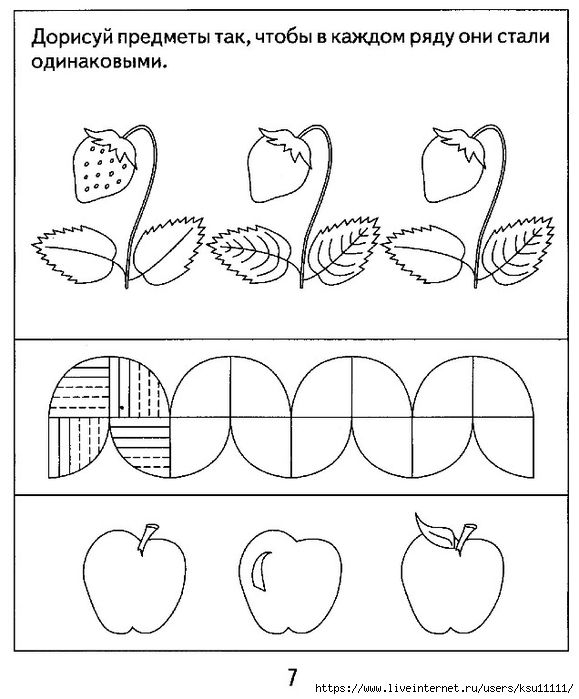
Логические графические задачи: Логические задачи для 1 класса с ответами и решениями, развивающие задания на логику для детей 7-8 лет
Решение логических задач графическим способом
- Климанова Анастасия Владимировна, преподаватель
Разделы: Информатика
Тип урока: комбинированный.
Цель и задачи урока:
- познакомить обучающихся с графическим способом решения логических задач,
- закрепить полученные знания при решении логических задач,
- повысить степень восприятия информации.
Требования к знаниям и умениям:
- Обучающиеся должны знать: способы решения логических задач.
- Обучающиеся должны уметь: применять свои знания
при решении логических задач.

Обеспечение: мультимедийный комплект, презентация «Решение логических задач графическим способом» (Приложение 1).
План
1. Организационный момент.
2. Актуализация знаний.
3. Сообщение нового материала.
4. Первичное закрепление.
5. Подведение итогов.
ХОД УРОКА
– На прошлых уроках мы познакомились с
различными способами решения логических задач.
– Какие способы решения логических задач вы
знаете?
Ответ:
– табличный
– с помощью системы уравнений
– Рассматривая алгебру высказываний, мы
сопоставляли ее с алгеброй чисел. Обратимся к
сравнению еще раз. В школьной алгебре для решения
уравнений и систем уравнений широко
используется графический метод.
При решении логических задач очень часто полезно
вычертить «дерево логических условий».
«Вырастим» логические деревья на простых примерах. Выращивание любого дерева начинается с рассмотрения исходной формулы.
Дизъюнкции (логической сумме) на логическом дереве будет соответствовать «разветвление» ветвей.
Конъюнкции (логическому произведению) на выращиваемом дереве будет соответствовать «следование» ветвей друг за другом (Приложение 1).
Задание 1. Построим логические выражения в виде простейших деревьев:
а) F = A & (B + С)
б) F = (A + В) & (B + С)
Построение происходит на доске одним из
обучающихся. Результат проверяется с помощью
демонстрации решения в презентации (
Задание 2. Решите задачу.
В соревнованиях по информатике на первенство колледжа участвуют Аня, Валя, Тамара и Даша. Болельщики высказали предположения о возможных победителях:
1) Аня будет второй, Даша – четвертой,
2) второй будет Тома, Даша – третьей,
3) первой будет Тома, Валя – второй,
По окончании соревнований оказалось, что в каждом предположении только одно из высказываний истинно, другое – ложно. Какое место на соревнованиях заняла каждая из девушек, если все они оказались на разных местах?
Решение.
Запишем каждое высказывание в буквенном виде:
1) Аня будет второй, Даша – четвертой
2) второй будет Тома, Даша – третьей
3) первой будет Тома, Валя – второй
Учтем, что в каждом предположении только одно из высказываний истинно, другое – ложно, получим:
Для решения данной задачи составим систему уравнений:
Поскольку между строками матрицы стоит
операция конъюнкция каждое уравнение будет
«вырастать» из предыдущего. Построим дерево и
проанализируем полученные варианты (Приложение
1).
Построим дерево и
проанализируем полученные варианты (Приложение
1).
Анализ решения проводится с помощью электронной презентации (Приложение 1)
В качестве домашнего задания обучающимся предлагается решить задачи по индивидуальным карточкам (вариантам) и придумать свою логическую задачу.
Подведение итогов урока
– На сегодняшнем уроке мы актуализировали знания по теме «Решение логических задач» и научились решать задачи графическим способом.
Графические организаторы в решении логических задач
Дубова Алёна Владимировна
Арзамасский филиал Нижегородского госуниверситета им. Н.И. Лобачевского
студентка 3 курса очной формы обучения
Аннотация
Данная статья посвящена обзору графических организаторов, используемых при решении логических задач. Задачи на соответствие можно решать различными способами, но именно применение графических организаторов дает логичность, наглядность, а значит, и уверенность в правильности решения задачи.
Задачи на соответствие можно решать различными способами, но именно применение графических организаторов дает логичность, наглядность, а значит, и уверенность в правильности решения задачи.
Ключевые слова: графические организаторы, задачи на соответствие, логические задачи, метод графов, метод таблиц
Dubova Alena Vladimirovna
Arzamas branch of N.Novgorod State University
3rd year student of full-time training
Abstract
This paper reviews the graphic organizers used in solving logic tasks. The different ways of solving tasks presented and discussed. But only graphic organizers really had show that the answer is correct. They make the process of solving clear and understandable for all.
Keywords: graph method, graphic organizers, logic tasks, table method, tasks of congruence
Библиографическая ссылка на статью:
Дубова А.В. Графические организаторы в решении логических задач // Исследования в области естественных наук.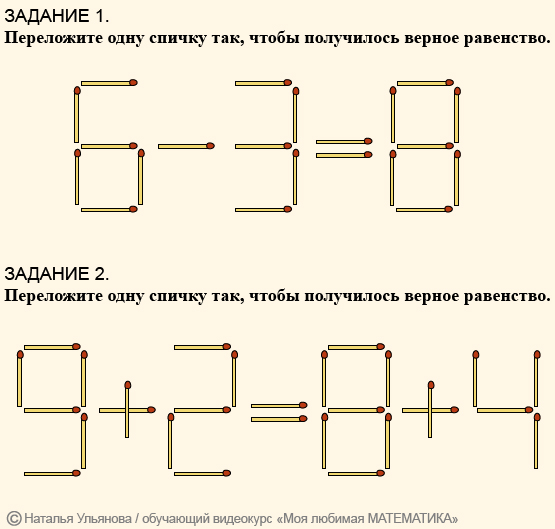
Известно множество различных методов решения задач на соответствие между множествами, но основными являются следующие методы:
– метод рассуждений,
– метод таблиц,
– метод графов.[1]
Для облегчения решения задач выше перечисленными методами используют графические организаторы. Перечислим некоторые из них:
– таблица,
– совмещенная таблица,
– граф,
– схема
Рассмотрим применение графических организаторов при решении логических задач на соответствие между множествами.
Организатор таблица
Этот графический организатор применяется для решения двухмерных логических задач.
Задача 1. Профессии.
В небольшом городке живут пятеро друзей: Иванов, Петров, Сидоров, Гришин и Алексеев. Профессии у них разные: один- маляр, другой – мельник, третий плотник, четвертый почтальон, пятый – парикмахер. [2]
[2]
- Петров и Гришин никогда не держали в руках малярной кисти.
- Иванов и Гришин все пытаются посетить мельницу, на которой работает их товарищ.
- Петров и Иванов живут в одном доме с почтальоном.
- Иванов и Сидоров каждое воскресенье играют в городки с плотником и маляром.
- Петров брал билеты на футбол для себя и мельника.
Определите профессии каждого из друзей?
Решение.
Построим таблицу.
Таблица 1 – Незаполненная таблица
| мельник | плотник | почтальон | парикмахер | ||
| Иванов | |||||
| Петров | |||||
| Сидоров | |||||
| Гришин | |||||
| Алексеев |
Из первого утверждения понятно, что Петров и Гришин не маляры.
Решение становится очевидным, когда заполняется таблица, согласно полученным результатам.
Таблица 2 –Таблица решения
| маляр | мельник | плотник | почтальон | парикмахер | |
| Иванов | – | – | – | – | + |
| Петров | – | + | – | – | |
| Сидоров | – | + | – | – | – |
| Гришин | – | – | – | + | – |
| Алексеев | + | – | – | – | – |
Ответ: Профессии друзей: Иванов работает парикмахером, Петров – плотником, Сидоров – мельником, Гришин – почтальоном, а Алексеев – маляром.
Организатор совмещенная таблица
При решении трехмерных логических задач на соответствие используют совмещенную таблицу, она строится из нескольких обычных таблиц.
Задача 2. Три дочери.
Три дочери писательницы Дорис Кей – Джуди, Айрис и Линда – тоже очень талантливы. Они приобрели известность в разных видах искусств – пении, балете и кино. Все они живут в разных городах, поэтому Дорис часто звонит им в Париж, Рим и Чикаго. Известно, что:
- Джуди живет не в Париже, а Линда – не в Риме;
- Парижанка не снимается в кино;
- Та, кто живет в Риме, певица;
- Линда равнодушна к балету. [3]
Решение.
Составим таблицу, в ней нужно учесть, что речь идет о трех множествах: имен, видов искусств и городов. Из первого условия можно поставить минусы на пересечении столбцов Джуди, Париж и Линда, Рим. Также можно установить из условий 1 и 3, что Линда не певица. Из условия 4 она равнодушна к балету. Следовательно, можно поставить плюс в клетке Линда, кино. После этого ясно, что кино не занимаются все остальные, расставляем минусы в таблице. Из условия 2 находим, что Линда не парижанка. В Париже может жить только Айрис (ставим плюс), минусы будут в клетках Айрис, Рим и Айрис, Чикаго. В столбце Рим уже два минуса, то есть можно установить, что там живет Джуди. И из условия 3 она певица. Оставшееся занятие: балет достается Айрис.
Следовательно, можно поставить плюс в клетке Линда, кино. После этого ясно, что кино не занимаются все остальные, расставляем минусы в таблице. Из условия 2 находим, что Линда не парижанка. В Париже может жить только Айрис (ставим плюс), минусы будут в клетках Айрис, Рим и Айрис, Чикаго. В столбце Рим уже два минуса, то есть можно установить, что там живет Джуди. И из условия 3 она певица. Оставшееся занятие: балет достается Айрис.
Таблица 3 – Совмещенная таблица
Ответ: Джуди достигла известности в пении и живет в Риме; Линда проживает в Чикаго и занимается балетом; Айрис- балет, Париж.
Организатор граф
Для решения задач на соответствие типа «Кто есть кто?» достаточно эффективно можно использовать графы. Элементы множеств обозначаются вершинами графа, а отношения между ними – ребрами графа. При этом получается k-дольный граф, где k – число множеств в задаче.
Задача 3. Соревнование по фехтованию.
Соревнование по фехтованию.
Артем, Петр, Андрей участвовали в соревнованиях по шахматам и заняли первые три места. Какое место занял каждый из них, если Петр занял не второе и не третье, а Андрей не третье?
Решение.
Пусть вершины первой доли графа – имена шахматистов, а вершины второй доли – места, которые они заняли.
Введем обозначения:
По условию задачи, сразу можно сделать вывод, что Петр занял первое место. Следовательно, Андрей занял второе, а Артем – третье место.
Ответ: Петр – первое место, Андрей- второе место, Артем- третье место.
Организатор схема
Для решения логических задач на соответствие также используют такой графический организатор, как схема. Она дает наглядность и простоту решения задачи, но в то же время она дает уверенности в правильности решения.
Задача 4. Сосуды.
В бутылке, стакане, кувшине и банке находятся молоко, лимонад, квас и вода. Известно, что вода и молоко не в бутылке; сосуд с лимонадом стоит между кувшином и сосудом с квасом; в банке не лимонад и не вода; стакан стоит между банкой и сосудом с молоком. В каком сосуде находится каждая из жидкостей? [4]
В каком сосуде находится каждая из жидкостей? [4]
Решение.
Введем обозначения:
1) Так как вода и молоко находятся не в бутылке, следовательно, в бутылке квас или лимонад.
2) В банке находится не лимонад и не вода, следовательно, в банке квас или молоко
3) Сосуд с лимонадом стоит между кувшином и сосудом с квасом, значит, в кувшине находится не лимонад и не квас, следовательно, там молоко или вода
4) Стакан стоит около банки и сосуда с молоком, следовательно, в стакане не молоко, а в банке может находиться молоко, а в стакане может находиться квас, лимонад или вода
5) Из пунктов 2) и 4) получается, что в банке налито молоко.
6) Из пунктов 3) и 5) получается, что в кувшине вода
7) Если бутылка с квасом или лимонадом находится между кувшином с водой и стаканом с квасом, то получается, что в стакане находится квас.
8) Следовательно, лимонад находится в бутылке.
Ответ: Молоко – в банке; квас – в стакане; лимонад – в бутылке; вода – в кувшине.
В заключение отметим, что решение приведённых задач возможно и без графических организаторов. Можно попытаться просто строить рассуждения, решать методом перебора. Однако использование графических организаторов значительно упрощает решение, даёт ясность, чёткость, строгость, а, следовательно, и уверенность в правильности полученного ответа задачи.
Библиографический список
- Сангалова М.Е. Курс лекций по математической логике. – Арзамас: Арзамас. гос. пед. ин-т, 2006. 98 с.
- В помощь школьнику. URL: http://booklisting.ru/resheniya-po-predmetam/informatika/v-gorode-zhivut-5-druzej-ivanov-petrov-sidorov-grishin-alekseev-proffessii-u-nix-raznye-odin-iz-nix-malyar-vtoroj-melnik-3-plotnik-4-pochtalon-5-par/ (дата обращения 22.05.2014 г.).
- Электронный образовательный ресурс по “Информатике и ИКТ”. URL: http://mir-logiki.ru/log_zadachi_tren (дата обращения 28.
 05.2014 г.).
05.2014 г.). - Narva Vocational Training Centre. URL: http://nvtc.ee/e-oppe/Sidorova/kursus/logic8/__3.html (дата обращения 30.05.2014).
Все статьи автора «Сангалова Марина Евгеньевна»
Решение логических задач табличным и графическим способом
1. РЕШЕНИЕ ЛОГИЧЕСКИХ ЗАДАЧ ТАБЛИЧНЫМ И ГРАФИЧЕСКИМ СПОСОБОМ
учитель информатики и ИКТН.Л. Никитенко
Решение логических задач
графическим способом
Решение логических задач
табличным
Задание группам
Решения
3. ГРАФИЧЕСКИЙ МЕТОД
Английский математик, писатель илогик Чарльз Доджсон (Льюис
Кэрролл):
«Своенравная и непокорная логика
отныне укрощена и обуздана».
4. ГРАФИЧЕСКИЙ МЕТОД
http://to-name.ru/biography/ljuiskerrol.htm5. ГРАФИЧЕСКИЙ МЕТОД
6. ГРАФИЧЕСКИЙ МЕТОД
Лёня, Женя и Миша имеют фамилии Орлов, Соколов иЯстребов. Какую фамилию имеет каждый мальчик, если Женя,
Миша и Соколов – члены математического кружка, а Миша и
Ястребов занимаются музыкой.
Ответ: Лёня Соколов, Миша Орлов,
Женя Ястребов
Лёня
Орлов
Женя
Соколов
Миша
Ястребов
7. ГРАФИЧЕСКИЙ МЕТОД
В редакцию журнала прислали рассказ, повесть, очерк, стихотворение и фельетон,которые написали Анискин, Борискин, Вискин, Грискин и Денискин. Каждый
написал только одно произведение. Вискин думал, что стихотворение сочинил
Борискин. Борискин предполагал, что Грискин написал фельетон, а Анискин повесть. Грискин считал, что Денискин написал повесть, а Вискин – очерк. Анискин
думал, что Борискин написал рассказ, а стихотворение сочинил Грискин.
В результате оказалось, что все они ошибались в своих предположениях. Кто что
написал?
А
Б
Р
П
Д
В
Г
С
О
Ф
8. ТАБЛИЧНЫЙ МЕТОД
Друзья Миша, Иван, Веня, Юра и Дима должны поехать в разныегорода А, Б, В, Г, Д, Е. При этом: Миша может ехать только в А, Б,
Д; Иван может ехать только в Б и Г; Веня может ехать только один и
в В; Юра не может ехать вместе с Иваном; Дима может ехать только
с Мишей и Веней, но не в Д.
 В каком городе мог быть каждый из них, если
В каком городе мог быть каждый из них, еслиоказалось, что вдвоем они не были ни в одном городе.
Миша
А
Б
В
Г
Д
Е
Иван
Веня
Юра
Дима
9. ТАБЛИЧНЫЙ МЕТОД
Друзья Миша, Иван, Веня, Юра и Дима должны поехать в разныегорода А, Б, В, Г, Д, Е. При этом: Миша может ехать только в А, Б,
Д; Иван может ехать только в Б и Г; Веня может ехать только один и
в В; Юра не может ехать вместе с Иваном; Дима может ехать только
с Мишей и Веней, но не в Д. В каком городе мог быть каждый из них, если
оказалось, что вдвоем они не были ни в одном городе.
Миша
А
+
Б
+
В
Г
Д
Е
+
Иван
Веня
Юра
Дима
10. ТАБЛИЧНЫЙ МЕТОД
Друзья Миша, Иван, Веня, Юра и Дима должны поехать в разныегорода А, Б, В, Г, Д, Е. При этом: Миша может ехать только в А, Б,
Д; Иван может ехать только в Б и Г; Веня может ехать только один и
в В; Юра не может ехать вместе с Иваном; Дима может ехать только
с Мишей и Веней, но не в Д.
 В каком городе мог быть каждый из них, если
В каком городе мог быть каждый из них, еслиоказалось, что вдвоем они не были ни в одном городе.
Миша
А
+
Б
+
Иван
+
В
Г
Д
Е
+
+
Веня
Юра
Дима
11. ТАБЛИЧНЫЙ МЕТОД
Друзья Миша, Иван, Веня, Юра и Дима должны поехать в разныегорода А, Б, В, Г, Д, Е. При этом: Миша может ехать только в А, Б,
Д; Иван может ехать только в Б и Г; Веня может ехать только один и
в В; Юра не может ехать вместе с Иваном; Дима может ехать только
с Мишей и Веней, но не в Д. В каком городе мог быть каждый из них, если
оказалось, что вдвоем они не были ни в одном городе.
Миша
А
+
Б
+
Иван
+
В
+
Г
Д
Е
Веня
+
+
Юра
Дима
12. ТАБЛИЧНЫЙ МЕТОД
Друзья Миша, Иван, Веня, Юра и Дима должны поехать в разныегорода А, Б, В, Г, Д, Е. При этом: Миша может ехать только в А, Б,
Д; Иван может ехать только в Б и Г; Веня может ехать только один и
в В; Юра не может ехать вместе с Иваном; Дима может ехать только
с Мишей и Веней, но не в Д.
 В каком городе мог быть каждый из них, если
В каком городе мог быть каждый из них, еслиоказалось, что вдвоем они не были ни в одном городе.
Миша
А
+
Б
+
Иван
+
+
Г
Е
Юра
+
В
Д
Веня
+
+
+
+
+
Дима
13. ТАБЛИЧНЫЙ МЕТОД
Друзья Миша, Иван, Веня, Юра и Дима должны поехать в разныегорода А, Б, В, Г, Д, Е. При этом: Миша может ехать только в А, Б,
Д; Иван может ехать только в Б и Г; Веня может ехать только один и
в В; Юра не может ехать вместе с Иваном; Дима может ехать только
с Мишей и Веней, но не в Д. В каком городе мог быть каждый из них, если
оказалось, что вдвоем они не были ни в одном городе.
Миша
А
+
Б
+
Иван
Е
Дима
+
+
+
+
Г
Юра
+
В
Д
Веня
+
+
+
+
+
+
14. ТАБЛИЧНЫЙ МЕТОД
Друзья Миша, Иван, Веня, Юра и Дима должны поехать в разныегорода А, Б, В, Г, Д, Е. При этом: Миша может ехать только в А, Б,
Д; Иван может ехать только в Б и Г; Веня может ехать только один и
в В; Юра не может ехать вместе с Иваном; Дима может ехать только
с Мишей и Веней, но не в Д.
 В каком городе мог быть каждый из них, если
В каком городе мог быть каждый из них, еслиоказалось, что вдвоем они не были ни в одном городе.
Миша
Иван
А
+
–
Б
+
+
В
Веня
Юра
Дима
+
+
+
–
+
+
+
–
–
–
Г
–
1
Д
+
–
+
–
+
Е
15. ТАБЛИЧНЫЙ МЕТОД
Друзья Миша, Иван, Веня, Юра и Дима должны поехать в разныегорода А, Б, В, Г, Д, Е. При этом: Миша может ехать только в А, Б,
Д; Иван может ехать только в Б и Г; Веня может ехать только один и
в В; Юра не может ехать вместе с Иваном; Дима может ехать только
с Мишей и Веней, но не в Д. В каком городе мог быть каждый из них, если
оказалось, что вдвоем они не были ни в одном городе.
Миша
Иван
А
+
Б
+
В
Веня
Юра
Дима
–
+
+
+
–
+
–
+
+
+
–
–
–
Г
–
1
Д
+
–
Е
–
–
+
–
1
–
16. ТАБЛИЧНЫЙ МЕТОД
Друзья Миша, Иван, Веня, Юра и Дима должны поехать в разныегорода А, Б, В, Г, Д, Е.
 При этом: Миша может ехать только в А, Б,
При этом: Миша может ехать только в А, Б,Д; Иван может ехать только в Б и Г; Веня может ехать только один и
в В; Юра не может ехать вместе с Иваном; Дима может ехать только
с Мишей и Веней, но не в Д. В каком городе мог быть каждый из них, если
оказалось, что вдвоем они не были ни в одном городе.
Миша
Иван
Веня
Юра
Дима
А
+
–
–
+
+
Б
+
+
–
–
+
В
–
–
1
+
+
Г
–
1
–
–
–
Д
+
–
–
+
–
Е
–
–
–
1
–
17. ТАБЛИЧНЫЙ МЕТОД
Друзья Миша, Иван, Веня, Юра и Дима должны поехать в разныегорода А, Б, В, Г, Д, Е. При этом: Миша может ехать только в А, Б,
Д; Иван может ехать только в Б и Г; Веня может ехать только один и
в В; Юра не может ехать вместе с Иваном; Дима может ехать только
с Мишей и Веней, но не в Д. В каком городе мог быть каждый из них, если
оказалось, что вдвоем они не были ни в одном городе.
Миша
Иван
Веня
Юра
Дима
А
+
–
–
+
+
Б
+
+
–
–
+
В
–
–
1
+
+
Г
–
1
–
–
–
Д
1
–
–
+
–
Е
–
–
–
1
–
18. ТАБЛИЧНЫЙ МЕТОД
Друзья Миша, Иван, Веня, Юра и Дима должны поехать в разныегорода А, Б, В, Г, Д, Е. При этом: Миша может ехать только в А, Б,
Д; Иван может ехать только в Б и Г; Веня может ехать только один и
в В; Юра не может ехать вместе с Иваном; Дима может ехать только
с Мишей и Веней, но не в Д. В каком городе мог быть каждый из них, если
оказалось, что вдвоем они не были ни в одном городе.
Дима может ехать в А или Б, так как туда никто не едет.
Миша
Иван
Веня
Юра
Дима
А
+
–
–
+
1
Б
+
+
–
–
1
В
–
–
1
+
+
Г
–
1
–
–
–
Д
1
–
–
+
–
Е
–
–
–
1
–
19.
 ЗАДАНИЕ ГРУППАМ1. Найти ошибку в решении задачи:
ЗАДАНИЕ ГРУППАМ1. Найти ошибку в решении задачи:В один ряд стоят 5 домов, в которых живут люди разных
национальностей. Француз выращивает яблони. Ему 40 лет. Тот, кто
живет в центре, играет на скрипке. Англичанин выращивает груши.
Швед, который играет на трубе, живет сразу слева от 40-летнего. Сразу
справа от 45-летнего живет тот, который занимается плаванием. Немец –
прыгун в длину. 30-летний и играющий на рояле – соседи. В саду у
теннисиста растут черешни. Поляк выращивает вишни
и живет
непосредственно правее от того, кто увлекается плаванием. Тот, кто
играет на ударных – бегун. Гитарист – сосед того, в саду которого вишни.
35-летний живет с краю. Скрипач выращивает абрикосы. 30-летний и 35летний – ближайшие соседи и очень дружны. Бегун всегда совершает
утреннюю пробежку по своему яблоневому саду. Кому из них 50 лет? Кто
играет в гольф?
2. Дорисуйте необходимые связи между объектами и дайте ответ
20. РЕШЕНИЕ ЗАДАЧИ 1
скрипкарояль
труба
француз
немец
поляк
швед
англичанин
ударные
гитара
+
+
+
+
+
21.
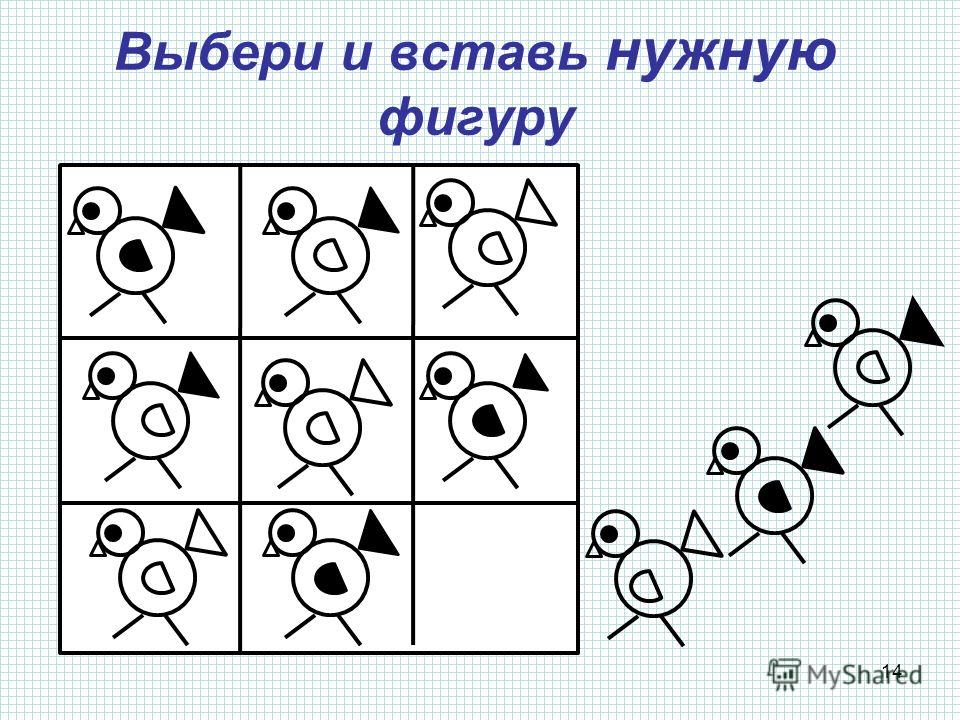 РЕШЕНИЕ ЗАДАЧИ 2
РЕШЕНИЕ ЗАДАЧИ 222. ДОМАШНЕЕ ЗАДАНИЕ
Задача:Однажды в лагере за круглым столом оказалось пятеро ребят из Перми,
Соликамска, Кунгура, Чернушки и Осы: Юра, Толя, Леша, Коля и Витя.
Пермяк сидел между осинцем и Витей, соликамец – между Юрой и Толей,
а напротив него сидели Чернушанин и Алеша. Коля никогда не был в
Соликамске, а Юра не был в Перми и Осе, осинец с Толей регулярно
переписываются в «аське». Определить, в каком городе живет каждый
из ребят?
Жизнь треугольника — логический конвейер NVIDIA возможно, пришло время обновить основную графическую архитектуру под ним. Ферми был первым Графический процессор NVIDIA, реализующий полностью масштабируемый графический движок, и его базовая архитектура могут быть обнаружены как у Кеплера, так и у Максвелла. Следующая статья и особенно «сжатый изображение конвейера знаний» ниже должно служить в качестве учебника, основанного на различных общедоступных материалы, такие как технические документы или руководства GTC по архитектуре графического процессора.
 эта статья
фокусируется на графической точке зрения на то, как работает GPU, хотя некоторые принципы, такие как
то, как выполняется программный код шейдера, одинаково для вычислений.
эта статья
фокусируется на графической точке зрения на то, как работает GPU, хотя некоторые принципы, такие как
то, как выполняется программный код шейдера, одинаково для вычислений.- Fermi Whitepaper
- Kepler Whitepaper
- Maxwell Whitepaper
- Fast Tessellated Rendering on Fermi GF100
- Programming Guidelines and GPU Architecture Reasons Behind Them
Pipeline Architecture Image
GPUs are super parallel work distributors
Why вся эта сложность? В графике нам приходится иметь дело с усилением данных, которое создает множество
переменных рабочих нагрузок. Каждый вызов отрисовки может генерировать разное количество треугольников. Количество
вершин после отсечения отличается от того, из чего изначально были сделаны наши треугольники. После отбраковки задней грани и глубины не всем треугольникам могут понадобиться пиксели на экране. Размер экрана треугольника может означать, что он требует миллионы пикселей или вообще не требует.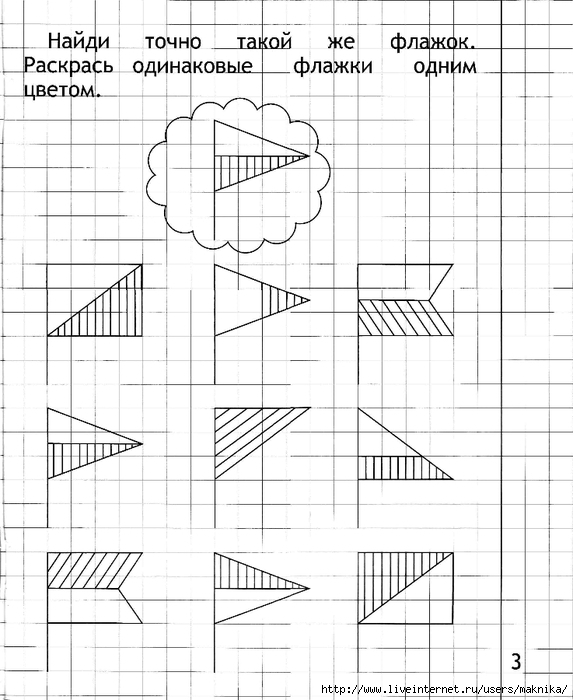
Как следствие, современные графические процессоры позволяют своим примитивам (треугольникам, линиям, точкам) следовать логическому конвейеру, а не физическому конвейеру. В старые времена, до появления унифицированной архитектуры G80 (вспомните аппаратное обеспечение DX9, ps3, xbox360), конвейер был представлен на чипе с различными этапами, и работа проходила через него один за другим. G80, по сути, повторно использовал некоторые единицы для вычислений как вершинных, так и фрагментных шейдеров, в зависимости от нагрузки, но по-прежнему имел последовательный процесс для примитивов/растеризации и так далее. С Fermi конвейер стал полностью параллельным, что означает, что чип реализует логический конвейер (шаги, через которые проходит треугольник) за счет повторного использования нескольких механизмов на чипе.
Допустим, у нас есть два треугольника A и B. Части их работы могут быть на разных этапах логического конвейера.
A уже был преобразован и нуждается в растрировании. Некоторые из его пикселей могут работать с пиксельным шейдером.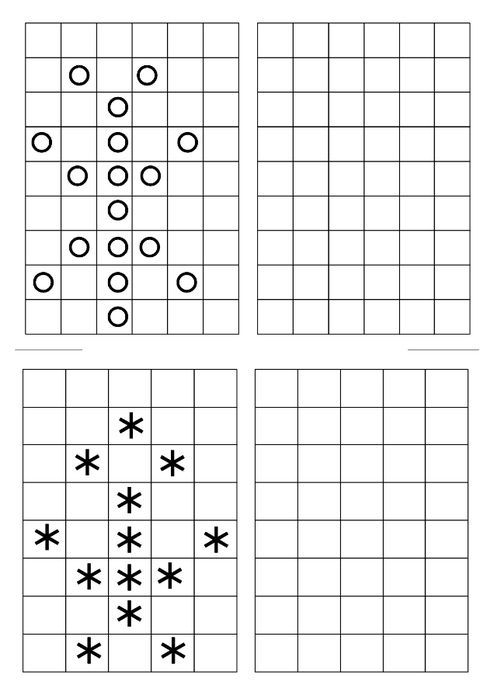 инструкции уже есть, в то время как другие отбрасываются буфером глубины (Z-cull), другие могут быть уже
записываются в фреймбуфер, а некоторые могут ждать. И рядом со всем этим, мы могли бы получать
вершин треугольника B. Таким образом, хотя каждый треугольник должен пройти логические шаги, многие из них могут быть
активно перерабатываются на разных этапах их жизни. Задача (получить треугольники drawcall на экране)
разделить на множество более мелких задач и даже подзадач, которые могут выполняться параллельно. Каждая задача назначена на
ресурсы, которые доступны, что не ограничивается задачами определенного типа (параллельное затенение вершин
к затенению пикселей).
инструкции уже есть, в то время как другие отбрасываются буфером глубины (Z-cull), другие могут быть уже
записываются в фреймбуфер, а некоторые могут ждать. И рядом со всем этим, мы могли бы получать
вершин треугольника B. Таким образом, хотя каждый треугольник должен пройти логические шаги, многие из них могут быть
активно перерабатываются на разных этапах их жизни. Задача (получить треугольники drawcall на экране)
разделить на множество более мелких задач и даже подзадач, которые могут выполняться параллельно. Каждая задача назначена на
ресурсы, которые доступны, что не ограничивается задачами определенного типа (параллельное затенение вершин
к затенению пикселей).
Представьте реку, которая расходится веером. Параллельные конвейерные потоки, независимые друг от друга, каждый на своей собственной временной шкале некоторые могут разветвляться больше, чем другие. Если бы мы кодировали блоки графического процессора цветом на основе треугольника или вызывали отрисовку, над которой он сейчас работает, это были бы многоцветные мерцающие огни 🙂
Архитектура графического процессора
Так как Fermi у NVIDIA похожая принципиальная архитектура. Существует Giga Thread Engine , который управляет всей текущей работой. Графический процессор разделен на несколько GPC (кластер обработки графики), каждый из которых имеет несколько SM (потоковый мультипроцессор) и один растровый процессор . В этом процессе существует множество взаимосвязей, в первую очередь Crossbar , который позволяет выполнять перенос работы между GPC или другими функциональными блоками, такими как подсистемы ROP (блок вывода рендеринга).
Существует Giga Thread Engine , который управляет всей текущей работой. Графический процессор разделен на несколько GPC (кластер обработки графики), каждый из которых имеет несколько SM (потоковый мультипроцессор) и один растровый процессор . В этом процессе существует множество взаимосвязей, в первую очередь Crossbar , который позволяет выполнять перенос работы между GPC или другими функциональными блоками, такими как подсистемы ROP (блок вывода рендеринга).
Работа, о которой думает программист (выполнение шейдерной программы), выполняется на SM. Он содержит множество ядер , которые выполняют математические операции для потоков. Один поток может быть вершинным или пиксельным шейдером.
призыв например. Эти ядра и другие блоки управляются Warp Scheduler , которые управляют группой
из 32 потоков в качестве основы и передать инструкции для выполнения диспетчерским подразделениям . Логика кода обрабатывается планировщиком, а не внутри самого ядра, которое просто видит что-то вроде “суммировать регистр 4234 с регистром 4235 и сохранить в 4230” от диспетчера. Ядро само по себе довольно тупое по сравнению с процессором, где ядро довольно умное. GPU выводит интеллектуальность на более высокий уровень, он выполняет работу всего ансамбля (или нескольких, если хотите).
Логика кода обрабатывается планировщиком, а не внутри самого ядра, которое просто видит что-то вроде “суммировать регистр 4234 с регистром 4235 и сохранить в 4230” от диспетчера. Ядро само по себе довольно тупое по сравнению с процессором, где ядро довольно умное. GPU выводит интеллектуальность на более высокий уровень, он выполняет работу всего ансамбля (или нескольких, если хотите).
Сколько из этих блоков фактически находится на GPU (сколько SM на GPC, сколько GPC…) зависит от сама конфигурация чипа. Как вы можете видеть выше, GM204 имеет 4 GPC с каждым 4 SM, но Tegra X1, например, имеет 1 GPC и 2 SM, оба с дизайном Maxwell. Сам дизайн SM (количество ядер, блоков команд, планировщиков…) также менялся с течением времени от поколения к поколению (см. первое изображение) и помог сделать чипы настолько эффективными, что их можно масштабировать от высокопроизводительного настольного компьютера до ноутбука. мобильный.
Логический конвейер
Для простоты некоторые детали опущены. Мы предполагаем, что вызов отрисовки ссылается на некоторый index-
и вершинный буфер, который уже заполнен данными и живет в DRAM графического процессора и использует только вершины.
и пиксельный шейдер (GL: фрагментный шейдер).
Мы предполагаем, что вызов отрисовки ссылается на некоторый index-
и вершинный буфер, который уже заполнен данными и живет в DRAM графического процессора и использует только вершины.
и пиксельный шейдер (GL: фрагментный шейдер).
- Программа делает вызов отрисовки в графическом API (DX или GL). Это достигает драйвера в какой-то момент, что делает немного проверка, чтобы проверить, являются ли вещи «законными», и вставляет команду в кодировке, читаемой графическим процессором, внутри проталкивающий буфер . Здесь может возникнуть множество узких мест на стороне ЦП, поэтому важно, чтобы программисты хорошо использовали API и методы, которые используют мощь современных графических процессоров.
- Через некоторое время или явных вызовов “flush”, драйвер буферизировал достаточно работы в pushbuffer и отправляет ее на
обрабатывается GPU (с некоторым участием ОС). Хост-интерфейс графического процессора принимает команды, которые обрабатываются через внешний интерфейс .
- Мы начинаем распределение нашей работы в примитивном распределителе , обрабатывая индексы в индексном буфере и генерируя рабочие пакеты треугольников, которые мы отправляем в несколько GPC.
- Внутри GPC Poly Morph Engine одного из SM обеспечивает выборку данных вершин из индексов треугольников ( Vertex Fetch ).
- После получения данных внутри SM запланированы варпы из 32 потоков, которые будут работать над вершинами.
- Планировщик варпа SM выдает инструкции для всего варпа по порядку. Потоки выполняют каждую инструкцию в режиме блокировки и могут быть замаскированы индивидуально, если они не должны активно ее выполнять. Причин для такой маскировки может быть несколько. Например, когда текущая инструкция является частью ветви «if (true)», а данные, относящиеся к потоку, оценены как «false», или когда критерий завершения цикла был достигнут в одном потоке, но не в другом.
 Следовательно, наличие большого количества расхождений ветвей в шейдере может значительно увеличить время, затрачиваемое на все потоки в варпе. Нити не могут продвигаться по отдельности, только как варп! Деформации, однако, независимы друг от друга.
Следовательно, наличие большого количества расхождений ветвей в шейдере может значительно увеличить время, затрачиваемое на все потоки в варпе. Нити не могут продвигаться по отдельности, только как варп! Деформации, однако, независимы друг от друга. - Инструкция варпа может быть выполнена сразу или может занять несколько ходов отправки. Например, SM обычно имеет меньше единиц для загрузки/сохранения, чем выполнение основных математических операций.
- Поскольку некоторые инструкции выполняются дольше, чем другие, особенно загрузка памяти, планировщик деформации
может просто переключиться на другой варп, не ожидающий памяти. Это ключевая концепция того, как GPU
преодолевают задержку чтения памяти, они просто переключают группы активных потоков. Чтобы сделать это
переключение очень быстрое, все потоки, управляемые планировщиком, имеют свои собственные регистры в файле регистров.
Чем больше регистров требуется шейдерной программе, тем меньше места занимают потоки/деформации.
.jpeg?size=l) Чем меньше деформации мы можем
переключаться между ними, тем менее полезная работа, которую мы можем выполнять, ожидая завершения инструкций (в первую очередь извлекается из памяти).
Чем меньше деформации мы можем
переключаться между ними, тем менее полезная работа, которую мы можем выполнять, ожидая завершения инструкций (в первую очередь извлекается из памяти). - Как только варп выполнил все инструкции вершинного шейдера, его результаты обрабатываются Viewport Transform . Треугольник обрезается объемом пространства отсечения и готов к растеризации. Мы используем кэши L1 и L2 для всех этих межзадачных коммуникационных данных.
- Теперь становится интересно, наш треугольник вот-вот расколется и, возможно, покинет GPC, в котором он сейчас живет. Ограничивающая рамка треугольника используется для определения того, какие растровые механизмы должны работать с ним, поскольку каждый механизм покрывает несколько фрагментов экрана. Он отправляет треугольник одному или нескольким GPC через Перекладина распределения работы . Теперь мы фактически разделили наш треугольник на множество более мелких задач.
- Настройка атрибута в целевом SM гарантирует, что интерполянты (например, выходные данные, которые мы сгенерировали в вершинном шейдере) находятся в формате, удобном для пиксельного шейдера.
- Raster Engine GPC работает с полученным треугольником и генерирует информацию о пикселях для тех разделы, за которые он отвечает (также обрабатывает отбраковку задней поверхности и Z-отбор).
- Снова мы объединяем 32 пиксельных потока, или, лучше сказать, 8 пиксельных квадратов 2×2, что является наименьшим
unit, с которым мы всегда будем работать в пиксельных шейдерах. Этот квадрат 2×2 позволяет нам вычислять производные
для таких вещей, как фильтрация текстуры MIP-карты (большое изменение координат текстуры в квадроциклах вызывает
более высокий мип). Те потоки в квадрате 2×2, места выборки которых на самом деле не покрывают треугольник, маскируются (gl_HelperInvocation). Один из планировщиков деформации локального SM будет управлять задачей затенения пикселей.

- Та же игра с инструкциями планировщика деформации, которая была у нас на логическом этапе вершинного шейдера, теперь выполняется в потоках пиксельного шейдера. Пошаговая обработка особенно удобна, потому что мы можем получить доступ к значениям внутри пиксельного квадрата почти бесплатно, так как все потоки гарантированно чтобы их данные вычислялись до одной и той же точки инструкции (NV_shader_thread_group).
- Мы уже на месте? Наш пиксельный шейдер почти завершил расчет цветов для записи в rendertargets.
и у нас также есть значение глубины. На этом этапе мы должны принять во внимание исходный порядок треугольников в API.
прежде чем мы передадим эти данные в одну из подсистем ROP (блок вывода рендеринга), которая сама по себе имеет несколько
единицы РОП. Здесь выполняется проверка глубины, смешивание с фреймбуфером и так далее. Эти операции должны происходить
атомарно (одновременно устанавливается один цвет/глубина), чтобы гарантировать, что у нас нет цвета одного треугольника и глубины другого треугольника.
 значение, когда оба покрывают один и тот же пиксель.
NVIDIA обычно применяет сжатие памяти, чтобы уменьшить требования к пропускной способности памяти, что увеличивает «эффективную» пропускную способность (см.80 ПДФ).
значение, когда оба покрывают один и тот же пиксель.
NVIDIA обычно применяет сжатие памяти, чтобы уменьшить требования к пропускной способности памяти, что увеличивает «эффективную» пропускную способность (см.80 ПДФ).
Фух! мы закончили, мы записали некоторый пиксель в rendertarget. Я надеюсь, что эта информация была полезной чтобы понять часть работы/потока данных внутри графического процессора. Это также может помочь понять другой побочный эффект почему синхронизация с процессором действительно вредна. Приходится ждать, пока все закончится, и нет отправляется новая работа (все блоки становятся бездействующими), это означает, что при отправке новой работы требуется некоторое время, пока все снова полностью загружено, особенно на больших графических процессорах.
На изображении ниже вы можете увидеть, как мы визуализировали модель CAD и раскрасили ее с помощью различных SM или деформации.
идентификаторы, которые участвовали в изображении (NV_shader_thread_group). Результат не будет кадрово-когерентным,
поскольку распределение работы будет варьироваться от кадра к кадру. Сцена визуализировалась с использованием множества вызовов отрисовки,
некоторые из которых также могут обрабатываться параллельно (используя NSIGHT, вы можете увидеть некоторые из этих вызовов отрисовки
также параллелизм).
Результат не будет кадрово-когерентным,
поскольку распределение работы будет варьироваться от кадра к кадру. Сцена визуализировалась с использованием множества вызовов отрисовки,
некоторые из которых также могут обрабатываться параллельно (используя NSIGHT, вы можете увидеть некоторые из этих вызовов отрисовки
также параллелизм).
Дополнительная литература
- Путешествие по графическому конвейеру Фабиан Гизен
- Руководство по оптимизации производительности и стоящая за ним архитектура графического процессора Паулюс Мицкевичюс
- Гранат: полностью масштабируемая графическая архитектура описывает концепцию параллельных этапов и распределения работы между ними.
графических процессоров в диспетчере задач
Брайан Лэнгли
21 июля 2017 г. 2 0
Сообщение ниже принадлежит Стиву Проновосту, нашему ведущему инженеру, ответственному за планировщик графического процессора и диспетчер памяти.
Мы рады представить поддержку данных о производительности графического процессора в диспетчере задач. Это одна из функций, о которых вы часто просили, и мы прислушались. Графический процессор наконец-то дебютирует в этом почтенном инструменте повышения производительности. Чтобы сразу увидеть эту функцию, вы можете присоединиться к программе предварительной оценки Windows. Или вы можете дождаться обновления Windows Fall Creator.
Чтобы понять все данные о производительности графического процессора, полезно знать, как Windows использует графические процессоры. В этом блоге подробно рассматриваются эти детали и объясняется, как оживают данные о производительности графического процессора диспетчера задач. Этот блог будет немного длинным, но, тем не менее, мы надеемся, что он вам понравится.
Системные требования
В Windows графический процессор предоставляется через модель драйвера дисплея Windows (WDDM). В основе WDDM лежит графическое ядро, которое отвечает за абстрагирование, управление и совместное использование графического процессора всеми запущенными процессами (каждое приложение имеет один или несколько процессов). Графическое ядро включает в себя планировщик графического процессора (VidSch), а также диспетчер видеопамяти (VidMm). VidSch отвечает за планирование различных механизмов графического процессора для процессов, желающих их использовать, а также за арбитраж и определение приоритетов доступа между ними. VidMm отвечает за управление всей памятью, используемой графическим процессором, включая как VRAM (память на вашей видеокарте), так и страницы основной DRAM (системной памяти), к которым непосредственно обращается графический процессор. Экземпляр VidMm и VidSch создается для каждого графического процессора в вашей системе.
Графическое ядро включает в себя планировщик графического процессора (VidSch), а также диспетчер видеопамяти (VidMm). VidSch отвечает за планирование различных механизмов графического процессора для процессов, желающих их использовать, а также за арбитраж и определение приоритетов доступа между ними. VidMm отвечает за управление всей памятью, используемой графическим процессором, включая как VRAM (память на вашей видеокарте), так и страницы основной DRAM (системной памяти), к которым непосредственно обращается графический процессор. Экземпляр VidMm и VidSch создается для каждого графического процессора в вашей системе.
Данные в Диспетчере задач собираются непосредственно из VidSch и VidMm. Таким образом, данные о производительности графического процессора доступны независимо от того, какой API используется, будь то Microsoft DirectX API, OpenGL, OpenCL, Vulkan или даже проприетарный API, такой как Mantle от AMD или CUDA от Nvidia. Кроме того, поскольку VidMm и VidSch являются фактическими агентами, принимающими решения об использовании ресурсов графического процессора, данные в диспетчере задач будут более точными, чем многие другие утилиты, которые часто делают все возможное, чтобы делать разумные предположения, поскольку они не имеют доступа к фактическим данным. данные.
данные.
Для данных о производительности графического процессора диспетчера задач требуется драйвер графического процессора, поддерживающий WDDM версии 2.0 или выше. WDDMv2 был представлен в исходном выпуске Windows 10 и поддерживается примерно 70% пользователей Windows 10. Если вы не уверены, какую версию WDDM использует ваш драйвер графического процессора, вы можете использовать утилиту dxdiag, которая входит в состав Windows, чтобы выяснить это. Чтобы запустить dxdiag, откройте меню «Пуск» и просто введите dxdiag.exe. Посмотрите на вкладке Display в Drivers для драйвера модели . К сожалению, если вы используете более старый графический процессор WDDMv1.x, диспетчер задач не будет отображать для вас данные графического процессора.
Вкладка «Производительность»
На вкладке «Производительность» вы найдете данные о производительности, агрегированные по всем процессам, для всех ваших графических процессоров с поддержкой WDDMv2.
Графические процессоры и ссылки
На левой панели вы увидите список графических процессоров в вашей системе. Номер графического процессора — это концепция диспетчера задач, которая используется в других частях пользовательского интерфейса диспетчера задач для краткой ссылки на конкретный графический процессор. Таким образом, вместо того, чтобы говорить Intel(R) HD Graphics 530 для ссылки на графический процессор Intel на приведенном выше снимке экрана, мы можем просто сказать GPU 0. Когда присутствует несколько графических процессоров, они упорядочены по их физическому местоположению (шина PCI/устройство/устройство). функция).
Windows поддерживает объединение нескольких графических процессоров для создания более крупного и мощного логического графического процессора. Связанные графические процессоры совместно используют один экземпляр VidMm и VidSch и, как следствие, могут очень тесно взаимодействовать, включая чтение и запись в VRAM друг друга. Вы, вероятно, будете более знакомы с коммерческим названием наших партнеров для связи, а именно Nvidia SLI и AMD Crossfire. Когда графические процессоры связаны друг с другом, диспетчер задач назначит номер ссылки для каждой ссылки и идентифицирует графические процессоры, которые являются ее частью. Диспетчер задач позволяет вам проверять состояние каждого физического графического процессора по ссылке, позволяя вам наблюдать, насколько хорошо ваша игра использует преимущества каждого графического процессора.
Использование графического процессора
В верхней части правой панели вы найдете информацию об использовании различных ядер графического процессора.
Движок графического процессора представляет собой независимый блок кремния на графическом процессоре, который можно планировать и который может работать параллельно друг с другом. Например, механизм копирования может использоваться для передачи данных, в то время как механизм 3D используется для 3D-рендеринга. Хотя 3D-движок также можно использовать для перемещения данных, простые операции передачи данных могут быть перенесены на механизм копирования, что позволяет 3D-движку работать над более сложными задачами, повышая общую производительность. В этом случае и механизм копирования, и механизм 3D будут работать параллельно.
VidSch отвечает за арбитраж, определение приоритетов и планирование каждого из этих ядер графического процессора в различных процессах, желающих их использовать.
Важно отличать движки GPU от ядер GPU. Движки графического процессора состоят из ядер графического процессора. Например, 3D-движок может иметь 1000 ядер, но эти ядра сгруппированы вместе в сущность, называемую движком, и планируются как группа. Когда процесс получает квант времени механизма, он получает возможность использовать все базовые ядра этого механизма.
Некоторые графические процессоры поддерживают сопоставление нескольких ядер с одним и тем же базовым набором ядер. Хотя эти механизмы также могут быть запланированы параллельно, в конечном итоге они совместно используют базовые ядра. Концептуально это похоже на гиперпоточность на ЦП. Например, 3D-движок и вычислительный движок могут фактически полагаться на один и тот же набор унифицированных ядер. В таком сценарии ядра либо пространственно, либо временно разделены между ядрами при выполнении.
На рисунке ниже показаны механизмы и ядра гипотетического графического процессора.
По умолчанию Диспетчер задач выберет 4 ядра для отображения. Диспетчер задач выберет движки, которые он считает наиболее интересными. Однако вы можете решить, какой движок вы хотите наблюдать, щелкнув имя движка и выбрав другой из списка движков, предоставляемых графическим процессором.
Количество движков и использование этих движков зависит от GPU. Драйвер графического процессора может принять решение о декодировании определенного медиаклипа с помощью механизма декодирования видео, в то время как другой клип, использующий другой видеоформат, может полагаться на вычислительный механизм или даже на комбинацию нескольких механизмов. С помощью нового диспетчера задач вы можете запустить рабочую нагрузку на GPU, а затем посмотреть, какие механизмы будут ее обрабатывать.
На левой панели под именем графического процессора и в нижней части правой панели вы увидите совокупный процент использования графического процессора. Здесь у нас было несколько различных вариантов того, как мы могли бы агрегировать загрузку по движкам. Средняя загрузка по движкам казалась обманчивой, поскольку, например, GPU с 10 движками, запускающими игру, полностью загружающую 3D-движок, в сумме составил бы 10% общего использования! Это определенно не то, что хотят видеть геймеры. Мы также могли бы выбрать 3D-движок для представления графического процессора в целом, поскольку он, как правило, является наиболее известным и используемым движком, но это также могло ввести пользователей в заблуждение. Например, воспроизведение видео при некоторых обстоятельствах может вообще не использовать 3D-движок, и в этом случае совокупное использование графического процессора будет отображаться как 0% во время воспроизведения видео! Вместо этого мы решили выбрать процент использования самого загруженного движка в качестве представителя общего использования графического процессора.
Здесь у нас было несколько различных вариантов того, как мы могли бы агрегировать загрузку по движкам. Средняя загрузка по движкам казалась обманчивой, поскольку, например, GPU с 10 движками, запускающими игру, полностью загружающую 3D-движок, в сумме составил бы 10% общего использования! Это определенно не то, что хотят видеть геймеры. Мы также могли бы выбрать 3D-движок для представления графического процессора в целом, поскольку он, как правило, является наиболее известным и используемым движком, но это также могло ввести пользователей в заблуждение. Например, воспроизведение видео при некоторых обстоятельствах может вообще не использовать 3D-движок, и в этом случае совокупное использование графического процессора будет отображаться как 0% во время воспроизведения видео! Вместо этого мы решили выбрать процент использования самого загруженного движка в качестве представителя общего использования графического процессора.
Видеопамять
Ниже графиков двигателей приведены графики использования видеопамяти и сводка. Видеопамять разбита на две большие категории: выделенная и общая.
Видеопамять разбита на две большие категории: выделенная и общая.
Выделенная память представляет собой память, которая зарезервирована исключительно для использования графическим процессором и управляется VidMm. На дискретных графических процессорах это ваша VRAM, память, которая находится на вашей видеокарте. Â Â В интегрированных графических процессорах это объем системной памяти, зарезервированный для графики. Многие интегрированные графические процессоры избегают резервирования памяти для исключительного использования графики и вместо этого предпочитают полагаться исключительно на память, совместно используемую с ЦП, что более эффективно.
Этот небольшой объем памяти, зарезервированной для драйвера, представляет собой зарезервированную память оборудования.
Для встроенных графических процессоров все сложнее. Некоторые интегрированные графические процессоры будут иметь выделенную память, а другие — нет. Некоторые интегрированные графические процессоры резервируют память в прошивке (или во время инициализации драйвера) из основной DRAM. Хотя эта память выделяется из DRAM, совместно используемой с ЦП, она отбирается у Windows и выходит из-под контроля диспетчера памяти Windows (Mm) и управляется исключительно VidMm. Этот тип резервирования обычно не рекомендуется в пользу общей памяти, которая является более гибкой, но в настоящее время она требуется некоторым графическим процессорам.
Хотя эта память выделяется из DRAM, совместно используемой с ЦП, она отбирается у Windows и выходит из-под контроля диспетчера памяти Windows (Mm) и управляется исключительно VidMm. Этот тип резервирования обычно не рекомендуется в пользу общей памяти, которая является более гибкой, но в настоящее время она требуется некоторым графическим процессорам.
Объем выделенной памяти на вкладке производительности представляет собой количество байтов, потребляемых в настоящее время всеми процессами, в отличие от многих существующих утилит, которые показывают объем памяти, запрошенный процессом.
Общая память представляет собой обычную системную память, которая может использоваться как GPU, так и CPU. Эта память является гибкой и может использоваться любым способом, и даже может переключаться туда и обратно в зависимости от рабочей нагрузки пользователя. Как дискретные, так и интегрированные графические процессоры могут использовать общую память.
В Windows есть политика, согласно которой графическому процессору разрешено использовать только половину физической памяти в любой момент времени. Это делается для того, чтобы остальная часть системы имела достаточно памяти для продолжения правильной работы. В системе 16 ГБ графическому процессору разрешено использовать до 8 ГБ этой DRAM в любой момент. Приложения могут выделять гораздо больше видеопамяти, чем это. Â На самом деле, видеопамять полностью виртуализирована в Windows и ограничена только общим пределом фиксации системы (т. е. общей установленной DRAM + размером файла подкачки на диске). VidMm гарантирует, что GPU не превысит половину бюджета DRAM, динамически блокируя и освобождая страницы DRAM. Точно так же, когда поверхности не используются, VidMm со временем освобождает страницы памяти обратно в Mm, чтобы при необходимости их можно было переназначить. Объем общей памяти, потребляемой на вкладке «Производительность», по сути представляет собой объем такой общей системной памяти, который в настоящее время потребляет графический процессор в соответствии с этим ограничением.
Это делается для того, чтобы остальная часть системы имела достаточно памяти для продолжения правильной работы. В системе 16 ГБ графическому процессору разрешено использовать до 8 ГБ этой DRAM в любой момент. Приложения могут выделять гораздо больше видеопамяти, чем это. Â На самом деле, видеопамять полностью виртуализирована в Windows и ограничена только общим пределом фиксации системы (т. е. общей установленной DRAM + размером файла подкачки на диске). VidMm гарантирует, что GPU не превысит половину бюджета DRAM, динамически блокируя и освобождая страницы DRAM. Точно так же, когда поверхности не используются, VidMm со временем освобождает страницы памяти обратно в Mm, чтобы при необходимости их можно было переназначить. Объем общей памяти, потребляемой на вкладке «Производительность», по сути представляет собой объем такой общей системной памяти, который в настоящее время потребляет графический процессор в соответствии с этим ограничением.
Вкладка «Процессы»
На вкладке «Процессы» вы найдете сводную информацию об использовании графического процессора с разбивкой по процессам.
Стоит обсудить, как работает агрегация в этом представлении. Как мы видели ранее, ПК может иметь несколько графических процессоров, и каждый из этих графических процессоров обычно имеет несколько ядер. Добавление столбца для каждой комбинации графического процессора и движка приведет к появлению десятков новых столбцов на обычном ПК, что сделает представление громоздким. Вкладка «производительность» предназначена для того, чтобы дать пользователю быстрый и простой взгляд на то, как его системные ресурсы используются в различных запущенных процессах, поэтому мы хотели, чтобы она была чистой и простой, но при этом предоставляла полезную информацию о графическом процессоре.
Решение, которое мы решили использовать, состоит в том, чтобы отобразить загрузку самого загруженного механизма на всех графических процессорах для этого процесса как представление его общего использования графического процессора. Но если бы это было все, что мы сделали, все равно было бы запутанно. Одно приложение может нагружать 3D-движок на 100 %, а другое — на 100 %. В этом случае оба приложения сообщили бы об общем использовании 100%, что могло бы ввести в заблуждение. Чтобы решить эту проблему, мы добавили второй столбец, который указывает, какой комбинации графического процессора и ядра соответствует отображаемое использование. Мы хотели бы услышать, что вы думаете об этом выборе дизайна.
Одно приложение может нагружать 3D-движок на 100 %, а другое — на 100 %. В этом случае оба приложения сообщили бы об общем использовании 100%, что могло бы ввести в заблуждение. Чтобы решить эту проблему, мы добавили второй столбец, который указывает, какой комбинации графического процессора и ядра соответствует отображаемое использование. Мы хотели бы услышать, что вы думаете об этом выборе дизайна.
Аналогично, сводка использования в верхней части столбца представляет собой максимальное использование всех графических процессоров. Расчет здесь такой же, как и общее использование графического процессора, отображаемое на вкладке производительности.
Вкладка «Подробности»
На вкладке «Подробности» по умолчанию нет информации о графическом процессоре. Но вы можете щелкнуть правой кнопкой мыши заголовок столбца, выбрать «Выбрать столбцы» и добавить либо счетчики использования графического процессора (тот же, что описан выше), либо счетчики использования видеопамяти.
Есть несколько важных моментов, которые следует учитывать при работе с этими счетчиками использования видеопамяти. Счетчики представляют собой общий объем выделенной и общей видеопамяти, используемой в данный момент этим процессом. Это включает в себя как частную память (т. е. память, которая используется исключительно этим процессом), так и общую память между процессами (т. е. память, которая используется совместно с другими процессами, не путать с памятью, разделяемой между ЦП и ГП).
В результате этого добавление памяти, используемой каждым отдельным процессом, даст в сумме объем памяти, превышающий объем памяти, используемый графическим процессором, поскольку память, совместно используемая процессами, будет учитываться несколько раз. Разбивка по процессам полезна, чтобы понять, сколько видеопамяти в настоящее время использует конкретный процесс, но чтобы понять, сколько общей памяти используется графическим процессором, нужно посмотреть на вкладке производительности суммирование, которое правильно учитывает общую память.
Другое интересное последствие этого заключается в том, что некоторые системные процессы, в частности dwm.exe и csrss.exe, которые совместно используют много памяти с другими процессами, будут казаться намного больше, чем они есть на самом деле. Например, когда приложение создает окно верхнего уровня, видеопамять будет выделена для хранения содержимого этого окна. Эта поверхность видеопамяти создается csrss.exe от имени приложения, возможно, отображается в самом процессе приложения и используется совместно с диспетчером окон рабочего стола (dwm.exe), так что окно может быть размещено на рабочем столе. Видеопамять выделяется только один раз, но доступна, возможно, всем трем процессам и появляется на фоне их индивидуального использования памяти. Точно так же цепочка обмена DirectX приложения или визуальный элемент DCOMP (XAML) совместно используются компоновщиком рабочего стола. Большая часть видеопамяти, выделяемой этим двум процессам, на самом деле является результатом того, что приложение создает что-то, что используется совместно с ними, поскольку сами по себе они выделяют очень мало. По этой же причине вы увидите, что они будут расти по мере того, как ваш рабочий стол будет загружен, но имейте в виду, что на самом деле они не потребляют все ваши ресурсы.
По этой же причине вы увидите, что они будут расти по мере того, как ваш рабочий стол будет загружен, но имейте в виду, что на самом деле они не потребляют все ваши ресурсы.
Мы могли бы вместо этого показать разбивку частной памяти для каждого процесса и игнорировать общую память. Однако в результате многие приложения выглядели бы намного меньше, чем они есть на самом деле, поскольку в Windows мы активно используем разделяемую память. В частности, для универсальных приложений типично наличие сложного визуального дерева, которое полностью используется компоновщиком рабочего стола, поскольку это позволяет компоновщику использовать более разумный и эффективный способ рендеринга приложения только тогда, когда это необходимо, и приводит к повышению общей производительности для система. Мы не думали, что скрытие общей памяти будет правильным ответом. Мы также могли бы выбрать отображение private+shared для обычных процессов, но только private для csrss.exe и dwm.exe, но это также было похоже на сокрытие полезной информации для опытных пользователей.
Эта дополнительная сложность является одной из причин, по которой мы не отображаем эту информацию в представлении по умолчанию и оставляем ее для опытных пользователей, которые знают, как ее найти. В конце концов, мы решили использовать прозрачность и пошли на разбивку, включающую как частную, так и общую память между процессами. Это область, в которой мы особенно заинтересованы в обратной связи, и мы с нетерпением ждем ваших мыслей.
Заключительные мысли
Мы надеемся, что вы нашли эту информацию полезной и что она поможет вам получить максимальную отдачу от новых данных о производительности графического процессора диспетчера задач.
Будьте уверены, что команда, стоящая за этой работой, будет внимательно следить за вашими конструктивными отзывами и предложениями, так что продолжайте их поступать! Лучший способ оставить отзыв — через Центр обратной связи. Чтобы запустить Feedback Hub, используйте сочетание клавиш Windows + f. Отправьте свой отзыв (и отправьте нам голосование) в категории Desktop Environment -> Task Manager.
ЦП и ГП | Лучшие варианты использования для каждого
Пурав Чима. 15 сентября 2021 г.
Вам интересно, ЦП или ГП? Мы объясняем, как каждый из них работает, и лучшие варианты использования для каждого из них.
В чем разница между CPU и GPU? ЦП (центральный процессор) — это обобщенный процессор, предназначенный для выполнения самых разнообразных задач. GPU (графический процессор) — это специализированный процессор с расширенными возможностями математических вычислений, идеально подходящий для задач компьютерной графики и машинного обучения.
Что такое центральный процессор (ЦП)?
В основе любого существующего компьютера лежит центральный процессор или ЦП. ЦП выполняет основные задачи обработки в компьютере — буквальное вычисление, которое управляет каждым действием в компьютерной системе.
Компьютеры работают посредством обработки двоичных данных, или единиц и нулей. Чтобы преобразовать эту информацию в программное обеспечение, графику, анимацию и любой другой процесс, выполняемый на компьютере, эти единицы и нули должны работать через логическую структуру ЦП. Это включает в себя основные арифметические, логические функции (И, ИЛИ, НЕ) и операции ввода и вывода. Процессор — это мозг, принимающий информацию, вычисляющий ее и перемещающий туда, куда нужно.
Это включает в себя основные арифметические, логические функции (И, ИЛИ, НЕ) и операции ввода и вывода. Процессор — это мозг, принимающий информацию, вычисляющий ее и перемещающий туда, куда нужно.
В каждом ЦП есть несколько стандартных компонентов, включая следующие:
- Ядра : Центральная архитектура ЦП — это «ядро», в котором происходят все вычисления и логика. Ядро обычно функционирует через так называемый «цикл инструкций», когда инструкции извлекаются из памяти (выборка), декодируются в язык обработки (декодирование) и выполняются через логические элементы ядра (выполнение). Изначально все процессоры были одноядерными, но с распространением многоядерных процессоров мы наблюдаем увеличение вычислительной мощности.
- Кэш-память : Кэш-память — это сверхбыстрая память, встроенная либо в ЦП, либо в материнские платы, предназначенные для ЦП, для облегчения быстрого доступа к данным, которые в данный момент использует ЦП.
 Поскольку процессоры работают так быстро, чтобы выполнять миллионы вычислений в секунду, для этого им требуется сверхбыстрая (и дорогая) память — память, которая намного быстрее, чем хранилище на жестком диске или даже самая быстрая оперативная память.
Поскольку процессоры работают так быстро, чтобы выполнять миллионы вычислений в секунду, для этого им требуется сверхбыстрая (и дорогая) память — память, которая намного быстрее, чем хранилище на жестком диске или даже самая быстрая оперативная память.В любой конфигурации ЦП вы увидите некоторое расположение кэша L1, L2 и/или L3, где L1 является самым быстрым, а L3 — самым медленным. Центральный процессор будет хранить наиболее необходимую информацию в L1, и по мере того, как данные теряют приоритет, они перемещаются в L2, затем в L3, а затем в ОЗУ или на жесткий диск.
- Блок управления памятью (MMU) : MMU управляет перемещением данных между ЦП и ОЗУ во время командного цикла.
- Часы процессора и блок управления : Каждый процессор работает над синхронизацией задач обработки через часы. Тактовая частота ЦП определяет частоту, с которой ЦП может генерировать электрические импульсы, его основной способ обработки и передачи данных, а также скорость работы ЦП.
 Таким образом, чем выше тактовая частота ЦП, тем быстрее он будет работать и быстрее могут выполняться задачи, интенсивно использующие процессор.
Таким образом, чем выше тактовая частота ЦП, тем быстрее он будет работать и быстрее могут выполняться задачи, интенсивно использующие процессор.
Все эти компоненты работают вместе, чтобы обеспечить среду, в которой может иметь место высокоскоростной параллелизм задач. По мере того, как часы ЦП управляют деятельностью, ядра ЦП быстро переключаются между сотнями различных задач в секунду. Вот почему на вашем компьютере можно одновременно запускать несколько программ, отображать рабочий стол, подключаться к Интернету и многое другое.
Центральный процессор отвечает за все действия на компьютере. Когда вы закрываете или открываете программы, ЦП должен отправлять правильные инструкции для получения информации с жесткого диска и запуска исполняемого кода из ОЗУ. Во время игры ЦП обрабатывает графическую информацию для отображения на экране. При компиляции кода ЦП обрабатывает все необходимые вычисления и математические операции.
Что такое графический процессор (GPU)?
Одна из этих задач, графическая обработка, обычно считается одной из наиболее сложных задач обработки для ЦП. Решение этой сложности привело к созданию технологий, выходящих далеко за рамки графики.
Решение этой сложности привело к созданию технологий, выходящих далеко за рамки графики.
Проблема обработки графики заключается в том, что графика требует сложной математики для рендеринга, и эта сложная математика должна выполняться параллельно, чтобы работать правильно. Например, графически насыщенная видеоигра может содержать сотни или тысячи полигонов на экране в любой момент времени, каждый со своим индивидуальным движением, цветом, освещением и т. д. Процессоры не рассчитаны на такую нагрузку. Вот где в игру вступают графические процессоры (GPU).
Графические процессоры по функциям аналогичны ЦП: они содержат ядра, память и другие компоненты. Вместо акцента на переключение контекста для управления несколькими задачами ускорение графического процессора делает упор на параллельную обработку данных с помощью большого количества ядер.
Эти ядра обычно менее мощные по отдельности, чем ядро процессора. Графические процессоры также обычно имеют меньшую совместимость с различными аппаратными API и бездомной памятью. В чем они сильны, так это в параллельной обработке больших объемов обрабатываемых данных. Вместо того, чтобы переключаться между несколькими задачами для обработки графики, графический процессор просто берет пакетные инструкции и выполняет их с большим объемом, чтобы ускорить обработку и отображение.
В чем они сильны, так это в параллельной обработке больших объемов обрабатываемых данных. Вместо того, чтобы переключаться между несколькими задачами для обработки графики, графический процессор просто берет пакетные инструкции и выполняет их с большим объемом, чтобы ускорить обработку и отображение.
Каковы преимущества и недостатки центрального процессора?
Несмотря на то, что графические процессоры все чаще используются для высокопроизводительной обработки, есть несколько причин, по которым большинство современных ПК по-прежнему содержат центральные процессоры.
Некоторые из преимуществ архитектуры ЦП включают следующее:
- Гибкость : ЦП являются гибкими и отказоустойчивыми и могут выполнять множество задач, не связанных с обработкой графики. Благодаря своим возможностям последовательной обработки ЦП может выполнять несколько задач на вашем компьютере в многозадачном режиме. Из-за этого сильный процессор может обеспечить большую скорость для типичного использования компьютера, чем графический процессор.

- Контекстная мощность : В определенных ситуациях ЦП превосходит ГП. Например, ЦП значительно быстрее при обработке нескольких различных типов системных операций (оперативная память, средние вычислительные операции, управление операционной системой, операции ввода-вывода).
- Точность : ЦП может работать с математическими уравнениями среднего диапазона с более высоким уровнем точности. Процессоры могут легче справляться с глубиной и сложностью вычислений, что становится все более важным для конкретных приложений.
- Доступ к памяти : ЦП обычно содержат значительный объем локальной кэш-памяти, что означает, что они могут обрабатывать больший набор линейных инструкций и, следовательно, более сложные системные и вычислительные операции.
- Стоимость и доступность : Процессоры более доступны, широко производятся и экономичны для использования потребителями и предприятиями. Кроме того, производители оборудования по-прежнему создают тысячи моделей материнских плат для размещения широкого спектра процессоров.
CPU также имеют несколько недостатков по сравнению с GPU:
- Параллельная обработка : CPU не могут выполнять параллельную обработку, как GPU, поэтому большие задачи, требующие тысяч или миллионов одинаковых операций, будут ограничивать возможности CPU по обработке данных.
- Медленная эволюция : В соответствии с законом Мура разработка более мощных процессоров в конечном итоге будет замедляться, что означает меньшее количество улучшений из года в год. Распространение многоядерных процессоров несколько смягчило это.
- Совместимость : Не каждая система или программное обеспечение совместимо с каждым процессором. Например, приложения, написанные для процессоров Intel x86, не будут работать на процессорах ARM. Это не такая уж большая проблема, поскольку все больше производителей компьютеров используют стандартные наборы процессоров (см. переход Apple на процессоры Intel), но по-прежнему возникают проблемы между ПК и мобильными устройствами.
Каковы преимущества и недостатки графического процессора?
В то время как центральные процессоры более широко используются для общих вычислений, графические процессоры нашли растущую нишу для пользователей и организаций, стремящихся применять высокопроизводительные вычисления для решения уникальных задач.
Некоторые из преимуществ графического процессора включают следующее:
- Высокая пропускная способность данных : графический процессор состоит из сотен ядер, выполняющих одну и ту же операцию с несколькими элементами данных параллельно. Из-за этого графический процессор может обрабатывать огромные объемы данных через рабочую нагрузку, ускоряя выполнение определенных задач сверх того, с чем может справиться ЦП.
- Массивные параллельные вычисления : В то время как ЦП превосходят более сложные вычисления, графические процессоры преуспевают в обширных вычислениях с многочисленными аналогичными операциями, такими как вычисление матриц или моделирование сложных систем.

Эти два преимущества были основными причинами создания графических процессоров, поскольку оба они способствуют сложной обработке графики. Однако структура графического процессора быстро побудила разработчиков и инженеров применить технологию графического процессора к другим высокопроизводительным приложениям:
- Майнинг биткойнов : Процесс майнинга биткойнов включает использование вычислительной мощности для решения сложных криптографических хэшей. Растущее распространение биткойнов и сложность майнинга биткойнов привели к тому, что биткойн-майнеры внедрили графический процессор для обработки огромных объемов криптографических данных в надежде заработать биткойны.
- Машинное обучение : Нейронные сети, особенно те, которые используются для алгоритмов глубокого обучения, функционируют благодаря способности обрабатывать большие объемы обучающих данных с помощью небольших узлов операций. Графические процессоры для машинного обучения появились, чтобы помочь обрабатывать огромные наборы данных, используемые для обучения алгоритмов машинного обучения и искусственного интеллекта.
- Аналитика и наука о данных : графические процессоры уникально подходят для того, чтобы помочь программам аналитики обрабатывать большие объемы базовых данных из разных источников. Кроме того, эти же графические процессоры могут выполнять вычисления, необходимые для глубоких наборов данных, связанных с такими областями исследований, как науки о жизни (геномное секвенирование).
Помимо этих конкретных нишевых приложений, GPU не справляется с некоторыми задачами:
- Многозадачность : GPU не созданы для многозадачности, поэтому они не имеют большого влияния в таких областях, как вычисления общего назначения.
- Стоимость : хотя цена графических процессоров с годами несколько снизилась, они по-прежнему значительно дороже, чем процессоры. Эта стоимость возрастает еще больше, когда речь идет о графическом процессоре, созданном для конкретных задач, таких как майнинг или аналитика.
- Мощность и сложность : В то время как GPU может обрабатывать большие объемы параллельных вычислений и пропускной способности данных, они испытывают трудности, когда требования к обработке становятся более хаотичными.
 Ветвящиеся логические пути, последовательные операции и другие подходы к вычислениям снижают эффективность GPU.
Ветвящиеся логические пути, последовательные операции и другие подходы к вычислениям снижают эффективность GPU.
WekaIO с аппаратным обеспечением для высокопроизводительных вычислений с графическим процессором
WekaIO специально создан для высокопроизводительных вычислений в таких областях, как машинное обучение, искусственный интеллект, биологические науки и аналитика. Наш подход к вычислениям заключается в оптимизации и расширении возможностей гибридных облачных сред с помощью системы, которая обеспечивает доступность данных, вычислительную мощность и комплексное покрытие для сложных рабочих нагрузок.
Кроме того, Weka поддерживает разработку программного обеспечения с использованием графических процессоров для максимальной производительности. Некоторые пакеты включают использование графических процессоров специально для алгоритмов глубокого обучения и интеллектуального анализа данных. Weka также имеет следующие функции:
- Автомасштабируемое хранилище для высокой производительности
- Локальные и гибридные облачные решения для тестирования и производства
- Лучшая в отрасли производительность GPUDirect (113 Гбит/с для одного DGX-2 и 162 Гбит/с для одного DGX A100)
- Шифрование во время передачи и в состоянии покоя для требований GRC
- Гибкий доступ и управление для периферийных, основных и облачных разработок
- Масштабируемость до эксабайт хранилища для миллиардов файлов
Свяжитесь с нами сегодня, если вы заинтересованы во внедрении облачной среды, которая может использовать технологию графического процессора для расширения ваших рабочих нагрузок облачных вычислений.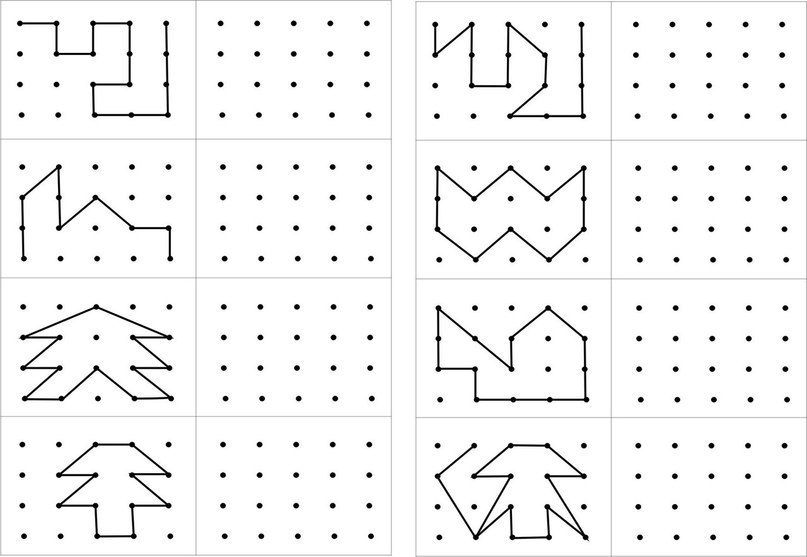
Дополнительные полезные ресурсы
NVIDIA GPUDirect® Storage Plus WekaIO™ обеспечивает больше, чем просто производительность
Ускорение GPU для высокопроизводительных вычислений
Эталонная архитектура NVIDIA и Weka DGX POD
GPU в ИИ, машинном обучении и глубоком обучении
Как GPUDirect Storage ускоряет анализ больших данных
Kubernetes для конвейеров AI/ML с использованием GPU
Почему GPU для машинного обучения ? Полное объяснение
ПОПУЛЯРНЫЕ БЛОГИ ОТ Purav Cheema
Этот веб-сайт хранит файлы cookie на вашем компьютере. Эти файлы cookie используются для сбора информации о том, как вы взаимодействуете с нашим веб-сайтом, и позволяют нам запомнить вас. Мы используем эту информацию, чтобы улучшить и настроить ваш опыт просмотра, а также для аналитики и показателей о наших посетителях как на этом веб-сайте, так и в других средствах массовой информации. Чтобы узнать больше о файлах cookie, которые мы используем, ознакомьтесь с нашей политикой конфиденциальности.