Ассоциации к буквам алфавита: «Живые» буквы и красочные пазлы: учим алфавит с помощью ассоциаций
«Живые» буквы и красочные пазлы: учим алфавит с помощью ассоциаций
Екатерина Ушахина
Друзья, сегодня мы расскажем вам о долгожданной новинке — «Азбуке. Живые буквы». Эта азбука очень необычная. Она состоит из ярких пазлов, а все буквы в ней «живые», они похожи на предметы, людей и животных, с ними можно играть и весело проводить время.
Буквы и пазлыАзбука — это набор из пар карточек, которые соединяются между собой как пазлы: на одной карточке изображена буква, а на второй — симпатичная картинка-ассоциация. Вас ждет 33 пары красивых карточек.
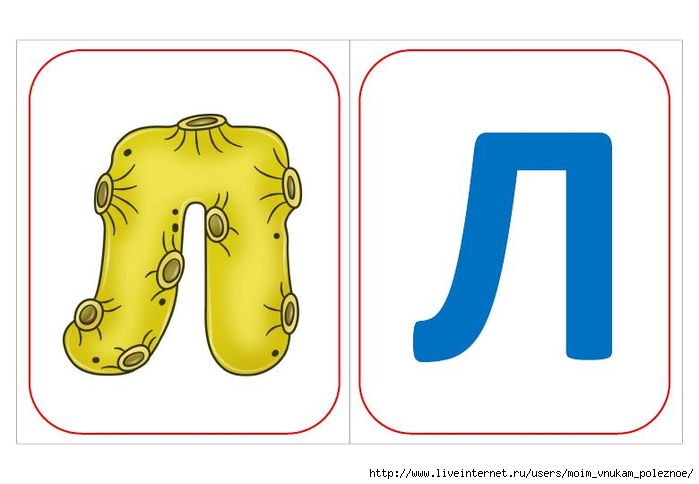
Буква «А» — как клюв у аиста. «Б» — как толстый бегемотик. «Д» — ну очень похожа на дом.
Правда, очень весело? А еще — полезно и эффективно. Ведь такой подход задействует ассоциативную память ребенка.
Картинка-ассоциация, подобранная к букве, по своей форме очень похожа на саму букву. Так что в процессе игры с карточками в памяти ребенка формируется ассоциация «картинка — форма буквы — название буквы», которые обязательно всплывут в памяти малыша в нужный момент.

К тому же, азбука интерактивная, с пазлами. А все знают, как дети их обожают. Вариант с пазлами хорош тем, что дает возможность ребенку самостоятельно подбирать картинки-ассоциации к букве, называть ее и проверять себя же. То есть соблюдается принцип активной познавательной деятельности.
Как родились живые буквыАвтор «Азбуки» Юлия Тараканова — педагог, психолог, специалист по эйдетике (методике развития образной и ассоциативной памяти через специальные упражнения). Она более 18 лет успешно обучает малышей буквам, используя ассоциативный метод.
А все началось с так:
Идея рисунков-ассоциаций для запоминания пришла мне в голову, когда я была десятилетней девочкой и лежала в больнице. Я помогала няне присматривать за малышами. У одной двухлетней девочки была нарисованная папой азбука с картинками. Малышка с огромным удовольствием ее всем показывала и называла буквы. Я поступила так же со своей младшей сестренкой Машей, применив еще и свои идеи с письмами от белочки, которые подкладывала в почтовый ящик.
Идея настоящей ассоциативной азбуки возникла у меня значительно позднее, в 1997 году, когда в «Московской Школе Эйдетики» я изучала приемы запоминания, основанные на умении создавать в памяти яркие образы.
При создании «Азбуки» Юлия Тараканова использовала только те ассоциации, которые ей подсказали маленькие ученики, поэтому они будут близки и вашему ребенку.
Веселые урокиПосле обучения в школе эйдетики я попробовала с полуторагодовалой дочерью методы ассоциаций на практике. Очень удивилась, что малыши и в этом возрасте способны создавать собственные ассоциации. Например, к букве «В» дочка придумала сама, что это старший брат Вовка едет на велосипеде. Моя племянница Соня в возрасте двух лет букву «Л» превратила в горку, с которой скатывалась ее бабушка Лера. Много идей подарили мне двухлетки из Саратовского детского клуба «Словечко». Я просила их придумать, на что или на кого похожи буквы. Так копились детские ассоциации.
«Азбука» получилась яркой и красивой, с симпатичными картинками. Все пазлы спрятаны в небольшую удобную коробочку (12×17 см), которую можно брать с собой, например, чтобы поиграть с ребенком в дороге.
Все пазлы спрятаны в небольшую удобную коробочку (12×17 см), которую можно брать с собой, например, чтобы поиграть с ребенком в дороге.
Очертания букв на картинках выпуклые, они специально покрыты лаком для тактильного знакомства. Причем как сами буквы, так и элементы ассоциаций, которые повторяют их форму.
У каждого пазла есть свой уникальный «замочек». Если ребенок подберет неправильную ассоциацию к букве, то пазл попросту не сложится.
Вместе с карточками в наборе идет подробная инструкция для родителей, как правильно учить с малышом алфавит.
Вот несколько коротких советов:
— Для более эффективного запоминания знакомьте ребенка не более чем с семью буквами за один раз.
— Произносите только звук, которые обозначает буква, а не название буквы.
— Просите малыша обвести буквы пальчиком.
— Показывайте ребенку слово под картинкой. Обращайте его внимание на первую букву слова.
Поиграем?«Живые буквы» сами по себе интерактивные и игровые, но кроме этого автор предлагает занятия с пазлами, которые помогут сделать обучение эффективнее.
— Разложите перед малышом вразброс карточки со знакомыми буквами. Показывайте и называйте буквы по одной и просите найти то, на что они похожи. После того, как ребенок найдет пару, попросите его соединить половинки пазлов.
— Игра наоборот. Показывайте ребенку по одной карточке с ассоциациями и говорите, что на ней нарисовано. Попросите малыша найти и назвать букву, на которую похожа картинка. Соедините пазл.
— Когда малыш выучит алфавит, разложите перед ним все карточки рубашками вверх. Переворачивайте любую карточку (букву или картинку-образ) и просите ребенка подобрать к ней пару. При этом малыш обязательно должен назвать букву, которую ищет.
— Во время обучения используйте игрушки и предметы, которые иллюстрируют ассоциации, изображенные на карточках. Это поможет быстрее запомнить буквы.
— Если малыш предлагает свои ассоциации к буквам, используйте их во время занятий. Создавайте собственные образы букв, рисуйте их или лепите.
— Для игры можно использовать и обратную сторону пазлов, на которой изображены картинки-ассоциации. Во время изучения той или иной буквы предлагайте ребенку искать ассоциацию на рубашке пазла.
Во время изучения той или иной буквы предлагайте ребенку искать ассоциацию на рубашке пазла.
— Дома, во время прогулок и поездок обращайте внимание ребенка на буквы вокруг себя. Только тогда, когда малыш будет узнавать буквы везде, вы можете быть уверены, что он освоил алфавит.
Проверено!Изучение алфавита с помощью ассоциаций очень эффективно. Мы проверили. Пока художник книги Маша Сергеева рисовала иллюстрации к азбуке, ее 2-летний сын по эскизам выучил весь алфавит.
Юлия Тараканова сейчас живет в Америке и использует ассоциативный метод и в обучении детей-билингвов.
В Америке мне приходится обучать двуязычных малышей русской азбуке. Дана, которая говорит уже на трех языках, к трехлетнему возрасту не была знакома с русскими буквами. Она приезжает ко мне на занятия два или три раза в неделю. И между другими важными делами мы играем в буквы. Достаточно было двух недель, чтобы она запомнила русские буквы.
С помощью метода ассоциаций Юлия Тараканова учит с детьми не только русские буквы, но английский алфавит и цифры, состав числа до десяти и таблицу умножения.
Мы уверены, что «живые» буквы обязательно очаруют вашего малыша, и он с легкостью и удовольствием выучит алфавит. Желаем радостного путешествия в страну знаний!
По материалам книги «Азбука. Живые буквы».
Обложка поста hockey-daddy.livejournal.comP.S.: Подписывайтесь на нашу полезную рассылку. Раз в две недели присылаем 10 самых лучших материалов из блога МИФ. Не без подарков
Алфавит… размышления на тему… Полное / Хабр
1. Алфавит. Ассоциативные связи.
По поводу алфавита сказано так много, что я для начала процитирую работу Карла Бюлера «Теория языка»
«Алфавит — это ассоциативная цепочка (механическая последовательность), и больше ничего; но каждый выучивал и знает его. Поэтому отображения последовательностей каких-либо объектов на алфавит — это удобное соотнесение. Мы постоянно им пользуемся на практике для упорядочивания. Было бы не трудно доказать, что в системе знаков, из которых состоит естественный язык, встречается множество ассоциативных цепочек и переплетений, которые с психологической точки зрения находятся на одной ступени с алфавитной цепочкой, и которые оказывают нам такую же службу во всеобъемлющей задаче упорядочения нашего знания о предметах и сообщения этого знания другим».
Стало быть, каждому элементу алфавита можно и нужно поставить в соответствие значение (что собственно и делается сейчас ) и закрыть этот вопрос. Однако не все так просто. Логично считать алфавитом множество ассоциаций A. Если i не равно j и аi и аj: A, то AI пересеченное AJ = пустому.
Отображение T множества знаков S (объекты класса Symbol) на алфавит в языке l:L (где L множество языков) обозначим Tl. Они же (знаки) являются своего рода источником ассоциаций (через отношение Tl). Множество ассоциаций, порожденное отображением знаков Tl, обозначим Al (собственно алфавит языка l). Множество Al конечное, его можно пронумеровать, что и будет кодом ассоциации или алфавита, но будет категорически не правильно называть это кодом знака. Ассоциацию, порожденную знаком s в языке l обозначим Tl(s). Понятно, что Tl(s): Al. Несколько знаков могут порождать одну и ту же ассоциацию. Например, знак большая буква «А» и маленькая «а» порождает одну и ту же ассоциацию. Стало быть могут существовать s1:S, и s2:S такие, что Tl(s1) пересеченное с Tl(s2) не пусто.
 Это один момент. И второй момент то, что это ассоциация зависит от среды или для каждого языка свое множество ассоциаций. Т.е. у английской, французской и русской среды, один и тот же знак может вызывать разные ассоциации. Обычно для реализации отображения Tl достаточно построить таблицу ассоциаций (она же и есть отношение Tl), но могут применяться и более сложные алгоритмы как, например, в нотной записи, картографии или в построении электрических схем.
Это один момент. И второй момент то, что это ассоциация зависит от среды или для каждого языка свое множество ассоциаций. Т.е. у английской, французской и русской среды, один и тот же знак может вызывать разные ассоциации. Обычно для реализации отображения Tl достаточно построить таблицу ассоциаций (она же и есть отношение Tl), но могут применяться и более сложные алгоритмы как, например, в нотной записи, картографии или в построении электрических схем..
2. Группирование знаков.
Однако не для всех категорий знаков есть необходимость строить свою таблицу ассоциаций. Есть знаки, которые вызывают общие для всех языков ассоциации. Справедливо, даже более сильное утверждение: Различные ассоциации в разных языках вызывают только объекты, которые мы обычно называем буквами. Что бы подчеркнуть это свойство объединим их в группу Letter. А так как разбиение на группы уже произошло, разобьем множество знаков еще на несколько групп.
Группа цифра (группа Digital) в которую включены знаки 0,1,2,3,4,5,6,7,8 и 9 вызывающие очевидные и одинаковые ассоциации во всех современных языках.
Группа управляющих знаков (группа Command) в которую включены все знаки управления и форматирования. В современных стандартах ассоциации этой группы используются, однако не предусмотрены знаки, отображающиеся непосредственно в управляющие ассоциации. По какой-то странной логике отображение T знаков этой группы отсутствует, а для графического представления используются знаки использующие пустую ассоциацию и только в обратном отображении пустая ассоциация знак, имитирующий соответствующую управляющую ассоциацию. Т.е. знак, который отображается непосредственно в ассоциацию «перевод строки» (код 10 в стандарте KOI8) отсутствует, а знак изображающий перевод строки отображается «ассоциацией знака» с кодом 182 в стандарте KOI8.

Группа знаков Letter имеет еще одну особенность, которая и есть основное назначение знаков этой группы, последовательность этих знаков формирует собственную ассоциацию, которую назовем лексемой. Отделяются лексемы друг от друга знаками остальных групп, одним из которых является пробел.
3. Ввод данных.
Все выше перечисленные группы объединяет одно спорное качество все их можно вводить с клавиатуры. Для того клавиатуру и изобретали, а так же и стандарты как кодировок знаков так и раскладок клавиатур. Подчеркнем здесь, что с клавиатуры вводятся именно знаки, а не ассоциации. И попытки подогнать в соответствие коды клавиатуры и коды ассоциаций наталкиваются на упорное сопротивление реального положения вещей.

Хорошей идеей считаю менять соответствие знаков и клавиш клавиатуры в зависимости от среды. Клавиатура Лебедева способная изменять изображение знаков на клавишах хорошо согласуется с нашими принципами.
4. Знаки как объекты.
4.1. Кодировка. Наборы знаков.
Это пошло со времен, когда мониторы и принтеры не отличались графическими возможностями, и каждая буква кодировалась «железно». Получилось так, что например, буква «а» английская и русская кодируется по-разному, хотя это же один знак. Таких примеров достаточно много. Я не вижу в этом много смысла. Притом что многих, действительно нужных знаков не хватает. Кроме того условное разделение на английские и русские буквы явно не выдерживает критики если мы будем кроме русского и английского использовать другие языки. Например, латинский или французский. Кто тогда мне скажет, какому языку принадлежит буква «p»?.. А веду я к тому, что это просто знак, и если считать этот знак объектом, то у него нет свойства «Язык».

4.2. Большие буквы. Сортировка.
Первые мониторы и принтеры были с ограниченными графическими возможностями, поэтому для больших букв предусматривалась отдельная кодировка, и на этом вопрос был закрыт. Значение этого кода служит параметром для операций сравнения, и остаются легко решаемые проблемы сортировок с учетом регистра и без. Если считать знак объектом возникает вопрос, как поступать с регистром? То ли это свойство, то ли это новый знак? Фактически вопрос стоит так: Считать ли большие буквы тем же знаком или это отдельный знак? Ответ: Это разные знаки обозначающее одно и то же. Само собой напрашивается объединить их в группу. Вопрос только что будем объединять? Вот здесь опять возникает вопрос, что такое знак? Только ли изображение? Или нас интересует смысловая нагрузка? Скорее смысловая нагрузка интересует. Тогда под это смысловое содержание надо и объединять варианты изображения. А если все-таки изображение? Тогда от изображения надо выходить на смысловую нагрузку.
 Здесь же заметим что ни управляющие знаки, ни знаки группы Mark, ни тем более пользовательские знаки этого свойства не имеют. Оно не имеет для них смысла. Время задуматься, а не наследуемый ли это класс от знаков?
Здесь же заметим что ни управляющие знаки, ни знаки группы Mark, ни тем более пользовательские знаки этого свойства не имеют. Оно не имеет для них смысла. Время задуматься, а не наследуемый ли это класс от знаков?4.3. Сортировка.
Необходимость сортировок знаков обычно сомнения не вызывает. А вот вызвало. Во-первых: Если считать знак объектом, то решение этого вопроса частный случай сортировки объектов, и по существу является вопросом определения операций сравнения на классе объектов. Допустим, мы этот вопрос решили, но нужен критерий для определения операций сравнения. При существующей на сегодняшний день ситуации код символа и служит таким критерием. Этот же код является параметром для формирования изображения, а это совершенно разные функциональные нагрузки.
Во-вторых, сами по себе знаки уже отсортированы. В той ситуации как это принято в данный момент, код символа и является порядковым номером положения его в таблице связанных с этим символом. В нашем случае объект Symbol определен в какой то группе, и тоже имеет свой индекс расположения, который вряд ли может быть аргументом для операций сравнения.
Таким образом, код символа несет в себе три различные функции: Является индексом массива, одним из параметров для графического изображения, и одним из параметров для операции сравнения. Если осуществлять динамическое и пользовательское формирование знаков, то это три разных свойства, а не одно. Стало быть, для операций сравнения к ассоциациям
Но кроме вопроса как выполнять операцию сравнения с учетом регистра или без, есть еще коварный вопрос. Если нет у буквы свойства «язык», то, как их сравнивать буквы из разных языков? И тут же напрашивается ответ. А ведь необходимость сортировок возникает при сортировке лексем. Сортировать отдельные буквы не имеет смысла. А в лексемах и свойство язык есть, и принадлежность лексемы какому-то классу!!! То есть мы пришли к тому, что сортировка применяется не к знакам, а к смыслу. То же самое можно сказать и о группе Digital. Мы сортируем не по знакам, а по значениям!
5. Обратное отображение .
Обратное отображение необходимо от ассоциации к знаку. Как мы заметили, одна ассоциация может быть порождена разными знаками. Но, дело в том, что как таковая ассоциация применяется только для внутренних нужд, и всегда порождена каким-то знаком. При современном подходе такая необходимость возникает при необходимости использовать управляющие ассоциации, так как они не имеют своего знака. Т.е. там, где надо сделать переход на новую строку или каким-то образом отформатировать информацию для вывода приходится сочинять что-то на тему chr(10) как в VB или /n как в C. Мы же смело можем поставить необходимый знак там, где он необходим. Как ожидается, он своим появлением вызовет изменение в тексте. Однако необходимо сделать только одно замечание, если управляющий знак является текстовой константой, то его управляющие функции не действуют. Т.е. взятый в текстовые кавычки управляющий знак теряет свои управляющие свойства.
Как мы заметили, одна ассоциация может быть порождена разными знаками. Но, дело в том, что как таковая ассоциация применяется только для внутренних нужд, и всегда порождена каким-то знаком. При современном подходе такая необходимость возникает при необходимости использовать управляющие ассоциации, так как они не имеют своего знака. Т.е. там, где надо сделать переход на новую строку или каким-то образом отформатировать информацию для вывода приходится сочинять что-то на тему chr(10) как в VB или /n как в C. Мы же смело можем поставить необходимый знак там, где он необходим. Как ожидается, он своим появлением вызовет изменение в тексте. Однако необходимо сделать только одно замечание, если управляющий знак является текстовой константой, то его управляющие функции не действуют. Т.е. взятый в текстовые кавычки управляющий знак теряет свои управляющие свойства.
6. Группа Mark.
6.1. Знак “=”.
История этой проблемы, в общем, то старая и мне не понятно, почему до сих пор не появились стандарты на разные знаки применительно к логическим отношениям и собственно присваиванием значения. В принципе, можно сконструировать транслятор, который будет отличать по контексту различное применение этого знака. Но это влечёт за собой, как накладные расходы по ресурсам во время трансляции, так и ограничения для некоторых синтаксических конструкций, для того, что б транслятор однозначно опознавал контекст. В разных языках этот вопрос решают по-разному. В языках класса C принято присваивание обозначать знаком равно “=”, а логическое отношение двойным знаком “==”. В языках класса Pascal присваивание обозначают двойным знаком “:=” а, логическое отношение одним знаком “=”. Язык VB пользуется одним знаком “=” для обоих применений приняв некие ограничения и умолчания. Одним, из которых является разделение двоеточием операторов в одной строке.
В принципе, можно сконструировать транслятор, который будет отличать по контексту различное применение этого знака. Но это влечёт за собой, как накладные расходы по ресурсам во время трансляции, так и ограничения для некоторых синтаксических конструкций, для того, что б транслятор однозначно опознавал контекст. В разных языках этот вопрос решают по-разному. В языках класса C принято присваивание обозначать знаком равно “=”, а логическое отношение двойным знаком “==”. В языках класса Pascal присваивание обозначают двойным знаком “:=” а, логическое отношение одним знаком “=”. Язык VB пользуется одним знаком “=” для обоих применений приняв некие ограничения и умолчания. Одним, из которых является разделение двоеточием операторов в одной строке.
Думаю, и мы бы придумали нечто из этого, если бы не третье назначение для того же знака. Вопрос возник в связи с единым форматом, заявленным в системе Lada и дальнейшим развитием объектной парадигмы. Знак “=” используемый для определения значения (или даже выражения) свойства объекта имеет совсем другой смысл в операции присвоении значения динамически создаваемому объекту (оператором Dim). Фактически разница в том, что когда мы создаем объект в редакторе (например, как сейчас делается графическими мастерами, но это же присвоение имеет текстовый вид) и присваиваем ему свойство, например, Top=2, то это значение 2 сохраняется в формате хранения созданного элемента, и при загрузке этого элемента в соответствующем месте памяти уже будет находиться именно это значение. Нет никакой необходимости использовать команду Move, для занесения этого значения, т.е. непосредственно выполнять команду присвоения Top=2, а, следовательно, и генерировать транслятором соответствующий код. С аналогичной ситуацией сталкиваемся в HTML. Там присвоение не превращается в команду присвоения, а является, каким-то значением. Если считать что там тегами создаются объекты, то никаких команд для присвоения свойств транслятором не генерируется. Соответствующие значения просто уже находятся в соответствующих местах в двоичном формате после трансляции.
Фактически разница в том, что когда мы создаем объект в редакторе (например, как сейчас делается графическими мастерами, но это же присвоение имеет текстовый вид) и присваиваем ему свойство, например, Top=2, то это значение 2 сохраняется в формате хранения созданного элемента, и при загрузке этого элемента в соответствующем месте памяти уже будет находиться именно это значение. Нет никакой необходимости использовать команду Move, для занесения этого значения, т.е. непосредственно выполнять команду присвоения Top=2, а, следовательно, и генерировать транслятором соответствующий код. С аналогичной ситуацией сталкиваемся в HTML. Там присвоение не превращается в команду присвоения, а является, каким-то значением. Если считать что там тегами создаются объекты, то никаких команд для присвоения свойств транслятором не генерируется. Соответствующие значения просто уже находятся в соответствующих местах в двоичном формате после трансляции.
В концепции .Net это некий аналог статического свойства.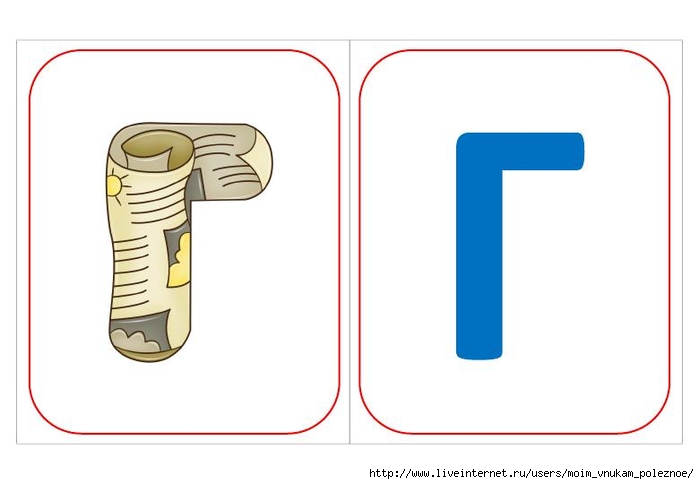 Т.е. свойства для доступа, к которым не обязательно создавать объект. Но в концепции .Net речь идет о программах, т.е. только об объектах, которые создают классы. И языки программирования, не создают (в том смысле как пишут программы) объекты. А в концепции Lada создание объекта такой же процесс, как и написание программы (программа тоже объект). Более того, объекты могут находиться внутри программы, как во время написания, отладки так и выполнения. Это очень полезно для сопровождения, как для процесса проектирования программы, так и эксплуатации. Поясним на примере.
Т.е. свойства для доступа, к которым не обязательно создавать объект. Но в концепции .Net речь идет о программах, т.е. только об объектах, которые создают классы. И языки программирования, не создают (в том смысле как пишут программы) объекты. А в концепции Lada создание объекта такой же процесс, как и написание программы (программа тоже объект). Более того, объекты могут находиться внутри программы, как во время написания, отладки так и выполнения. Это очень полезно для сопровождения, как для процесса проектирования программы, так и эксплуатации. Поясним на примере.
Пример 1. Создание в тексте программы объекта «Срок сдачи программы».
Tag «Срок сдачи программы»: Date
{
Value=Pointer «Поступление Т.З.»: Data. ¤Value+2Месяц
}
Допустим, где-то есть тег с датой поступления Т.З… В данном примере выполняется присвоение значения срока выполнения программы. Присвоение технологически произойдет на этапе трансляции (при создании объектов), и именно тогда выполнится операция сложения, и результат этого сложения сохранится в значении свойства Value объекта «Срок сдачи программы». Этот значение и будет служить информацией для управления проектом. Никакого запуска программы, и создания классов для доступа к объекту «Срок сдачи программы» нет необходимости. Достаточно что бы исходный текст хранился в сопровождаемом месте. Понятно, что для такого присвоения нет необходимости генерировать команды сложения и присвоения, формировать адреса для данных, выделять для них место при создании объекта, как это делается в программе. Новое значение даты формируется и присваивается во время трансляции, а не во время выполнения программы. Не говоря уже о том, что создаваемый объект может вообще не быть программой. А вот как нечто аналогичное происходит в программе.
Этот значение и будет служить информацией для управления проектом. Никакого запуска программы, и создания классов для доступа к объекту «Срок сдачи программы» нет необходимости. Достаточно что бы исходный текст хранился в сопровождаемом месте. Понятно, что для такого присвоения нет необходимости генерировать команды сложения и присвоения, формировать адреса для данных, выделять для них место при создании объекта, как это делается в программе. Новое значение даты формируется и присваивается во время трансляции, а не во время выполнения программы. Не говоря уже о том, что создаваемый объект может вообще не быть программой. А вот как нечто аналогичное происходит в программе.
Пример 2. Вычисление даты сдачи программы.
Dim DateTZ: Date
……
Dim Value: Date
Value= Date. ¤Value+2Месяц
Совсем иная картина в данном примере. Здесь обычная ситуация. Где-то определена переменная с датой поступления Т.З. (DateTZ). В результате трансляции создадутся объекты Dim и объекты присвоения и выражения с адресами операндов. При выполнении программы для данных выделится область памяти (операторами Dim), и когда наступит время выполнять данную последовательность команд, выполнится сложение, и потом присвоение.
При выполнении программы для данных выделится область памяти (операторами Dim), и когда наступит время выполнять данную последовательность команд, выполнится сложение, и потом присвоение.
Можно опять оставить задачу определения назначения на контекстный анализ транслятором, но тогда мы лишим себя возможности анализировать недопустимые присвоения в статических классах. А можно пойти дальше и отказаться от такой парадигмы как статические классы. Собственно их роль выполнение функций или методов, в какой-то области определения. Не вижу смысла отказываться от интуитивно более понятных категорий, ради того что бы породить новое понятие, да еще и попытаться объяснить его назначение.
Таким образом, мы просто вынуждены вводить новые знаки, что б опознать три различных назначения знака “=”. Хотелось бы иметь две стрелочки для различных видов присваивания и знак “=” оставить для логических отношений.
Хотелось бы добавить операцию определяемого равенства (или тождества) для ссылочных объектов после, которого в фигурных или круглых скобках список свойств, по которым сравниваются два ссылочных объекта. Например
Например
A B {Location, Size}
Даже если объекты разного класса они могут иметь одинаковые свойства.
Присваивание. Тогда присваивание правое можно определить как
Или можно пойти дальше с определяемыми отношениями вообще.
6.2. Знак обмена. “><“.
Нет такого знака. Мы его сконструировали из двух знаков “>” и “<“. А ведь полезный оператор. При необходимости поменять значения двух переменных необходимо определять третью переменную для сохранения промежуточного значения. Конечно, машинной команды такой нет. А ведь мы давно знаем, что формат процедуры (и программы) имеет в запасе место, которым пользуется именно по этому назначению (для сохранения промежуточных результатов) при вычислении выражений. Почему бы его не использовать для этой операции. Да. Отсутствие соответствующего знака это большая проблема!!! А двунаправленная стрелочка очень подошла бы. Или вот так.
6.3. Операции отношения. “=>”, “<=”, “!=”.
Просто слов нет. Моделист конструктор какой-то. А ведь пора бы придумать соответствующие знаки. Особенно меня восхищает подход в языке C, где восклицательным знаком обозначили отрицание. Читать тексты, перегруженные знаками не соответствующими смысловой нагрузке очень увлекательное занятие. Неужели такие бедные графические возможности? Ведь давно есть сложившиеся обозначения для обозначения меньше и равно знак меньше и внизу черточка. Для обозначения больше и равно знак больше и внизу черточка. Неравенство обозначать принято перечеркнутым знаком равно
Моделист конструктор какой-то. А ведь пора бы придумать соответствующие знаки. Особенно меня восхищает подход в языке C, где восклицательным знаком обозначили отрицание. Читать тексты, перегруженные знаками не соответствующими смысловой нагрузке очень увлекательное занятие. Неужели такие бедные графические возможности? Ведь давно есть сложившиеся обозначения для обозначения меньше и равно знак меньше и внизу черточка. Для обозначения больше и равно знак больше и внизу черточка. Неравенство обозначать принято перечеркнутым знаком равно
Здесь уместно применить так называемые композиционные знаки. Если знаки рассматривать как объекты, то при лексическом разборе (или даже до лексического разбора при редактировании) можно объединять составные знаки в один. Например знаки “:” и “=”, в “:=”. Или три точки “.” в “…”, Таким же путем получать смайлики или другие графические элементы так или иначе являющиеся знаками. Композиционные знаки добавлять в группу алфавит, и они могут наравне со стандартными участвовать в синтаксическом разборе.
6.4. Операция & и |. Кванторы.
Этим знаком принято обозначать логическую операцию в одних языках и конкатенацию текста в других. Как поступить если есть необходимость в обоих знаках? Или оставить и определиться с операцией по типу данных. Операция Или применяет знак |. Надо определиться. Знаки, которые давно используются в математической логике очень бы подошли. И ( или ( отрицание (¬), импликация () и два знака эквивалентности (,≡). Хотя, так как операции + и * определяются для каждого типа вполне можно обойтись ими для операций и или.
Традиционно в логике употребляется два вида кванторов: всеобщности () и существования (). Если F некоторая формула, содержащая единственную переменную x, то (x: F) — предложение утверждающее, что F выполняется для всех рассматриваемых объектов, а (x: F) — по крайней мере, для одного из них. Таким образом, появляется возможность описывать взаимосвязи между предикатами. Например, делать такие знаменитые утверждения, как (x: человек(x) смертен(x)) или (x: y: управдом(x) человек (у) друг(x, у) ).
6.5. Прогрессивные операции.
Сложились стандартные обозначения, для выполнения многих операций. Это суммирование и произведение по индексу, интеграл, дифференциал и многие другие. Выполнить эти операции, определив их какими-то (а они уже давно сложились) знаками не есть большая проблема, если язык позволяет функции высокого порядка. Наш язык таков.
Пример 3. Прогрессивное суммирование.
i=n∑mA[I]2 или
Пример 4. Прогрессивное произведение.
I=0n-1A[I2 или
Аналогично можно поступить и с интегралом, и не забыть про дифференциал и с прочими делами.
7. Группа Mark.
С тех же «железных» времен тянутся коды «перевода строки» и «возврат каретки». Это имело смысл, когда автоматизировали печатные машинки. Тогда это было актуально. Но сейчас, то зачем эти два управляющих кода? Вот табуляция пригодилась бы. Только не как управляющий код, а как лексема, содержащая количество пробелов (а может не только пробелов) и, конечно, с каким-то значением (количество) по умолчанию. Вообще-то табуляция должна иметь длину отступа в пикселях, или относительных единицах, а не количество пробелов. А то выравнивание текста становится невозможным. Для визуализации табуляции вполне подходит стрелочка, для перевода строки то, что и применяется в Word. Вообще управляющие знаки должны иметь визуальное представление, открывающееся в режиме просмотра управляющих кодов. Ведь не совсем логично иметь отдельно код перевода строки, и отдельно код знака визуализирующего перевод строки. Собственно это касается всех управляющих кодов, а не только тех, о которых я упомянул. Ведь какой смысл заложен в управляющие коды? Да редактирование и форматирование текста! И если сейчас мы имеет возможности редактировать не на уровне печатной машинки, то почему мы остановились в стандартизации управляющих кодов не только для перевода строки и перевода страницы но и нового раздела, примечания, комментариев и прочего. Почему не расширить возможности до уровня графического редактирования?
Вообще-то табуляция должна иметь длину отступа в пикселях, или относительных единицах, а не количество пробелов. А то выравнивание текста становится невозможным. Для визуализации табуляции вполне подходит стрелочка, для перевода строки то, что и применяется в Word. Вообще управляющие знаки должны иметь визуальное представление, открывающееся в режиме просмотра управляющих кодов. Ведь не совсем логично иметь отдельно код перевода строки, и отдельно код знака визуализирующего перевод строки. Собственно это касается всех управляющих кодов, а не только тех, о которых я упомянул. Ведь какой смысл заложен в управляющие коды? Да редактирование и форматирование текста! И если сейчас мы имеет возможности редактировать не на уровне печатной машинки, то почему мы остановились в стандартизации управляющих кодов не только для перевода строки и перевода страницы но и нового раздела, примечания, комментариев и прочего. Почему не расширить возможности до уровня графического редактирования?
О пробеле. Были времена, когда это был знак со своей позицией и стандартными размерами, под которые подгоняли все буквы. Но теперь вполне можно иметь не знак, а размер не занятого пространства. Пусть с минимальным значением для каждого шрифта и размера шрифта.
Были времена, когда это был знак со своей позицией и стандартными размерами, под которые подгоняли все буквы. Но теперь вполне можно иметь не знак, а размер не занятого пространства. Пусть с минимальным значением для каждого шрифта и размера шрифта.
Я бы подумал еще о пробеле, который не допускает переносов и форматирования. Если необходимо записать выражение с запретом форматирования. Например, формулу или пример, который должен выглядеть специальным образом там, где форматирование может нарушить задумку автора, изменив вид (а может и смысл) текста. Или пригодилось бы там, где мы используем знак “_” обозначая единый смысл несколькими словами. Например: Обращение_к_функции. По сути дела это обозначение единого понятия или объекта. Конечно, удобнее было бы применять вместо подчеркивания пробел, который вроде буквы не позволяет разорвать эту последовательность знаков при форматировании. Т.е. хотелось бы иметь пробел, который скорее буква, но выглядит как пробел (т.е. никак не выглядит).
Таким образом, предлагается 4 пробела. Один выполняющий функции табуляции. Второй служащий разделителем слов и позволяющий форматировать (изменять размеры пробела в сторону увеличения от некого минимального значения). Третий пробел, допускающий изменение размера только при редактировании, и не изменяемый при форматировании, и четвертый, который похож на третий, но не являющийся разделителем. Отличать функционально пробелы можно с помощью цвета фона.
Если мы применим такой подход к знакам, и управляющие коды будут иметь графическое представление, то нам не нужны будут хитрости с функциями, превращающими букву в код и наоборот (извиняюсь за рифму), для текстовых переменных, а использовали бы именно их графическое изображение в качестве управляющих знаков для форматирования текста. И не только в редакторе.
8. Желательные знаки.
Знаки из теории множеств:
Знак принадлежности.
Знак не принадлежности
Знак пусто .
Знак включения
Знак включения с замыканием
Знак включения справа
Знак включения с замыканием справа
Знак не включения
Знак бесконечность как максимальное значение
Объединение
Пересечение
Знак угол
Корень квадратный √
Тождественно
Приблизительно
Если то
То если
Тогда и только тогда
Знак принадлежности можно реализовать как логическое выражение вместо цикла с вложенной проверкой на наличие данного объекта в массиве или в коллекции.
Идя далеко вперед можно рекомендовать для булевских значений True и False отдельные знаки.
Например, True и False.
Было бы неплохо сделать отдельный знак для указателя.
Что это такое и как его использовать – Эффективность
Фонетический алфавит — это алфавит, в котором каждая буква представлена кодовым словом, начинающимся с этой буквы. Например, в фонетическом алфавите буква «Б» может быть представлена словом «Браво», а буква «П» может быть представлена словом «Папа».
Фонетический алфавит НАТО, в котором используется стандартизированный набор кодовых слов для обозначения букв английского алфавита, является наиболее распространенным типом фонетического алфавита в современном использовании. Фонетические алфавиты в целом и фонетический алфавит НАТО в частности являются полезными инструментами, поскольку они могут помочь вам более эффективно общаться в различных ситуациях. Кроме того, поскольку их концепция проста и интуитивно понятна, эти алфавиты можно выучить быстро и легко.
Таким образом, в следующей статье вы узнаете больше о фонетических алфавитах в целом и о фонетическом алфавите НАТО в частности. Затем вы увидите советы о том, как запомнить фонетический алфавит НАТО и понять, как использовать этот тип алфавита в повседневных ситуациях максимально эффективно.
Содержание
Как работает фонетический алфавит
Чтобы создать фонетический алфавит, вы просто заменяете букву, которую хотите сказать, словом, которое начинается с той же буквы 9.0022 , понятие, которое называется акрофонией . Например:
- «C» можно заменить на «Чарли».
- «G» можно заменить на «Golf».
- «О» можно заменить на «Оскар».
В некоторых фонетических алфавитах используются кодовые слова, связанные с определенной темой; например, в некоторых старых алфавитах в качестве кодовых слов использовались названия городов и стран (например, «Амстердам» и «Италия»). Другие фонетические алфавиты используют кодовые слова, которые основаны на других факторах, и в первую очередь на разборчивости, которая отражает, насколько легко понять кодовые слова в условиях, когда их трудно передать (например, «Способный» и «Бейкер»).
Примечание : «фонетический алфавит» — это разговорный термин, используемый для обозначения алфавитов правописания , которые также упоминаются с использованием других терминов, таких как алфавитов правописания слов , радиоалфавитов или телефонных алфавитов . Кроме того, обратите внимание, что такие алфавиты не связаны с системами фонетической записи и транскрипции, такими как Международный фонетический алфавит, который использует символы для создания визуального представления звуков, встречающихся в разговорных языках.
Зачем использовать фонетический алфавит
Проблемы с общением могут возникать по разным причинам, например, из-за плохого приема на телефоне, из-за того, что вы говорите в районе с большим фоновым шумом или из-за того, что вы разговариваете с кем-то, у кого сильный акцент, к которому вы не привыкли. Такие проблемы особенно неприятны и проблематичны, если вы пытаетесь сообщить точный термин, например имя, почтовый адрес или серийный номер.
Фонетические алфавиты могут облегчить общение в таких ситуациях и снизить вероятность недопонимания, помогая вам произносить точные термины так, чтобы слушатели могли понять их независимо от обстоятельств. Это может быть полезно, например, если вы разговариваете со службой технической поддержки или передаете важную информацию службам экстренной помощи. На самом деле, алфавит НАТО настолько эффективен, что раздаются призывы к его использованию среди медицинских работников, где точное общение может быть вопросом жизни и смерти.
Фонетический алфавит НАТО. официально учреждена в 1956 году совместными усилиями нескольких групп, в том числе, в первую очередь, Организации Североатлантического договора (НАТО) и Международной организации гражданской авиации (ИКАО). Он был создан с целью стать универсальным фонетическим алфавитом, чтобы преодолеть проблемы, возникшие в результате использования разными странами и организациями разных алфавитов.
В настоящее время изучение фонетического алфавита НАТО имеет два основных преимущества по сравнению с другими алфавитами:
- Алфавит НАТО является основным фонетическим алфавитом, используемым многими странами, организациями и отдельными лицами во всем мире, а это означает, что многие люди, и особенно те, кто сталкивается с ним в профессиональной среде, скорее всего, знакомы с ним.
 Соответственно, это фонетический алфавит, который люди, скорее всего, легко поймут, если вы будете использовать его для разговора с ними, и это также фонетический алфавит, который люди, скорее всего, будут использовать при разговоре с вами.
Соответственно, это фонетический алфавит, который люди, скорее всего, легко поймут, если вы будете использовать его для разговора с ними, и это также фонетический алфавит, который люди, скорее всего, будут использовать при разговоре с вами. - Конкретные кодовые слова в фонетическом алфавите НАТО были выбраны на основе всестороннего тестирования, поскольку они обеспечивают взаимную разборчивость между говорящими с разным языковым фоном благодаря простоте произношения и распознавания.
Соответственно, фонетический алфавит НАТО состоит из 26 кодовых слов, каждое из которых представляет собой отдельную букву английского алфавита. Эти слова:
A lfa, B ravo, C harlie, D elta, E cho, F oxtrot, G olf, H otel, I ndia, J uliett, K ilo, L ima, M ike, N Ovember, O Scare, P APA, Q UEBEC, R OMEO, S IERRA, T ANGO, U , vor it it vor vor vor vor vor vor vor vor vor vor vor .
X – луч, Y пятка, Z ул.
Например, используя фонетический алфавит НАТО, вы бы написали слово «позитивный» следующим образом:
Положительный: Папа, Оскар, Сьерра, Индия, Танго, Индия, Виктор, Эхо.
На изображении ниже вы можете увидеть полный фонетический алфавит НАТО, который показывает, какую букву обозначает каждое кодовое слово, а также официальное фонетическое произношение этого кодового слова.
Если вы хотите произнести число в алфавите НАТО, вы обычно произносите его как обычно, хотя в некоторых случаях в произношении есть несколько незначительных вариаций по сравнению с тем, как вы произносите название номера на обычном английском языке, как показано ниже:
В алфавите НАТО знаки препинания обозначаются по их названиям, за некоторыми исключениями: дефис (-) обозначается как тире , точка (. ) обозначается как стоп , а десятичная точка обозначается как точка или как десятичная .
) обозначается как стоп , а десятичная точка обозначается как точка или как десятичная .
Если вам нужна полная таблица фонетического алфавита НАТО, которая содержит как буквы, так и цифры, вы можете просмотреть ее по следующим ссылкам в виде изображения или в формате PDF.
Примечание : фонетический алфавит НАТО также упоминается с использованием других терминов, включая радиотелефонный алфавит ИКАО , фонетический алфавит ИКАО , международный радиотелефонный орфографический алфавит , военный фонетический алфавит военный алфавит , или просто фонетический алфавит .
Как выучить фонетический алфавит НАТО
Поскольку алфавит НАТО содержит лишь небольшое количество элементов и поскольку он довольно интуитивен по своей структуре, его будет относительно легко запомнить при некоторой практике.
Если вы решили выучить фонетический алфавит НАТО, вы можете сделать это, используя различные методы, например, записывая кодовые слова на самодельных карточках или используя программу для запоминания. Вы также можете просто запомнить кодовые слова по порядку, используя список кодовых слов в фонетическом алфавите НАТО. Потенциально вы можете повторять эти слова с ритмом или мелодией, которые облегчат вам запоминание кодовых слов, хотя это не имеет решающего значения.
Вы также можете просто запомнить кодовые слова по порядку, используя список кодовых слов в фонетическом алфавите НАТО. Потенциально вы можете повторять эти слова с ритмом или мелодией, которые облегчат вам запоминание кодовых слов, хотя это не имеет решающего значения.
Если вы изо всех сил пытаетесь запомнить определенные кодовые слова, вы можете попытаться связать их с тем, что они представляют. Например, если вы изо всех сил пытаетесь вспомнить, что кодовое слово для буквы «W» — «Виски», постарайтесь сосредоточиться не только на запоминании самого кодового слова, но и на запоминании соответствующего изображения, связанного с ним, например бутылки. виски.
Когда вы примерно сможете вспомнить все кодовые слова, начните практиковаться в использовании алфавита, записывая с его помощью различные слова. Эти слова могут быть какими угодно: от случайных предметов, которые вы видите, до адресов улиц, по которым вы проезжаете.
Наконец, обратите внимание, что если вы в конечном итоге забудете определенное ключевое слово при использовании фонетического алфавита НАТО в режиме реального времени, вы можете импровизировать и использовать альтернативное кодовое слово, которое начинается с той же буквы, что и кодовое слово, которое вы пытаетесь передать. Поскольку люди, использующие фонетический алфавит НАТО, обычно понимают лежащую в его основе концепцию, они, как правило, смогут понять, какую информацию вы пытаетесь передать, когда делаете это, и поэтому вы должны быть в состоянии надежно использовать фонетический алфавит НАТО. даже если вы не помните его со 100% точностью.
Поскольку люди, использующие фонетический алфавит НАТО, обычно понимают лежащую в его основе концепцию, они, как правило, смогут понять, какую информацию вы пытаетесь передать, когда делаете это, и поэтому вы должны быть в состоянии надежно использовать фонетический алфавит НАТО. даже если вы не помните его со 100% точностью.
Советы по использованию фонетического алфавита НАТО
При использовании алфавита НАТО необходимо помнить о нескольких вещах, чтобы использовать его максимально эффективно:
- Убедитесь, что человек, с которым вы разговариваете, знает, что вы пишете слова, используя фонетический алфавит НАТО, еще до того, как вы начнете это делать.
- Если человек, с которым вы разговариваете, , а не , знаком с понятием фонетического алфавита, вы можете использовать следующую модель речи при написании слов: «S как в Сьерре, N как в ноябре…”, которые большинство людей интуитивно поймут.
- В некоторых случаях вам может быть полезно произнести полный термин, на который вы ссылаетесь, прежде чем начать писать его с использованием фонетического алфавита.
 Это может помочь, например, в ситуациях, когда другой человек может понять, что вы пытаетесь написать, когда вы уже на полпути к термину.
Это может помочь, например, в ситуациях, когда другой человек может понять, что вы пытаетесь написать, когда вы уже на полпути к термину.
Советы по импровизации фонетического алфавита
Если вы импровизируете полный фонетический алфавит или некоторые определенные кодовые слова в случаях, когда вы не можете вспомнить, какие из них используются в фонетическом алфавите НАТО, вам могут помочь следующие советы. вы выбираете хорошие кодовые слова для использования:
- Выберите слово, знакомое большинству людей.
- Выберите слово средней длины, состоящее примерно из двух слогов (например, «Оскар», которое произносится как «ОС-КАР»).
- Избегайте слов, которые можно легко спутать с другими словами, особенно из-за похожего звучания начальной буквы (например, «Бан»/«Пан»).
- Избегайте слов, содержащих начальную букву, которую трудно выделить (например, буква «Т» в слове «Тропа», за которой сразу следует буква «Р»). Соответственно, если буква, которую вы пытаетесь произнести, является согласной, то следующая за ней буква должна быть гласной, как, например, в случае «Кило», где за «К» следует «И».
 ‘. И наоборот, если буква, которую вы пытаетесь произнести, гласная, то буква, следующая за ней, должна быть согласной; например, в «Alfa» за буквой «A» следует буква «L».
‘. И наоборот, если буква, которую вы пытаетесь произнести, гласная, то буква, следующая за ней, должна быть согласной; например, в «Alfa» за буквой «A» следует буква «L».
Эти советы в основном отражены в кодовых словах, которые используются в фонетическом алфавите НАТО. Есть некоторые исключения из этого; например, в кодовом слове “Браво” за начальной буквой “В” сразу следует буква “Р”. Однако даже такие исключения, как правило, по-прежнему соответствуют общим рекомендациям по выбору кодовых слов, и в этом случае, например, существует сильный фонетический контраст между двумя звуками («Б» и «Р»), что делает их относительно легкими. отличить.
Наконец, обратите внимание, что хотя эти советы и полезны, по большей части они не имеют решающего значения, и самое главное — просто выбрать слово, которое люди смогут четко идентифицировать. Кроме того, помните, что если у вас есть какие-либо сомнения относительно того, правильно ли вас поняли, вы можете попросить собеседника повторить то, что вы ему сказали, после того, как закончите говорить. Затем, если вы заметите какие-либо проблемы с недопониманием, вы можете соответствующим образом изменить кодовые слова, которые вы использовали, и повторить проблемные части вашего сообщения.
Затем, если вы заметите какие-либо проблемы с недопониманием, вы можете соответствующим образом изменить кодовые слова, которые вы использовали, и повторить проблемные части вашего сообщения.
Резюме и выводы
- Фонетический алфавит — это алфавит, в котором каждая буква представлена кодовым словом, начинающимся с этой буквы. Например, в фонетическом алфавите буква «Б» может быть представлена словом «Браво».
- Фонетические алфавиты используются для того, чтобы избежать проблем с недопониманием, позволяя вам произносить точные термины таким образом, который будет понятен в проблемных ситуациях, например, в ситуациях с большим фоновым шумом или в ситуациях, когда вы пытаетесь общаться с кем-то, чей акцент заметно отличается от вашего.
- Фонетический алфавит НАТО является широко используемым алфавитом, который был создан для создания стандартизированной системы связи по всему миру на основе кодовых слов, выбранных для обеспечения разборчивости.

- При использовании фонетического алфавита обычно предпочтительнее использовать кодовые слова из алфавита НАТО, хотя вы также можете импровизировать кодовые слова, основанные на тех же принципах, в ситуациях, когда вы не можете вспомнить, какое кодовое слово НАТО использовать.
- Прежде чем вы начнете использовать фонетический алфавит для общения с кем-либо, вы должны убедиться, что человек, с которым вы разговариваете, понимает, что вы собираетесь делать; если они не знакомы с концепцией фонетических алфавитов, вы можете использовать следующую формулировку, которая интуитивно понятна большинству людей: «М как в Майке, Е как в Эхо…».
Ассоциация букв
Главная > Обучение письму > Ассоциация букв
Автор: Джоан Уокер, бакалавр искусств (с отличием) — обновлено: 6 октября 2012 г. | *Обсудить
Tweet
Изучение того, как разные буквы произносятся в других языках, не всегда легко, поэтому изучение буквенных ассоциаций может быть хорошим способом для начинающих запомнить, как произносить разные слова.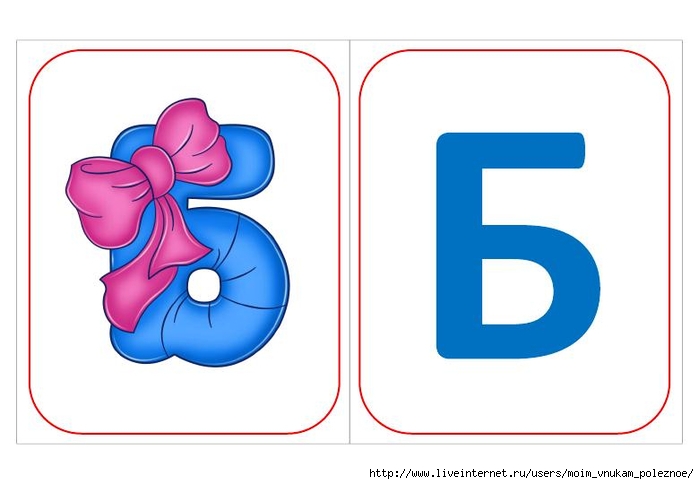 Довольно часто труднее всего запомнить произношение не тех букв, которые сильно отличаются от английских, а тех, которые похожи, но если их произнести неправильно, это будет иметь огромное значение. Буквенные ассоциации могут быть разными для разных людей — так же, как и при запоминании чего-либо, важно найти правильную ассоциацию для вашей памяти.
Довольно часто труднее всего запомнить произношение не тех букв, которые сильно отличаются от английских, а тех, которые похожи, но если их произнести неправильно, это будет иметь огромное значение. Буквенные ассоциации могут быть разными для разных людей — так же, как и при запоминании чего-либо, важно найти правильную ассоциацию для вашей памяти.
Различные алфавиты
Если вы изучаете язык с совершенно другим алфавитом, вам нужно использовать буквенные ассоциации, чтобы запомнить, как звучит каждая буква. Например, если вы изучаете греческий или русский язык, алфавит будет выглядеть не так, как вы привыкли. Но просто запишите буквы рядом с соответствующей буквой на английском языке и постарайтесь их запомнить. Тогда каждый раз, когда вы видите букву, вы будете ассоциироваться с соответствующей буквой на английском языке и запоминать, как ее произносить. Так, в греческом языке буква «альфа» связана с английской буквой «а» и произносится одинаково. Буква «тета» произносится как «й». Изучив эти ассоциации, когда вы начнете изучать греческий язык, вы вскоре узнаете, как произносится алфавит, без необходимости каждый раз искать каждую букву.
Буква «тета» произносится как «й». Изучив эти ассоциации, когда вы начнете изучать греческий язык, вы вскоре узнаете, как произносится алфавит, без необходимости каждый раз искать каждую букву.
Другие ассоциации букв
Как и во всем в изучении языков, всегда есть исключения из правил. Во многих языках есть буквы, в которых используется тот же алфавит, что и в английском, но они не соответствуют звуку буквы, что делает буквенную ассоциацию невозможной. В этих случаях вам просто нужно выучить буквы.
К счастью, их не так уж много для каждого языка и вообще у них очень запоминающееся произношение. В испанском языке двойная L, «ll» произносится так же, как «ll» в слове «миллион». Это считается отдельным звуком. Акценты также могут варьировать звучание буквы в таких языках, как испанский или турецкий. Но выучите эти звуки и свяжите их с сочетаниями букв в английском языке, и снова вы будете хорошо знать алфавит по ним, когда начнете говорить на разговорном языке.
Существует множество мнений о том, как лучше всего научиться произносить слова на иностранном языке. Одни люди считают, что буквосочетаниям следует учить, другие считают, что путь вперед — это буквенные ассоциации. Некоторые учат только целым словам и тому, как они произносятся, и не утруждают себя изучением алфавита — ведь именно так дети изначально учат родной язык. Но в большинстве школ учителя обучают буквенным ассоциациям, так что, когда ученик сталкивается со словом, которое он когда-либо видел или использовал, прежде чем он мог произнести его, используя буквы, и, надеюсь, произнести его правильно.
Людям, плохо знакомым с языком, лучше всего использовать комбинацию всех методов, и, конечно же, изучение алфавита и того, как он звучит с помощью буквенных ассоциаций, должно быть одним из них. Остерегайтесь ложных друзей — букв, которые выглядят как одни буквы, но звучат как другие — используя буквенные ассоциации, и убедитесь, что вы можете произнести последнюю, когда она входит в слово.