Что такое звуковая модель слова: Звуковая модель слова схема
Звуковая модель слова схема
Идёт приём заявок
Подать заявку
Для учеников 1-11 классов и дошкольников
Учимся составлять звуковую схему слова
Уважаемые родители, для ребят, которые идут в 1 класс, будут очень полезны занятия по составлению звуковой схемы слова.
Давайте попробуем разобраться, как правильно составить звуковую схему слова или звуковую модель слова. Данный вид работы мы также можем назвать звуко-буквенным разбором слова или фонетическим разбором.
Фонетика – раздел науки о языке, в котором изучаются звуки языка, ударение, слог.
Звуки, которые произносит человек, мы называем звуками речи. Звуки речи образуются в речевом аппарате при выдыхании воздуха. Речевой аппарат – это гортань с голосовыми связками, ротовая и носовая полости, язык, губы, зубы, нёбо.
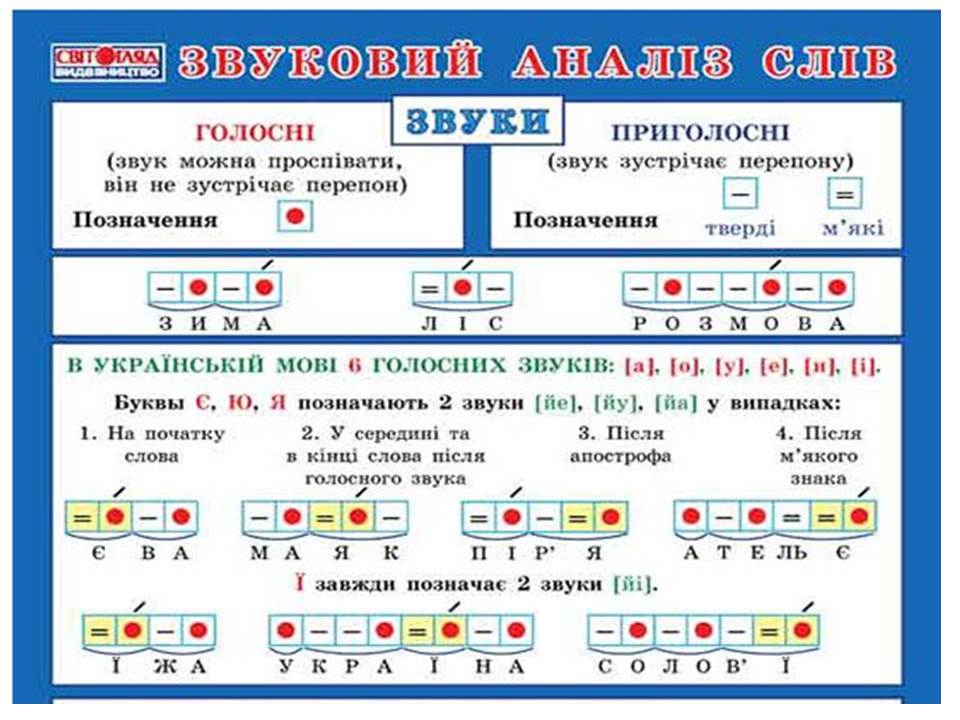
Гласные звуки состоят только из голоса, выдыхаемый воздух проходит через рот свободно, не встречая преграду. Гласные звуки можно долго тянуть, петь.
В русском языке гласных звуков шесть: [а], [о], [у], [э], [ы], [и]. Гласные звуки бывают ударными и безударными.
Гласные звуки мы будем обозначать красным цветом ( условные обозначения для звуков я взяла из программы “Школа России”).
Предлагаем большой выбор школьных рюкзаков для девочек и мальчиков. В нашем магазине вы можете купить школьный рюкзак для первоклассников и для подростков, а также школьные сумки и мешки для обуви.
Когда мы произносим согласные звуки, воздух встречает преграду (губы, зубы, язык). Одни согласные состоят только из шума – это глухие согласные. Другие – из голоса и шума. Это звонкие согласные.
Согласные также делятся на твёрдые и мягкие.
Твёрдые согласные обозначают синим цветом, мягкие – зелёным.
По программе “Школа России” слияние гласного звука с согласным мы обозначаем прямоугольником, разделённым наискосок прямой линией, где снизу закрашиваем согласный, а сверху гласный.
Сделайте из цветного картона или бумаги карточки, чтобы составлять слова. Также понадобятся карточки со знаком ударения и разделительной чертой.
Также понадобятся карточки со знаком ударения и разделительной чертой.
Можно рисовать схемы в тетради в крупную клеточку. Ещё лучше совмещать оба вида работы.
Начинайте работу с простых слов – односложных или двусложных.
Итак, вы сделали карточки и готовы к занятию.
Подумайте, как заинтересовать ребёнка.
Может вы научите составлять слова куклу Машу или любимого зайку?
Или будете отгадывать загадки и составлять схему слова-отгадки?
А может быть слово (карточка или картинка) спрятаны и вы поиграете в игру “холодно-горячо”?
Очень хорошо, если вы придумали что-то интересное и появился стимул к работе.
Сидит дед в сто шуб одет.
Кто его раздевает,
Тот слёзы проливает.
Давай, составим схему слова лук.
1. Делим слово на слоги.
Произносим с хлопком в ладоши – лук. В этом слове 1 слог.
2. Из каких звуков состоит слог?
Произносим протяжно л-у-к.
Первый звук – [л]. Это твёрдый согласный звук. Второй звук – [у]. Это гласный звук. Звуки [л], [у] сливаются вместе, получается слияние [лу]. Выбираем нужную карточку – слияние твёрдого согласного с гласным звуком.
Третий звук [к] – твёрдый согласный. Выбираем карточку для твёрдого согласного.
3. Обозначим звуки буквами. Звук [л] обозначаем буквой “эль”. Звук [у] – буквой “у”. Звук [к] – буквой “ка”.
Ударение в односложных словах не ставим. В слове один гласный звук, значит он ударный.
По программе “Школа России” нет обозначений звонкого и глухого согласного. Поэтому можно проявить фантазию и придумать свои обозначения для звонкого и глухого согласного. Например, в игре “Узнай звук” для обозначения звонкого согласного я выбрала колокольчик, а для глухого согласного – смайлик в наушниках. Картинки можно распечатать и использовать в схеме.
Потренироваться давать характеристику звуку можно в игре.
Дать характеристику звуку вам поможет лента букв.
На ленте очень хорошо видно какие звуки обозначают буквы.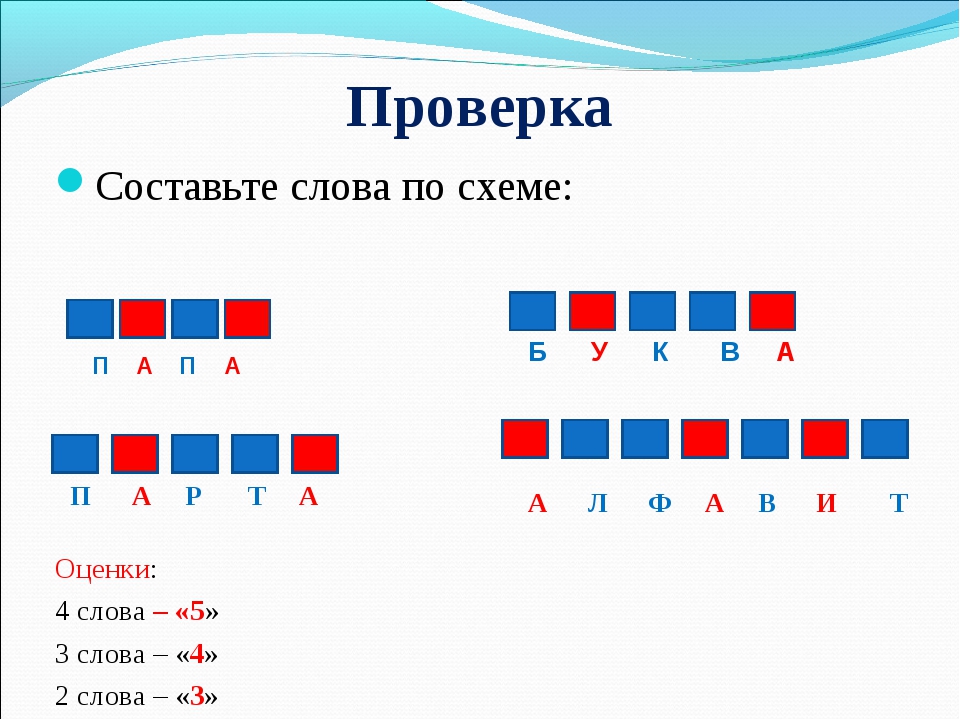
Например, буква “эн” обозначает два звука – твёрдый [н] и мягкий [н’]. Поэтому прямоугольник двух цветов – синего и зелёного. Эти звуки звонкие, поэтому сверху – колокольчик.
Все звуки в верхнем ряду звонкие, а в нижнем – глухие.
Буква “жэ” обозначает один звук – твёрдый звук [ж]. Поэтому прямоугольник полностью синего цвета. Это звонкий звук.
Особое внимание надо обратить на йотированные гласные.
Буквы я, ё, ю, е могут обозначать два звука или один.
Если они стоят в начале слова или после гласного, они обозначают два звука:
я [й’ а], ё [й’ о], ю [й’ у], е [й’ э]
После согласного звука они обозначают один звук: я [а], ё [о], ю [у], е [э].
Составим схему слова Яна.
1. Делим слово на слоги.
В этом слове два слога.
2. Первый слог – я. Это слияние двух звуков – [й’], [а]. Звук [й’] – мягкий согласный, звук [а] – гласный. Выбираем карточку – слияние мягкого согласного и гласного звука.
3. Ставим разделительную черту после первого слога.
3. Второй слог – на. Это слияние двух звуков – [н], [а]. Звук [н] – твёрдый согласный, звук [а] – гласный. Выбираем карточку – слияние твёрдого согласного и гласного звука.
4. Ставим ударение. Находим ударный слог. Говорим слово целиком, выделяя ударный слог. Ударный слог – первый. Чтобы ребёнок понял, что ударение поставлено верно, попробуйте поставить ударение и на второй слог.
5. Обозначаем звуки буквами.
Звуки [й’а] обозначают одной буквой – буквой я.
Звук [н] обозначают буквой “эн”.
Звук [а] обозначают буквой а.
Все условные обозначения звуков в статье взяты из программы “Школа России”. Но для нас самое главное, чтобы ребёнок научился давать характеристику звуку, умел работать с моделями. Если ребёнок научился давать характеристику звуку, то заменить обозначение не составит труда.
модель — слово из 2 слогов: мо-дель. Ударение падает на 2-й слог.
Транскрипция слова: [мад’эл’]
м — [ м ] — согласный, звонкий непарный, сонорный (всегда звонкий) , твёрдый (парный)
о — [ а ] — гласный , безударный
д — [ д’ ] — согласный, звонкий парный, мягкий (парный)
е — [ э ] — гласный , ударный
л — [ л’ ] — согласный, звонкий непарный, сонорный (всегда звонкий) , мягкий (парный)
ь — не обозначает звука
В слове 6 букв и 5 звуков.
Цветовая схема: м о д е л ь
14123 / Слово разобрано с помощью программы. Результат разбора используется вами на свой страх и риск.
Нужен разбор с ударением на другой слог?
Поставьте ударение, кликнув на нужной гласной. Страница обновится и дополнится новым разбором.
м о ́ д е ́ ль
Слова с буквой ё обязательно пишите через ё. Фонетические разборы слов «еж» и «ёж» будут разными!
С началом осени взрослым зачастую приходится садиться за уроки вместе с детьми. Сложно приходится родителям первоклассников, поскольку программа младшей школы быстро забывается, а образовательные стандарты часто меняются. Еще до начала чтения и письма, когда вчерашние дошкольники в 1 классе проходят азбуку, им дают задание составить звуковую схему как слова, так и целого предложения. В таких случаях родителям на помощь приходит интернет с примерами и образцами.
Звуко-буквенный разбор слов
Изучением букв и звуков, их анализом занимается раздел русского языка под названием фонетика. Чтобы разложить слово на звуки, используется транскрипция. Такой разбор именуется фонетическим. Родителям потребуется вспомнить, что такое гласные и согласные буквы, какие звуки им соответствуют, что такое йотированные гласные и чем отличаются буквы первого и второго рядов.
Таблица гласных и согласных звуков русского языка
Найти буквенный ряд можно в книгах для начальных классов или в интернете. Как правило, буквы расположены в две линии. Гласные делятся на обозначающие мягкость и твердость согласных, последние же — на глухие и звонкие, парные и непарные.
Гласные, определяющие твердость: а, э, о, у, ы. Им соответствуют звуки: [а], [э], [о], [у], [ы].
Гласные, обозначающие мягкость: я, е, ё, ю, и. Также их называют йотированными, потому что эти буквы состоят из двух звуков, если стоят в начале, после гласной или после мягкого и твердого знаков. Эти буквы смягчают согласные, стоящие перед ними.
Согласные бывают глухие и звонкие, они образуют шесть пар:
Остальные согласные парными не являются:
Кроме того, есть согласные, которые всегда мягкие или всегда твердые, независимо от следующей за ними гласной:
- Ч, Щ, Й — всегда мягкие.
- Ж, Ш, Ц — всегда твёрдые.
Буквы Ь и Ъ не имеют собственных звуков. Мягкий знак смягчает впереди стоящий согласный, твердый — нет.
Схема букв и звуков русского языка в таблице для первого класса представлена на картинке:
В образовательной программе «Школа России» принято обозначать звуки цветами:
- Гласный — красный цвет;
- Согласный твёрдый — синий;
- Согласный мягкий — зелёный.
Слияние согласной и гласной обозначают прямоугольником, разделенным пополам. Одну часть закрашивают синим или зелёным цветом, вторую — красным. Иногда в этой модели дополнительно обозначаются глухие и звонкие согласные, ударение и деление на слоги.
Примеры
Для графического изображения звукового состава слова можно подобрать цветные карточки. Для облегчения составления схемы в начале целесообразно использовать надписи на картинках. В перспективе можно самостоятельно начертить схематический состав слова в тетради по клеточкам с помощью цветных ручек или карандашей.
Чтобы показать алгоритм составления схемы, лучше начинать со звуковой записи односложных слов с помощью таблички.
Например, слова из трех букв: дуб, кот, мак, лук, жук, рак. Сначала надо написать транскрипцию.
Для слова «дуб» она выглядит так: [дуп]. Далее описать схему, где первые два звука представляют слияние твердой согласной и гласной, а третий — твердый согласный. Теперь надо графически изобразить результат:
- Сначала нарисовать прямоугольник.
Оставшиеся слова также подходят под полученную схему.
Варианты, где одна или обе из согласных мягкие:
- кит, йод — схема такая:
мяч, ель, день — схема следующая:
конь, гусь, рысь, лось, соль — схема:
мышь — учитывая, что буква Ш всегда твердая, получается схема, аналогичная слову «дуб».
Слова из 4 звуков, состоящие из единственного слога:
Стол, слон:
Хлеб, гриб: есть смягчающая гласная
Дверь: есть смягчающая гласная и мягкий знак
Слова из 2 слогов:
Зима, лиса: слова со смягчающей гласной
Утка, окно:
Осел, утюг, ирис: здесь мягкая согласная во втором слоге
Овощ, окунь: на конце есть мягкий знак или всегда мягкая согласная.
Образцы слоговой схемы
При обучении чтению первоклассников учат, как разложить слово на слоги. Для этого достаточно помнить, что слог образует гласная. Например, в слове «лист» один слог, а в слове «листья» — два.
Таким образом, слог может состоять:
- Из одной гласной: Аист, Якорь.
На картинках примеры слов, разложенных на слоги:
- Машина, капуста, улитки, баранки, малина, барабан.
Курица, яблоко, чемодан, солнышко, звёздочка, кубики.
И целое стихотворение про лягушку, разложенное на слоги.
Пример полного разбора слова «Медведь».
Теперь можно попробовать самим разложить слово «Дельфин» на слоги. И решить следующую задачу.
Мотивациялық-қозғаушылық Мотивационно-побудительный | Здравствуйте, ребята! Круг радости. Встанем в круг и поприветствуем друг друга: Как хорошо на свете жить, Как хорошо уметь дружить! Сегодня к нам в гости пришёл Алдар Косе. Он принёс конверт с интересными заданиями. Давайте заглянем в него и узнаем, что там лежит. | Дети в кругу повторяют слова. Приветствуют. Проявляют интерес. | Ұйымдастыру- іздестіру Организационно -поисковый | 1.Работа со звуками. Дидактическая игра «Звук потерялся». – Я буду показывать вам картинки с изображением предметов, и называть их с пропущенным звуком в слове, а вы должны угадать, какой звук я забыла произнести. 2.задание Алдар Косе загадал слова, которые начинаются на слог «ма». 3.задание. Первая часть слова начинается на слог «бу». Придумайте и назовите слова, которые начинаются со слога «бу». 4.задание. Первая часть слова начинается на слог «до». Придумайте и назовите слова, которые начинаются со слога «до». Физкультминутка. Звуковая модель слова. Достаю из конверта карточки со звуками. Раздаю детям. Предлагаю подобрать к каждой звуковой схеме – слово. – У каждого из вас стоит звуковая модель слова. Каждый звук обозначен соответствующей фишкой. Вам надо внимательно посчитать количество звуков, определить какие это звуки: гласные, твёрдые и мягкие согласные звуки. Когда вы определите эти звуки – подберите к этой модели слово, в котором все звуки будут совпадать с определёнными фишками. На доске выставляю звуковые схемы. Пальчиковая гимнастика «Замок». 5. Работа в тетради, стр. 48 – 49. | Проявляют интерес. Слушают. Понимают. Добавляют звук Понимают задание. Называют слова: мама, машина, малина, магазин. Придумывают слова: бусы, будка, булавка, булка. Придумывают и называют слова: дом, дорога, доски. Выполняют движения по сигналу. Рассматривают. Слушают. Понимают задание. Выполняют. Подбирают. Подбирают слова к звуковым схемам. Выполняют работу в соответствии с заданием. | Рефлексивті түзетушілік Рефлексивно – корригирующий | – Какие задания принёс Алдар Косе? – Какое задание вам понравилось? Прощание с Алдар Косе. Вы отлично выполнили все задания, и он желает вам дальнейших успехов. | Работа со словами. Подбирать слова к звуковой модели. Прощаются с Алдар Косе. |

Составь звуковые модели слов конь тень апрель письмо галька | Составь звуковые модели слов конь тень апрель письмо галька |
Составь звуковые модели слов конь тень апрель письмо галька | Составь звуковые модели слов конь тень апрель письмо галька |
Составь звуковые модели слов конь тень апрель письмо галька | Составь звуковые модели слов конь тень апрель письмо галька |
Составь звуковые модели слов конь тень апрель письмо галька | Составь звуковые модели слов конь тень апрель письмо галька |
Составь звуковые модели слов конь тень апрель письмо галька | Составь звуковые модели слов конь тень апрель письмо галька |
Составь звуковые модели слов конь тень апрель письмо галька | Составь звуковые модели слов конь тень апрель письмо галька |
Составь звуковые модели слов конь тень апрель письмо галька | Составь звуковые модели слов конь тень апрель письмо галька |
Составь звуковые модели слов конь тень апрель письмо галька | Составь звуковые модели слов конь тень апрель письмо галька |
Составь звуковые модели слов конь тень апрель письмо галька | Составь звуковые модели слов конь тень апрель письмо галька |
Составь звуковые модели слов конь тень апрель письмо галька | Составь звуковые модели слов конь тень апрель письмо галька |
Составь звуковые модели слов конь тень апрель письмо галька | Составь звуковые модели слов конь тень апрель письмо галька |
Составь звуковые модели слов конь тень апрель письмо галька | Составь звуковые модели слов конь тень апрель письмо галька |
Составь звуковые модели слов конь тень апрель письмо галька | Составь звуковые модели слов конь тень апрель письмо галька |
Дәлелдеу – ояту Мотивационно- побудительная | Здравствуйте, ребята! Давайте возьмемся за руки и поприветствуем друг друга такими словами: Спасибо скажем мы не раз Всему живому вокруг нас: Как хорошо на свете жить, Как хорошо уметь дружить! -Сегодня к нам в гости пришел Алдар-Косе. | Дети берутся за руки и вместе с воспитателем приветствуют друг друга. Проявляют радость. Приветствуют. | Ұйымдастыру-іздену Организационно- поисковый | Дидактическая игра «Звук потерялся». Воспитатель: -Я буду показывать вам картинки с изображением предметов, и называть их с пропущенным звуком в слове, а вы должны исправить меня и «добавить» звук, который я забыла произнести. Примерные слова: …олесо,…тица,…алина,…амолет, …орзина,…олоко,…арелка,…айник. –Алдар-Косе загадал слова, которые начинаются на слог ма. – Первая часть слова начинается на слог бу. Придумайте и назовите слова, которые начинаются со слога бу. – Первая часть слова начинается на слог до. Придумайте и назовите слова, которые начинаются со слога до. За каждый правильный ответ воспитатель дает детям фишку. В конце игры определяется победитель. Физкультминутка: Самолеты загудели, Самолеты полетели. На полянку тихо сели, Да и снова полетели. Воспитатель достает из конверта карточки со звуками. Раздает их детям. Воспитатель: -Следующее задание Алдар-Косе просит нас выполнить и подобрать к каждой звуковой схеме – слово. У каждого из вас стоит звуковая модель слова. Каждый звук обозначен соответствующей фишкой. Вам необходимо внимательно посчитать количество звуков, определить какие это звуки: гласные, твердые и мягкие согласные звуки. Когда вы определите все звуки – подберите к этой модели слово, в котором все звуки будут совпадать с отмеченными фишками. Пальчиковая гимнастика «Замок». Пальцы сжимаем И замок мы получаем, А потом их разжимаем И сначала начинаем. Пальцы сжимаем И замок мы получаем .Работа в тетради | Проявляют интерес. Слушают. Понимают. Добавляют звук. Понимают задание. Дети называют слова: мама, машина, мало, малина, магазин. Называют слова: бутон, булавка, бумага, бусы, бутылка, букет, букашка. Дети придумывают и называют слова: дом, доктор, доска, дорога, добро, доброта, дочка, доярка. Выполняют движения согласно физкультминутке. Рассматривают. Слушают. Понимают задание. Выполняют. Подбирают слова к звуковым схемам: бусы, кит, мяч, лук, лист, дыня, утюг, шуба, роза, игла, мак, лиса, жук. Выполняют работу в соответствии с заданием. |
 Он принес нам конверт с интересными заданиями. Давайте заглянем в конверт и узнаем, что лежит в нем. Алдар-Косе сказал: что задания его интересные, надо их решить и отгадать слова, которые он задумал.
Он принес нам конверт с интересными заданиями. Давайте заглянем в конверт и узнаем, что лежит в нем. Алдар-Косе сказал: что задания его интересные, надо их решить и отгадать слова, которые он задумал. Педагог на доске выставляет звуковые схемы.
Педагог на доске выставляет звуковые схемы.Урок 68. сколько в слове слогов? – Русский язык – 1 класс
Конспект по предмету
«Русский язык» для «1» класса
Урок № 68 «Сколько в слове слогов?»
Вопросы, рассматриваемые на уроке.
на уроке мы закрепим умение делить слова на слоги,
повторим способы выделения слогов в слове,
сможем соотносить слово с его звуковой моделью.
Глоссарий
Слог – это часть слова.
слоговая модель
Слоговая модель слова выглядит так
ангел
_́|_
Звуковая модель слова выглядит так
ангел
Литература
Основная
В. П. Канакина В. Г. Горецкий «Русский язык» 1 класс. Учебник для общеобразовательных организаций. Москва «Просвещение» 2014
Дополнительная
Справочное пособие по русскому языку. 1–2 классы. Узорова О.В., Нефедова Е.Л. – Москва: АСТ: Астрель, 2013. – 256 с.
1–2 классы. Узорова О.В., Нефедова Е.Л. – Москва: АСТ: Астрель, 2013. – 256 с.
Тренировочные примеры по русскому языку. Задания для повторения и закрепления. 1 класс. Кузнецова М.И. Москва, Издательство “Экзамен”, 2014 – 32 с. (Серия “5000 задач”)
Полный курс русского языка: все типы заданий, все виды упражнений, все правила. 1 класс. Узорова О.В., Нефёдова Е.А. – Москва: АСТ: Астрель; Владимир: ВКТ, 2012. – 190, [2]с.
Занимательный русский язык. 1 класс. Рабочая тетрадь. В 2 ч. Мищенкова Л.В. – М.: 2016 –Ч.1 – 80с., Ч.2 – 80с.
Язык родной, дружи со мной. А. Шибаев. – Санкт-Петербург, “Детгиз”, 2014. – 127с.
http://gramota.ru/slovari/
Теоретический материал
Чтобы разбить слово на слоги, нужно узнать сколько в нем гласных звуков. Сколько гласных, столько и слогов
де-душ-ка _́|_|_ 3 слога
динозавр _|_|_ ́ 3 слога
ведро _|_́ 2 слога
арбуз _|_́ 2 слога
слог может состоять из одного гласного звука и-мя
из гласного и согласного ма-ма
из нескольких согласных и гласного а-ист
в звуковой модели слова
гласный звук будем обозначать красным цветом,
твердый согласный – синим,
мягкий согласный – зеленым,
слоги слияния будем обозначать
твердый согласный и гласный – синий с красным,
мягкий согласный и гласный – зеленый с красным
Давайте составим звуковую и слоговую модель слова аист
слоговая модель
в слове аист два гласных. значит в слове два слога
а-ист
_|_
ааааист, первый слог под ударением
_́|_
Теперь давайте составим звуковую модель слова
в слове аист два слога
Первый слог состоит из одного гласного, второй из слога слияния и согласного (сначала рисуется первая вертикальная линия, потом вторая вертикальная линия, потом слог слияния)
Резюме теоретической части
Слово состоит из слогов
Сколько в слове гласных, столько и слогов.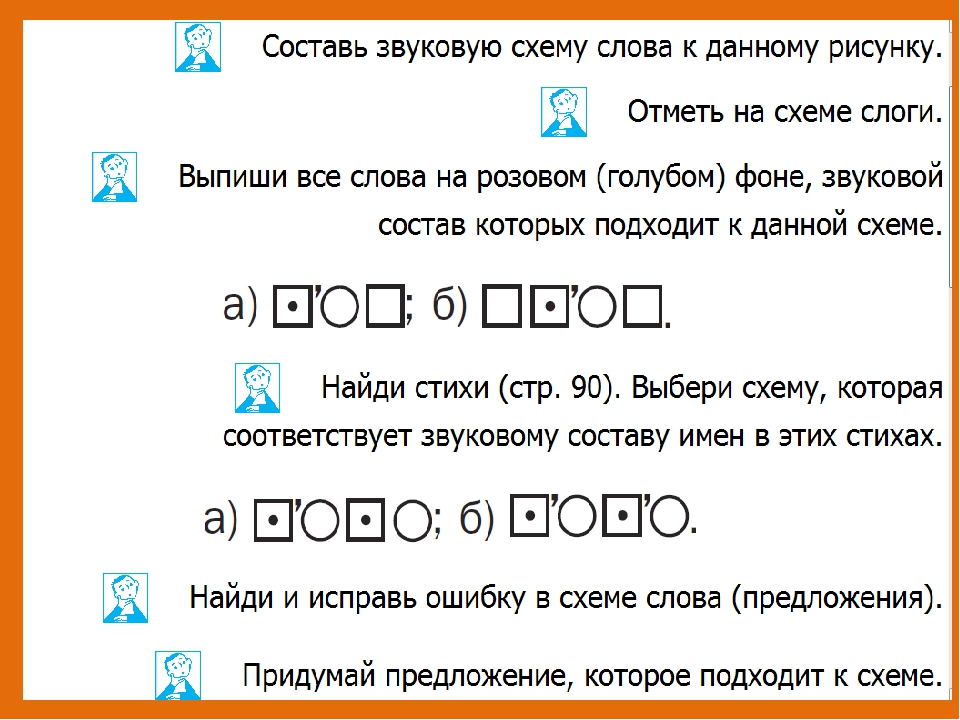
Слоговая модель слова выглядит так
ангел
_́|_
звуковая модель слова выглядит так
ангел
Примеры заданий
1.Подчеркните слова, которые соответствуют данной схеме
_|_́
поле
зима
кость
луна
гранат
ива
забег
игла
Правильный ответ
поле
зима
кость
луна
гранат
ива
забег
игла
2. Распределите слова по столбикам
2 слога | 3 слога | 4 слога |
воробей, гуашь, звезды идея, индеец, Алеша, космический, пианино, черепаха, парикмахер, бульдог, завтрак,
Правильный ответ
2 слога бульдог, гуашь, завтрак, звезды | 3 слога воробей идея, индеец, Алеша, , | 4 слога космический, пианино, черепаха, парикмахер |
Звуковую Модель Слова
Частичный анализ слов с опорой на их звуковые модели. Составление высказываний (2-3 предложения) с использованием наводящих вопросов. Цель: научить проводить полный звуковой анализ слова с опорой на звуковую схему и фишки. Описание игры. Воспитатель выкладывает на доске модель слова и говорит: «А.
Умничка » Архив сайта » Учимся составлять звуковую схему слова. Уважаемые родители, для ребят, которые идут в 1 класс, будут очень полезны занятия по составлению звуковой схемы слова. Давайте попробуем разобраться, как правильно составить звуковую схему слова или звуковую модель слова. Данный вид работы мы также можем назвать звуко- буквенным разбором слова или фонетическим разбором. Фонетика – раздел науки о языке, в котором изучаются звуки языка, ударение, слог. Звуки, которые произносит человек, мы называем звуками речи. Звуки речи образуются в речевом аппарате при выдыхании воздуха.
Звуковая схема слова. Главная · Упражнения · 7 лет; Звуковая схема слова. 2
года · 3 года · 4 года · 5 лет · 6 лет · 7 лет · 1 класс · 2 класс · 3 класс · 4 класс.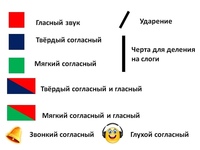 Уважаемые родители, на этапе обучения грамоте ребята учатся составлять звуковую схему или, по-другому, модель слова. Помогите. Для работы нам понадобятся карточки-модели для обозначения звуков или
Уважаемые родители, на этапе обучения грамоте ребята учатся составлять звуковую схему или, по-другому, модель слова. Помогите. Для работы нам понадобятся карточки-модели для обозначения звуков или
карандаши (синий, зелёный, красный, простой), если мы рисуем схемы в .
Речевой аппарат – это гортань с голосовыми связками, ротовая и носовая полости, язык, губы, зубы, нёбо. Гласные звуки состоят только из голоса, выдыхаемый воздух проходит через рот свободно, не встречая преграду. Гласные звуки можно долго тянуть, петь. В русском языке гласных звуков шесть: [а], [о], [у], [э], [ы], [и]. Гласные звуки бывают ударными и безударными. Гласные звуки мы будем обозначать красным цветом ( условные обозначения для звуков я взяла из программы “Школа России”). Предлагаем большой выбор школьных рюкзаков для девочек и мальчиков.
В нашем магазине вы можете купить школьный рюкзак для первоклассников и для подростков, а также школьные сумки и мешки для обуви. Когда мы произносим согласные звуки, воздух встречает преграду (губы, зубы, язык). Одни согласные состоят только из шума – это глухие согласные. Другие – из голоса и шума. Это звонкие согласные. Согласные также делятся на твёрдые и мягкие.
Твёрдые согласные обозначают синим цветом, мягкие – зелёным. По программе “Школа России” слияние гласного звука с согласным мы обозначаем прямоугольником, разделённым наискосок прямой линией, где снизу закрашиваем согласный, а сверху гласный. Сделайте из цветного картона или бумаги карточки, чтобы составлять слова. Также понадобятся карточки со знаком ударения и разделительной чертой. Можно рисовать схемы в тетради в крупную клеточку. Ещё лучше совмещать оба вида работы. Начинайте работу с простых слов – односложных или двусложных.
1. Азбука в картинках. 2. Картины-схемы звукового состава слов (19 таблиц). слова на слоги, называть слова по заданной звуковой модели, читать слоги, слова, простые предложения. Звуковая Модель Слова. Фонетика – раздел науки о языке, в котором изучаются звуки языка, ударение, слог. Звуки, которые произносит человек, мы. Давайте попробуем разобраться, как правильно составить звуковую схему слова или звуковую модель слова. Данный вид работы мы.
Звуки, которые произносит человек, мы. Давайте попробуем разобраться, как правильно составить звуковую схему слова или звуковую модель слова. Данный вид работы мы.
Итак, вы сделали карточки и готовы к занятию. Подумайте, как заинтересовать ребёнка. Может вы научите составлять слова куклу Машу или любимого зайку? Или будете отгадывать загадки и составлять схему слова- отгадки? А может быть слово (карточка или картинка) спрятаны и вы поиграете в игру “холодно- горячо”?
Очень хорошо, если вы придумали что- то интересное и появился стимул к работе. Фрагмент занятия. Отгадай загадку. Сидит дед в сто шуб одет.
Умничка » Архив сайта » Как составить звуковую схему слова? Уважаемые родители, на этапе обучения грамоте ребята учатся составлять звуковую схему или, по- другому, модель слова. Помогите ребёнку разобраться в составлении звуковой модели слова. Я приведу примеры звуковых схем по программе “Школа России”. Там обозначения разных звуков различаются по цвету. Итак, освежим в памяти знания по фонетике, которые вы получили в школе.
Гласных звуков в русском языке шесть – [а], [о], [у], [ы], [э], [и]Согласные образуют пары по твёрдости- мягкости, по глухости- звонкости. Есть непарные согласные. Мягкий знак и твёрдый знак звуков не обозначают. Буквы Я, Ё, Ю, Е обозначают два звука, если стоят в начале слова или после гласного звука, обозначают один звук, если стоят после согласного.
В таблице мы видим букву и под ней звук или звуки, которые обозначают этой буквой. Например, буквой Б обозначают два звука [б], [б’].
Буквой Ж один звук [ж]. Разберём составление звуковой модели слова ПИСЬМО. Делим слово на слоги: ПИ- СЬМО (как разделить слово на слоги можно посмотреть здесь http: //ya- umni. Первый слог – ПИ. Это слияние. Гласный звук [и] обозначает мягкость согласного. Первый звук [п’] – мягкий согласный, второй звук [и] – гласный. Второй слог – СЬМО.
Первый звук [с’] – мягкий согласный. Дальше идёт слияние – МО. Гласный звук [о] обозначает твёрдость согласного. Звук [м] – твёрдый согласный. Звук [о] – гласный.
Звук [м] – твёрдый согласный. Звук [о] – гласный.
Ставим ударение. В итоге получается такая схема: Мы с ребятами делаем затем транскрипцию (как мы слышим слово).[п’ис’мо]А затем записываем слово: письмо. Гласные звуки, которые находятся в верхнем ряду таблички – а, о, у, ы, э обозначают твёрдость согласного звука. Гласные буквы я, ё, е, ю стоят после мягкого согласного, звук [и] тоже обозначает мягкость согласного. Но необходимо помнить, что есть согласные, которые всегда твёрдые. Они обозначены в таблице только синим цветом: [ж], [ш], [ц]. Есть согласные, которые всегда мягкие, они обозначены только зелёным цветом: [ч’], [щ’], [й’]. Будьте внимательны при разборе слов с йотированными гласными.
Вот пример разбора слова ЯБЛОКО. В начале слова йотированные гласные обозначают два звука. Надеюсь, что статья помогла вам немного разобраться в составлении звуковой схемы слова. В других программах просто другие обозначения звуков. Могут быть не квадратики, а кружки. По другому обозначена твёрдость- мягкость. Но разобраться можно, подставив нужные обозначения.
Материалы о составлении звуковой схемы можно посмотреть ещё здесь.
Упражнение 4 – ГДЗ Русский язык 1 класс. Евдокимова, Кузнецова. Учебник. Страница 6
- Главная
- ГДЗ
- 1 класс
- Русский язык
- Евдокимова, Кузнецова, Иванов. Учебник
- Урок 1
- Упражнение 4
- ← Предыдущее
- Следующее →
Вернуться к содержанию учебника
Урок 1. Страница 6
Вопрос
- Назови, что ты видишь на рисунке.
 Выполни звуковой анализ произнесённого слова.
Выполни звуковой анализ произнесённого слова. - Найди в тексте открытки из упражнения 2 слово, которое соответствует звуковой модели.
- Проверь, правильно ли Антон составил звуковую модель слова друзья.
Подсказка
Памятка: звуковой разбор слова.
! Обратите внимание на обозначения в схеме:
- синий цвет – твёрдый согласный;
- зелёный цвет – мягкий согласный;
- красный цвет – гласный;
- колокольчик – звонкий согласный.
Ответ
Поделись с друзьями в социальных сетях:
Вернуться к содержанию учебника
- ← Предыдущее
- Следующее →
© budu5.com, 2021
Пользовательское соглашение
Copyright
Нашли ошибку?
Связаться с нами
9.4: Сопоставление правописания со звуком при чтении слов
Теперь мы увеличиваем масштаб прямого пути между визуальным вводом слов (орфография) и вербальным речевым выводом (фонология), используя гораздо больший набор слов, составляющих большинство односложных слов в английском языке. (почти 3000 слов). Изучая такой большой набор слов, отобранных в соответствии с частотой их встречаемости в английском языке, сеть имеет шанс извлечь «правила», которые управляют сопоставлением орфографии и звука в английском языке (такими, какие они есть), и, следовательно уметь успешно произносить неслова.
Английский язык является особенно сложным с точки зрения произношения, как знает любой, кто пытался выучить его в качестве второго языка. Абсолютных правил очень мало (если они вообще есть). Все больше похоже на частичную контекстно-зависимую регулярность , которую также называют субрегулярностью . Например, сравните произношение буквы i в mint и hint (короткий звук i ) с тем, что в mind и найдите (длинный звук I ).Последний согласный ( t против d ) определяет произношение, и, конечно, всегда есть исключения, такие как пинта (длинный звук I ).
Один из способов определить, насколько сильна регулярность, – это подсчитать, от скольких других букв зависит произношение. Полное исключение, такое как pint или yacht , зависит от всех букв в слове, в то время как mint vs. mind зависит от еще одной буквы в слове (последние t или d ).Есть много примеров безмолвных букв, таких как заключительный e , состоящий из нескольких слов. Хорошая подрегулярность – это буква м , которая зависит от того, есть ли рядом с ней n , и в этом случае она замолкает, как в черт , столбец или мнемоника . Многие другие согласные могут быть беззвучными с разной степенью субрегулярности, включая b ( долг ), d ( красивый ), h ( честный ), l ( половин ), p ( переворот ), r ( железо ), s ( проход ), t ( замок ), w ( меч ) и z ( z ) рандеву ).
Еще одним фактором, определяющим, сколько контекста требуется для произнесения данной буквы, является преобладание многобуквенных групп, таких как  Другие примеры: sch ( school ), tch ( партия ), gh ( ghost ), ght ( справа ), kn ( knock ) , ph ( фото ), wh ( what ).Один из наиболее зависимых от контекста наборов букв – это группа ough , например, , хотя , tough , cough , plow , –, null , где произношение сильно различается.
Другие примеры: sch ( school ), tch ( партия ), gh ( ghost ), ght ( справа ), kn ( knock ) , ph ( фото ), wh ( what ).Один из наиболее зависимых от контекста наборов букв – это группа ough , например, , хотя , tough , cough , plow , –, null , где произношение сильно различается.
Итак, английский – это беспорядок. Сконструированное слово ghoti – известный пример того, насколько сумасшедшим может быть оно. Он произносится как «рыба», где gh – это звук f , как в tough , o
– это звук и , как в women , а ti – это звук sh , как в нации . Для того, чтобы любая система могла иметь возможность производить правильное произношение английского языка, она должна быть способна учитывать диапазон контекста вокруг данной буквы в слове, вплоть до самого слова. Влиятельный ранний подход к моделированию орфографии для звука в нейронной сети (Seidenberg & McClelland, 1989) использовал так называемое представление Wickelfeature (названное в честь Уэйна Викельгрена), где написанные буквы кодировались парами по три.Например, слово «думать» будет закодировано как thi , hin и ink . Это хорошо для захвата контекста, но немного жестко и не учитывает значительную регулярность самих отдельных букв (в большинстве случаев м – это всего лишь м ). В результате эта модель не очень хорошо обобщалась на неслова, где буквы появлялись в другой компании, чем в реальных словах, используемых в обучении. Последующая модель, разработанная Плаутом, МакКлелландом, Зайденбергом и Паттерсоном (1996) (далее PMSP), достигла хорошего несловесного обобщения путем представления входных слов посредством кодированной вручную комбинации отдельных буквенных единиц и полезных многобуквенных контекстов (например,г.
Мы применяем другой подход в нашей модели озвучивания орфографии (рис. 9.8), используя идеи модели распознавания объектов, которая была исследована в главе «Восприятие». В частности, мы увидели, что модель распознавания объектов может научиться создавать все более сложные комбинации функций, одновременно развивая пространственную инвариантность на нескольких уровнях обработки в иерархии от V1 до ИТ. В контексте распознавания слов эти сложные функции могут включать комбинации букв, в то время как пространственная инвариантность позволяет системе распознавать, что м в любом месте совпадает с любым другим м (большую часть времени).
Убедительная демонстрация важности пространственной инвариантности при чтении проистекает из этого примера, который несколько лет назад стал популярным в электронной почте:
- Я не знаю, что я был раньше. Несмотря на то, что передовые документы на сайте hmuan mnid, aocdcrnig to rseecrah at Cmabrigde Uinervtisy, это не означает, что в каком-либо тексте есть тексты, единственная информация в тексте – это имя и текст. Набор может быть задан, и вы можете сидеть без него.Tihs is bucseae huamn mnid deos не raed ervey ltteer by istlef, а wrod as a wlohe. Аазнмиг, а? Yaeh и я awlyas tghhuot slelinpg was ipmorantt! Посмотри, может ли твой фдрейнс ранить их.
Очевидно, что это труднее, чем правильно написанный текст, но способность вообще его читать указывает на то, что простое извлечение отдельных букв неизменным способом имеет большое значение.
| Набор без слов | н.ж. Модель | PMSP | Люди |
| Глушко завсегдатаи | 95.3 | 97,7 | 93,8 |
| Глушко исключения сырые | 79,0 | 72,1 | 78,3 |
| Исключения Глушко альт ОК | 97,6 | 100,0 | 95,9 |
| McCann & Besner ctrls | 85.9 | 85,0 | 88,6 |
| McCann & Besner homoph | 92,3 | НЕТ | 94,3 |
| Тарабан и Макклелланд | 97,9 | НЕТ | 94,3 |
Таблица \ (9.1 \): Сравнение производительности чтения без слов для нашей модели преобразования орфографии в звук (модель ss), модели PMSP и данных от людей по ряду различных наборов данных без слов, как описано в текст.Наша модель сравнима с людьми после изучения почти 3000 односложных слов английского языка.
Чтобы проверить производительность этого подхода, основанного на распознавании объектов, мы пропустили его через набор различных стандартных наборов неслов, некоторые из которых также использовались для тестирования модели PMSP. Результаты показаны в таблице \ (9,1 \).
Результаты показаны в таблице \ (9,1 \).
- Регуляторы Глушко – неслова, построенные так, чтобы соответствовать строгим закономерностям, например nust , который является полностью регулярным (например, nust ).г., надо , бюст , траст и тд).
- Исключения Глушко – неслова, которые имеют похожие английские исключения и противоречивые закономерности, такие как bint (может быть как mint , но также может быть как pint ). Мы оцениваем эти элементы либо в соответствии с преобладающей регулярностью, либо с учетом близких исключительных случаев (в таблице – ОК).
- McCann & Besner ctrls – это псевдогомофоны и согласованные элементы управления, которые звучат как настоящие слова, но пишутся по-новому, например choyce (произносится как выбор ), а согласованный элемент управления – фойс .
- Taraban & McClelland – имеет согласованную частоту обычных и исключительных неслов, например поэтов (например, высокочастотные слова идут или делают ), и mose , например, более низкие частоты позы или проигрывают .
Результаты показывают, что модель замечательно справляется с захватом производительности людей на этих наборах без чтения слов. Это говорит о том, что модель способна изучать соответствующие закономерности и субрегуляции, присутствующие в статистике английского произношения.
Разведка
- Откройте Spelling to Sound, чтобы изучить модель преобразования правописания в звук и проверить ее эффективность как на словесных, так и на несловесных стимулах.
Глоссарий звуковых эффектов – Стойка Boom Box
треск – звук, состоящий из быстрой последовательности легких трескающих звуков.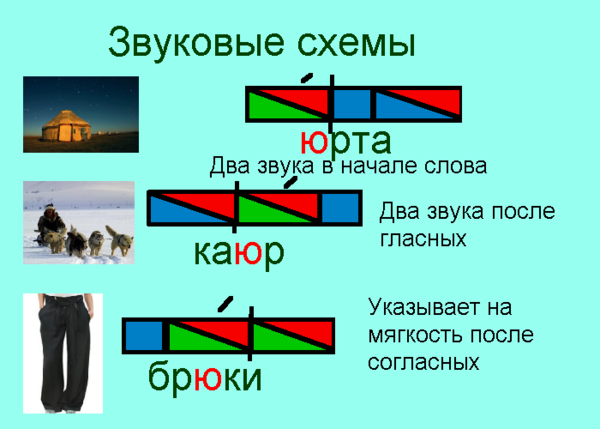 Также посмотрите вверх: шипение, шипение, шипение, треск, щелчок, предохранитель, взрыватель, ожог, огонь
Также посмотрите вверх: шипение, шипение, шипение, треск, щелчок, предохранитель, взрыватель, ожог, огонь
авария – внезапный громкий звук, как будто что-то ломается или ударяется о другой предмет. Также посмотрите вверх: bang, smash, crack, bump, thud, clatter, clunk, clang, hit
bodyfall – звук, издаваемый телом, падающим на твердую поверхность. Также посмотрите вверх: удар по корпусу, земля
boing – шум, представляющий звук внезапно выпущенной сжатой пружины. Также посмотрите вверх: bounce, bouncing, bonk, jaw harp
boom – громкий, глубокий, резонансный звук. Также посмотрите вверх: взрыв, хлопок, треск, барабан, тайко, грохот
гудение – гудение или бормочущий звук, издаваемый или похожий на звук, издаваемый насекомым. Также посмотрите: гул, гул, насекомое, неон, флуоресцентный
chomp – жевать или жевать энергично и шумно. Также посмотрите вверх: жевать, хрустеть, жевать, кусать
щелчок – короткий резкий звук, как при нажатии на выключатель или при быстром контакте двух твердых предметов. Также посмотрите: щелчок, щелчок, щелчок, тик, щелчок, переключатель, кнопка
скрип – резкий царапающий или скрипящий звук. Также посмотрите: скрип, решетка
flutter – звук неустойчивого полета или зависания при быстром и легком взмахе крыльев. Также посмотрите вверх: beat, clap, quiver, wing
glug – звук питья или наливания (жидкости) с глухим булькающим звуком. Также посмотрите: налейте, слейте воду
стон – тихий скрип или стон, когда к объекту прилагается давление или вес, ИЛИ нечленораздельный звук в ответ на боль или отчаяние. Также посмотрите вверх: скрип, скрип; стон, плач, хныканье
гудок – крик дикого гуся.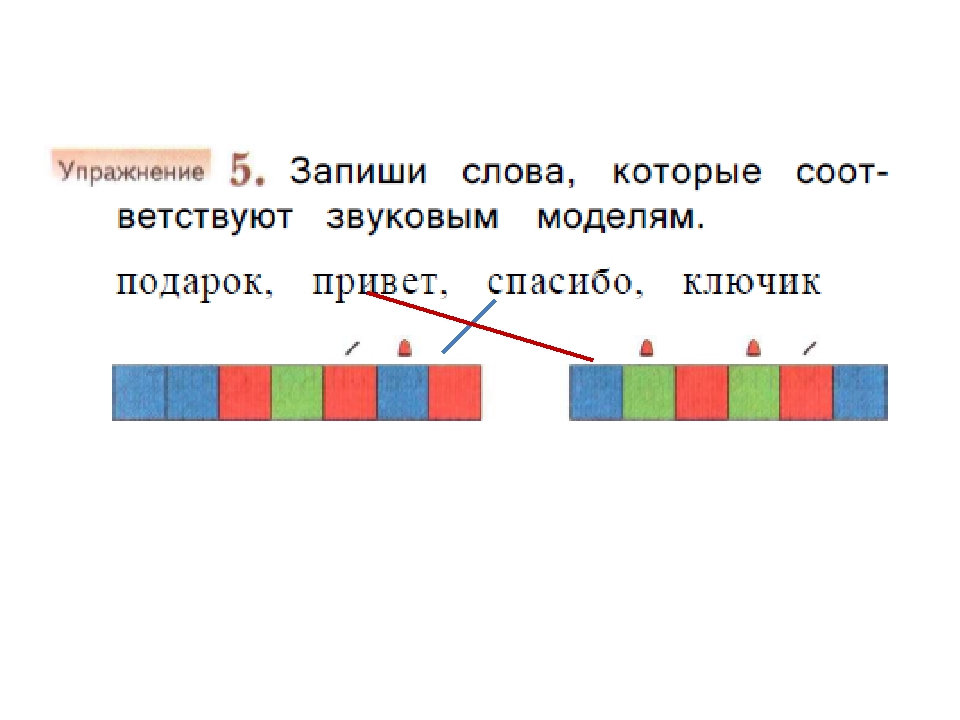 Также посмотрите: гусак, гусь
Также посмотрите: гусак, гусь
ахуогах – звук определенного типа рожка. Также посмотрите: модель a, модель t, старинный рог, рог лампы
jingle – легкий звенящий звук, такой как звук, издаваемый при сотрясении металлических предметов. Также посмотрите вверх: звон, звон, звон, звон, звон, бубенцы
ржать – Характерный высокий звук, издаваемый лошадью. Также посмотрите вверх: whinny, bray, knicker
poof – используется для передачи внезапности, с которой кто-то или что-то исчезает. Также посмотрите: puff
pop – легкий взрывной звук. Также посмотрите вверх: пузырь, пробка, кувшин, барабан
затяжка – короткий взрывной порыв дыхания или ветра. Также посмотрите: пуф, порыв, взрыв, дуновение, ветерок, дыхание
хрип – быстрая последовательность коротких, резких, резких звуков. Также посмотрите: лязг, лязг, лязг, лязг
ribbit – характерный квакающий звук лягушки. Также посмотрите: лягушка, жаба, кваканье
кряк – характерный резкий звук, издаваемый уткой. Также посмотрите вверх: утка, кряква
шелест – мягкий приглушенный треск, похожий на звук движения сухих листьев, бумаги, ткани или подобного материала. Также посмотрите: свист, шепот, движение, mvmt
грохот – непрерывный глубокий резонансный звук. Также посмотрите вверх: бум, подводная лодка, землетрясение
крик – длинный, громкий, пронзительный крик, выражающий крайние эмоции или боль. Также посмотрите вверх: визг, визг, вопль, вой, крик, мычание, вопль, плач, визг, визг, вой, вопль
визг – громкий, резкий, пронзительный крик. Также посмотрите вверх: визг, крик, визг
занос – занос или скольжение. Также посмотрите вверх: скользите, перетаскивайте
Также посмотрите вверх: скользите, перетаскивайте
slurp – громкий звук сосания, издаваемый во время еды или питья. Также посмотрите вверх: сосать, пить, соломинку, лизать
всплеск – звук, издаваемый чем-то ударом или падением в жидкость. Также посмотрите вверх: брызги, брызги, брызги, падающая вода
splat – звук, производимый мокрым предметом, ударяющимся о твердую поверхность. Также ищите: squish
splatter – брызги липкой или вязкой жидкости. Также посмотрите: брызги, брызги, брызги, брызги
крики – громкий, резкий или несогласованный шум, издаваемый птицей или человеком. Также посмотрите вверх: визг, визг, визг, вопль, кваканье, ворона, карканье, кудахтанье, кудахтанье, улюлюканье, крик, вызов
визг – короткий пронзительный звук или плач. Также посмотрите: писк, писк, трубка, визг, чирикать, тявкать, хныкать, скрип
squish – мягкий хлюпающий звук. Также посмотрите вверх: splat, splatter
swish – легкий звук объекта, движущегося по воздуху. Также посмотрите вверх: свист, свист
свуш – звук, производимый внезапным порывом воздуха. Также посмотрите вверх: swish, whoosh
thunk – звук, когда пробка вынимается или помещается в бутылку или кувшин. Также посмотрите вверх: хлоп, пробка, кувшин
звенящий – сильный звонкий звук, такой как звук, издаваемый натянутой струной музыкального инструмента, натянутой тетивой или линейкой, удерживаемой на одном конце и выдергиваемой из Другие. Также посмотрите вверх: протяжный звук линейки, протяжный звук, рябь, щипок, скрипка, гитара
треск хлыста – громкий и внезапный звук хлыста, движущегося быстрее скорости звука, создавая небольшой звуковой удар. Также посмотрите вверх: бычий кнут, кнут, свист, свист, свист
Также посмотрите вверх: бычий кнут, кнут, свист, свист, свист
свист – тяжелый звук движущегося в воздухе объекта. Также посмотрите: swish, swoosh
woof – звук, издаваемый лающей собакой. Также посмотрите вверх: лай, вой, визг, хныканье, собака
визг – короткий резкий крик, особенно от боли или тревоги. Также посмотрите вверх: визг, вопль, вой, вой, вопль, крик, крик
zap – внезапный прилив энергии или звука. Также посмотрите: лазер, луч, синтезатор, научная фантастика
посмотрите еще два наших глоссария: Глоссарий звуковых эффектов Часть 2 и Глоссарий звуковых эффектов Часть 3!
Взаимодействие значения и звука при распознавании устных слов
Aitken, L.С., и Уэст, С. Г. (1991). Множественная регрессия: тестирование и интерпретация взаимодействия . Ньюбери-Парк, Калифорния: Сейдж.
Google Scholar
Балота Д., Ферраро Р. и Коннор Л. (1991). О раннем влиянии значения на распознавание слов: обзор литературы. В P. Schwanenflugel (Ed.), Психология значений слов, (стр. 187–222). Хиллсдейл, Нью-Джерси: Эрлбаум.
Google Scholar
Беккер, К.А. (1980). Эффекты семантического контекста в визуальном распознавании слов: анализ семантических стратегий. Память и познание , 8 , 493–512.
Google Scholar
Браун, Г. Д. А., & Уотсон, Ф. Л. (1987). Первым пришел – первым ушел: возраст заучивания слов и частота произнесенных слов как предикторы узнаваемости слов и задержки при названии слов. Память и познание , 15 , 208–216.
Артикул Google Scholar
Колтер, М.(1981). Психолингвистическая база данных MRC. Ежеквартальный журнал экспериментальной психологии , 33A , 497–505.
Ежеквартальный журнал экспериментальной психологии , 33A , 497–505.
Google Scholar
deGroot, A.M.B. (1989). Репрезентативные аспекты визуализации слов и их частотности, оцениваемые с помощью словесных ассоциаций. Журнал экспериментальной психологии: обучение, память и познание , 15 , 824–845.
Артикул Google Scholar
Форстер, К.I. (1979). Уровни обработки и структура языкового процессора. В W. E. Cooper & E. Walker (Eds.), Обработка предложений: Психологические исследования, представленные Merrill Garrett . Хиллсдейл, Нью-Джерси: Эрлбаум.
Google Scholar
Форстер, К. И., и Форстер, Дж. К. (1990). Система индикации DMASTR для ментальной хронометрии . Тусон: Университет Аризоны Press.
Google Scholar
Гаскелл, Г., И Марслен-Уилсон, В. Д. (1995). Моделирование восприятия произносимых слов. В Дж. П. Мур и Ф. Леман (ред.), Труды семнадцатой ежегодной конференции Общества когнитивных наук . Махва, Нью-Джерси: Эрлбаум.
Google Scholar
Гаскелл, Г., и Марслен-Уилсон, В. Д. (1997). Интеграция формы и значения: распределенная модель восприятия речи. Язык и когнитивные процессы , 12 , 613–656.
Артикул Google Scholar
Хофланд, К., и Йоханссон, С. (1982). Частота слов в британском и американском английском . Харлоу, Великобритания: Longman.
Google Scholar
Люс П., Писони Д. и Голдингер С. (1990). Сходство окрестностей произнесенных слов. В G.A. Altmann (Ed.), Когнитивные модели обработки речи: психолингвистические и вычислительные перспективы (стр. 122–147). Кембридж, Массачусетс: MIT Press.
122–147). Кембридж, Массачусетс: MIT Press.
Google Scholar
Марслен-Уилсон, В. Д. (1990). Активация, конкуренция и частота в лексическом доступе. В Г. А. Альтманне (ред.), Когнитивные модели обработки речи: психолингвистические и вычислительные перспективы (стр. 148–172). Кембридж, Массачусетс: MIT Press.
Google Scholar
Marslen-Wilson, W. D., & Welsh, A.(1978). Обработка взаимодействий и лексический доступ при распознавании слов в непрерывной речи. Когнитивная психология , 10 , 29–63.
Артикул Google Scholar
Макклелланд Дж. И Элман Дж. (1986). Модель восприятия речи Trace. Когнитивная психология , 18 , 1–86.
Артикул PubMed Google Scholar
Маклеод, П., & Познер, М. (1984). Привилегированные петли от восприятия к действию. В H. Bouma & D. G. Bouhuis (Eds.), Внимание и производительность X: Контроль языковых процессов (стр. 55–66). Хиллсдейл, Нью-Джерси: Эрлбаум.
Google Scholar
Мертус Дж. (1989). Руководство пользователя BLISS . Провиденс, Род-Айленд: издательство Brown University Press.
Google Scholar
Пайвио, А.(1986). Ментальные представления: подход двойного кодирования . Нью-Йорк: Oxford University Press, Clarendon Press.
Google Scholar
Плаут Д. и Шаллис Т. (1993). Глубокая дислексия: тематическое исследование коннекционистской нейропсихологии. Когнитивная нейропсихология , 10 , 377–500.
Артикул Google Scholar
Рэтклифф Р. (1993).Методы борьбы с выбросами времени реакции. Психологический бюллетень , 114 , 510–532.
Психологический бюллетень , 114 , 510–532.
Артикул PubMed Google Scholar
Зайденберг, М.С., Уотерс, Г.С., Сандерс, М., и Лангер, П. (1984). Пре- и постлексические локусы контекстных эффектов на распознавание слов. Память и познание , 12 , 315–328.
Артикул Google Scholar
Штамм E., Паттерсон, К. Э. и Зайденберг, М. (1995). Семантические эффекты в именовании одного слова. Журнал экспериментальной психологии: обучение, память и познание , 21 , 1140–1154.
Артикул Google Scholar
Табачник Б. Г. и Фиделл Л. С. (1989). Использование многомерной статистики (2-е изд.). Нью-Йорк: Харпер и Роу.
Google Scholar
Трейман, Р., Mullennix, J., Bijeljac-Babic, R., & Richmond-Welty, E. D. (1995). Особая роль римов в описании, использовании и усвоении английской орфографии. Журнал экспериментальной психологии: общие , 124 , 107–136.
Артикул Google Scholar
Тайлер Л. К. и Мосс Х. Э. (1997). Возможность изображения и эффекты, зависящие от категории. Когнитивная нейропсихология , 14 , 293–318.
Артикул Google Scholar
Ульрих Р. и Миллер Дж. (1994). Влияние усечения на анализ времени реакции. Журнал экспериментальной психологии: общие , 123 , 34–80.
Артикул Google Scholar
Обучение буквенно-звуковым соответствиям и типам слогов для идентификации слов
Результаты исследований неизменно подтверждают, что обучение алфавиту и фонетике способствует успехам детей в чтении (напр.г., Мерфи и Фаркухарсон, 2016). Эти базовые навыки не являются конечной целью обучения чтению, и их недостаточно для того, чтобы учащийся мог читать с пониманием (Brady, 2011). Однако в алфавитных языковых системах, таких как английский, понимание того, как звуки языка представлены буквами, является необходимой частью понимания написанных слов (Ehri, 2014). Некоторые дети могут выучить определенные буквенно-звуковые соответствия или основные слова, постоянно читая книги и печатные слова в своей среде (Pelatti, Piasta, Justice, & O’Connell, 2014).К сожалению, соответствия букв и звука в английском языке не так очевидны или последовательны, как в других алфавитных языках, таких как итальянский или финский (Seymour, Aro, & Erskine, 2003), поэтому может быть очень трудно выучить все различные способы, которыми наш язык может быть представлена простой экспозицией. Часто более эффективно преподавать буквенно-звуковые соответствия напрямую (Кизи, Конрад и Джозеф, 2015).
Однако в алфавитных языковых системах, таких как английский, понимание того, как звуки языка представлены буквами, является необходимой частью понимания написанных слов (Ehri, 2014). Некоторые дети могут выучить определенные буквенно-звуковые соответствия или основные слова, постоянно читая книги и печатные слова в своей среде (Pelatti, Piasta, Justice, & O’Connell, 2014).К сожалению, соответствия букв и звука в английском языке не так очевидны или последовательны, как в других алфавитных языках, таких как итальянский или финский (Seymour, Aro, & Erskine, 2003), поэтому может быть очень трудно выучить все различные способы, которыми наш язык может быть представлена простой экспозицией. Часто более эффективно преподавать буквенно-звуковые соответствия напрямую (Кизи, Конрад и Джозеф, 2015).
Эта инструкция также выполняется в последовательности от простых к более сложным навыкам.Например, начальная инструкция по буквенно-звуковому соответствию может быть заказана следующим образом:
- Согласные, представляющие наиболее распространенные звуки, и гласные, представляющие короткие звуки
- Согласные диграфы
- Сочетание двухбуквенных согласных
- Трехбуквенные переходы согласных и диграфы
- Сварные звуки (например, all , ing , ink )
- Одинарные гласные или образцы гласных-согласных, представляющие длинные звуки
- Гласные с контролем R
- Гласные диграфы
- Образцы согласных
- -sion / -tion окончания
Важно помнить, что приведенная выше последовательность является одним из возможных способов упорядочить уроки от более простых соответствий к более сложным.Различные учебные программы могут иметь несколько разную последовательность для согласования с вспомогательными материалами, такими как декодируемые тексты.
Пример урока начального уровня для эффективного обучения акустике
Целью следующего примера плана урока по фонетике является определение буквенно-звуковых соответствий для декодирования слов с закрытым слогом, согласный-гласный-согласный (CVC). Учитывая эту направленность, он предназначен для учащихся начальной школы. Однако описанный тип обучения может быть адаптирован для учащихся средних школ (см. Рисунок 2).План урока представляет собой сценарий для размышлений вслух на этапе моделирования и включает инструмент, называемый блоком слов . Блоки слов используются, чтобы помочь студентам сегментировать или разбивать отдельные звуки (фонемы) в слове и представлять эти звуки буквами (графемами), которые можно снова смешать вместе, чтобы прочитать слово. Поле слова создается путем разделения прямоугольника вертикальными линиями, проведенными внутри прямоугольника. Сначала изображение помещается над разделенным прямоугольником, а количество квадратов под изображением равно количеству звуков в слове, которое оно представляет.Позже количество ящиков может оставаться постоянным, так что учащиеся должны сами определять количество звуков. По мере того как учащиеся начинают читать более сложные слова, квадраты могут использоваться для обозначения слогов, а не отдельных звуков. Пустые рамки для слов можно найти в разделе «Дополнительные материалы для учителей».
Учитывая эту направленность, он предназначен для учащихся начальной школы. Однако описанный тип обучения может быть адаптирован для учащихся средних школ (см. Рисунок 2).План урока представляет собой сценарий для размышлений вслух на этапе моделирования и включает инструмент, называемый блоком слов . Блоки слов используются, чтобы помочь студентам сегментировать или разбивать отдельные звуки (фонемы) в слове и представлять эти звуки буквами (графемами), которые можно снова смешать вместе, чтобы прочитать слово. Поле слова создается путем разделения прямоугольника вертикальными линиями, проведенными внутри прямоугольника. Сначала изображение помещается над разделенным прямоугольником, а количество квадратов под изображением равно количеству звуков в слове, которое оно представляет.Позже количество ящиков может оставаться постоянным, так что учащиеся должны сами определять количество звуков. По мере того как учащиеся начинают читать более сложные слова, квадраты могут использоваться для обозначения слогов, а не отдельных звуков. Пустые рамки для слов можно найти в разделе «Дополнительные материалы для учителей».
Введение
Для начала расскажите студентам, что цель урока – определить звуки в слове и как представить эти звуки буквами, чтобы они могли прочесть слово.После постановки цели активируйте базовые знания учащихся с помощью разминки или повторения звуковых навыков, полученных на предыдущих уроках. Перед тем, как начать новую инструкцию, напомните студентам о важности изучения буквенно-звуковых соответствий и о том, как звуковые навыки могут улучшить способность к чтению, давая читателям возможность вычислять новые слова, которые они видят в своих книгах. Объясните: опытные читатели могут определять отдельные звуки в слове и могут связывать эти звуки с буквами.Чтобы узнать, как это сделать, скажите учащимся, что они будут использовать карточки с напечатанными на них буквами или карточки с буквами или .
Моделирование
Смоделируйте этапы использования карточек с буквами с полями для слов на бумаге, с помощью камеры для документов или с помощью интерактивной доски. Используйте декодируемые слова с соответствующими картинками. Убедитесь, что слова, выбранные для урока, соответствуют возрасту учащихся и типам слогов, которые они выучили в систематической последовательности. Слова в этом примере урока подходят для студентов, которые выучили общие согласные и короткие гласные.Студенты будут применять эти буквенно-звуковые соответствия для декодирования закрытых слогов, слов CVC. Ниже приведен пример использования поля слов и размышлений вслух, чтобы смоделировать его использование (см. Рисунок 1).
Используйте декодируемые слова с соответствующими картинками. Убедитесь, что слова, выбранные для урока, соответствуют возрасту учащихся и типам слогов, которые они выучили в систематической последовательности. Слова в этом примере урока подходят для студентов, которые выучили общие согласные и короткие гласные.Студенты будут применять эти буквенно-звуковые соответствия для декодирования закрытых слогов, слов CVC. Ниже приведен пример использования поля слов и размышлений вслух, чтобы смоделировать его использование (см. Рисунок 1).
Рис. 1. Пример окна Word
| м | a | п. |
Сегодня мы используем поле для слов и карточки с буквами, чтобы попрактиковаться в расшифровке слов с соответствиями между буквой и звуком, которые вы выучили.Я собираюсь смоделировать, как использовать поле со словами, а затем мы вместе попрактикуемся. Для начала посмотрите, как я моделирую, как использовать поле со словом.
Это поле со словом (поместите поле со словом и карточки с буквами перед учащимися) . Вверху поля word находится изображение карты. Внизу поля word находятся три поля. Эти три прямоугольника говорят нам, сколько звуков содержится в слове «карта». Первый звук, который я слышу в «карте», – это / m /.Я знаю, что буква «м» представляет звук / м / (разложите карточки с буквами перед учениками так, чтобы они могли видеть, что вы нашли карточку с буквой «м» и поместите ее в первое поле в поле со словами) .
Я нашел карточку с буквой «м». Я собираюсь поместить карточку с буквой «м» в начало поля со словом. Буква «м» представляет звук / м / в «карте». Средний звук, который я слышу в «карте», – / ă /. Это / ă / – это короткий гласный звук «а».Я собираюсь выбрать карточку с буквой «а» и поместить ее во вторую ячейку, чтобы представить / ă / звук (разложите карточки с буквами перед учениками так, чтобы они могли видеть, что вы нашли букву «а». карточку и поместите ее в среднее поле поля со словами) .
Конечный звук в «карте» – / p /. Согласная «п» представляет звук / п /. Я собираюсь найти карточку с буквой «p» и поместить ее в конечную ячейку поля со словом (разложите карточки с буквами перед учениками так, чтобы они могли видеть, что вы нашли карточку с буквой «p» и поместите ее в конец поля на поле слова) .
Я нашел все буквы слова «карта». Теперь я собираюсь попрактиковаться в произнесении всех звуков в «карте». Произнося каждый звук, я коснусь каждой буквы, представляющей этот звук: 1) / m /, 2) / ă / и 3) / p /. Смешайте все звуки вместе, «нанесите на карту» (повторите моделирование 3-5 раз или пока студенты не поймут процедуры) .
Практика с инструкциями
Объясните ученикам, что они будут использовать поля для слов, чтобы писать и читать слова, когда их небольшие группы встречаются с учителем.Раздайте каждой небольшой группе набор картинок для слов, содержащих только те типы слогов и буквенно-звуковые соответствия, которые выучили учащиеся. На этом уроке практика продолжится со словами CVC. Отобразите изображение в верхнем поле и следуйте процедурам, начиная с этапа моделирования. Однако во время управляемой практики привлекайте студентов к выполнению шагов. Попросите студентов назвать слово, которое представляет изображение или картинка. Затем попросите студентов произнести и сосчитать каждый звук в слове.Спросите, сколько квадратов нужно для обозначения звуков в слове. Помогите студентам выбрать карточки с буквами для представления каждого звука и поместить карточки в коробки. После того, как все карточки с буквами будут размещены, попросите учащихся в унисон повторять каждый звук. Наконец, попросите учащихся смешать все звуки вместе, чтобы сформировать целевое слово. Попросите учащихся подтвердить, что прочитанное слово соответствует картинке. Заполните дополнительные практические слова, если все учащиеся ответили неточно. Этот этап следует повторять 3-5 раз или до тех пор, пока ученики не продемонстрируют понимание.
Независимая практика
Продолжая работать с небольшой группой, переходите от ответов всей группы к индивидуальным ответам учащихся. Если вы работаете один на один, переходите от ответов учителя и учеников к индивидуальным ответам учеников. Отобразите новое изображение в верхнем поле. Попросите учащегося выбрать карточки с буквами для соответствующих звуков букв (или, если необходимо, распечатать буквы), а затем соединить звуки вместе, чтобы прочитать слово. Если студент не добился успеха во время самостоятельной практики, важно вернуться к моделированию и управляемой практике до тех пор, пока каждый студент не сможет правильно ответить.Если группа достигнет мастерства, подумайте о том, чтобы дополнить этот урок более сложными словами.
Адаптация инструкции по фонетике со словарными блоками для учащихся средних школ
Явный инструктаж по фонетике также может быть полезен для старших школьников, которым сложно определить слова (McDaniel, Houchins, & Terry, 2013; Warnick & Caldarella, 2016). Хотя явное обучение фонетике может показаться элементарным для учащихся средней школы, базовые звуковые навыки можно практиковать, используя многосложные слова, соответствующие возрасту и выученные в областях содержания (Casillas, Robbins, Allen, & Kuo 2012; Kim et al., 2017). Например, слово «концепция» может быть согласовано с текстами на уровне своего класса, которые учащиеся часто используют в своих классах. Выбор слов, имеющих отношение к учащимся, может повысить мотивацию и заинтересованность во время обучения акустике (Lovett, Lacerenza, De Palma, & Frijters, 2011).
Предыдущий подробный план урока может быть реализован путем замены буквенных карточек на слоговые карточки для обучения многосложным словам. Учитель выбирает слово, составленное из слоговых карточек, которое соответствует обычным звуковым образцам и типам слогов, которым учили учеников.Учитель представляет слово, состоящее из двух или более слоговых карточек. Учащиеся используют образец согласных и гласных для определения типа слога, который указывает, как должна произноситься гласная в слоге. После произнесения каждого слога отдельно ученики затем смешивают слоги вместе, чтобы произнести слово целиком.
Например, учитель может предъявить слоговые карточки «con» и «cept» (см. Рисунок 2). Студентов попросят определить, что одна гласная в слоге, за которой следует один или несколько согласных, указывает на то, что каждая карточка содержит закрытый слог.Гласные в закрытых слогах произносятся коротким звуком: / ŏ / и / ĕ /. Каждый слог начинается с буквы «с». Когда «c» предшествует гласным «a», «o» или «u», это обычно представляет звук / k /. Когда «c» предшествует гласным «e» или «i», это обычно означает звук / s /. Таким образом, учащиеся могут использовать свои знания о структуре букв для определения произношения гласной в слоге, а также первого согласного звука. После произнесения каждого слога отдельно ( con – cept ) ученики затем должны смешать слоги, чтобы идентифицировать слово целиком.
Рис. 2. Слоговые карточки
Качественное четкое и систематическое обучение фонетике сложно, но имеет решающее значение для учащихся, которые учатся читать, и тех, кому требуется вмешательство из-за трудностей с чтением (Ehri & Flugman, 2018). Отработка буквенно-звуковых соответствий с использованием поля слов и буквенных карточек или многосложных слов со слоговыми карточками – это примеры учебных инструментов, которые учителя могут применять явным и систематическим образом для поддержки развития чтения своих учеников.
Дополнительные материалы для учителей
Шаблон Word Box
Графический органайзер, предназначенный для помощи учащимся в определении того, какие буквы представляют звуки, слышимые в данном слове. На графике, представляющем слово, есть пробелы для каждого звука, который необходимо заполнить.
Список литературы
Брэди, С. (2011). Эффективность обучения акустике для результатов чтения: показания после исследования NRP. В S. Brady, D. Braze, & C. Fowler (Eds.), Объяснение индивидуальных различий в чтении: Теория и доказательства (стр.69–96). Нью-Йорк, Нью-Йорк: Психология Пресс.
Касильяс, А., Роббинс, С., Аллен, Дж., И Куо, Ю. Л. (2012). Предсказание ранней неуспеваемости в старшей школе на основе предыдущих академических достижений, психосоциальных характеристик и поведения. Журнал педагогической психологии , 104 , 407–420. DOI: 10.1037 / a0027180
Эри, Л. К. (2014). Орфографическое отображение в приобретении навыков чтения слов, орфографической памяти и изучения словарного запаса. Научные исследования чтения , 18 , 5–21.DOI: 10.1080 / 10888438.2013.819356
Эри, Л. К., и Флюгман, Б. (2018). Наставничество учителей в систематическом обучении фонетике: эффективность интенсивной годичной программы для детского сада через учителей 3-х классов и их учеников. Чтение и письмо: междисциплинарный журнал , 31 , 425-456. DOI: 10.1007 / s11145-017-9792-7
Кизи С., Конрад М. и Джозеф Л. М. (2015). Коробки со словами улучшают фонематическую осведомленность, буквенно-звуковые соответствия и орфографические навыки воспитанников из группы риска. Лечебное и специальное образование , 36 , 167-180. DOI: 10.1177 / 0741932514543927
Ким, Дж. С., Хемфилл, Л., Тройер, М., Томсон, Дж. М., Джонс, С. М., ЛаРуссо, М. Д., и Донован, С. (2017). Привлечение читателей-подростков к совершенствованию навыков чтения. Ежеквартальное исследование чтения , 52 , 357–382. DOI: 10.1002 / rrq.171
Ловетт, М. В., Ласеренца, Л., Де Пальма, М., и Фрайтерс, Дж. К. (2011). Оценка эффективности исправления проблем читателей в средней школе. Журнал нарушений обучаемости , 45 , 151–169. DOI: 10.1177 / 0022219410371678
МакДэниел, С. К., Хучинс, Д. Э. и Терри, Н. П. (2013). Коррекционное чтение как дополнительная учебная программа для студентов с эмоциональными и поведенческими расстройствами. Журнал эмоциональных и поведенческих расстройств , 21 , 240–249. DOI: 10.1177 / 1063426611433506
Мерфи, К. А., и Фаркухарсон, К. (2016). Изучение профилей лексического качества в дошкольных учреждениях и их вклада в чтение в первом классе. Чтение и письмо: междисциплинарный журнал , 29 , 1745-1770. DOI: 10.1007 / s11145-016-9651-y
Пелатти, К. Ю., Пяста, С. Б., Джастис, Л. М., и О’Коннелл, А. (2014). Возможности изучения языка и грамотности в классах для детей младшего возраста: типичный опыт детей и вариативность в классе. Early Childhood Research Quarterly , 29, 445-456. DOI: 10.1016 / j.ecresq.2014.05.004
Сеймур, П. Х. К., Аро, М., и Эрскин, Дж.М. (2003). Основы приобретения грамотности в европейской орфографии. Британский журнал психологии , 94 , 143–174.
Варник К. и Калдарелла П. (2016). Использование мультисенсорной акустики для развития навыков чтения у подростков-правонарушителей. Ежеквартально по чтению и письму , 32 , 317–335. DOI: 10.1080 / 10573569.2014.962199
Символика звукаоблегчает изучение слов в 14-месячном возрасте
Словарный анализ
Данные J-MCDI были получены от 28 из 34 родителей младенцев по почте в течение одного месяца после участия младенцев в эксперименте.Понимание на J-MCDI варьировалось от 9 до 287 слов ( Mdn = 51, M = 72,3, SD = 68,1), а отчетная производительность варьировалась от 0 до 73 слов ( Mdn = 3, M ). = 9,3, SD = 16,1). Понимание слов-заполнителей составило 50,9%, что означает, что в среднем младенцы знают только 2 из четырех слов-заполнителей. Таким образом, хотя нормы J-MCDI предполагали, что большинство 14-месячных японских младенцев должны знать слова, используемые для испытаний наполнителей, эти слова не были так знакомы младенцам в нашей выборке.
Более того, младенцы в условиях совпадения и несоответствия не различались по объему словарного запаса ни в понимании, ни в выражении, и не различались по сообщаемому количеству известных слов-заполнителей (использовался U-критерий Манна-Уитни, поскольку показатели MCDI не соответствовали критериям). нормально распределенный: понимание, U = 79,5, p = 0,40; выражение, U = 95,5, p = 0,91; знание слов-заполнителей, U = 98,0, p = 0,99 ).
Предварительные испытания и испытания по привыканию
Чтобы убедиться, что младенцы в условиях совпадения и несовпадения имели равное воздействие на целевые объекты перед переходом к последующим фазам эксперимента, мы рассчитали время, в течение которого младенцы в условиях совпадения и несовпадения смотрели на два испытания, содержащие целевые объекты во время эти предварительные этапы.Никаких различий не наблюдалось, т (29) = 1,08, р = 0,29.
Среднее количество испытаний, необходимых для достижения привыкания, составило 10,3 для условия соответствия ( SD = 3,7, диапазон: 6–16) и 9,6 для условия несовпадения ( SD = 4,9, диапазон: 6–23), что не различались в двух условиях ( т, (32) = 0,52, р, = 0,61). Все младенцы успешно приучаются.
Испытательные испытания
Объекты-заполнители: анализ динамики времени. Поскольку мы не прогнозировали различия между испытаниями наполнителей для младенцев в условиях совпадения и несовпадения, мы агрегировали данные по двум условиям для этого анализа. В предыдущем исследовании, посвященном оценке способности 14- и 15-месячных младенцев определять референсы знакомых слов, было подсчитано, что младенцы начинают фиксировать правильный объект примерно с 367 мс до 1800 мс – 2500 мс после появления первого экземпляр целевого слова [37,39,40,41]. Здесь мы выбрали аналогичную зависимую меру, а также аналогичное временное окно для анализа, которое использовалось в [36] и [40].Средняя доля взгляда на нужный объект (относительно времени взгляда на оба объекта) была рассчитана для всех младенцев в течение временного окна от 400 мс до 2000 мс после начала целевого слова, а затем сравнивалась со средней долей наблюдения за одним и тем же объектом в течение базового периода (т. е. периода 3000 мс, непосредственно предшествующего началу слова, в течение которого младенцы видели две фигуры бок о бок, не слыша звука). Эти пропорции в целевом временном окне нанесены в интервалы 100 мс на рис.2, поскольку мы не знаем заранее, как будет меняться внешнее поведение младенцев во времени.
Рис. 2. Среднее время просмотра нужного объекта с интервалами 100 мс.
В испытаниях наполнителя соответствие-несовпадение объединено. Исходный вид рассчитывался путем усреднения взглядов младенцев на целевой объект за 3000 мс непосредственно перед началом слова. Полоса ошибок указывает на стандартную ошибку.
https://doi.org/10.1371/journal.pone.0116494.g002
Результаты показали, что доля наблюдений за правильным объектом в течение целевого временного окна существенно не отличалась от таковой в течение базового временного окна (базовый уровень, М = 50.3%; целевое окно, M = 54,7%; t (33) = 1,55, p = 0,13, хотя визуальный анализ данных показывает, что более ограниченное временное окно могло дать более надежные результаты. Однако без какой-либо мотивации a priori для изменения временного окна анализа наша выборка 14-месячных японцев не показала явно никаких доказательств того, что они смотрели на правильный объект, когда слышали слова, мяч , банан , вагон , или книга .
Целевые объекты: анализ динамики движения. Как и в случае с объектами-наполнителями, средняя доля младенцев, которые смотрели на правильный объект по сравнению с обоими объектами (т. Е. Правильным объектом был тот, который ассоциировался с новым словом во время фазы привыкания), рассчитывалась для каждых 100 мс, начиная с от 400 мс до 2000 мс от начала целевого слова и был нанесен на график отдельно для условий совпадения и несовпадения на рис. 3.
Рис. 3. Среднее время наблюдения за правильным целевым объектом с интервалами 100 мс в тестовых испытаниях.
Исходный вид был рассчитан путем усреднения взглядов младенцев на целевой объект за 3000 мс непосредственно перед началом слова. Полоса ошибок указывает на стандартную ошибку.
https://doi.org/10.1371/journal.pone.0116494.g003
При тестовых испытаниях здесь был проведен тот же анализ временного окна, что и при испытаниях наполнителя. Анализ ANOVA 2 (исходное и целевое временное окно) X 2 (совпадение или несоответствие) проводили для средней пропорции, смотрящей на правильный объект.Как и в испытаниях наполнителя, целевое временное окно составляло 400 мс – 2000 мс после начала слова, а поиск базовой линии представлял собой временное окно 3000 мс непосредственно перед началом слова (рис. 4).
Рис. 4. Среднее время просмотра нужного объекта в каждом временном окне в тестовых испытаниях.
Расчет базовой линии обзора был таким же, как на рис. 3. Окно обзора цели было рассчитано путем усреднения взглядов младенцев на целевой объект от 400 мс до 2000 мс. Полоса ошибок указывает на стандартную ошибку.
https://doi.org/10.1371/journal.pone.0116494.g004
В соответствии с гипотезой самонастройки звукового символизма, взаимодействие между факторами Временного окна и Условием является значимым, F (1, 31) = 4,31, p = 0,046, η 2 = 0,11. Чтобы разделить это взаимодействие, в каждом временном окне были проведены два последующих множественных тестирования простого основного эффекта. Первый анализ показал отсутствие различий между младенцами в матче ( M = 48.6% при взгляде на правильный объект, SD = 14,6%) и условиях несоответствия ( M = 50,0% при взгляде на правильный объект, SD = 9,7%) во время базовой линии, F (1, 31) = 0,11, p = 0,75, η 2 = 0,003. Второй анализ показал, что младенцы в условиях соответствия (57,1% смотрели на правильный объект, SD = 10,0%) смотрели значительно дольше на правильный целевой объект, чем младенцы в условиях несовпадения ( M = 44.6% смотрят на правильный объект, SD = 13,8%) F (1, 31) = 8,83, p <. 025 (с поправкой Бонферонни), η 2 = 0,222. В совокупности эти результаты предполагают, что не было различий между условиями совпадения и несоответствия в базовый период, но эти дети превосходили детей с несоответствием в критическом временном окне после присвоения имени.
Альтернативный способ анализа этого взаимодействия – изучить изменения во временных окнах в каждой группе младенцев, используя тот же анализ, что и выше.В условиях совпадения пропорция, смотрящая на правильный объект, незначительно увеличивалась по временным окнам, F ( 1 , 31) = 3,25, p = 0,081, η 2 = 0,095. Однако в условиях несоответствия пропорция, смотрящая на правильный объект во временных окнах, не изменилась, F ( 1 , 31) = 1,29, p = 0,265, η 2 = 0,040. Эти результаты снова предполагают, что младенцы в условиях совпадения и несовпадения имели разные модели взгляда.
Результаты анализа ANOVA, безусловно, на согласуются с , что и ожидалось согласно гипотезе. Однако, когда рассматривается качественное представление данных, как показано на рис. 3, визуальная проверка данных позволяет предположить, что временной ход взгляда на целевой объект был другим при сравнении условий совпадения и несовпадения. В условиях совпадения младенцы, казалось, смотрели на нужный объект в первой части временного окна (примерно от 800 мс до 1000 мс после начала слов).Однако после этого их внимание постепенно снижается до уровня вероятности (50%). В условиях несоответствия младенцы, казалось, смотрели на оба объекта одинаково в первой части временного окна, но их взгляд на нужный объект постоянно снижался на протяжении всего времени, оставаясь на уровне чуть ниже 50%.
Эти визуальные осмотры предполагают, что младенцы в состоянии соответствия показали раннее распознавание названного объекта, но младенцы с несоответствием не распознали, вместо этого постепенно проявляя тенденцию смотреть на другой, необученный объект, который по звуку символически соответствовал звук.Анализ ANOVA для всего временного окна (400–2000 мс), приведенный выше, игнорирует эти различия во времени. Для дальнейшего изучения наших данных мы обратились к байесовскому анализу времени взгляда, чтобы лучше оценить вклад динамических моделей взгляда младенцев в наш экспериментальный вопрос.
Целевые объекты: байесовский анализ. Приведенный выше анализ временного окна предполагает, что младенцы в состоянии соответствия превосходили детей в состоянии несоответствия, больше глядя на обученный объект, когда слышали целевое слово.Однако анализ с использованием традиционных линейных моделей, таких как ANOVA, накладывает некоторые ограничения на наш набор данных, в котором данные о младенцах динамически меняются с течением времени по разным образцам, которые также могут отличаться в зависимости от сравниваемых условий. Таким образом, мы используем байесовский анализ для устранения некоторых недостатков анализа временных окон, описанного выше.
Во-первых, анализ временного окна игнорирует динамические шаблоны, поскольку неявная идея этого анализа состоит в том, что взгляд младенцев на целевой объект не меняется интересным образом в пределах заранее определенного временного окна.Однако рис. 3 ясно показывает, что в нашем случае это предположение не выполняется. Это усугубляет более общую озабоченность по поводу уместности нашего временного окна 400–2000 мс. Действительно, мы выбрали это временное окно на основе предыдущей работы по изучению распознавания слов и обучаемости у 14-месячных младенцев в аналогичных парадигмах [37,41], но существуют большие разногласия относительно подходящего места начала и смещения временного окна, когда анализ обучения и распознавания слов в возрасте от 12 до 15 месяцев [39,40,42,43,44].
Во-вторых, еще не ясно, действительно ли разница между условиями совпадения и несовпадения может быть объяснена влиянием звуковой символики на тренировку. Например, разница между двумя условиями может просто отражать глобальное предпочтение смотреть на объект, звук которого символически соответствует метке, независимо от условия обучения. (Обратите внимание, что в условии несоответствия [неправильный] элемент-отвлекающий элемент в тестовых испытаниях также является звуковым символически совпадающим словом).Тем не менее, эта альтернативная интерпретация кажется маловероятной с учетом данных на рис. 3: время просмотра звукового символьно совпадающего объекта (т. Е. Обученного объекта для условия соответствия и необученного объекта в условии несовпадения) должно быть равным. симметрично, если бы один и тот же механизм работал в обоих условиях. Паттерны, наблюдаемые на рис. 3, указывают на иное, но анализ временного окна, использованный в предыдущей работе по оценке предпочтительного взгляда у младенцев, не может статистически разделить эти две интерпретации.
Чтобы обойти проблемы, описанные выше, мы провели байесовский анализ, аналогичный тому, который был предложен Юровским и др. [45]. Их анализ имеет по крайней мере три преимущества перед традиционными линейными моделями для просмотра данных во времени. Во-первых, внешнее поведение анализируется как непрерывный временной ряд. Это означает, что вместо усреднения времени просмотра по заранее определенному временному окну для анализа используются все точки покадровых данных. Анализ определяет оптимальное «временное окно» для данной экспериментальной установки посредством оценки параметров набора данных.Во-вторых, вместо предположения о линейном увеличении или уменьшении времени просмотра этот анализ рассматривает вероятность просмотра как полиномиальную функцию времени с множеством факторов в качестве коэффициентов. С помощью нелинейного моделирования поведения при взгляде эффекты экспериментальной манипуляции можно отделить от других вспомогательных факторов, таких как предвзятость реакции младенцев. В-третьих, традиционные линейные модели просто учитывают индивидуальные различия во внешнем виде младенцев (например, предпочтение смотреть в определенное место на мониторе, предпочтение смотреть на конкретный объект, вероятность сместить взгляд и т. Д.)) как экспериментальный шум, который снижает статистическую мощность для обнаружения интересующего экспериментального эффекта. В результате критический экспериментальный эффект может быть смыт. В отличие от этого, байесовская модель Юровского и др. Способна рассматривать детализированные характеристики ответа для конкретной подгруппы младенцев путем классификации участников с похожими внешними моделями в кластеры и оценки групповых параметров.
При анализе наших данных гипотетические отношения между набором экспериментальных факторов (т.д., эффекты, вызванные экспериментальными манипуляциями: обучение, звуковая символика во время теста и их взаимодействие), вспомогательные факторы (т. е. склонность смотреть на конкретный объект или конкретное место на мониторе) и потенциальные модели поведения (т. е. , время просмотра) выражаются в виде статистической модели с набором параметров, которые оцениваются путем подгонки модели к набору данных. Модель состоит из набора параметров, которые также включают параметры предпочтений для факторов, которые потенциально могут повлиять на вид определенной области интереса (AOI) в данный момент: предпочтение отдельных младенцев смотреть на определенное место (т.е., влево или вправо или ни в коем случае), предпочтение смотреть на конкретный объект, предпочтение смотреть на «правильный» объект, с которым была связана метка, или предпочтение смотреть на объект, который звучит символически совпадающим. Эти параметры были оценены по отношению к индивидуальной дисперсии испытуемых с использованием иерархической байесовской модели (подробности см. В приложении S2).
Данные просмотра каждого кадра видео из всех целевых испытаний были классифицированы как просмотр левого AOI, правый AOI или «без просмотра».Поскольку эта модель включала информацию о том, что ребенок не смотрит, а также о предпочтениях младенцев в отношении определенного объекта, критерии исключения из анализа ANOVA (раздел 2.6 выше) больше не применялись. Вместо этого покадровый подсчет для всего испытания был проанализирован как функция пяти факторов: предпочтения, зависящего от местоположения, предпочтения, зависящего от объекта, «правильного» (обученного) предпочтения объекта, предпочтения звуковой символики и многих других. что важно, взаимодействие между обучением и звуковым символическим соответствием, которое указывает на эффект начальной загрузки звуковой символики для обучения.
Предпочтение, зависящее от местоположения, определяется как склонность смотреть на определенную сторону экрана. Предпочтение объекта – это склонность смотреть в сторону определенного объекта. Остальные три фактора являются факторами, имеющими непосредственное отношение к экспериментальным манипуляциям. Правильное предпочтение объекта – это предпочтение смотреть на объект, с которым метка была связана во время фазы привыкания. Предпочтение звуковой символики – это тенденция смотреть на звук, символически соответствующий объекту (метке, услышанной в испытании) после начала речи (т.е. предпочтение остроконечного предмета после начала речи «кипи» или предпочтение круглому предмету после «мома»). Наконец, эффект взаимодействия – это совместный эффект обучения и звуковой символики, который нельзя объяснить только эффектом звуковой символики или только эффектом обучения, что было критическим эффектом, представляющим интерес в данном анализе.
Результаты байесовского анализа
Мы смоделировали вероятность взгляда на объект (после начала целевого слова) в зависимости от его различных свойств: трех экспериментальных факторов (обучение, звуко-символическое соответствие при тестировании и взаимодействие обучение-звук-символизм). , влияние которых, как предполагалось, изменялось в зависимости от времени в ходе испытания, два дополнительных фактора предпочтения (форма объекта и местоположение объекта), как предполагалось, были постоянными во времени.Мы оценили, должна ли модель включать все три экспериментальных фактора и какой тип временной зависимости трех экспериментальных факторов (линейная, квадратичная или кубическая функция времени) был оптимальным. Чтобы сравнить эти возможные модели, мы запустили серию (байесовских) моделей, в которых изучались факторы, связанные с экспериментом (см. Таблицу 1).
При проверке байесовской гипотезы каждая модель определяет вероятность для гипотезы воспроизвести текущий набор данных. В процессе подбора модели мы оценили набор параметров для всех пяти факторов, описанных выше (т.д., три экспериментальных фактора и два фактора, отражающие индивидуальные предубеждения), но мы приводим здесь только релевантные для эксперимента факторы (т.е. тренировку, соответствие звука и символа при тестировании, и факторы взаимодействия обучения, звука и символики).
Эффект каждого фактора оценивается с помощью байесовского фактора ([46] См. Также [47] обзор психологических исследований). Согласно Джеффрису (1961), «[т] байесовский фактор (BF) X модели A – B с учетом набора данных указывает на то, что отношение шансов для модели A для воспроизведения набора данных составляет X . раз выше, чем у модели B , чтобы сделать это при даже априорной вероятности для каждой модели.Здесь мы используем производную от BF, log-BFβ, которая указывает, что вероятность воспроизведения данных в exp (β) раз выше по сравнению с базовой моделью. BF от 3 до 10 (log-BF от 1,1 до 2,3) указывает на «существенные» доказательства гипотезы, BF от 10 до 30 (log-BF от 2,3 до 3,4) указывает на «сильные» доказательства, а BF выше 30 (log-BF больше 3,4) указывает на «очень сильные» доказательства [46]. В настоящем исследовании мы считали, что значения log-BF, превышающие 3,4, являются убедительным свидетельством того, что модель A предпочтительнее модели B в соответствии с критерием Джеффриса (1961).
В таблице 1 показаны результаты нашей процедуры подбора модели (в предварительном анализе мы проанализировали 16 возможных моделей, пересекающих уровень сложности (P1, P2, P3 и P4) с типом модели (полная, NoSS, NoTr и NoInt). Здесь мы снова обнаружили, что P2-полная модель лучше всего подходит, но только 6 из этих моделей показаны в таблице 1 из-за допущений, лежащих в основе априорной функции разреженности (см. Текст), и из соображений риторической простоты). . Первые три модели – P1-полная, P2-полная и P3-полная модели – были полными моделями, в которые были включены все три экспериментальных фактора.Эти три модели предполагали разные уровни сложности в своих функциях поиска вероятности. Модель P1-full предполагает полиномиальную функцию первого порядка, а модели P2-full и P3-full принимают полиномиальную функцию второго и третьего порядка соответственно. Мы сравнили три модели, чтобы определить оптимальную полиномиальную функцию. Анализ log-BF показывает, что полиномиальная функция второго порядка (т. Е. Средняя степень сложности: P2-полная) значительно предпочтительнее относительно простой модели (от P2-полной до P1-полной: log-BF 27.584) или над сложной моделью (от P2-full до P3-full: log-BF 247.378). Поэтому мы использовали модель P2-full в качестве базовой модели, с которой сравнивали каждую из моделей подмножества.
Поскольку текущая модель использует «априорную функцию разреженности», которая адаптивно удаляет ненужные параметры, не влияющие на восстановление данных, текущая модель смещена в сторону более простых моделей. Таким образом, маловероятно, что избыточные модели с ненужными параметрами будут выбраны ошибочно.Вот почему мы не включили модели, которые проще, чем перечисленные в таблице 1, и считаем, что протестированные модели, перечисленные в таблице 1, охватывают все возможные модели, которые следует учитывать. Более того, модели P4 или выше также маловероятны, когда модели P3 (n = 3) оцениваются как худшие, чем модели P2. Таким образом, мы не указываем модели P4 или более сложные модели, поскольку они даже более избыточны, чем модели P3.
В модели P2-NoSS (без звуковой символики) фактор звуковой символики удален и сравнивался с моделью P2-full.Точно так же модель P2-NoTr (без обучения) исключает фактор обучения из полной модели, а сравнение между моделью P2-full и P2-NoTr (без обучения) позволило нам оценить эффект одного обучения. Модель P2-NoInt включает фактор звуковой символики и фактор обучения, но взаимодействие исключено. Эта модель была наиболее важной, так как здесь мы можем оценить, улучшал ли звуковой символизм тренировку сверх эффектов тренировки и / или только звуковой символики.
Анализ байесовских факторов показал, что модель P2-full имеет сильное преимущество перед моделями P2-NoSS (logBF 119,609), P2-NoTr (log-BF 92,546) и P2-NoInt (log-BF 109,625). Таким образом, результаты показывают, что эффекты звуковой символики, обучения и взаимодействия между звуковой символикой и обучением существенно повлияли на соответствие модели. Другими словами, младенцы имели тенденцию смотреть на обученный объект независимо от того, соответствовал ли этот объект звуку символически или нет.Более того, звуковая символика влияла на внешний вид младенцев, независимо от того, были ли младенцы обучены звуковому символически совпадающему объекту. Наконец, байесовский анализ также установил, что эти факторы взаимодействуют. В сочетании с рис. 3 это предполагает, что звуковая символика обеспечивает дополнительный импульс тренировке, особенно в первые 800 мс, так что эффект тренировки был сильнее для младенцев в условиях совпадения, чем у детей в условиях несовпадения. Подробности предполагаемых эффектов обучения, звуковой символики и взаимодействия показаны в Приложении S3.
Звуки речи | Лингвистическое общество Америки
Моррис Халле
Идентификационные слова
Когда мы говорим, мы говорим слова, а когда мы говорим с ними, мы слышим слова. В обычном разговоре, однако, мы не разделяем — слова — короткими — паузами, а скорее вставляем одно слово в другое. Тем не менее, несмотря на это, мы все еще слышим высказывания, состоящие из отдельных слов. Почему так должно быть?
Ключ к разгадке заключается в том, что для того, чтобы мы могли слышать слова, произнесение должно быть на известном нам языке; в высказываниях на незнакомом нам языке мы не слышим слов.Точно так же, когда мы слышим последовательность бессмысленных слогов, мы не можем сказать, состоит она из одного или нескольких слов. Поэтому знание языка имеет решающее значение.
В некотором смысле это не удивительно. Каждый, кто изучал иностранный язык, знает, что изучение слов – важная часть овладения языком. Знания слов недостаточно, но, безусловно, необходимо. Когда мы изучаем слово, мы сохраняем в своей памяти информацию, которая позволяет нам как произнести слово, так и распознать его, когда он произносится кем-то другим.И причина того, что мы не слышим слова, когда мы говорим на иностранном языке, заключается в том, что мы их не выучили, у нас их нет в нашей лингвистической памяти, то есть в той части нашей памяти, которая посвящена языку.
Разговор
Правдоподобный рассказ об акте говорения может выглядеть следующим образом. Ораторы выбирают из своей памяти слова, которые они хотят сказать. Затем они выполняют особый вид гимнастики с помощью органов речи или артикуляторов, то есть языка, губ, велума и гортани.В результате гимнастики возникает акустический сигнал, который слышат и говорящий, и собеседники. Поскольку при выполнении гимнастики говорящие не делают паузы в конце каждого слова, слова в высказывании сталкиваются друг с другом. Эта модель речи представлена графически ниже:
Слова в памяти >>> Артикуляционное действие >>> Акустический сигнал
Есть некоторые свидетельства того, что, когда мы слышим речь, активируется тот же процесс, но в обратном направлении. Акустический сигнал ударяет в наши уши; мы интерпретируем сигнал в терминах артикуляционных действий, которые его породили, и мы используем эту интерпретацию – а не сам акустический сигнал – для доступа к нашей памяти.
Теперь рассмотрим гимнастику, которую мы выполняем, произнося английские слова «meet» и «Mott». В обоих словах мы начинаем с действия, закрывающего ротовую полость губами, и заканчиваем действием, когда лезвие языка закрывает ротовую полость в точке в передней части твердого неба. Между этими двумя действиями находится действие тела языка: тело языка поднимается и продвигается вперед в «встрече» и опускается и втягивается в «Мотте», однако, не закрывая полость. Таким образом, производство этих слов состоит из различных действий трех разных артикуляторов.Более того, действия должны выполняться в указанном порядке: если порядок трех действий меняется на противоположный, появляются разные слова, а именно, команда, Том. Факты такого рода мотивируют гипотезу о том, что слова, которые мы произносим, состоят из дискретных звуков или фонем.
слов в памяти
Как отмечалось выше, слова запоминаются и сохраняются в нашей лингвистической памяти. Если слова, которые мы произносим, состоят из дискретных звуков, то разумно предположить, что слова в памяти также состоят из последовательностей дискретных звуков.Научное изучение языка решительно поддерживает это предположение, хотя доказательства и аргументация слишком сложны, чтобы приводить их здесь.
Произнося слово, мы актуализируем последовательность дискретных звуков, хранящихся в памяти, как последовательность действий наших артикуляторов. Поскольку, как и в случае с другими человеческими действиями, речь может иметь ограничения по точности, следует ожидать, что произойдёт некоторая проскальзывание и что дискретность звуков будет в некоторой степени скомпрометирована в высказывании.Фактически, рентгеновские кинофильмы речи показывают, что действия артикуляторов при воспроизведении данного звука не начинаются и не заканчиваются в одно и то же время. Однако это проскальзывание не мешает слушателю распознавать слова, то есть получать к ним доступ в памяти. Инерция артикуляторов, конечно, не единственный фактор, из-за которого речевой сигнал не может точно воспроизвести различные аспекты слова, представленные в памяти. Другими факторами являются высокая скорость речи и различные провалы в памяти.
Несмотря на то, что отрыжка, зевание, кашель, звук задуваемой свечи и многие другие шумы производятся действиями артикуляторов, они не воспринимаются как последовательности фонем, даже если они могут быть неразличимы акустически и артикуляторно от произнесения последовательностей фонем. Не будучи словами, эти шумы не сохраняются в той части нашей памяти, которая посвящена словам. Предполагая, что только элементы, хранящиеся в лингвистической памяти, состоят из фонем, мы объясняем, почему отрыжка, зевание и т. Д.не воспринимаются как последовательности фонем.
В целом звуки речи являются составными частями слов, а особенность слов в том, что только слова представляют собой последовательности звуков речи.
Рекомендуемая литература
Halle, Morris. 1992. «Фонологические особенности». Международная энциклопедия языкознания, Vol. III, изд. Уильям Брайт, 207-11. Оксфорд: Издательство Оксфордского университета.
Ладефогед, Питер и Ян Мэддисон. 1996. Звуки языков мира. Оксфорд, Великобритания и Кембридж, Массачусетс: Блэквелл.
Маккарти, Джон Дж. 1988. “Геометрия объектов и зависимости: обзор”. Фонетика 45 . 84-108.
Основные концепции распознавания речи – CMUSphinx Open Source Speech Recognition
Речь – сложное явление. Люди редко понимают, как это производится и воспринимается. Наивное восприятие часто состоит в том, что речь построена из слов и каждое слово состоит из телефонов. К сожалению, в действительности все обстоит иначе. Речь – это динамический процесс без четко выделенных частей.Это всегда Полезно обзавестись звуковым редактором и посмотреть запись речи и Послушай это. Вот, например, запись речи в аудиоредакторе.
Все современные описания речи в той или иной степени вероятностны. Это означает что нет определенных границ между единицами или словами. Обращение к перевод текста и другие приложения речи никогда не бывают правильными на 100%. Что идея довольно необычна для разработчиков программного обеспечения, которые обычно работают с детерминированные системы.И это создает множество проблем, связанных только с речью. технология.
Структура речи
В современной практике под структурой речи понимают:
Речь – это непрерывный аудиопоток, в котором достаточно стабильные состояния смешиваются с динамически изменяемые состояния. В этой последовательности состояний можно определить несколько или меньше аналогичных классов звуков, или телефонов. Слова понимаются как построенные телефонов, но это, конечно, не так. Акустические свойства форма волны, соответствующая телефону, может сильно различаться в зависимости от многих факторов – телефонный контекст, динамик, стиль речи и так далее.Так называемая коартикуляция заставляет телефоны звучать совсем иначе, чем их «каноническое» представление. Следующий, поскольку переходы между словами более информативны, чем стабильные области, разработчики часто говорят о дифонах – части телефонов между двумя последовательные телефоны. Иногда разработчики говорят о субфонетических единицах – разные подсостояния телефона. Часто три или более регионов разных природу можно найти.
Число три легко объяснить: первая часть телефона зависит от его предыдущий телефон, средняя часть стабильна, а следующая часть зависит от последующий телефон.Вот почему в телефоне часто бывает три состояния выбран для распознавания речи.
Иногда телефоны рассматриваются в контексте. Такие телефоны в контексте называются трифона или даже квинфона . Например, «u» с левым телефоном «b» и правый телефон «d» в слове «плохой» звучит немного иначе, чем то же самое телефон «u», левый телефон «b» и правый телефон «n» в слове «запретить». Обратите внимание, что в отличие от дифонов, они соответствуют тому же диапазону формы волны, что и просто телефоны.Они просто различаются по названию, потому что описывают немного разные звуки.
Для вычислительных целей полезно обнаруживать части трифонов вместо трифоны в целом, например, если вы хотите создать детектор для начало трифона и передать его на многие телефоны. Все разнообразие детекторы звука могут быть представлены небольшим количеством отчетливого короткого звука детекторы. Обычно мы используем 4000 различных детекторов коротких звуков для составления детекторы для телефонов. Мы называем эти детекторы сенонами .Сеноне зависимость от контекста может быть более сложной, чем просто левый и правый контекст. Это может быть довольно сложная функция, определяемая деревом решений, или другие способы.
Далее, телефоны строят подсловные единицы, например слоги. Иногда слоги определены как «устойчивые к редукции объекты». Например, когда речь становится быстро, телефоны часто меняются, но слоги остаются прежними. Также слоги относящийся к интонационному контуру. Есть и другие способы построения подслов – на основе морфологии (в языках с богатой морфологией) или на основе фонетики.7 слов. К счастью, даже люди с богатый словарный запас, на практике редко используется более 20 тыс. слов, что делает способ распознавания более осуществимый.
слов и других неязыковых звуков, которые мы называем наполнителями (дыхание, ммм, кашель), форма высказывания . Это отдельные фрагменты звука между пауза. Они не обязательно соответствуют предложениям, которые являются более семантическими понятиями.
Вдобавок к этому есть диалоги, похожие на повороты, но они выходят за рамки цель этого документа.
Процесс распознавания
Распространенный способ распознавания речи следующий: мы берем форму волны, разбиваем ее при произнесении молчанием, а затем попытайтесь распознать, что говорится в каждом высказывание. Для этого мы хотим взять все возможные комбинации слов и попробуйте сопоставить их со звуком. Выбираем наиболее подходящую комбинацию.
В этом процессе сопоставления есть несколько важных концепций. В первую очередь это концепт с особенностями . Поскольку количество параметров равно большой, мы пытаемся его оптимизировать.Числа, рассчитываемые по речи обычно путем разделения речи на кадры. Затем для каждого кадра, как правило, Длина 10 миллисекунд, мы извлекаем 39 чисел, которые представляют речь. Это называется вектором признаков . Способ генерации количества параметров является предметом активного исследования, но в простом случае это производная из спектра.
Во-вторых, это концепция модели . Модель описывает некоторые математические объект, который собирает общие атрибуты произнесенного слова.На практике для аудиомодель сенона – это гауссовская смесь его трех состояний – положить это просто, это наиболее вероятный вектор признаков. Из концепции модели возникают следующие вопросы:
- насколько хорошо модель описывает реальность,
- можно ли улучшить модель с учетом внутренних проблем модели и
- насколько адаптивна модель при изменении условий
Модель речи называется Hidden Markov Модель или HMM. Это общий модель, описывающая канал связи черного ящика.В этой модели процесс описывается как последовательность состояний, которые сменяют друг друга с определенным вероятность. Эта модель предназначена для описания любого последовательного процесса, например речь. Было доказано, что HMM действительно практичны для декодирования речи.
В-третьих, это сам процесс сопоставления. Поскольку это займет больше времени чем существовала вселенная для сравнения всех векторов признаков со всеми моделями, поиск часто оптимизируется с помощью множества уловок. В любой момент мы поддерживаем наиболее подходящие варианты и расширяйте их со временем, создавая лучшие варианты соответствия для следующего кадра.
Модели
По структуре речи в распознавании речи используются три модели. для совпадения:
Акустическая модель содержит акустические свойства для каждого сенона. Есть контекстно-независимые модели, содержащие свойства (наиболее вероятная функция векторов для каждого телефона) и контекстно-зависимые (построенные из сенонов с контекст).
Фонетический словарь содержит отображение слов на телефоны. Это отображение не очень эффективен.Например, всего два-три варианта произношения отмечены в нем. Однако в большинстве случаев это достаточно практично. Словарь это не единственный метод сопоставления слов с телефонами. Вы также можете использовать сложная функция, изученная с помощью алгоритма машинного обучения.
Языковая модель используется для ограничения поиска слов. Он определяет, какое слово может следовать за ранее распознанными словами (помните, что соответствие – это последовательный процесс) и помогает значительно ограничить процесс сопоставления за счет удаление слов, которые не являются вероятными.Наиболее распространенные языковые модели: n-граммные языковые модели – они содержат статистику последовательностей слов – и конечные модели государственного языка – они определяют речевые последовательности с помощью конечной автоматизации, иногда с весами. Для достижения хорошей точности ваша языковая модель должна быть очень успешным в ограничении пространства поиска. Значит, должно быть очень хорошо предсказывает следующее слово. Языковая модель обычно ограничивает словарный запас, который считается содержащимся в нем словами. Это проблема для узнавания имени.Чтобы справиться с этим, языковая модель может содержат более мелкие фрагменты, такие как подслова или даже телефоны. Обратите внимание, что поиск ограничение пространства в этом случае обычно хуже, и соответствующее распознавание точность ниже, чем у словесной языковой модели.
Эти три объекта объединены вместе в механизме распознавания речи. Если вы собираетесь применить свой движок для другого языка, вам нужно получить такие конструкции на месте. Для многих языков существуют акустические модели, фонетические словари и даже языковые модели с большим словарным запасом, доступные для скачать.
Прочие использованные концепции
A Lattice – ориентированный граф, представляющий варианты распознавания. Часто найти наилучшее совпадение непрактично. В таком случае решетки хороши промежуточные форматы для представления результата распознавания.
N-лучших списков вариантов подобны решеткам, хотя их представления не такие плотные, как решетчатые.
Сети путаницы слов (сосиски) – это решетки, в которых строгий порядок узлы взяты с ребер решетки.
База данных речи – набор типовых записей из базы данных задачи. Если мы разработать диалоговую систему, это могут быть диалоги, записанные от пользователей. Под диктовку система может читать записи. Речевые базы данных используются для обучения, настройки и протестировать системы декодирования.
Текстовые базы данных – образцы текстов, собранные, например, для языковая модель обучения. Обычно базы данных текстов собираются в виде образцов текста. Проблема с такой коллекцией помещать настоящие документы (например, PDF-файлы, веб-страницы, сканы) в устную текстовую форму.То есть нужно убрать теги и заголовки, развернуть числа в их устную форму и для расширения сокращений.
Что оптимизировано
При разработке распознавания речи самая сложная проблема – сделать поиск точный (рассмотреть как можно больше вариантов для совпадения) и сделать его достаточно быстро, чтобы не бегать целую вечность. Поскольку модели не идеальны, возникает еще одна проблема. заключается в том, чтобы модель соответствовала речи.
Обычно система тестируется на тестовой базе данных, которая предназначена для представления правильно поставить задачу.
Используются следующие характеристики:
Частота ошибок в словах. Предположим, у нас есть исходный текст и распознавание текст длиной N слов. I – количество вставленных слов, D – количество удаленных слов, а S – количество замененных слов. слова. Таким образом, коэффициент ошибок в словах можно рассчитать как
.WER = (I + D + S) / N
WER обычно измеряется в процентах.
Точность. Это почти то же самое, что и частота ошибок в словах, но не учтите прошивки.
Точность = (N – D – S) / N
Для большинства задач точность хуже, чем WER, так как прошивки также важны для конечных результатов. Однако для некоторых задач точность является разумной мерой производительности декодера.
Скорость. Предположим, аудиофайл имеет время записи (RT) 2 часа и расшифровка заняла 6 часов.Тогда скорость считается как 3xRT.
Кривые ROC. Когда мы говорим о задачах обнаружения, бывают ложные срабатывания и попадания / промахи. Чтобы проиллюстрировать это, кривые ROC используются. Такая кривая представляет собой диаграмму, описывающую количество ложных срабатываний. по сравнению с количеством попаданий. Он пытается найти оптимальную точку, в которой число ложных срабатываний невелико, а количество срабатываний соответствует 100%.
Есть и другие свойства, которые не часто принимаются во внимание, но все же важен для многих практических приложений.Ваша первая задача должна состоять в том, чтобы построить такую меру и систематически применять ее при разработке системы. Ваш Вторая задача – собрать тестовую базу данных и протестировать, как ваше приложение выполняет.
Введение в учебное пособие Обзор набора инструментов CMUSphinx
.