Английский алфавит в строку: fkn+antitotal | студентам & программистам
python – Шифр Цезаря, английский алфавит
Задать вопрос
Вопрос задан
Изменён 2 года 4 месяца назад
Просмотрен 4k раз
На вход программе подается строка текста на английском языке, в которой нужно зашифровать все слова. Каждое слово строки следует зашифровать с помощью шифра Цезаря (циклического сдвига на длину этого слова). Строчные буквы при этом остаются строчными, а прописные – прописными.
Формат входных данных На вход программе подается строка текста на английском языке.
Формат выходных данных Программа должна вывести зашифрованный текст в соответствии с условием задачи.
Примечание. Символы, не являющиеся английскими буквами, не изменяются.
def encrypt(text,s):
result = ""
for i in range(len(text)):
char = text[i]
if (char.isupper()):
result += chr((ord(char) + s-65) % 26 + 65)
else:
result += chr((ord(char) + s - 97) % 26 + 97)
return result
#check the above function
text = input().split()
s = 4
print (text)
print (str(s))
print(encrypt(text,s))
- python
- шифрование
0
Вы пытаетесь обрабатывать слово как символ. Также Вы учитываете спец. символы при подсчёте длины слова. И return в блоке else.
Пример:
def encrypt(text: str) -> str:
words = []
for word in text.split():
new_word = ''
word_len = len([c for c in word if c.isupper() or c.islower()])
for char in word:
if char. isupper():
new_word += chr((ord(char) + word_len - 65) % 26 + 65)
elif char.islower():
new_word += chr((ord(char) + word_len - 97) % 26 + 97)
else:
new_word += char
words.append(new_word)
return ' '.join(words)
text = 'Day, mice. "Year" is a mistake!'
print(encrypt(text))
isupper():
new_word += chr((ord(char) + word_len - 65) % 26 + 65)
elif char.islower():
new_word += chr((ord(char) + word_len - 97) % 26 + 97)
else:
new_word += char
words.append(new_word)
return ' '.join(words)
text = 'Day, mice. "Year" is a mistake!'
print(encrypt(text))
stdout:
Gdb, qmgi. "Ciev" ku b tpzahrl!
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
Курс Harvard CS50 – Лекция: Задание 2.
 Parlez-vous français?
Parlez-vous français?Harvard CS50
2 уровень , 10 лекция
Открыта
Условие
Написать программу vigenere.c, которая шифрует сообщение с помощью шифра Виженера.
На вход программы подаем один аргумент командной строки: ключевое слово k, состоящее из букв английского алфавита. Если приложение запускается более чем с одним аргументом или с аргументом не входящим в алфавит, нужно вывести информацию об ошибке с завершением программы. То есть main будет возвращать 1 — в таком случае наши автоматические тесты поймут, что здесь всё хорошо, и это условие учтено. Если всё хорошо, программа должна перейти к запросу строки текста p, который мы и шифруем полученным выше ключом k, напечатать результат и завершить выполнение программы, возвратив значение 0.
Уточнение
Нужно сделать так, чтобы в ключе k символы A и a обозначались как 0, B и b как 1, …, Z и z как 25. Программа должна применять шифр Виженера только к буквам текста p. Остальные символы (цифры, знаки препинания, пробелы) нужно вывести без изменений. Если алгоритм собирается применить j-й символ k к i-му символу p, не входящему в алфавит, применяем этот j-й символ ключа к следующему алфавитному символу в тексте; вы не можете просто оставить его и перейти к другому символу в k. Наконец, программа должна сохранить регистр каждой буквы в p.
Программа должна применять шифр Виженера только к буквам текста p. Остальные символы (цифры, знаки препинания, пробелы) нужно вывести без изменений. Если алгоритм собирается применить j-й символ k к i-му символу p, не входящему в алфавит, применяем этот j-й символ ключа к следующему алфавитному символу в тексте; вы не можете просто оставить его и перейти к другому символу в k. Наконец, программа должна сохранить регистр каждой буквы в p.
Не знаете, с чего начать?
Вот вам несколько советов от Замайлы, ассистента курса CS50
К счастью, реализация этой задачки очень похожа на реализацию шифра Цезаря. Только в качестве ключа используется не целое число, а строка. Если вы успешно реализовали шифр имени римского правителя, он может стать прекрасным стартом для второго задания. Вы, вероятно, уже смекнули, что шифр Виженера с одной буквой в качестве ключа — это тот же шифр Цезаря.
В алгоритме Виженера применяются те же шаги, что и в «Цезаре»:
- Получить ключ
- кодовое слово — это второй аргумент командной строки
argv[1] - должен входить в алфавит: функция
isalpha
Итак, второй аргумент командной строки argv[1] проверим на принадлежность к алфавитным символам. Делаем это с помощью уже знакомой isalpha. Если ключ корректен, получаем от пользователя строку и начинаем шифровать.
Делаем это с помощью уже знакомой isalpha. Если ключ корректен, получаем от пользователя строку и начинаем шифровать.
Формула шифра Виженера похожа на формулу шифра Цезаря. Каким образом вы преобразуете букву на соответствующее смещение шифра? Попробуйте сравнить значения по таблице ASCII.
Скорее всего, у вас получится отыскать закономерность между буквами и их алфавитными индексами, используя последовательности в таблице. Догадались, как отнять одну букву от другой, чтобы получить желаемый результат? Смещения для больших и малых букв неодинаковы, так что вам придется определить две похожие формулы для определения смещения для строчных и отдельно для прописных букв.
Также не забудьте, что цикл прохода по тексту должен игнорировать символы, не входящие в английский алфавит. И не забудьте сохранить регистр букв.
Если посмотреть на формулу шифра:
ci = (pi + kj) % 26
вы увидите две индексные переменные, i и j. Одна сохраняет позицию в исходном тексте, другая — в ключе.
Как это сделать? С помощью операции деления по модулю! Результат операции — остаток от деления двух чисел. Практическая польза этой операции в программировании просто огромна!
Представьте, что многочисленную группу людей нужно разделить на три подгруппы. Один из способов это сделать — попросить их рассчитаться на первый-второй-третий.
То есть, первый человек относится к первой группе, второй — ко второй, третий — к третьей, четвертый — снова к первой и так далее. Вы можете использовать деление по модулю чтобы произвести эту же операцию. Пронумеруем те же три группы с нуля. Вот как это делается:
Если вы возьмете индекс и поделите его по модулю максимального значения, полученный результат никогда не будет больше или равен этому значению.
Попробуйте применить этот принцип для возвращения ключевого слова в начало! Только вместо сортировки по группам вам нужен индекс ключевого слова, чтобы вы могли правильную букву для смещения, не выходя за длину ключа.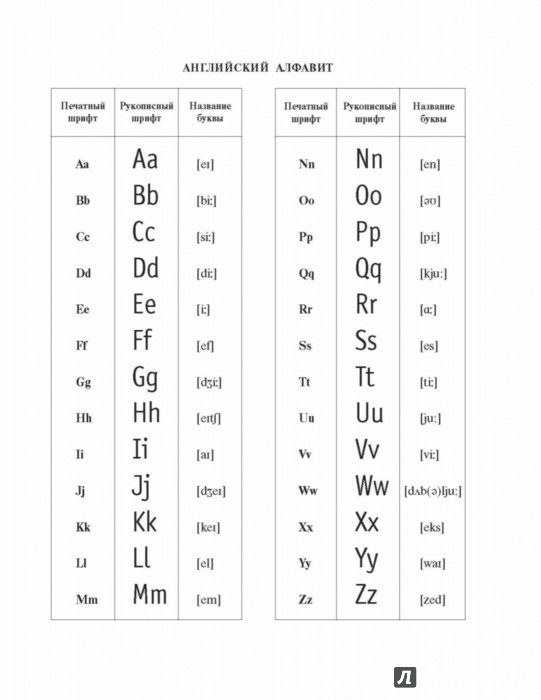
Так как мы автоматизируем некоторые тесты вашего кода, программа должна вести себя так, как показано ниже:
jharvard@appliance (~/Dropbox/pset2): ./vigenere bacon Meet me at the park at eleven am Negh zf av huf pcfx bt gzrwep oz
Как еще можно протестировать программу, кроме ручного вычисления зашифрованного текста? Мы добрые: для этого мы написали программу devigenere. Она принимает один и только один аргумент командной строки (ключевое слово), а её работа заключается в том, чтобы принять зашифрованный текст в качестве входных данных и вернуть обычный.
Запустите её:
~cs50/pset2/devigenere k
Где k — ключевое слово.
Если вы хотите проверить правильность вашей программы с помощью check50, выполните:
check50 2015.fall.pset2.vigenere vigenere.c
А если хотите оценить нашу реализацию vigenere, наберите:
~cs50/pset2/vigenereПредыдущая Предыдущая лекция Следующая Следующая лекция
regex – Обнаружение строк с неанглийскими символами в Python
У меня есть несколько строк, которые содержат английские буквы и не содержат английских букв. Например:
Например:
w='_1991_اف_جي2'
Как я могу распознать эти типы строк с помощью Regex или любого другого быстрого метода в Python?
Я предпочитаю не сравнивать буквы строки по очереди со списком букв, а делать это одним махом и быстро.
- питон
- регулярное выражение
- не английский
4
Вы можете просто проверить, может ли строка быть закодирована только символами ASCII (которые представляют собой латинский алфавит + некоторые другие символы). Если он не может быть закодирован, то он имеет символы из какого-то другого алфавита.
Обратите внимание на комментарий # --*- Кодировка: .... . Он должен быть в верхней части файла python (иначе вы получите ошибку о кодировке)
# --*- coding: utf-8 --*-
def isАнглийский(ые):
пытаться:
s.encode (кодирование = 'utf-8'). декодировать ('ascii')
кроме UnicodeDecodeError:
вернуть ложь
еще:
вернуть Истина
assert not isEnglish («slabiky, ale liší se podle významu»)
утверждать isEnglish('английский')
утверждать, что это не английский язык ( ' непрерывно
assert not isEnglish («как насчет этого: 通 asfspoke»)
утверждать isEnglish('?fd4))45s&')
4
ИМХО это самое простое решение:
def isEnglish(s): вернуть s.isascii() print(isEnglish("Тест")) print(isEnglish("_1991_اف_جي2")) Выход: Истинный ЛОЖЬ
1
Если вы работаете со строками (не юникодными объектами), то можно почистить переводом и проверить с помощью isalnum() , что лучше кидать Exceptions:
import string
def isАнглийский(ые):
вернуть s.translate(Нет, строка.пунктуация).isalnum()
print isEnglish («slabiky, ale liší se podle významu»)
print isEnglish('Английский')
Печать Isenglish ('ގެ ދެ އަކުރު ކަ')
print isEnglish('как насчет этого: 通 asfspoke')
print isEnglish('?fd4))45s&')
print isEnglish('Текст на русском')
> Ложь
> Правда
> Ложь
> Ложь
> Правда
> Ложь
Также вы можете отфильтровать не-ascii символы из строки с помощью этой функции:
ascii = set(string.printable)
защита remove_non_ascii(s):
возвратный фильтр (лямбда x: x в ascii, s)
remove_non_ascii('slabiky, ale liší se podle významu')
> слабики, але ли се подле взнаму
1
Я считаю, что у этого будет минимальное время выполнения, поскольку он останавливается, как только находит символ, который не является латинской буквой. Он также использует генератор для лучшего использования памяти.
Он также использует генератор для лучшего использования памяти.
строка импорта
def has_only_latin_letters (имя):
char_set = строка.ascii_letters
return all((Истина, если x в char_set, иначе False для x в имени))
>>> has_only_latin_letters('_1991_اف_جي2')
ЛОЖЬ
>>> has_only_latin_letters('bla bla')
Истинный
>>> has_only_latin_letters('бла бла')
ЛОЖЬ
>>> has_only_latin_letters('저주중앙초등학교')
ЛОЖЬ
>>> has_only_latin_letters('также строка с цифрами и знаками препинания 1, 2, 4')
Истинный
Вы также можете использовать другой набор символов: 9_`{|}~ \t\n\r\x0b\x0c’
Чтобы добавить буквы с латинским акцентом, вы можете обратиться к этому сообщению.
импорт
english_check = перекомпилировать (r'[a-z]')
если english_check.match(w):
печатать "english",w
еще:
напечатать "другое:",w
1
w.isidentifier()
Вы можете легко увидеть этот метод в документации:
Возвращает true, если строка является допустимым идентификатором в соответствии с определением языка, раздел Идентификаторы и ключевые слова.
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Алфавитная строка с примерами кода
Алфавитная строка с примерами кода
В этой статье на ряде примеров показано, как решить проблему с алфавитной строкой, возникающую в коде.
abcdefghijklmnopqrstuvwxyz ABCDEFGHIJKLMNOPQRSTUVWXYZ
Другое решение, описанное ниже с примерами кода, может быть использовано для решения той же проблемы со строкой алфавита.
#Python: готовая строка алфавита строка импорта string.ascii_lowercase #output: 'abcdefghijklmnopqrstuvwxyz' string.ascii_uppercase #output: 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', ' к', 'л', 'м', 'н', 'о', 'р', 'к', 'р', 'с', 'т', 'у', 'в', 'ш' , 'х', 'у', 'з'] ["а", "б", "в", "г", "д", "ж", "ж", "з", "и", "к", "к", "л", " м", "н", "о", "р", "ц", "р", "с", "т", "у", "в", "ш", "х", "у" , "з"]
alphas_l='abcdefghijklmnopqrstuvwxyz' Alphabets_u='ABCDEFGHIJKLMNOPQRSTUVWXYZ'
Использование большого количества различных примеров позволило успешно решить проблему с алфавитной строкой.
Какие 26 английских букв?
Английский алфавит состоит из 26 букв: A, B, C, D, E, F, G, H, I, J, K, L, M, N, O, P, Q, R, S, T, U, V, W, X, Y, Z.
Какие 4 типа алфавитов существуют в английском языке?
Примечания. Пять букв английского алфавита — гласные: A, E, I, O, U. Остальные 21 буква — согласные: B, C, D, F, G, H, J, K, L, M, N, P, Q, R, S, T, V, X, Z и обычно W и Y. Письменный английский включает диграфы: ch c ck gh ng ph qu rh sc sh th ti wh wr zh. 9a-zA-Z]’ для сопоставления с неалфавитными символами в строке и замены их пустой строкой с помощью оператора re. функция sub(). Результирующая строка будет содержать только буквы.
Какая 27-я буква алфавита?
Амперсанд, также известный как знак “и”, представляет собой логограмму &, представляющую союз “и”. Оно возникло как лигатура букв et — латинское «и».
Сколько лет букве J?
Только в 1524 году Джан Джорджио Триссино, итальянский грамматист эпохи Возрождения, известный как отец буквы J, провел четкое различие между двумя звуками.08-Apr-2011
Как называется английский алфавит?
Латинский алфавит
Кто изобрел алфавиты от А до Я?
Первоначальный алфавит был разработан семитским народом, живущим в Египте или его окрестностях.