (2010). Распознавание речевых стимулов на основе паттернов фазы реакции нейронов зависит от акустики, но не от понимания. Дж. Нейрофизиол. 104, 2500–2511. doi: 10.1152/jn.00251.2010
CrossRef Полный текст | Google Scholar
Иеми Л., Шомон М., Крузе С. М. и Буш Н. А. (2017). Спонтанные нейронные колебания искажают восприятие, модулируя базовую возбудимость. Дж. Неврологи. 37, 807–819. doi: 10.1523/JNEUROSCI.1432-16.2016
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Джафакеш С., Джахроми Ф. З. и Далири М. Р. (2016). Декодирование категорий объектов из сигналов мозга с использованием методов перекрестной связи частот. Биомед. Сигнальный процесс. Контроль 27, 60–67. doi: 10.1016/j.bspc.2016.01.013
CrossRef Full Text | Google Scholar
Кахана, М. Дж., Силиг, Д., и Мэдсен, Дж. Р. (2001). Тета возвращается. Курс. мнение Нейробиол . 11, 739–744. doi: 10.1016/S0959-4388(01)00278-1
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Климеш, В. (1999). Альфа- и тета-колебания ЭЭГ отражают когнитивные функции и память: обзор и анализ. Мозг Res. Мозг Res. Ред. 29, 169–195. doi: 10.1016/S0165-0173(98)00056-3
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Крюгер Н., Янссен П., Калкан С., Лаппе М., Леонардис А., Пиатер Дж. и др. (2013). Глубокие иерархии в зрительной коре приматов: что мы можем узнать о компьютерном зрении? IEEE Trans. Анальный узор. Мах. Интел. 35, 1847–1871 гг. doi: 10.1109/TPAMI.2012.272
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Lange, J. , Oostenveld, R., and Fries, P. (2013). Снижение индексов мощности затылочных альфа-каналов повышает возбудимость, а не улучшает зрительное восприятие. J. Neurosci. 33, 3212–3220. doi: 10.1523/JNEUROSCI.3755-12.2013
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Лисман Дж. Э. и Идиарт М. А. (1995). Хранение 7 +/- 2 кратковременных воспоминаний в колебательных субциклах. Наука 267, 1512–1515. doi: 10.1126/science.7878473
Полный текст CrossRef | Google Scholar
Луо Х. и Поппель Д. (2007). Фазовые паттерны нейронных ответов надежно различают речь в слуховой коре человека. Нейрон 54, 1001–1010. doi: 10.1016/j.neuron.2007.06.004
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Мацуо Т., Кавасаки К., Каваи К., Маджима К., Масуда Х., Мураками Х. и др. (2015). Чередующиеся зоны, селективные к лицам и написанным словам, в вентральной затылочно-височной коре человека. Кора головного мозга 25, 1265–1277. doi: 10.1093/cercor/bht319
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Незамфар Х., Салехи С.С.М., Могхадамфалахи М. и Эрдогмус Д. (2016). FlashType™: контекстно-зависимый интерфейс типирования BCI на основе c-VEP с использованием сигналов ЭЭГ. IEEE J. Сел. Верхний. Сигнальный процесс. 10, 932–941. doi: 10.1109/JSTSP.2016.2552140
CrossRef Полный текст | Google Scholar
Нг, Б.С., Логотетис, Н.К., и Кайзер, К. (2013). Фазовые паттерны ЭЭГ отражают избирательность возбуждения нейронов. Кора головного мозга 23, 389–398. doi: 10.1093/cercor/bhs031
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Oldfield, RC (1971). Оценка и анализ хиральности: Эдинбургская инвентаризация. Нейропсихология 9, 97–113. doi: 10.1016/0028-3932(71)-4
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Panzeri, S., Macke, JH, Gross, J. и Kayser, C. (2015). Кодирование нейронной популяции: объединение информации из микроскопических и массовых сигналов. Познание тенденций. науч. 19, 162–172. doi: 10.1016/j.tics.2015.01.002
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Панцери С., Сафааи Х., Де Фео В. и Вато А. (2016). Последствия зависимости нейронной активности от состояний нейронной сети для проектирования интерфейсов мозг-машина. Фронт. Неврологи. 10:165. doi: 10.3389/fnins.2016.00165
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Price, CJ, and Devlin, JT (2011). Интерактивный отчет о вентральных затылочно-височных вкладах в чтение. Познание тенденций. науч. 15, 246–253. doi: 10.1016/j.tics.2011.04.001
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Schyns, P.G., Thut, G., and Gross, J. (2011). Взлом кода колебательной активности. PLoS Биол. 9:e1001064. doi: 10.1371/journal.pbio.1001064
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Сигель М. , Уорден М. Р. и Миллер Э. К. (2009). Фазозависимое нейронное кодирование объектов в кратковременной памяти. Проц. Натл. акад. науч. США 106, 21341–21346. doi: 10.1073/pnas.0
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Танака, К. (1996). Нижневисочная кора и предметное зрение. год. Преподобный Нейроски. 19, 109–139. doi: 10.1146/annurev.ne.19.030196.000545
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
тен Овер С. и Сак А. Т. (2015). Колебательная фаза формирует восприятие слога. Проц. Натл. акад. науч. США 112, 15833–15837. doi: 10.1073/pnas.1517519112
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Томассини А., Амбродиони Л., Медендорп В. П. и Марис Э. (2017). Тета-колебания, привязанные к намеченным действиям, ритмично модулируют восприятие. eLife 6:e25618. doi: 10.7554/eLife.25618
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Ван Дейк Х. , Шоффелен Дж. М., Остенвельд Р. и Дженсен О. (2008). Предстимульная колебательная активность в альфа-диапазоне предсказывает способность к зрительному различению. Дж. Неврологи. 28, 1816–1823 гг. doi: 10.1523/JNEUROSCI.1853-07.2008
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Ван Гервен М. А., Марис Э., Сперлинг М., Шаран А., Литт Б., Андерсон К. и др. (2013). Расшифровка запоминания отдельных стимулов с прямыми записями человеческого мозга. Нейроизображение 70, 223–232. doi: 10.1016/j.neuroimage.2012.12.059
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Ванруллен Р., Буш Н. А., Древес Дж. и Дюбуа Дж. (2011). Текущая фаза ЭЭГ как предиктор изменчивости восприятия и внимания. Фронт. Психол. 2:60. doi: 10.3389/fpsyg.2011.00060
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
VanRullen, R., and Macdonald, JSP (2012). Перцептивные эхо на частоте 10 Гц в человеческом мозгу. Курс. биол. 22, 995–999. doi: 10.1016/j.cub.2012.03.050
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Ван Р., Перро-Гимарайнш М., Карвальяш К. и Суппес П. (2012). Использование фазы для распознавания английских фонем и их отличительных особенностей в мозгу. Проц. Натл. акад. науч. США 109, 20685–20690. doi: 10.1073/pnas.1217500109
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Уотроус, А. Дж., Дойкер, Л., Фелл, Дж., и Аксмахер, Н. (2015). Связь фазы с амплитудой поддерживает фазовое кодирование в ЭКоГ человека. eLife 4:e07886. doi: 10.7554/eLife.07886
Полный текст CrossRef | Google Scholar
Вон Д.-О., Чжан Х.Х., Гуань С. и Ли С.-В. (2014). «Программа правописания BCI на основе SSVEP с использованием дизайна высокочастотных стимулов», в Международная конференция IEEE по системам, человеку и кибернетике (SMC), 2014 г., (Сан-Диего, Калифорния: IEEE), 1068–1071. doi: 10.1109/SMC.2014.6974055
CrossRef Полный текст | Google Scholar
Уорден М.С., Фокс Дж.Дж., Ван Н. и Симпсон Г.В. (2000). Упреждающее смещение зрительно-пространственного внимания, индексируемое с помощью ретинотопически специфической электроэнцефалографии α-банка, увеличивается в затылочной коре. J. Neurosci. 20:RC63.
Google Scholar
Чжан Д., Сун Х., Сюй Р., Чжоу В., Линг З. и Хун Б. (2013). На пути к минимально инвазивному интерфейсу мозг-компьютер с использованием одного субдурального канала: исследование визуального правописания. Нейроизображение 71, 30–41. doi: 10.1016/j.neuroimage.2012.12.069
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Раньше в нашем алфавите было еще шесть букв!
Вы думали, что знаете азбуку, но раньше в нашем алфавите было 32 буквы вместо 26. Вот что случилось с этими шестью потерянными буквами.
1 / 7
Татьяна Аязо/Rd. com
Как бы странно это ни звучало, но за последние несколько сотен лет в английском алфавите было на несколько букв больше, чем сегодня. Если быть точным, еще шесть, включая Этель и Йога (да, это были настоящие названия звука «ой», как в «монете», и звука «кх», как в «Лохнесском чудовище» соответственно). Эксперты-лингвисты говорят, что в их утрате виновата современная упорядоченность и смешение культур Северной Европы.
«Некоторые прежние буквы имели значение, поскольку Eth и Ash до сих пор используются как часть фонематической таблицы, используемой для произношения, — говорит профессор ESL Аликс Хёхстер, — но не ожидайте увидеть их на клавиатуре или использовать их в повседневной жизни». – в повседневную жизнь». Это потому, что они, как правило, постепенно упраздняются и заменяются буквами, которые выполняют двойную функцию: либо уже обращаясь к рассматриваемым звукам, либо создавая желаемые звуки в сочетании с другими стандартными существующими буквами. Вот почему буквы на вашей клавиатуре расположены не в алфавитном порядке.
Энн Бэбсон, преподаватель английского языка в Университете Юго-Восточной Луизианы, изучавшая позднесредневековые европейские языки, объясняет, что буквы, которые мы больше не видим, постепенно выходили из употребления по мере того, как печатные станки разрабатывали систему набора текста. «Сначала Eth и Thorn были заменены на «Y» в некоторых шрифтах и вывесках, поэтому современные читатели произносили бы «Ye Olde English Shoppe» как «Староанглийский магазин», — говорит она. Увлекательная штука, правда? И это не ограничивается простой рекламой.
К середине 1600-х годов звук «th» почти всегда представлялся типографски, как и сегодня. Но вкратце, английский язык содержал типографскую букву под названием «длинная s» примерно со времен позднего Возрождения до начала 1800-х годов — она выглядела почти как буква «f», но произносилась просто как «s». «Вот почему у нас есть фронтиспис для публикации «Потерянный рай » в 1600-х годах, который выглядит как «Потерянный рай, », — говорит Бэбсон.
Если вам интересно, будет ли наш нынешний алфавит продолжать сокращаться, Бэбсон полагает, что в ближайшее время нет причин беспокоиться об этом. «Стандартное правописание делает это менее вероятным, чем когда среднеанглийский язык превращался в современный английский», — говорит она. «Большинство наших учителей английского языка в старших классах перевернулись бы в гробу, если бы слово «быстро» навсегда превратилось в слово «быстро». При этом не исключено, что мы упростим орфографию многих слов так, как это сделало «драйв-сквозь».
Если вас интересуют письма, которые мы потеряли, вы можете вылить одно из них сегодня вечером:
2 / 7
Татьяна Аязо/Rd.com
Eth (ð)
В своей первоначальной форме eth произносился как th в словах типа th is, th at или th e, или th en.
3 / 7
Татьяна Аязо/Rd.com
Thorn (þ)
Thorn также произносится с цифрой -й звучит как , но в более мягкой манере. Представьте, что звук -й используется как можно менее агрессивно, и он плавно вылетает из-под ваших зубов. Это удивительная история того, почему алфавит находится в том порядке, в котором он есть.
4 / 7
Татьяна Аязо/Rd.com
Wynn (ƿ)
Это был предшественник сегодняшнего uu; он потерял популярность, когда писатели и печатники начали смешивать две более модные буквы u вместе.
5 / 7
Татьяна Аязо/Rd.com
Yogh (ȝ)
Мы можем поблагодарить шотландцев за то, что это письмо существовало, хотя и недолго. Подумайте о звуке ch в слове «Лохнесское чудовище» или о том, как вы произносите ch в слове «хлеб халы». Последняя буква, добавленная в алфавит, на самом деле не была «Z».
6 / 7
Татьяна Аязо/Rd.com
Ясень (æ)
Срочные новости: эта буква до сих пор используется в современном датском языке. Если вы хотите повеселиться с этим антиквариатом, отправляйтесь прямо в Данию. В противном случае, просто знайте, что это был короткий гласный звук в староанглийском языке, как странное дитя любви из короткого а и короткого е, например, когда вы не можете сказать, сказал кто-то «pat» или «pet».
Первоначально опубликовано: 11 сентября 2018 г.
Брайс Грубер
В качестве главного редактора Брайс Грубер является экспертом по идеям подарков, покупкам и электронной коммерции в Ридерз Дайджест. Вы, вероятно, видели ее работу в различных изданиях о женском образе жизни и воспитании детей, а также в телешоу. Она живет и работает в долине реки Гудзон в Нью-Йорке со своими пятью маленькими детьми.
Английский алфавит • ICAL TEFL
Английский алфавит состоит из 26 букв. Их можно разделить на гласные и согласные.
Гласные: a,e,i,o,u
Согласные: b,c,d,f,g,h,j,k,l,m,n,p,q, r,s,t,v,w,x,y,z
В каждом слове есть хотя бы один гласный звук. Однако, когда мы пишем их, в некоторых словах нет ни одной из вышеперечисленных гласных, например:
летать, гимн, почему
Хотя в этих словах есть гласный звук, в них используется согласная буква и вместо гласной.
Очень немногие слова содержат все пять гласных в алфавитном порядке:
шутливый, воздержанный
Звуки и буквы
Хотя в алфавите 26 букв, существует примерно 40 различных звуков. Это означает, что в английском языке разные буквы часто имеют разные звуки, и, аналогично, иногда один и тот же звук обозначается разными буквами:
Подумайте о звуке /k/ в падеже и о том же звуке в 9.1113 Кейт .
Подумайте о различном произношении буквы c как в торт и милое .
Alphabet Case
The English alphabet is a bicameral , that is it has upper case (or capitals ):
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
and lower case :
a b c d e f g h i j k l m n o p q r s t u v w x y z
Etymologies
Слово алфавит происходит от альфа и бета , первых двух букв греческого алфавита. Они, в свою очередь, происходят от первых двух букв финикийского алфавита, где они означают ox и house соответственно.
Итак, алфавит на самом деле означает воловий дом .
Слово гласный происходит от латинского слова vowis , означающего голос ; слово согласная 9Число 1114 происходит от латинского слова consonare , означающего, что звучат вместе как .
Откуда взялся английский алфавит?
Хотя история английского алфавита точно не известна, считается, что его самым ранним предком была египетская иероглифическая система. Здесь картинки представляли реальные объекты. Например, изображение быка представляло быка из реальной жизни.
Позже изображение быка стало более стилизованным и совсем не похоже на быка. Другими словами, он превратился в символ или букву. И со временем эти буквы стали обозначать звуки, а не предметы (хотя звуки были связаны с произношением предмета).
Примерно к 2500 г. до н.э. люди, жившие в Египте, Сирии и Палестине, широко использовали эти символы для обозначения звуков; это было известно как семитский алфавит. Однако они использовали их только для обозначения только согласных звуков (не гласных). Около 1600 г. до н.э. семитский алфавит использовался финикийцами и получил более широкое распространение.
Затем около 1000 г. до н.э. пришли греки, которые приняли более короткую версию этого алфавита и, что немаловажно, добавили звуки для гласных. Конечно, следующими были римляне, которые взяли алфавит и адаптировали его для собственного использования. Это так называемый латинский алфавит, который мы используем сегодня, и между греческим и латинским алфавитами есть значительное сходство.
Предполагается, что латинский алфавит попал в Англию через Ирландию между 5 и 1000 г. н.э. Между прочим, латинский алфавит используется примерно в 100 языках мира и на сегодняшний день является самой распространенной системой письма (хотя и адаптированной для каждого языка).
Панграммы
Панграмма — это предложение, содержащее все 26 букв алфавита. Пожалуй, самая известная из них:
Быстрая коричневая лиса перепрыгивает через ленивую собаку.
Существует неофициальная охота на кратчайшее предложение, которое делает это; в идеале это было бы всего 26 букв. Это еще не совсем достигнуто, но это близко к 31 букве:
Пять мастеров бокса быстро прыгают.
Есть гораздо более короткие, но часто они основаны на очень неясных словах, мучительной грамматике или аббревиатурах:
Вальс, нимфа, для быстрой джиги vex Bud.
Пылкие ночные сорванцы разозлили Джека Кью.
Глум Шварцкопф разозлился на NJ IQ.
Обычные буквы
В английской орфографии наиболее часто встречаются следующие буквы:
e-t-a-o-i-n-s-r-h-l-d-c
Это полезно знать при игре в Hangman.
Полный список частот букв см. на этой странице.
Почему в алфавите 26 букв?
Нет никакой логической причины, по которой в английском алфавите 26 букв. В алфавитах других языков больше или меньше или такое же количество букв.
Буквы, используемые в английском языке, происходят от звуков, но между звуками и буквами нет реальной связи. Количество букв также определяется историей написания, правописания и печатания на английском языке.
Полезные ссылки
Заглавные буквы – когда мы их используем, почему они у нас есть…
Гласные и согласные. – посмотрите на разницу между ними.
Фото: iPhone Alphabet (лицензия)
Латинский алфавит | Определение, описание, история и факты
- Связанные темы:
- Этрусский алфавит
Просмотреть весь связанный контент →
Латинский алфавит , также называемый Латинский алфавит , наиболее широко используемая в мире алфавитная система письма, стандартная письменность английского языка и языков большей части Европы и территорий, заселенных европейцами. Разработанный из этрусского алфавита незадолго до 600 г. до н. э., его можно проследить через этрусские, греческие и финикийские письмена до северносемитского алфавита, использовавшегося в Сирии и Палестине около 1100 г. до н. э. Самая ранняя надпись латинским алфавитом появляется на Praeneste Fibula, булавке для плаща, датируемой примерно 7 веком до н. для Нумерия»). Немногим позже этого датируется вертикальная надпись на небольшой колонне на Римском форуме, а надпись Дуэноса на вазе, найденной недалеко от Квиринала (холм в Риме), вероятно, датируется 6 веком до н.э. Хотя эксперты расходятся во мнениях относительно датировки этих объектов, надписи обычно считаются старейшими из сохранившихся образцов латинского алфавита.
Классический латинский алфавит состоял из 23 букв, 21 из которых произошли от этрусского алфавита. В средние века буква I была дифференцирована на I и J и V на U , V и W , что дало алфавит, эквивалентный современному английскому языку с 26 буквами. Некоторые европейские языки, в настоящее время использующие латинский алфавит, не используют буквы K и W , а некоторые добавляют дополнительные буквы (обычно стандартные латинские буквы с добавленными диакритическими знаками или иногда пары букв, читающиеся как один звук).
Викторина «Британника»
Викторина «Как мы пишем»
Будь то Шекспир или Стивен Кинг, вы наверняка много знаете о своем любимом писателе. Но как насчет того, как вообще появились системы письма? Пройдите этот тест, чтобы узнать.
В древнеримские времена существовало два основных типа латинского письма: заглавные буквы и курсив. Были также разновидности письма, в которых заглавные буквы смешивались с курсивом или полукурсивом; Латинское унциальное письмо развилось из такой смешанной формы в 3 веке н.э. В средние века из заглавных, курсивных и унциальных форм возникло множество различных латинских шрифтов. Круглый «гуманистический» почерк, используемый для переписывания книг, и более угловатый курсив, использовавшийся в юридических и коммерческих целях в Италии 15-го века, дали начало, соответственно, римскому и курсивному шрифтам, используемым в настоящее время в печати.
В таблице указан латинский алфавит.
| верхний регистр | нижний регистр |
|---|---|
| А | а |
| Б | б |
| С | с |
| Д | д |
| Е | е |
| Ф | ф |
| грамм | грамм |
| ЧАС | час |
| я | я |
| Дж | Дж |
| К | к |
| л | л |
| М | м |
| Н | н |
| О | о |
| п | п |
| Вопрос | д |
| р | р |
| С | с |
| Т | т |
| U | ты |
| В | в |
| Вт | ж |
| Икс | Икс |
| Д | у |
| Z | г |
Редакторы Британской энциклопедии Эта статья была недавно отредактирована и обновлена Патрисией Бауэр.
Изучайте английский алфавит — изучайте основы английского языка
Алфавит | Гласные | Согласные | Рифмованный алфавит
Фонетический алфавит | Общие символы | Капитализация
Выучите английский алфавит (требуется Real Player).
Алфавит от A до Z | |||||||
| А и | Б б | С с | Д д | Е и | Ф ф | г г | Н ч |
| я и | Дж Дж | К к | л л | М м | Нет | О или | Р п |
| Q q | р р | С с | Т т | У у | В против | Вт с | Х х |
| Г г | З из | ||||||
Смотреть это видео с алфавитом
Согласных | |||||||
| Б | С | Д | Ф | Г | Х | Дж | К |
| л | М | Н | Р | В | Р | С | Т |
| В | Вт | х | Д | З | |||
Алфавит рифм | |||||||
|---|---|---|---|---|---|---|---|
Следующие буквы рифмуются друг с другом:- | |||||||
| звук | звук | е звук | ï звук | ю звук | |||
| А | Б | Ф | я | О | В | р | З |
| Н | С | л | Д | У | |||
| Д | Д | М | Вт | ||||
| К | Е | Н | |||||
| Г | С | ||||||
| Р | х | ||||||
| Т | |||||||
| В | |||||||
Фонетический алфавит | |||
| При написании (особенно по телефону) вы можете использовать фонетический алфавит, чтобы избежать путаницы между похожими по звучанию буквами – P/B S/F T/D и т. д. | |||
| А | Альфа | Б | Браво |
| С | Чарли | Д | Дельта |
| Е | Эхо | Ф | Фокстрот |
| Г | Гольф | Х | Отель |
| я | Индия | Дж | Джульетта |
| К | Кило | л | Лима |
| М | Майк | Н | ноябрь |
| О | Оскар | Р | Папа |
| В | Квебек | Р | Ромео |
| С | Сьерра | Т | Танго |
| У | Униформа | В | Виктор |
| Ш | Виски | х | Рентген |
| Д | Янки | З | Зулу |
Подробнее о произношении здесь. | |||
Общие символы | |
|---|---|
| Символ | Word (общий термин в скобках) |
| . | полный остановка |
| , | запятая |
| ? | вопрос марка |
| ! | восклицательный знак марка |
| : | двоеточие |
| ; | точка с запятой |
| – | дефис (тире) |
| и | амперсанд |
| / | косая черта (косая черта) |
| \ | наоборот косая черта (обратная косая черта) |
| @ | в |
| # | хеш |
| фунтов стерлингов | символ фунта |
| символ евро | |
| $ | символ доллара |
| апостроф | |
| ~ | тильда |
| * | звездочка |
| ´ | острый акцент |
| ` | могила акцент |
| ” | цитата марка |
| ( ) | левые/правые скобки |
| [] | левый/правый квадратный кронштейн |
| {} | распорка левая/правая |
| < > | левый/правый угловой кронштейн |
Капитализация | |
| При написании слова для кого-то иногда необходимо
сообщить человеку, когда нужно писать буквы ЗАГЛАВНЫМИ БУКВАМИ и когда их надо писать маленькие . |