Правильное написание цифр прописью в документах: Формы написания чисел в тексте документов
Умный парсер числа, записанного прописью / Хабр
Добрый день, уважаемые читатели. В данной статье я расскажу о том, как распарсить число, записанное прописью на русском языке.
Умным данный парсер делает возможность извлечения чисел из текста с ошибками, допущенными в результате некорректного ввода или в результате оптического распознавания текста из изображения (OCR).
Для ленивых:
Ссылка на проект github: ссылка.
В данном разделе будут описаны использованные алгоритмы. Осторожно, много букв!
Постановка задачи
По работе мне требуется распознать текст из печатного документа, сфотографированного камерой смартфона/планшета. Из-за соглашения о неразглашении информации я не могу привести пример фотографии, но суть в том, что в документе имеется таблица, в которой записаны некие показатели числом и прописью, и эти данные необходимо прочитать. Парсинг текста прописью необходим как дополнительный инструмент валидации, чтобы убедиться, что число распознано верно. Но, как известно, OCR не гарантирует точного распознавания текста. Например, число двадцать, записанное прописью, может быть распознано как «двадпать» или даже как «двапать». Нужно это учесть и извлечь максимальное количество информации, оценив величину возможной ошибки.
Но, как известно, OCR не гарантирует точного распознавания текста. Например, число двадцать, записанное прописью, может быть распознано как «двадпать» или даже как «двапать». Нужно это учесть и извлечь максимальное количество информации, оценив величину возможной ошибки.
Примечание. Для распознавания текста я использую tesseract 4. Для .NET нет готового NuGet-пакета четвертой версии, поэтому я создал такой из ветки основного проекта, может кому пригодится: Genesis.Tesseract4.
Базовый алгоритм парсинга числа
Начнем с простого, а именно с алгоритма распознавания текста, записанного прописью, пока без ошибок. Если вам интересен именно умный парсинг, данный раздел можно пропустить.
Я не особо силен в гуглении, поэтому сходу не нашел готовый алгоритм для решения этой задачи. Впрочем, это даже к лучшему, т.к. алгоритм, придуманный самим, дает больше простора для кодинга. Да и сама задача оказалось интересной.
Итак, возьмем небольшое число, например «сто двадцать три».
"сто двадцать три" = сто + двадцать + три = 100 + 20 + 3 = 123
Пока все просто, но копнем глубже, например рассмотрим число «двести двенадцать тысяч сто пять».
"двести двенадцать тысяч сто пять" = (двести + двенадцать) × тысяч + (сто + пять) = 212 * 1.000 + 105 = 212.105.
Как видим, когда в числе присутствуют тысячи (а также миллионы и прочие степени тысячи), число делится на части, состоящие из локального маленького числа, в примере выше – 212, и множителя (1000). Таких фрагментов может быть несколько, но все они идут по убыванию множителя, например, за тысячей не может последовать миллион или еще одна тысяча. Это верно также и для частей маленького числа, так за сотнями не могут последовать сотни, а за десятками — десятки, поэтому запись «сто пятьсот» неверна. Характеристику, относящую два токена к одному типу, назовем уровнем, например, токены «сто» и «триста» имеют один уровень, и он больше, чем у токена «пятьдесят».
Из этих рассуждений и рождается идея алгоритма. Давайте выпишем все возможные токены (образцы), каждому из которых поставим в соответствие число, а также два параметра – уровень и признак множителя.
| Токен | Число | Уровень | Множитель? |
|---|---|---|---|
| ноль |
0 |
1 |
нет |
| один/одна |
1 |
1 |
нет |
| два/две |
2 |
1 |
нет |
| … |
… |
1 |
нет |
| девятнадцать |
19 |
1 |
нет |
| двадцать |
20 |
2 |
нет |
| … |
… |
2 |
нет |
| девяносто |
90 |
2 |
нет |
| сто |
100 |
3 |
нет |
| … |
… |
3 |
нет |
| девятьсот |
900 |
3 |
нет |
| тысяча/тысячи/тысяч |
1. 000 000 |
4 |
да |
| миллион/миллиона/миллионов |
1.000.000 |
5 |
да |
| … |
… |
… |
да |
| квадриллион/квадриллиона/квадриллионов |
1.000.000.000.000.000 |
8 |
да |
На самом деле, в эту таблицу можно добавить и любые другие токены, в том числе для иностранных языков, только не забывайте, что в некоторых странах используется длинная, а не короткая система наименования чисел.
Теперь перейдем к парсингу. Заведем четыре величины:
- Глобальный уровень (globalLevel). Указывает, какой уровень был у последнего множителя. Изначально не определен и необходим для контроля. Если мы встретим токен-множитель, у которого уровень больше или равен глобальному, то это ошибка.
- Глобальное значение
 Общий сумматор, куда складывается результат результат перемножения локального числа и множителя.
Общий сумматор, куда складывается результат результат перемножения локального числа и множителя. - Локальный уровень (localLevel). Указывает, какой уровень был у последнего токена. Изначально не определен, работает аналогично глобальному уровню, но сбрасывается после обнаружения множителя.
- Локальное значение (localValue). Сумматор токенов, не являющихся множителями, т.е. чисел до 999.
Алгоритм выглядит следующим образом:
- Разбиваем строку на токены с помощью регулярки “\s+”.
- Берем очередной токен, получаем информацию о нем из образца.
- Если это множитель:
- Если задан глобальный уровень, то убеждаемся, что он больше или равен уровню токена. Если нет – это ошибка, число некорректно.
- Устанавливаем глобальный уровень на уровень текущего токена.
- Умножаем величину токена на локальное значение и добавляем результат к глобальному значению.
- Очищаем локальное значение и уровень.

- Если это не множитель:
- Если задан локальный уровень, то убеждаемся, что он больше или равен уровню токена. Если нет – это ошибка, число некорректно.
- Устанавливаем локальный уровень на уровень текущего токена.
- Прибавляем к локальному значению величину токена.
- Возвращаем результат как сумму глобального и локального значений.
Пример работы для числа «два миллиона двести двенадцать тысяч сто восемьдесят пять».
| Токен |
globalLevel |
globalValue |
localLevel |
localValuе |
|---|---|---|---|---|
| – |
– |
– |
||
| два |
– |
– |
1 |
2 |
| миллиона |
5 |
2.000.000 |
– |
– |
| двести |
5 |
2. 000.000 000.000 |
3 |
200 |
| двенадцать |
5 |
2.000.000 |
1 |
212 |
| тысяч |
4 |
2.212.000 |
– |
– |
| сто |
4 |
2.212.000 |
3 |
100 |
| восемьдесят |
4 |
2.212.000 |
2 |
180 |
| пять |
4 |
2.212.000 |
1 |
185 |
Результатом будет 2.212.185.
Умный парсинг
Данный алгоритм можно использовать для реализации других сопоставлений, а не только для парсинга чисел, по этой причине я постараюсь описать его как можно подробнее.
С парсингом корректно записанного числа разобрались. Теперь давайте подумаем, какие ошибки могут быть при неверной записи числа, полученного в результате OCR. Другие варианты я не рассматриваю, но вы можете модифицировать алгоритм под конкретную задачу.
Теперь давайте подумаем, какие ошибки могут быть при неверной записи числа, полученного в результате OCR. Другие варианты я не рассматриваю, но вы можете модифицировать алгоритм под конкретную задачу.
Я выделил три вида ошибок, с которыми столкнулся в процессе работы:
- Замена символов на другие со схожим начертанием. Например, буква «ц» почему-то заменяется на «п», а «н» на «и» и наоборот. При использовании третьей версии tesseract возможна замена буквы «о» на ноль. Эти ошибки, навскидку, самые распространенные, и требуют тюнинга под конкретную библиотеку распознавания. Так так принципы работы tesseract версий 3 и 4 имеют кардинальные различия, поэтому и ошибки там будут разными.
- Слияние токенов. Слова могут сливаться воедино (обратного пока не встречал). В комбинации с первой ошибкой порождает демонические фразы типа «двапатьодин». Попробуем раздраконить и таких монстров.
- Шум – левые символы и фразы в тексте. К сожалению, здесь мало что можно сделать на данный момент, но перспектива есть при сборе достаточно весомой статистики.

При этом сам алгоритм разбора, описанный выше, почти не меняется, главное различие в разбиении строки на токены.
Но начнем со сбора небольшой статистики использования букв в токенах. Из 33 букв русского языка при написании неотрицательных целых чисел используются только 20, назовем их хорошими буквами:
авдеиклмнопрстцчшыья
Остальные 13, соответственно, назовем плохими буквами. Максимальный размер токена при этом составляет 12 символов (13 при счете до квадриллионов). Подстроки длиной больше этой величины нужно разбивать.
Для сопоставления строк и токенов я решил использовать алгоритм Вагнера-Фишера, хотя и назвал его именем Левенштейна в коде. Редакционное предписание мне не нужно, поэтому я реализовал экономную по памяти версию алгоритма. Должен признаться, что реализация этого алгоритма оказалась более сложной задачей, чем сам парсер.
Небольшой ликбез: расстояние Левенштейна – частный случай алгоритма Вагнера-Фишера, когда стоимость вставки, удаления и замены символов статичны.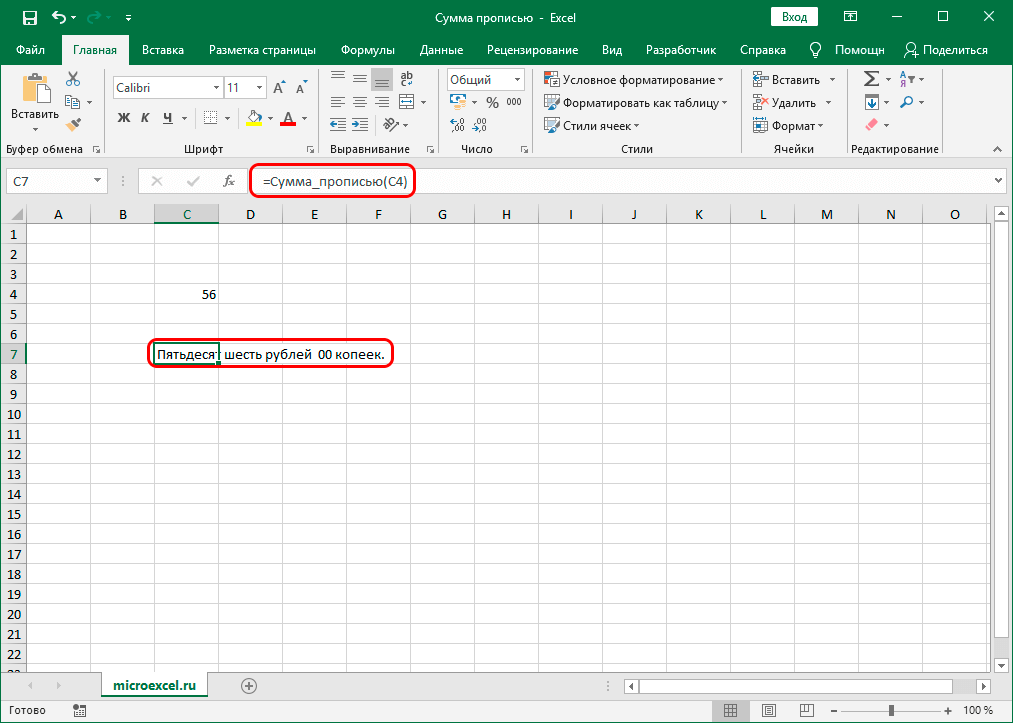
Для описания стоимости вставки, удаления и замены символов я создал такую таблицу: ссылка на таблицу с весами. Пока она заполнена методом трех П (пол, палец, потолок), но если заполнить ее данными на основе статистики OCR, то можно значительно улучшить качество распознавания чисел. В коде библиотеки присутствует файл ресурсов NumeralLevenshteinData.txt, в который можно вставить данные из подобной таблицы с помощью Ctrl+A, Ctrl+C и Ctrl+V.
Если в тексте встречается нетабличный символ, например, ноль, то стоимость его вставки приравнивается к максимальной величине из таблицы, а стоимость удаления и замены – к минимальной, таким образом алгоритм охотнее заменит ноль на букву «о», а если вы используете третью версию tesseract, то имеет смысл добавить ноль в таблицу и прописать минимальную цену для замены его на букву «о».
Итак, данные для алгоритма Вагнера-Фишера мы подготовили, давайте внесем изменения в алгоритм разбиения строки на токены. Для этого каждый токен мы подвергнем дополнительному анализу, но перед этим расширим информацию о токене следующими характеристиками:
- Уровень ошибки. Вещественное число от 0 (ошибки нет) до 1 (токен некорректен), означающее, насколько хорошо токен был сопоставлен с образцом.
- Признак использования токена. При разборе строки с вкраплениями мусора, часть токенов будет отброшена, для них данный признак выставляться не будет. При этом итоговая величина ошибки будет считаться как среднее арифметическое от ошибок использованных токенов.
Алгоритм анализа токенов:
- Пытаемся найти токен в таблице как есть. Если находим – все хорошо, возвращаем его.
- Если нет, то составляем список возможных вариантов:
Пытаемся сопоставить токен с образцом с помощью алгоритма Вагнера-Фишера.
 Данный вариант состоит из одного токена (сопоставленного образца) и его ошибка равна лучшему расстоянию, поделенному на длину образца.
Данный вариант состоит из одного токена (сопоставленного образца) и его ошибка равна лучшему расстоянию, поделенному на длину образца.
Пример: токен «нуль» сопоставляется с образцом «ноль», при этом расстояние равно 0.5, т.к. стоимость замены плохой буквы «у» на хорошую «о» равна 0.5. Общая ошибка для данного токена будет 0.5 / 4 = 0.125.Если подстрока достаточно большая (у меня это 6 символов), пытаемся поделить ее на две части минимум по 3 символа в каждой. Для строки в 6 символов будет единственный вариант деления: 3+3 символа. Для строки в 7 символов – уже два варианта, 3+4 и 4+3, и т.д. Для каждого из вариантов вызываем рекурсивно эту же функцию анализа токенов, заносим полученные варианты в список.
Чтобы не умирать в рекурсии, определяем максимальный уровень проваливания. Кроме того, варианты полученные в результате деления искусственно ухудшаем на некую величину (опция, по умолчанию 0.1), чтобы вариант прямого сопоставления был более ценным.
 Эту операцию пришлось добавить, т.к. подстроки типа «двапать» успешно делились на токены «два» и «пять», а не приводились к «двадцать». Увы, таковы особенности русского языка.
Эту операцию пришлось добавить, т.к. подстроки типа «двапать» успешно делились на токены «два» и «пять», а не приводились к «двадцать». Увы, таковы особенности русского языка.Пример: токен «двапать» имеет прямое сопоставление с образцом «двадцать», ошибка 0.25. Кроме того, лучшим вариантом деления является «два» + «пять» стоимостью 0.25 (замена «а» на «я»), ухудшенная искусственно до 0.35, в результате чего предпочтение отдается токену «двадцать».
- После составления всех вариантов выбираем лучший по минимальной сумме ошибок участвующих в нем токенов. Результат возвращаем.
Кроме того, в основной алгоритм генерации числа вводится проверка токенов, чтобы их ошибка не превышала некую величину (опция, по умолчанию 0.67). С помощью этого мы отсеиваем потенциальный мусор, хотя и не очень успешно.
Алгоритм в двух словах для тех, кому было лень читать текст выше
Входящую строку, представляющую число прописью мы разбиваем на подстроки с помощью регулярки \s+, затем каждую из подстрок пытаемся сопоставить с токенами-образцами или разбить на более мелкие подстроки, выбирая при этом лучшие результаты. В итоге получаем набор токенов, по которым генерируем число, а величину ошибки принимаем за среднее арифметическое ошибок среди токенов, использованных при генерации.
В итоге получаем набор токенов, по которым генерируем число, а величину ошибки принимаем за среднее арифметическое ошибок среди токенов, использованных при генерации.
Заточка алгоритма под конкретную задачу
В моей задаче числа неотрицательные и относительно небольшие, поэтому я исключу ненужные токены от «миллиона» и выше. Для теста, уважаемые читатели, я, напротив, добавил дополнительные токены-жаргонизмы, что позволило парсить строки типа «пять кусков», «косарь двести» и даже «три стольника и два червонца». Забавно, но это даже не потребовало изменений в алгоритме.
Дальнейшее улучшение
У существующего алгоритма есть и недоработки:
- Контроль падежей. Строки «две тысячи» и «два тысячей» будут с нулевой ошибкой распознаны как 2000. В моей задаче контроль падежей не требуется, он даже вреден, но если вам нужна такая функция, это решается введением дополнительного флага в токен, отвечающего за падеж следующего токена.
- Отрицательные числа.
 Вводится дополнительный токен «минус» с особой обработкой. Ничего сложного, но не забудьте, что буква «у» является плохой, и не встречается в числительных, нужно будет изменить ее весовые характеристики или надеятся, что она не изменится в процессе OCR.
Вводится дополнительный токен «минус» с особой обработкой. Ничего сложного, но не забудьте, что буква «у» является плохой, и не встречается в числительных, нужно будет изменить ее весовые характеристики или надеятся, что она не изменится в процессе OCR. - Дробные числа. Решается заменой типа long на double и введением токенов «десятых», «сотых» и т.п… Не забудьте пересмотреть весы букв.
- Распознавание чисел, введенных пользователями. Т.к. при вводе текста вручную мы чаще всего допускаем ошибки, связанные с переТСановкой сиВМолов, следует добавить эту операцию в алгоритм Вагнера-Фишера.
- Поддержка других языков. Вводим новые токены, расширяем таблицу весов.
- Обработка мусора. В некоторых документах на данные налезает печать, качество изображением может быть плохим, ячейка может быть банально пустой. В этом случае в строку попадает мусор, который нужно как-то чистить. Лучшее, что я могу предложить на данный момент – производить предварительную обработку документа перед OCR.
 Мне очень сильно помогло удаление линий таблицы и заливка их цветом, близким к цвету свободного пространства ячейки. Это не решило все проблемы, но улучшило качество распознавания текста с документов, где таблица имела искривления из-за помятости документа или криворукого фотографа. В идеале стоит доворачивать саму ячейку и распознавать ее отдельно, если у вас, конечно, вообще имеется таблица.
Мне очень сильно помогло удаление линий таблицы и заливка их цветом, близким к цвету свободного пространства ячейки. Это не решило все проблемы, но улучшило качество распознавания текста с документов, где таблица имела искривления из-за помятости документа или криворукого фотографа. В идеале стоит доворачивать саму ячейку и распознавать ее отдельно, если у вас, конечно, вообще имеется таблица.
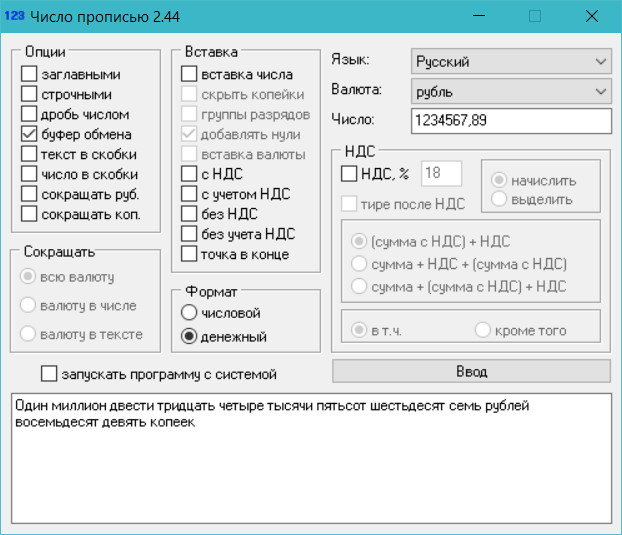
В проекте есть пример консольного приложения, бегущего по файлу samples.txt с примерами для парсера. Вот скриншот результатов:
Оценивать результат поручаю вам, но как по мне, он неплох. Величина ошибки для реальных примеров распознавания не превышает 0.25, хотя я еще не прогонял весь набор имеющихся документов, наверное, не все там будет так гладко.
Что касается последнего раздела, мне всегда было интересно, сколько же это – «дофига». Также программа дала вполне себе адекватный ответ, сколько нужно принимать на посошок (я не употребляю, но все же) и даже точно определила значение древнерусского слова «тьма». И да, в вывод не вошла еще одна мера, которую воспитание добавить не позволило, но программа считает, что она равна тысяче =)
И да, в вывод не вошла еще одна мера, которую воспитание добавить не позволило, но программа считает, что она равна тысяче =)
Изначально в мои планы не входило создание библиотеки, оформить ее я решил исключительно для хабра. Код постарался привести в порядок, но если будете использовать, делайте форк или копию, т.к. скорее всего вам не потребуются жаргонизмы и прочие токены, включенные в примеры.
Сама библиотека написана под .NET Standart 2.0 и C# 7.x, а алгоритмы легко переводятся на другие языки.
На случай возможного расширения библиотеки добавлю состав важных составляющих парсера чисел прописью (пространство имен Genesis.CV.NumberUtils):
- RussianNumber.cs – непосредственно парсер
- RussianNumber.Data.cs – файл с описанием токенов
- RussianNumber.ToString.cs – конвертер числа в текст прописью
- RussianNumberParserOptions.cs – опции парсера
- NumeralLevenshtein.cs – реализация алгоритма Вагнера-Фишера
- NumeralLevenshteinData.
 txt – ресурс, данные весов букв
txt – ресурс, данные весов букв
Использование:
- RussianNumber.ToString(value) – преобразование числа в текст
- RussianNumber.Parse(value, [options]) – преобразование текста в число
Очень надеюсь, что статья не показалась вам скучной даже несмотря на обилие текста. В последнее время у меня появилось множество тем, связанных с компьютерным зрением, о которых есть что рассказать, поэтому хотелось бы узнать мнение насчет такого формата статей. Что стоит добавить или, наоборот, удалить? Что больше интересно вам, читатели, сами алгоритмы или фрагменты кода?
Понравилась статья? Посмотрите другие:
- Классовая сериализация на JavaScript с поддержкой циклических ссылок
- Заполнение текстовых шаблонов данными на основе модели. Реализация на .NET с использованием динамических функций в байт-коде (IL)
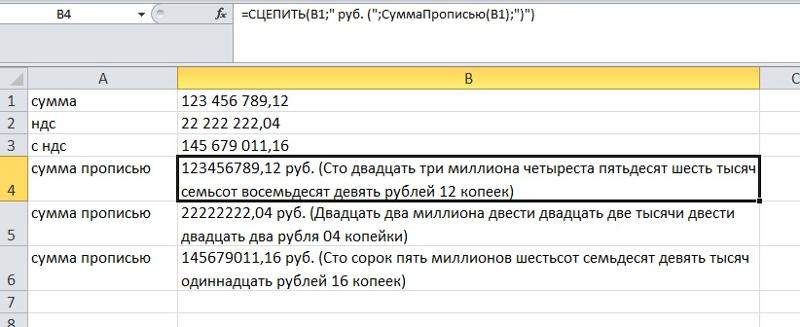
Как сделать сумму прописью с копейками в Эксель: надстройка, формула
При работе с финансовыми документам часто требуется указывать сумму не только в виде числа, но и прописью. Безусловно, такое занятие способно отнять немало времени, особенно, когда речь идет не об одном документе. К тому же, при написании сумм прописью не исключены грамматические ошибки, на поиск и устранение которых также потребуются дополнительные трудозатраты. К счастью, в Эксель можно автоматизировать данный процесс и ниже мы рассмотрим, как именно это сделать.
Безусловно, такое занятие способно отнять немало времени, особенно, когда речь идет не об одном документе. К тому же, при написании сумм прописью не исключены грамматические ошибки, на поиск и устранение которых также потребуются дополнительные трудозатраты. К счастью, в Эксель можно автоматизировать данный процесс и ниже мы рассмотрим, как именно это сделать.
Содержание
- Специальная надстройка NUM2TEXT
- Заключение
Специальная надстройка NUM2TEXT
Смотрите также: “Автозамена в Excel: как отключить, включить, настроить”
В программе Excel не предусмотрен какой-либо специальный инструмент, позволяющий выполнить автоматический перевод цифр в соответствующие текстовые значения. Однако в этом деле может помочь специальная надстройка NUM2TEXT, которая работает через функцию.
Алгоритм действий следующий:
- В верхней строке окна программы кликаем по меню “Файл”.
- В перечне слева выбираем пункт “Параметры”.

- В открывшихся параметрах программы кликаем по разделу “Надстройки”. В нижней части окна щелкаем по кнопке “Перейти” рядом с пунктом “Управление”, значение которого должно быть установлено как “Надстройки Excel”.
- На экране отобразится окно надстроек, в котором нажимаем кнопку “Обзор”.
- Откроется окно обзора, где мы переходим в папку, в которой находится заранее скачанный файл надстройки “NUM2TEXT.xla”. Выбираем его и щелкаем кнопку OK.Примечание: Официального сайта, с которого можно скачать надстройку, к сожалению нет, однако, в интернете ее достаточно легко найти, воспользовавшись поисковой системой. Главное – скачивайте файл с надежных источников, обязательно с расширением “xla”. Не лишним будет после загрузки файла на компьютер проверить его с помощью антивирусной программы.
- Система снова вернет нас в прежнее окно, где мы можем заметить, что в списке надстроек появилась и только что добавленная.
 Ставим флажок напротив нее (если это по какой-то причине не произошло автоматически), затем нажимаем кнопку OK.
Ставим флажок напротив нее (если это по какой-то причине не произошло автоматически), затем нажимаем кнопку OK. - Теперь нам нужно убедиться, что надстройка работает. Для этого пишем в любой незаполненной ячейке случайное число. После этого переходим в другую свободную ячейку и жмем кнопку “Вставить функцию” (fx) слева от строки формул.
- В окне вставки функции выбираем категорию “Полный алфавитный перечень”, находим строку “Сумма_прописью”, щелкаем по ней, затем – по кнопке OK.
- Откроется окно с единственным аргументом функции – “Сумма”. В поле для ввода значения аргумента мы можем написать как обычное число, так и указать адрес ячейки, который печатаем вручную или выбираем в таблице кликом по нужному элементу (при этом, курсор должен находится в поле для ввода информации). После того, как значение аргумента заполнено, щелкаем OK.
- В ячейке с функцией отобразился результат в виде суммы прописью, что и требовалось.
 Причем, если мы поменяем число в исходной ячейке, на которую ссылается функция, значение в финальной ячейке также изменится.
Причем, если мы поменяем число в исходной ячейке, на которую ссылается функция, значение в финальной ячейке также изменится.
Ручной ввод формулы функции
Опытные пользователи довольно часто предпочитают вместо использования вставки функции и последующего заполнения ее аргументов в отдельных окнах сразу писать конечную формулу в ячейке.
В данном случае, формула выглядит следующим образом:
=Сумма_прописью(Сумма)
В качестве аргумента “Сумма”, как мы ранее уже отметили, может быть указано как конкретное число, так и ссылка на ячейку.
Например, вот как выглядит финальная формула с числом 21: =Сумма_прописью(21).
После того, как она набрана в нужной ячейке, нам остается только нажать Enter, чтобы получить результат.
Или же мы можем вместо числа указать адрес ячейки: =Сумма_прописью(B3).
После нажатия клавиши Enter мы также получаем результат в виде суммы прописью в ячейке с формулой.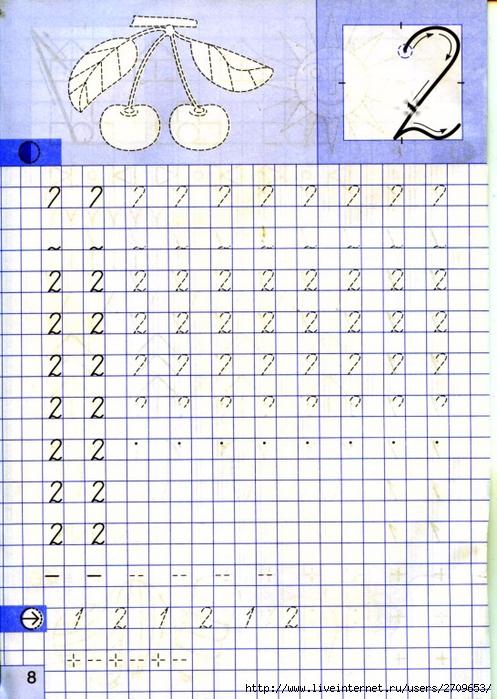
Заключение
Несмотря на то, что в Эксель по умолчанию не предусмотрена функция, позволяющая перевести числовое значение в сумму прописью, тем не менее, выполнить данную задачу в программе можно, установив специальную надстройку. Данный процесс не займет много времени и не требует особых пользовательских навыков.
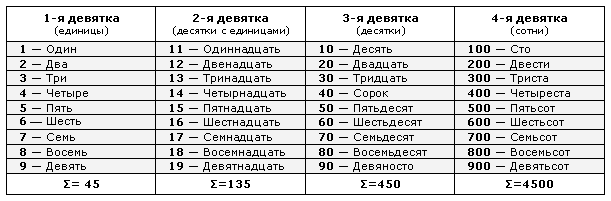
номеров — Руководство по стилю Microsoft
Твиттер LinkedIn Фейсбук Эл. адрес
- Статья
- 5 минут на чтение
Будьте последовательны
в вашем использовании чисел. Когда вы пишете о числах, используемых в
примеры или пользовательский интерфейс, продублируйте их точно так, как они отображаются в пользовательском интерфейсе. В
все остальное содержимое, следуйте приведенным ниже инструкциям.
В
все остальное содержимое, следуйте приведенным ниже инструкциям.
Цифры и слова
В основном тексте указывайте целые числа от нуля до девяти и используйте цифры для 10 или больше. Можно использовать цифры от нуля до девяти, когда у вас ограниченное пространство, например, в таблицах и пользовательском интерфейсе.
Примеры
10 хранителей экрана
пять баз данных
нулевая вероятность
7 990 000
1 000Укажите по буквам от нуля до девяти и используйте цифры от 10 или больше для обозначения дней, недель и других единиц времени.
Примеры
семь лет
28 дней
12 часовЕсли для одного элемента требуется число, используйте числа для всех других элементов этого типа.
Примеры
В одной статье 16 страниц, в другой 7 страниц, а в третьей всего 5 страниц.
Microsoft Inspire появится всего через месяц и 12 дней.
Когда два числа, относящиеся к разным вещам, должны стоять вместе, используйте цифру для одного и расшифруйте другое.
Пример
пятнадцать 20-страничных статейНе начинайте предложение с числительного. Добавьте модификатор перед числом или запишите число, если вы не можете переписать предложение. Начинать элементы списка с цифр — нормально — рассудите сами.
Примеры
Включено более 10 приложений.
Включено одиннадцать приложений.В этих случаях используйте цифры.
| Используйте цифры для | Примеры |
|---|---|
| Измерения расстояния, температуры, объема, размера, веса, пикселей, точек и т. д., даже если число меньше 10. | 3 фута, 5 дюймов 1,76 фунта 80 × 80 пикселей 0,75 грамма 3 сантиметра 3 см |
Номер, который предлагается ввести клиенту. | Введите 5 . |
| Круглое число от 1 миллиона и выше. | 7 миллионов |
| Размеры. Расшифруйте как , за исключением размеров плитки, разрешения экрана и размера бумаги. Для них используйте знак умножения (×). Используйте пробел до и после знака умножения. | Кабель длиной 10 футов Плитка 4 × 4 Бумага 8,5 × 11 дюймов 1280 × 1024 |
| Время суток. Включите AM или PM. Исключение Не используйте цифры для 12∶00 . Используйте 901:15, полдень или , полночь вместо этого. Включите часовой пояс, если вы обсуждаете событие, и клиенты за пределами местного часового пояса могут его увидеть. Отметки времени в пользовательском интерфейсе и на веб-сайтах обычно автоматически отображают местное время и дату. | 10:45 18:30 Встреча в полдень. Событие начинается в 17:00 по тихоокеанскому времени.  Дата меняется в полночь. |
| Проценты, какими бы маленькими они ни были. Используйте цифру плюс 90 115 процентов 90 116, чтобы указать процент. Используйте процентов , если не указано количество. | Должно быть доступно не менее 50% системных ресурсов. Только 1 процент тестовой группы не смог выполнить задание. Должен быть доступен большой процент системных ресурсов. |
| Координаты таблиц или рабочих листов и нумерованных разделов документов. | ряд 3, столбец 4 том 2 глава 10 часть 5 шаг 1 |
Запятые в цифрах
Используйте запятые в числах, состоящих из четырех и более цифр.
Примеры
1 024 долл. США
1 093 МБ
Исключение При обозначении лет, пикселей или бод используйте запятые только в том случае, если число состоит из пяти или более цифр.
Примеры
2500 г. до н.э.
до н.э.
10 000 лет до н.э.
1920 × 1080 пикселей
10 240 × 4320 пикселей
9600 бод
14 400 бод
Не используйте запятые в номерах страниц, адресах или после запятой в десятичных дробях.
Примеры
Стр. 1091
15601 NE 40 TH Street
1,06377 Единицы
Числа в датах
Не используйте ординальные номера, такие как . Первые или октября- . . Вместо этого используйте цифру: 1 июня, 28 октября.
Общий совет Во избежание путаницы всегда указывайте название месяца по буквам. Позиции месяца и дня зависят от страны. Например, 12.06.2017 может быть 12 июня 2017 г. или 6 декабря 2017 г.
Телефонные номера
Используйте дефисы, а не круглые скобки, точки, пробелы или что-либо еще, чтобы разделить части телефонного номера.
Пример 612-555-0175
Общий совет Информацию о том, как форматировать телефонные номера в регионе за пределами США и Канады, см. в руководстве по стилю локализации для этого региона.
в руководстве по стилю локализации для этого региона.
Отрицательные числа
Образуйте отрицательное число с помощью короткого тире, а не дефиса:
Пример
–79
Составные числа
Составные числа расставляйте через дефис при написании.
Примеры
двадцать пять шрифтов
двадцать первый день
Дроби и десятичные дроби
Выражайте дроби словами, символами или десятичными знаками, в зависимости от того, что наиболее подходит.
В таблицах выравнивайте десятичные знаки по запятой.
Добавляйте ноль перед запятой для десятичных дробей меньше единицы, если клиенту не будет предложено ввести значение.
Примеры
0,5 см
введите .75″Не используйте числа, разделенные косой чертой, для выражения дробей.
Исключение Когда уравнение встречается в тексте, можно использовать косую черту между числителем и знаменателем.
 Или в Microsoft Word перейдите на вкладку Вставить и выберите Уравнение для автоматического форматирования уравнения.
Или в Microsoft Word перейдите на вкладку Вставить и выберите Уравнение для автоматического форматирования уравнения.
Пример
½ + ½ = 1Расставьте дроби по буквам. Соедините числитель и знаменатель дефисом, если ни один из них уже не содержит дефис.
Примеры
одна треть страницы
две трети заполнены
три шестьдесят четвертыхВ измерения, где единица измерения прописана, используйте множественное число Форма, когда количество представляет собой десятичную дробь. Используйте только форму единственного числа когда количество равно 1.
Примеры
0,5 дюйма
0 дюймов
1 дюйм
5 дюймов
Порядковые номера
Всегда указывайте порядковые номера по буквам.
Примеры
первый ряд
двадцать первая годовщинаНе используйте порядковые номера, например первое июня, для дат.
Не добавлять – ly к порядковому номеру, как в сначала или во вторую .
Диапазоны чисел
В большинстве случаев используйте от и от до для описания диапазона чисел.
Пример
с 9 до 17Исключения
Используйте короткое тире в диапазоне страниц или там, где не хватает места, например, в таблицах и пользовательском интерфейсе. Например, 2016–2020 и страницы 112–120.
Используйте от до несколько раз. Например, с 10:00 до 14:00.Не используйте из перед диапазоном, обозначенным коротким тире, например, 10–15 .
Сокращения
В общем, не сокращайте тысяч, миллионов, и миллиардов как K, M, и B. Запишите тысяч,
миллионов, 90 116 и 90 115 миллиардов, 90 116 или используйте все число.
Примеры
В компании Fabrikam, Inc. работает более 65 000 человек.
Общие затраты предприятия: 300 000 часов и 30 миллионов долларов в год
В пользовательском интерфейсе избегайте сокращений, если только место не слишком ограничено для написания числа.
Общий совет Машинный перевод может неправильно перевести эти сокращения. Кроме того, сокращенная форма может быть недоступен или может быть длиннее на целевом языке, поэтому оставьте место для расширения в локализованном контенте.
Если вы должны использовать сокращения, следуйте этим рекомендациям:
- Используйте заглавные буквы K, M, и B.
- Не ставьте пробел между номером и аббревиатурой.
- Используйте десятичную форму числа только в том случае, если это действительно сэкономит место. В частности, избегайте использования десятичной дроби.
с K — 8.21K имеет то же количество символов, что и 8 210.

См. также
Сбор терминов даты и времени
Сбор терминов единиц измерения
Сбор терминов битов и байтов
Дефисы и дефисы
Проценты, проценты
Дефисы и дефисы
Обратная связь
Просмотреть все отзывы о странице
Проверка на неправильные цифры в тексте (Microsoft Word)
Обратите внимание: Эта статья написана для пользователей следующих версий Microsoft Word: 2007, 2010 и 2013. Если вы используете более раннюю версию (Word 2003 или более раннюю), этот совет может вам не подойти . Чтобы просмотреть версию этого совета, написанную специально для более ранних версий Word, щелкните здесь: Проверка неправильных чисел в тексте.
Автор: Allen Wyatt (последнее обновление: 7 апреля 2017 г.)
Этот совет относится к Word 2007, 2010 и 2013
Средство проверки грамматики, входящее в состав Word, является достаточно мощным, когда дело доходит до проверки стиля вашего письма. Одна из вещей, которую вы можете проверить в Word, — правильно ли вы используете числа в своем тексте. Обычно следует указывать любое число десять или меньше (например, «девять грузовиков» или «три офицера»). Если число больше десяти, оно должно быть выражено цифрами (например, «47 карандашей» или «12 пенни»).
Одна из вещей, которую вы можете проверить в Word, — правильно ли вы используете числа в своем тексте. Обычно следует указывать любое число десять или меньше (например, «девять грузовиков» или «три офицера»). Если число больше десяти, оно должно быть выражено цифрами (например, «47 карандашей» или «12 пенни»).
По умолчанию Word не проверяет правильность использования чисел. Однако вы можете изменить эту функцию Word, выполнив следующие действия:
- Откройте диалоговое окно «Параметры Word». (В Word 2007 нажмите кнопку «Офис» и выберите «Параметры Word». В Word 2010 и Word 2013 откройте вкладку «Файл» на ленте и нажмите «Параметры».)
- Щелкните параметр Проверка правописания в левой части диалогового окна. (См. рис. 1.)
- Нажмите кнопку Настройки. Word отображает диалоговое окно «Параметры грамматики». (См. рис. 2.)
- Прокрутите список опций, пока не найдете опцию Числа. Убедитесь, что он отмечен.
- Нажмите «ОК», чтобы закрыть диалоговое окно «Параметры грамматики».
- Нажмите «ОК», чтобы закрыть диалоговое окно «Параметры Word».
Рис. 1. Параметры проверки правописания в диалоговом окне «Параметры Word».
Рисунок 2. Диалоговое окно «Параметры грамматики».
Диалоговое окно «Параметры грамматики».
Как и в случае с большинством других инструментов проверки грамматики, вы не должны полагаться исключительно на эту конкретную функцию проверки для исправления всех ваших ошибок. На самом деле существуют довольно сложные правила, которым должны следовать писатели и редакторы при использовании чисел в тексте. Для получения дополнительной информации обратитесь к хорошему руководству по стилю, например к Чикагскому руководству по стилю .
WordTips — ваш источник недорогого обучения работе с Microsoft Word.
(Microsoft Word — самая популярная в мире программа для обработки текстов.)
Этот совет (7837) относится к Microsoft Word 2007, 2010 и 2013. Вы можете найти версию этого совета для старого интерфейса меню Word здесь: Проверка на наличие неверных цифр в тексте .
Биография автора
Аллен Вятт
На его счету более 50 научно-популярных книг и множество журнальных статей, Аллен Вятт является всемирно признанным автором. Он является президентом Sharon Parq Associates, компании, предоставляющей компьютерные и издательские услуги. Узнайте больше об Аллене…
Первое и последнее слово в Word! Бестселлер Для чайников Автор Дэн Гукин возвращается к своей обычной веселой и дружелюбной прямоте, чтобы показать вам, как ориентироваться в Word 2013. Тратьте больше времени на работу и меньше на попытки разобраться во всем! Выезд Word 2013 для чайников уже сегодня!
Подписаться
БЕСПЛАТНАЯ УСЛУГА: Получайте подобные советы каждую неделю в WordTips, бесплатном информационном бюллетене по продуктивности. Введите свой адрес и нажмите «Подписаться».
Просмотреть последний информационный бюллетень.
(Ваш адрес электронной почты никому никогда не передается.