Разобрать по схеме слово онлайн: Поиск слов по словарю фонетических разборов
Фонетический разбор слова онлайн (звуко-буквенный разбор)
Не путайте Ё с Е. Нёбо и небо – разные слова.
Фонетический разбор: А Б В Г Д Е Ё Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Э Ю Я.
Фонетический разбор — то же самое, что и звуко-буквенный разбор — это анализ звукового состава слова. Разбор под цифрой 1. На нашем сайте вы можете разобрать нужное слово, воспользовавшись формой выше. Просто введите слово и нажмите на кнопку «Разобрать». Можно вводить как одно слово, так и несколько слов или предложение. Наш сервис отличается большой базой слов в разных формах и с разными ударениями (более 1 460 000 слов) и мощной системой поиска с исправлением ошибок. Также у нас есть морфемный разбор слова онлайн.
Что включает в себя фонетический разбор слова:
- Орфографическую запись
- Деление на слоги
- Ударение
- Транскрипцию
- Характеристику каждого звука
- Число букв и звуков
- Несоответствия звука букве
На нашем сайте есть возможность оценивать разборы пальцами вверх и вниз. Этим вы делаете сайт лучше. Наша цель – стать лучшим сайтом для фонетических разборов в рунете.
Этим вы делаете сайт лучше. Наша цель – стать лучшим сайтом для фонетических разборов в рунете.
Независимо от того, из какого вы или ваш ребёнок класса, эта страница поможет вам.
Если вы ищете способ анализа фонетической структуры слов, для этого есть онлайн-инструмент. Сервис фонетического анализа слов позволяет ввести слово и посмотреть, как оно фонетически распадается.
Это может быть полезно для различных целей, например, для понимания произношения нового слова. Сервис включает словарь с большим количеством распространенных слов, чтобы вы могли увидеть, как они произносятся с учётом ударения. Это очень важно для того, чтобы понять, как правильно произносить слова и фразы. Без фонетического разбора вы можете не понять, как произносить некоторые звуки в словах, и в результате этого ваша речь может быть непонятной для других. Фонетический разбор поможет вам правильно произносить слова и фразы, что положительно скажется на вашей речи в целом.
Попробуйте использовать сервис фонетического разбора слов и узнайте, как он может помочь вам в изучении языка!
Пример фонетического разбора
лю́лька
Слово «лю́лька» состоит из 2 слогов: люль-ка. Ударение на 1-й слог.
Ударение на 1-й слог.
Транскрипция: [л’у́л’ка]
л — [ л’ ] — согласный, непарный звонкий, сонорный (всегда звонкий), мягкий (парный)
ю — [ у́ ] — гласный, ударный
л — [ л’ ] — согласный, непарный звонкий, сонорный (всегда звонкий), мягкий (парный)
ь — не обозначает звука
к — [ к ] — согласный, парный глухой, твёрдый (парный)
а — [ а ] — гласный, безударный
6 букв, 5 звуков.
Некоторые пояснения:
- Звуков [е], [ё], [ю], [я] не существует. Их не может быть в транскрипции слова.
- Букв ь и ъ не может быть в транскрипции слова. Они не обозначают звуков.
- Согласные л, м, н, р, й – сонорные, они всегда образуют звонкие звуки (не могут быть глухими).
- Знаком апострофа (’) обозначают мягкие согласные.
Цветовая схема: люлька
Не путайте Ё с Е. Всё и все – разные слова.
Популярное: больной, только , дрозд, ерасыл, день, уже, такого, уши, бизнес, мороз, белый, шмель, снег, слышится, крепнет, июль, красивую, пюре, кафе, январь, москва, ель, пояс, вьюга, яблоко, карабас-барабас, ёлка, друг, солнце, гуляй, оляпка, дождь, чайка, заяц, вдруг, юг, окно, кофе, ёжик, фильм, коньки, йогурт, бьёт, октябрь, пальто, зима, ещё, хлеб, трамвай, термос, сухой, кузнец, белка, чашка, вещь, град, музей, жизнь, анна, берёза, зимой, россия, маяк, гриб, щавель, его, листья, яма, мяч, глазки, чайник, земля, флаг, ателье, язык, ветер, горох, фонетика, мёд, дерево, ночь, модель, рельсы, легко, пень, клюв, конь, щука, лес, ослик, съел, гвоздь, дуб, жить, иней, съезд, утка, ручьи, лёд, улыбка
Поделиться
Пишите, мы рады комментариям
Вверх ↑
Фонетический разбор слов онлайн — правила и примеры
Фонетикой называют раздел языкознания, который изучает звуковую систему языка и звуки речи в целом. Фонетика — это наука о сочетании звуков в речи.
Фонетика — это наука о сочетании звуков в речи.
Фонетический разбор, или звуко-буквенный, — это анализ строения слогов и звуковой системы слова. Такой анализ предлагается выполнять как упражнение в учебных целях.
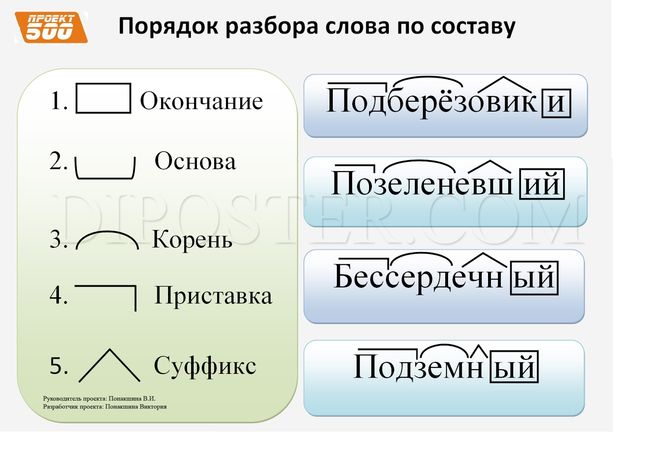
Под анализом понимается:
- подсчитывание количества букв;
- определение числа звуков в слове;
- постановка ударения;
- распределение звуков на согласные и гласные;
- классификация каждого звука;
- составление транскрипции (графической формы слова).
При разборе важно различать понятия «буква» и «звук». Ведь первые соответствуют орфографическим правилам, а вторые — речевым (то есть звуки анализируются с точки зрения произношения).
Прежде чем приступить к звуко-буквенному разбору, следует запомнить
В русском языке десять гласных звуков:
| [А] | [О] | [У] | [Ы] | [Э] | [ЙА] буква «Я» | [ЙО] буква «Ё» | [ЙУ] буква «Ю» | [И] | [ЙЭ] буква «Е» |
Первые пять обозначают, что предшествующий согласный является твердым, а вторые — мягким.
И двадцать один согласный звук:
| звонкие непарные звуки | [Й’] | [Л] | [М] | [Н] | [Р] | |
| глухие непарные | [Х] | [Ц] | [Ч’] | [Щ’] | ||
| звонкие парные | [Б] | [В] | [Г] | [Д] | [Ж] | [З] |
| глухие парные | [П] | [Ф] | [К] | [Т] | [Ш] | [С] |
Звонкими называют согласные, которые образуются с участием звука, а глухие — с помощью шума. Парными называют те согласные, которые образуют пару глухой/звонкий. Например, [Б]/[П], [В]/[Ф], [Г]/[К]. Непарными — те, которые не образуют пары: [Л], [М], [Р].
При фонетическом анализе слова стоит помнить, что согласные [Ч’], [Щ’], [Й’] — всегда мягкие, вне зависимости от того, какой гласный образует с ними слог. Согласные [Ж], [Ш] и [Ц] — всегда твердые.
[Й’], [Л], [Л’], [М], [М’], [Н], [Н’], [Р], [Р’] — сонорные звуки.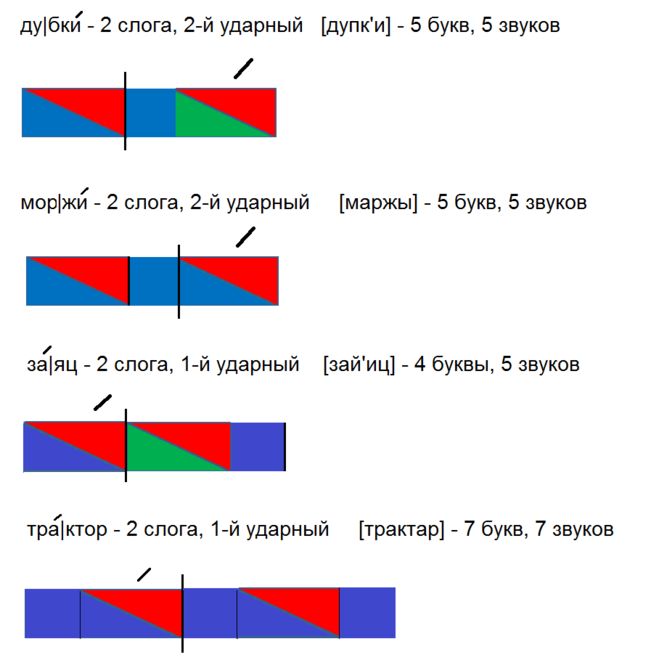 А значит, при произношении этих согласных звук образуется преимущественно голосом, но не шумом. Все сонорные — звонкие звуки.
А значит, при произношении этих согласных звук образуется преимущественно голосом, но не шумом. Все сонорные — звонкие звуки.
В русском алфавите есть также буквы Ь, Ъ. Они не образуют звука. Ь (мягкий знак) служит для того, чтобы смягчать согласные, после которых он ставится. Ъ (твердый знак) имеет разделительную функцию.
Правила разбора на звуки
- Транскрипция записывается в квадратных скобках: [ ].
- Мягкость звука обозначается символом «’».
- Перед глухими звонкие согласные оглушаются: ногти — [нокт’и].
- Звуки [с], [з] в приставках слов смягчаются: разъединить — [раз’й’эд’ин’ит’].
- Некоторые согласные в словах не читаются: костный — [косный’].
- Сочетание букв «сч», «зч» читаются как «щ»: счастье — [щ’аст’й’э].
- Удвоенный согласный обозначается «:»: постепенный — [паст’ип’эн:ый’].
Образец звуко-буквенного разбора слова
- Записать слово по правилам орфографии.
- Разделить слово по слогам.

- Обозначить ударный слог.
- Произнести слово вслух и на основании этого выполнить транскрипцию.
- Описать гласные звуки по порядку, обозначить, какие из них являются ударными, а какие — безударными. Описать согласные. Охарактеризовать их: парные/непарные, звонкие/глухие, твердые/мягкие.
- Подсчитать количество звуков и букв в слове.
Примеры фонетического разбора
Для примера ниже подобраны слова с наиболее интересными вариантами фонетического разбора: шестнадцатью, яростного, съестного, шестнадцатого, ерошиться, ёжиться, ёжится, ёршится, разъезжаться, съезжаться, для выполнения фонетического разбора других слов воспользуйтесь формой поиска:
Что такое парсер? Определение, типы и примеры
Архитектура приложенияК
- Бен Луткевич, Технические характеристики Писатель
В компьютерных технологиях синтаксический анализатор — это программа, которая обычно является частью компилятора. Он получает входные данные в виде последовательных инструкций исходной программы, интерактивных онлайн-команд, тегов разметки или какого-либо другого определенного интерфейса.
Он получает входные данные в виде последовательных инструкций исходной программы, интерактивных онлайн-команд, тегов разметки или какого-либо другого определенного интерфейса.
Парсеры разбивают входные данные, которые они получают, на такие части, как существительные (объекты), глаголы (методы) и их атрибуты или параметры. Затем они управляются другими программами, такими как другие компоненты компилятора. Синтаксический анализатор также может проверить, были ли предоставлены все необходимые входные данные.
Синтаксический анализатор — это программа, входящая в состав компилятора, а синтаксический анализ — часть процесса компиляции. Парсинг происходит на этапе анализа компиляции.
При синтаксическом анализе код берется из препроцессора, разбивается на более мелкие части и анализируется, чтобы другое программное обеспечение могло его понять. Синтаксический анализатор делает это, создавая структуру данных из входных данных.
Точнее, человек пишет код на понятном человеку языке, таком как C++ или Java, и сохраняет его в виде набора текстовых файлов. Синтаксический анализатор принимает эти текстовые файлы в качестве входных данных и разбивает их, чтобы их можно было перевести на целевую платформу.
Анализатор состоит из трех компонентов, каждый из которых обрабатывает разные этапы процесса анализа. Три этапа:
Учитывая набор символов x+z=11, лексический анализатор разделит его на серию токенов и классифицирует их, как показано.Этап 1: Лексический анализ
Лексический анализатор — или сканер — берет код из препроцессора и разбивает его на более мелкие части. Он группирует входной код в последовательности символов, называемые лексемами, каждая из которых соответствует токену. Токены — это единицы грамматики языка программирования, понятные компилятору.
Лексические анализаторы также удаляют пробельные символы, комментарии и ошибки из ввода.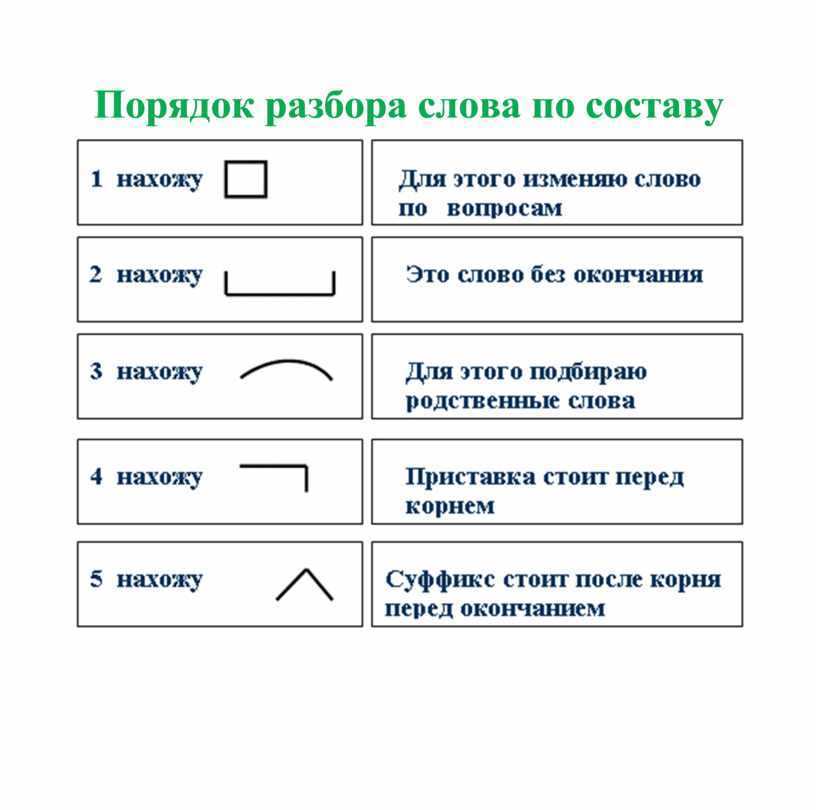
Этап 2: синтаксический анализ
Синтаксический анализатор принимает (x+y)*3 в качестве входных данных и возвращает это дерево синтаксического анализа, которое позволяет синтаксическому анализатору понять уравнение.Этап 3: Семантический анализ
Семантический анализ сверяет дерево синтаксического анализа с таблицей символов и определяет, является ли оно семантически непротиворечивым. Этот процесс также известен как контекстно-зависимый анализ. Он включает проверку типов данных, проверку меток и проверку управления потоком.
Если предоставлен код:
с плавающей запятой а = 30,2; число с плавающей запятой b = a*20
, то анализатор будет рассматривать 20 как 20.0 перед выполнением операции.
Некоторые источники называют синтаксическим анализом только стадию синтаксического анализа, поскольку она генерирует дерево синтаксического анализа. Они не учитывают лексический и семантический анализ.
Синтаксический анализ происходит на первых трех этапах процесса компиляции — лексическом, синтаксисе и семантическом анализе. Какие существуют основные типы парсеров?При создании языка программного обеспечения его создатели должны указать набор правил. Эти правила обеспечивают грамматику, необходимую для построения правильных операторов языка.
Ниже приведен набор грамматических правил для простого вымышленного языка, который содержит всего несколько слов:
<предложение> ::= <субъект> <глагол>
<тема> ::= <статья> <существительное>
<статья> ::= the | a
<существительное> ::= собака | кошка | человек
<глагол> ::= домашние животные | fed
<объект> ::= <статья> <существительное>
В этом языке предложение должно содержать подлежащее, глагол и существительное в указанном порядке, а отдельные слова должны соответствовать частям речи. Подлежащее – это артикль, за которым следует существительное. Существительное может быть одним из следующих трех слов: собака , кошка или лицо . А глаголом может быть только домашних животных или накормленных .
Подлежащее – это артикль, за которым следует существительное. Существительное может быть одним из следующих трех слов: собака , кошка или лицо . А глаголом может быть только домашних животных или накормленных .
Синтаксический анализ проверяет оператор, предоставленный пользователем в качестве входных данных, на соответствие этим правилам, чтобы доказать, что оператор действителен. Разные алгоритмы парсинга проверяют в разном порядке. Существует два основных типа парсеров:
- Нисходящие парсеры. Они начинаются с правила вверху, например <предложение> ::= <субъект> <глагол> <объект>. Имея входную строку «Человек накормил кошку», синтаксический анализатор просматривает первое правило и просматривает все правила, проверяя их правильность. В этом случае первое слово — это
, оно следует правилу подлежащего, и синтаксический анализатор продолжит чтение предложения в поисках . - Парсеры «снизу вверх».
 Они начинаются с правила внизу. В этом случае синтаксический анализатор сначала будет искать
Они начинаются с правила внизу. В этом случае синтаксический анализатор сначала будет искать
Проще говоря, нисходящие синтаксические анализаторы начинают свою работу с начального символа грамматики в верхней части дерева синтаксического анализа. Затем они продвигаются вниз от правила к предложению. Синтаксические анализаторы снизу вверх работают от предложения к правилу.
Помимо этих типов важно знать два типа деривации. Вывод — это порядок, в котором грамматика согласовывает входную строку. Их:
- Парсеры LL . Они анализируют входные данные слева направо, используя крайнее левое производное, чтобы сопоставить правила грамматики с входными данными. Этот процесс выводит строку, которая проверяет ввод, расширяя крайний левый элемент дерева синтаксического анализа.
- LR-парсеры . Эти входные данные анализируются слева направо, используя самое правое производное.
 Этот процесс извлекает строку, расширяя крайний правый элемент дерева синтаксического анализа.
Этот процесс извлекает строку, расширяя крайний правый элемент дерева синтаксического анализа.
Кроме того, существуют другие типы парсеров, в том числе следующие:
- Парсеры рекурсивного спуска. Парсеры рекурсивного спуска возвращаются после каждой точки решения, чтобы перепроверить точность. Парсеры рекурсивного спуска используют синтаксический анализ сверху вниз.
- Парсеры Эрли. Они анализируют все контекстно-свободные грамматики, в отличие от парсеров LL и LR. Большинство реальных языков программирования не используют контекстно-свободные грамматики.
- Парсеры Shift-reduce. Сдвигают и сокращают входную строку. На каждом этапе строки они сокращают слово до правила грамматики. Этот подход уменьшает строку до тех пор, пока она не будет полностью проверена.
Парсеры используются, когда необходимо абстрактно представить входные данные из исходного кода в виде структуры данных, чтобы их можно было проверить на правильность синтаксиса.
К технологиям, использующим синтаксический анализ для проверки входных данных кода, относятся следующие:
Языки программирования. Парсеры используются во всех языках программирования высокого уровня, включая следующие:
- С++
- Расширяемый язык разметки или XML
- Язык гипертекстовой разметки или HTML
- Препроцессор гипертекста или PHP
- Ява
- JavaScript
- Обозначение объекта JavaScript или JSON
- Перл
- Питон
Языки базы данных. Языки баз данных, такие как язык структурированных запросов, также используют синтаксические анализаторы.
Протоколы . Такие протоколы, как протокол передачи гипертекста и удаленные вызовы функций через Интернет, используют синтаксические анализаторы.
Генератор парсеров . Генераторы синтаксического анализа принимают грамматику в качестве входных данных и генерируют исходный код, который выполняет синтаксический анализ в обратном порядке. Они создают синтаксические анализаторы из регулярных выражений, которые представляют собой специальные строки, используемые для управления и сопоставления шаблонов в тексте.
Синтаксический анализ — это фундаментальная концепция разработки программного обеспечения и теории вычислений. Однако большинство ИТ-специалистов могут обойтись без глубокого понимания синтаксического анализа, используя платформы с низким кодом, которые позволяют пользователям создавать программы без написания тысяч строк кода. Узнайте о плюсах и минусах использования платформ с низким кодом на предприятии.
Узнайте о плюсах и минусах использования платформ с низким кодом на предприятии.
Последнее обновление: июль 2022 г.
Продолжить чтение О парсере- Памятка Terraform: известные команды, HCL и многое другое
- Как стать хорошим Java-программистом без диплома
- Интерпретируемые и компилируемые языки: в чем разница?
- Исправление 10 самых распространенных ошибок времени компиляции в Java
- 7 советов по выбору правильной библиотеки Java
командлет
Автор: Стивен Бигелоу
обработка естественного языка (NLP)
Автор: Бен Луткевич
компилятор
Автор: Роберт Шелдон
компьютерная лингвистика (CL)
Автор: Александр Гиллис
Качество ПО
- Тестовые фреймворки и примеры для модульного тестирования кода Python
Модульное тестирование является важным аспектом разработки программного обеспечения.
 Команды могут использовать Python для модульного тестирования, чтобы оптимизировать преимущества Python…
Команды могут использовать Python для модульного тестирования, чтобы оптимизировать преимущества Python… - Атрибуты эффективной стратегии тестирования базы данных
Команды должны внедрить правильную стратегию тестирования базы данных для оптимизации результатов. Изучение эффективных атрибутов тестирования базы данных …
- Обновления Java 20 Project Loom готовят почву для Java LTS
Java 20 повторно инкубирует две функции масштабируемости Project Loom, что делает их главными кандидатами на то, чтобы стать стандартом в сентябрьском выпуске Java …
Облачные вычисления
- Как работает маршрутизация на основе задержки в Amazon Route 53
Если вы рассматриваете Amazon Route 53 как способ уменьшить задержку, вот как работает этот сервис.
- 4 рекомендации, чтобы избежать привязки к поставщику облачных услуг
Без надлежащего планирования организация может оказаться в ловушке отношений с облачным провайдером.
 Следуйте этим …
Следуйте этим … - Подходит ли вам облачная стратегия?
Стратегия, ориентированная на облачные технологии, имеет свои преимущества и недостатки. Узнайте, как избежать рисков и построить стратегию, которая …
TheServerSide.com
- Как избежать выгорания удаленного инженера-программиста
Выгорание разработчика программного обеспечения реально. Вот несколько стратегий, которые программисты могут использовать, чтобы этого избежать.
- JavaScript против TypeScript: в чем разница?
TypeScript и JavaScript — две дополняющие друг друга технологии, которые стимулируют разработку как интерфейсных, так и серверных приложений. Вот…
- Как применить принцип единой ответственности в Java
Как работает модель единой ответственности в программе Java? Здесь мы покажем вам, что означает этот принцип SOLID и как .
 ..
..
Анализ текста с помощью Python · vipinajayakumar
Я ненавижу анализировать файлы, но это то, что мне приходилось делать в начале почти каждого проекта. Разбор не простой, и может стать камнем преткновения для новичков. Однако, как только вы освоитесь с разбором файлов, вам больше не придется беспокоиться об этой части проблемы. Вот почему я рекомендую новичкам освоиться с разбором файлов на раннем этапе обучения программированию. Эта статья предназначена для начинающих пользователей Python, которым интересно научиться анализировать текстовые файлы.
В этой статье я познакомлю вас со своей системой разбора файлов. Я кратко коснусь парсинга файлов в стандартных форматах, но хочу сосредоточиться на парсинге сложных текстовых файлов. Что я подразумеваю под комплексом? Что ж, к этому мы еще вернемся, юный падаван.
Для справки: набор слайдов, который я использую для презентации по этой теме, доступен здесь. Весь код и образцы текста, которые я использую, доступны в моем репозитории Github здесь.
Во-первых, давайте разберемся, в чем проблема. Зачем нам вообще нужно разбирать файлы? В воображаемом мире, где все данные существуют в одном и том же формате, можно было бы ожидать, что все программы будут вводить и выводить эти данные. Не было бы необходимости анализировать файлы. Однако мы живем в мире, где существует большое разнообразие форматов данных. Некоторые форматы данных лучше подходят для разных приложений. Можно ожидать, что отдельная программа будет обслуживать только некоторые из этих форматов данных. Итак, неизбежно возникает необходимость конвертировать данные из одного формата в другой для использования разными программами. Иногда данные даже не в стандартном формате, что немного усложняет задачу.
Итак, что такое синтаксический анализ?
- Анализ
- Разобрать (строку или текст) на логические синтаксические компоненты.
Мне не нравится приведенное выше определение из Оксфордского словаря. Итак, вот мое альтернативное определение.
- Анализ
- Преобразование данных определенного формата в более удобный формат.
Имея в виду это определение, мы можем представить, что наш ввод может быть в любом формате. Итак, первый шаг при столкновении с любой проблемой синтаксического анализа — понять формат входных данных. Если повезет, будет документация, описывающая формат данных. Если нет, возможно, вам придется самостоятельно расшифровать формат данных. Это всегда весело.
Как только вы поймете входные данные, следующим шагом будет определение более удобного формата. Ну, это полностью зависит от того, как вы планируете использовать данные. Если программа, в которую вы хотите передать данные, ожидает формат CSV, то это ваш конечный продукт. Для дальнейшего анализа данных я настоятельно рекомендую прочитать данные в pandas DataFrame .
Если вы аналитик данных Python, то, скорее всего, вы знакомы с pandas. Это пакет Python, который предоставляет DataFrame и другие функции для невероятно мощного анализа данных с минимальными усилиями. Это абстракция поверх Numpy, которая предоставляет многомерные массивы, подобные Matlab.
Это абстракция поверх Numpy, которая предоставляет многомерные массивы, подобные Matlab. DataFrame — это двумерный массив, но он может иметь несколько индексов строк и столбцов, которые pandas называет MultiIndex , что по существу позволяет хранить многомерные данные. Операции в стиле SQL или базы данных можно легко выполнять с помощью pandas (сравнение с SQL). Pandas также поставляется с набором инструментов ввода-вывода, который включает функции для работы с CSV, MS Excel, JSON, HDF5 и другими форматами данных.
Хотя мы хотели бы считывать данные в многофункциональную структуру данных, такую как pandas DataFrame , было бы очень неэффективно создавать пустой DataFrame и напрямую записывать в него данные. DataFrame представляет собой сложную структуру данных, и запись чего-либо в DataFrame поэлементно требует больших вычислительных ресурсов. Гораздо быстрее читать данные в примитивный тип данных, такой как list или dict . Как только список или словарь создан, pandas позволяет нам легко преобразовать его в
Как только список или словарь создан, pandas позволяет нам легко преобразовать его в DataFrame , как вы увидите позже. На изображении ниже показан стандартный процесс разбора любого файла.
Если ваши данные имеют стандартный или достаточно близкий формат, то, вероятно, существует существующий пакет, который вы можете использовать для чтения ваших данных с минимальными усилиями.
Допустим, у нас есть файл CSV, data.txt:
a,b,c 1,2,3 4,5,6 7,8,9
Вы легко справитесь с этим с пандами.
123 | импортировать панд как pd
df = pd.read_csv('data.txt')
гф |
а б в 0 1 2 3 1 4 5 6 2 7 8 9
Python невероятен, когда дело доходит до работы со строками. Стоит усвоить все распространенные строковые операции. Мы можем использовать эти методы для извлечения данных из строки, как вы можете видеть в простом примере ниже.
1 2 3 4 5 6 7 8 9101112131415161718192021 | my_string = 'Имена: Ромео, Джульетта' # разделить строку на ':' step_0 = my_string. |
 split(':')
# получаем первый фрагмент списка
шаг_1 = шаг_0[1]
# разделить строку на ','
step_2 = step_1.split(',')
# удаляем пробелы в начале и конце каждого элемента списка
step_3 = [name.strip() для имени в step_2]
# делаем все вышеперечисленные операции за один раз
one_go = [name.strip() для имени в my_string.split(':')[1].split(',')]
для idx, элемент в перечислении ([шаг_0, шаг_1, шаг_2, шаг_3]):
print("Шаг {}: {}".format(idx, элемент))
print("Окончательный результат за один раз: {}".format(one_go))
split(':')
# получаем первый фрагмент списка
шаг_1 = шаг_0[1]
# разделить строку на ','
step_2 = step_1.split(',')
# удаляем пробелы в начале и конце каждого элемента списка
step_3 = [name.strip() для имени в step_2]
# делаем все вышеперечисленные операции за один раз
one_go = [name.strip() для имени в my_string.split(':')[1].split(',')]
для idx, элемент в перечислении ([шаг_0, шаг_1, шаг_2, шаг_3]):
print("Шаг {}: {}".format(idx, элемент))
print("Окончательный результат за один раз: {}".format(one_go)) Шаг 0: ['Имена', 'Ромео, Джульетта'] Шаг 1: Ромео, Джульетта Шаг 2: ['Ромео', 'Джульетта'] Шаг 3: ['Ромео', 'Джульетта'] Окончательный результат за один раз: ['Ромео', 'Джульетта']
Как вы видели в предыдущих двух разделах, если проблема синтаксического анализа проста, мы могли бы просто использовать существующий анализатор или некоторые строковые методы. Однако жизнь не всегда так проста. Как нам разобрать сложный текстовый файл?
Шаг 1.
 Разберитесь с форматом ввода
Разберитесь с форматом ввода123 | с файлом open('sample.txt'):
file_contents = файл.чтение()
print(file_contents) |
Образец текста В викторине приняли участие ученики Ривердейл Хай и Хогвартса. Ниже приводится запись их результатов. Школа = Средняя школа Ривердейла Оценка = 1 Номер студента, имя 0, Фиби 1, Рэйчел Номер студента, Балл 0, 3 1, 7 Оценка = 2 Номер студента, имя 0, Анджела 1, Тристан 2, Аврора Номер студента, Балл 0, 6 1, 3 2, 9Школа = Хогвартс Оценка = 1 Номер студента, имя 0, Джинни 1, Луна Номер студента, Балл 0, 8 1, 7 Оценка = 2 Номер студента, имя 0, Гарри 1, Гермиона Номер студента, Балл 0, 5 1, 10 Оценка = 3 Номер студента, имя 0, Фред 1, Джордж Номер студента, Балл 0, 0 1, 0
Довольно сложный входной файл! Фу! Данные, которые он содержит, довольно просты, как вы можете видеть ниже:
Name Score.
Номер учащегося класса школы
Хогвартс 1 0 Джинни 8
1 Луна 7
2 0 Гарри 5
1 Гермиона 10
3 0 Фред 0
1 Джордж 0
Ривердейл Хай 1 0 Фиби 3
1 Рэйчел 7
2 0 Анжела 6
1 Тристан 3
2 Аврора 9 Образец текста похож на CSV, поскольку в нем используются запятые для разделения некоторой информации. В верхней части файла есть заголовок и некоторые метаданные. Есть пять переменных: школа, класс, номер ученика, имя и балл. Ключами являются школа, класс и номер ученика. Имя и Оценка являются полями. Для данной школы, класса, номера учащегося есть имя и оценка. Другими словами, школа, класс и номер учащегося вместе образуют составной ключ.
В верхней части файла есть заголовок и некоторые метаданные. Есть пять переменных: школа, класс, номер ученика, имя и балл. Ключами являются школа, класс и номер ученика. Имя и Оценка являются полями. Для данной школы, класса, номера учащегося есть имя и оценка. Другими словами, школа, класс и номер учащегося вместе образуют составной ключ.
Данные представлены в иерархическом формате. Сначала объявляется школа, затем класс. Затем следуют две таблицы, содержащие имя и балл для каждого номера учащегося. Затем увеличивается оценка. Далее следует еще один набор таблиц. Затем картина повторяется для другой школы. Обратите внимание, что количество учащихся в классе или количество классов в школе не являются постоянными, что немного усложняет файл. Это всего лишь небольшой набор данных. Вы можете легко представить, что это массивный файл с множеством школ, классов и учеников.
Само собой разумеется, что формат данных исключительно плохой. Я сделал это намеренно. Если вы понимаете, как с этим обращаться, вам будет намного проще освоить более простые форматы. Нередко встречаются такие файлы, если приходится иметь дело с большим количеством устаревших систем. В прошлом, когда эти системы разрабатывались, возможно, не требовалось, чтобы вывод данных был машиночитаемым. Однако в настоящее время все должно быть машиночитаемым!
Нередко встречаются такие файлы, если приходится иметь дело с большим количеством устаревших систем. В прошлом, когда эти системы разрабатывались, возможно, не требовалось, чтобы вывод данных был машиночитаемым. Однако в настоящее время все должно быть машиночитаемым!
Шаг 2: Импортируйте необходимые пакеты
Нам понадобится модуль регулярных выражений и пакет pandas. Итак, давайте продолжим и импортируем их.
12 | импорт повторно import pandas as pd |
Шаг 3: определение регулярных выражений
На последнем шаге мы импортировали re, модуль регулярных выражений. Что это такое?
Ранее мы видели, как использовать строковые методы для извлечения данных из текста. Однако при синтаксическом анализе сложных файлов мы можем столкнуться с большим количеством зачистки, разделения, нарезки и многого другого, и код может выглядеть довольно нечитаемым. Вот тут-то и появляются регулярные выражения. По сути, это крошечный язык, встроенный в Python, который позволяет вам сказать, какой строковый шаблон вы ищете. Кстати, это не уникально для Python (дом на дереве).
Вот тут-то и появляются регулярные выражения. По сути, это крошечный язык, встроенный в Python, который позволяет вам сказать, какой строковый шаблон вы ищете. Кстати, это не уникально для Python (дом на дереве).
Вам не нужно становиться мастером регулярных выражений. Однако некоторые базовые знания о регулярных выражениях могут оказаться очень полезными в вашей карьере программиста. В этой статье я научу вас только самым основам, но я призываю вас продолжить изучение. Я также рекомендую regexper для визуализации регулярных выражений. regex101 — еще один отличный ресурс для тестирования вашего регулярного выражения.
Нам понадобятся три регулярных выражения. Первый, как показано ниже, поможет нам идентифицировать школу. Его регулярное выражение равно Школа = (.*)\n . Что означают символы?
-
.: Любой символ -
*: 0 или более предыдущего выражения -
(.*): Помещение части регулярного выражения в круглые скобки позволяет сгруппировать эту часть выражения. Итак, в данном случае сгруппированная часть — это название школы.
Итак, в данном случае сгруппированная часть — это название школы. -
\n: Символ новой строки в конце строки
Затем нам нужно регулярное выражение для оценки. Его регулярное выражение равно Оценка = (\d+)\n . Это очень похоже на предыдущее выражение. Новые символы:
-
\d: сокращение от [0-9] . -
+: 1 или более предыдущих выражений
Наконец, нам нужно регулярное выражение, чтобы определить, является ли таблица, следующая за выражением в текстовом файле, таблицей имен или рейтингов. Его регулярное выражение: (Name|Score) . Новый символ:
-
|: Логическое или утверждение, поэтому в данном случае это означает «Имя» или «Оценка».
Нам также необходимо понять несколько функций регулярных выражений:
-
re.compile(pattern): скомпилировать шаблон регулярного выражения вRegexObject.
RegexObject имеет следующие методы:
-
match(string): если начало строки совпадает с регулярным выражением, вернуть соответствующий экземплярMatchObject. В противном случае вернутьNone. -
search(string): Просканировать строку в поисках места, где это регулярное выражение произвело совпадение, и вернуть соответствующий экземплярMatchObject. ВозвращаетNone, если совпадений нет.
MatchObject всегда имеет логическое значение True . Таким образом, мы можем просто использовать оператор if для определения положительных совпадений. Он имеет следующий метод:
-
group(): Возвращает одну или несколько подгрупп совпадения. На группы можно ссылаться по их индексу.group(0)возвращает полное совпадение.group(1)возвращает первую подгруппу в скобках и так далее. Используемые нами регулярные выражения имеют только одну группу. Легкий! Однако что, если групп было несколько? Было бы трудно запомнить, к какому номеру принадлежит группа. Специальное расширение Python позволяет нам называть группы и ссылаться на них по имени. Мы можем указать имя внутри группы в скобках
Используемые нами регулярные выражения имеют только одну группу. Легкий! Однако что, если групп было несколько? Было бы трудно запомнить, к какому номеру принадлежит группа. Специальное расширение Python позволяет нам называть группы и ссылаться на них по имени. Мы можем указать имя внутри группы в скобках (...)примерно так:(?P<имя>...).
Сначала определим все регулярные выражения. Обязательно используйте необработанные строки для регулярного выражения, т. е. используйте индекс r перед каждым шаблоном.
1234567 | # настроить регулярные выражения
# используйте https://regexper.com, чтобы визуализировать их, если это необходимо
rx_dict = {
'школа': re.compile(r'School = (?P |
Шаг 4: Напишите синтаксический анализатор строк
Затем мы можем определить функцию, которая проверяет соответствие регулярным выражениям.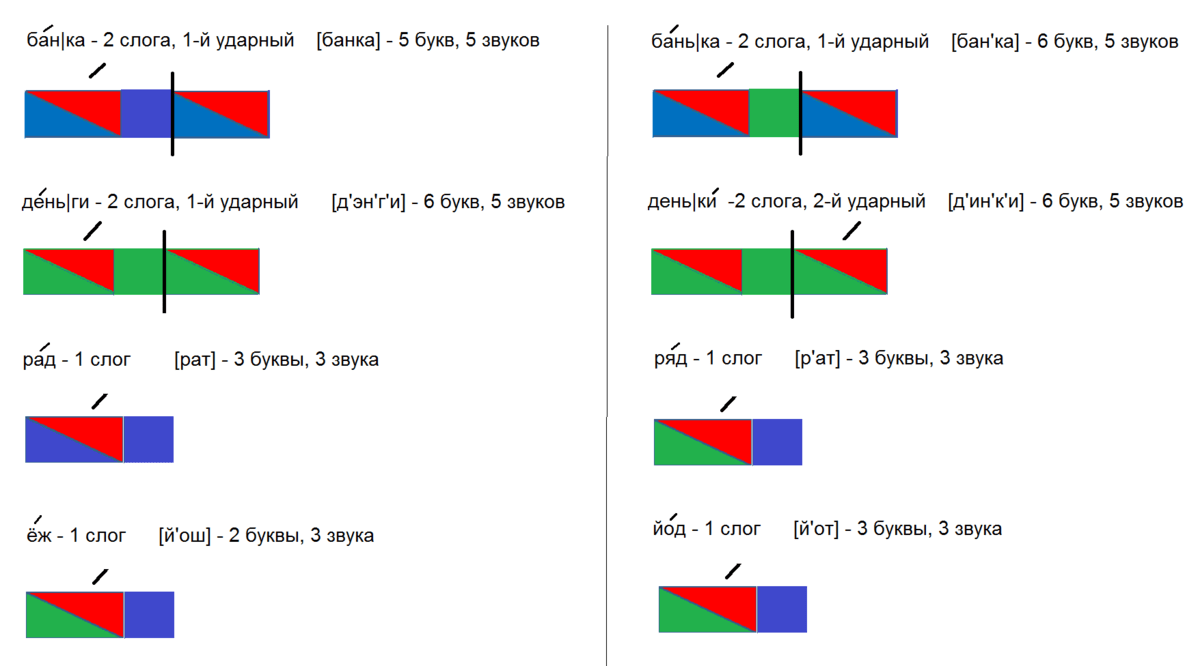
1 2 3 4 5 6 7 8 910111213 | определение _parse_line (строка):
"""
Выполните поиск регулярных выражений по всем определенным регулярным выражениям и
вернуть ключ и результат сопоставления первого совпадающего регулярного выражения
"""
для ключа, rx в rx_dict.items():
совпадение = rx.search(строка)
если совпадают:
ключ возврата, совпадение
# если совпадений нет
возврат Нет, Нет |
Шаг 5: Напишите синтаксический анализатор файлов
Наконец, для основного события у нас есть функция синтаксического анализа файлов. Он довольно большой, но комментарии в коде должны помочь вам понять логику.
1 2 3 4 5 6 7 8 |
 DataFrame
Проанализированные данные
"""
data = [] # создаем пустой список для сбора данных
# открываем файл и читаем его построчно
с открытым (путь к файлу, 'r') как файл_объект:
строка = файл_объект.readline()
пока строка:
# в каждой строке проверяем совпадение с регулярным выражением
ключ, совпадение = _parse_line (строка)
# извлечь название школы
если ключ == 'школа':
школа = match.group('школа')
# степень извлечения
если ключ == 'оценка':
оценка = match.group('оценка')
класс = инт (класс)
# идентифицируем заголовок таблицы
если ключ == 'name_score':
# извлечь тип таблицы, т. е. имя или счет
value_type = match.group('name_score')
строка = файл_объект.readline()
# читать каждую строку таблицы до пустой строки
в то время как line.
DataFrame
Проанализированные данные
"""
data = [] # создаем пустой список для сбора данных
# открываем файл и читаем его построчно
с открытым (путь к файлу, 'r') как файл_объект:
строка = файл_объект.readline()
пока строка:
# в каждой строке проверяем совпадение с регулярным выражением
ключ, совпадение = _parse_line (строка)
# извлечь название школы
если ключ == 'школа':
школа = match.group('школа')
# степень извлечения
если ключ == 'оценка':
оценка = match.group('оценка')
класс = инт (класс)
# идентифицируем заголовок таблицы
если ключ == 'name_score':
# извлечь тип таблицы, т. е. имя или счет
value_type = match.group('name_score')
строка = файл_объект.readline()
# читать каждую строку таблицы до пустой строки
в то время как line. strip():
# извлечь число и значение
число, значение = line.strip().split(',')
значение = значение.strip()
# создать словарь, содержащий эту строку данных
строка = {
«Школа»: школа,
«Оценка»: оценка,
«Номер студента»: номер,
тип_значения: значение
}
# добавляем словарь в список данных
data.append(строка)
строка = файл_объект.readline()
строка = файл_объект.readline()
# создать pandas DataFrame из списка диктов
данные = pd.DataFrame(данные)
# установить номер школы, класса и ученика в качестве индекса
data.set_index(['Школа', 'Оценка', 'Номер ученика'], inplace=True)
# объединить df, чтобы удалить nans
данные = данные.группа(уровень=данные.индекс.имена).первый()
# обновить Score с float до integer
data = data.
strip():
# извлечь число и значение
число, значение = line.strip().split(',')
значение = значение.strip()
# создать словарь, содержащий эту строку данных
строка = {
«Школа»: школа,
«Оценка»: оценка,
«Номер студента»: номер,
тип_значения: значение
}
# добавляем словарь в список данных
data.append(строка)
строка = файл_объект.readline()
строка = файл_объект.readline()
# создать pandas DataFrame из списка диктов
данные = pd.DataFrame(данные)
# установить номер школы, класса и ученика в качестве индекса
data.set_index(['Школа', 'Оценка', 'Номер ученика'], inplace=True)
# объединить df, чтобы удалить nans
данные = данные.группа(уровень=данные.индекс.имена).первый()
# обновить Score с float до integer
data = data.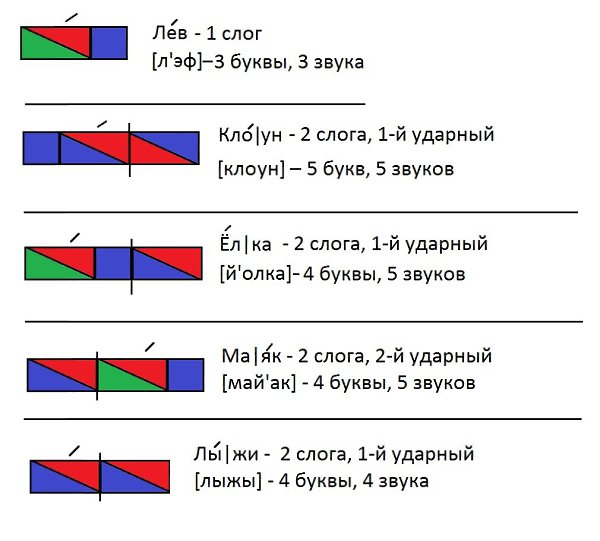 apply(pd.to_numeric, errors='игнорировать')
вернуть данные
apply(pd.to_numeric, errors='игнорировать')
вернуть данные Шаг 6: Тестирование синтаксического анализатора
Мы можем использовать наш синтаксический анализатор для нашего образца текста следующим образом:
1234 | , если __name__ == '__main__':
путь к файлу = 'sample.txt'
данные = разбор (путь к файлу)
печать(данные) |
Имя Оценка
Номер учащегося класса школы
Хогвартс 1 0 Джинни 8
1 Луна 7
2 0 Гарри 5
1 Гермиона 10
3 0 Фред 0
1 Джордж 0
Ривердейл Хай 1 0 Фиби 3
1 Рэйчел 7
2 0 Анжела 6
1 Тристан 3
2 Аврора 9 Это все хорошо, и вы можете увидеть, сравнив ввод и вывод на глаз, что парсер работает правильно. Тем не менее, лучше всего всегда писать юнит-тесты, чтобы убедиться, что ваш код делает то, что вы хотели. Всякий раз, когда вы пишете синтаксический анализатор, убедитесь, что он хорошо протестирован. У меня возникли проблемы с моими коллегами из-за использования парсеров без тестирования. Эй! Также стоит отметить, что это не обязательно должен быть последний шаг. Действительно, многие программисты проповедуют разработку через тестирование. Я не включил сюда набор тестов, так как хотел, чтобы это руководство было кратким.
Всякий раз, когда вы пишете синтаксический анализатор, убедитесь, что он хорошо протестирован. У меня возникли проблемы с моими коллегами из-за использования парсеров без тестирования. Эй! Также стоит отметить, что это не обязательно должен быть последний шаг. Действительно, многие программисты проповедуют разработку через тестирование. Я не включил сюда набор тестов, так как хотел, чтобы это руководство было кратким.
Я разбирал текстовые файлы в течение года и со временем усовершенствовал свой метод. Тем не менее, я провел дополнительное исследование, чтобы выяснить, есть ли лучшее решение. Действительно, я должен поблагодарить различных членов сообщества, которые посоветовали мне оптимизировать мой код. Сообщество также предложило несколько различных способов разбора текстового файла. Некоторые из них были умными и захватывающими. Мой личный фаворит был этот. Я представил свой пример проблемы и решения на следующих форумах:
- Сообщение Reddit
- Пост переполнения стека
- Сообщение о проверке кода
Если ваша проблема еще более сложна и регулярные выражения не решают ее, то следующим шагом будет рассмотрение возможности разбора библиотек.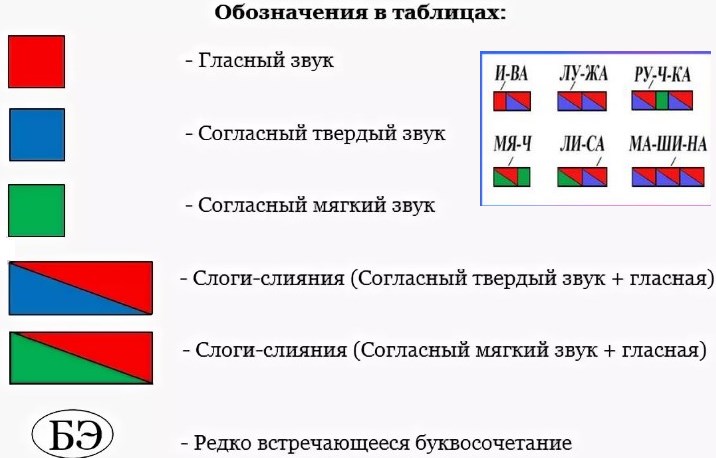 Вот несколько мест, с которых можно начать:
Вот несколько мест, с которых можно начать:
- Анализ ужасных вещей с помощью Python: Лекция Эрика Роуза о PyCon, в которой рассматриваются плюсы и минусы различных библиотек синтаксического анализа.
- Синтаксический анализ в Python: инструменты и библиотеки: Инструменты и библиотеки, позволяющие создавать парсеры, когда регулярных выражений недостаточно.
Теперь, когда вы понимаете, насколько трудным и утомительным может быть анализ текстовых файлов, если вы когда-нибудь окажетесь в привилегированном положении при выборе формата файла, выбирайте его с осторожностью. Вот лучшие практики Стэнфорда для форматов файлов.
Я бы солгал, если бы сказал, что был в восторге от моего метода синтаксического анализа, но я не знаю другого способа быстрого анализа текстового файла, который так же удобен для новичков, как тот, который я представил выше. Если вы знаете лучшее решение, я весь внимание! Надеюсь, я дал вам хорошую отправную точку для разбора файла в Python! Я провел пару месяцев, пробуя множество разных методов и написав какой-то безумно нечитаемый код, прежде чем наконец понял это, и теперь я не думаю дважды о разборе файла.