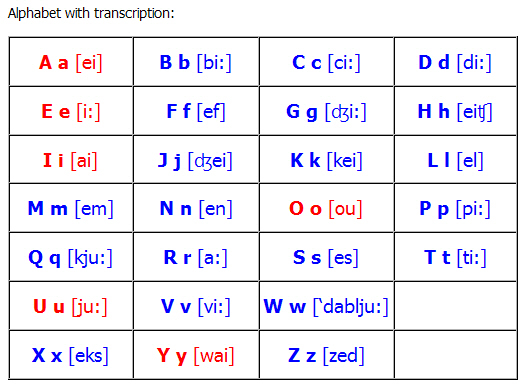
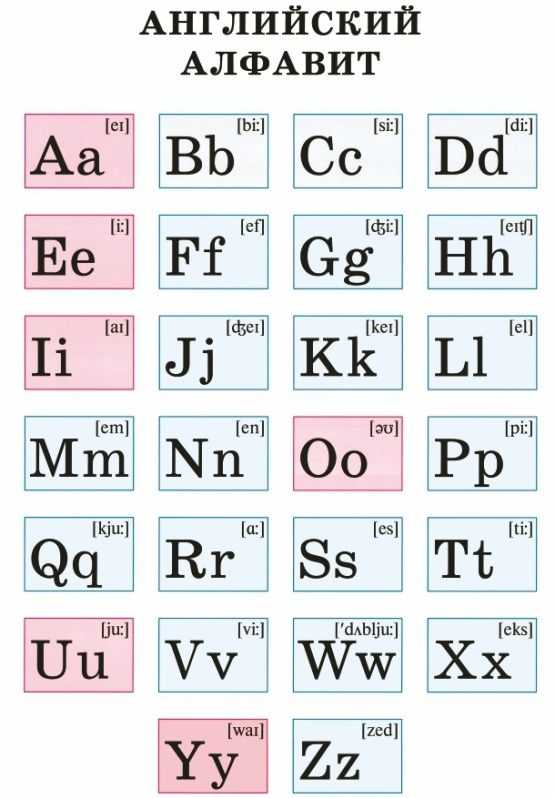
Английский алфавит разрезной с транскрипцией распечатать: Карточки с английскими буквами
Как расшифровывать документы с помощью Transkribus — Введение
О Transkribus
Transkribus — это комплексное решение для оцифровки, распознавания текста с помощью искусственного интеллекта, расшифровки и поиска исторических документов. Узнайте больше о Транскрибусе здесь.
О Transkribus
Transkribus — это комплексное решение для оцифровки, распознавания текста с помощью искусственного интеллекта, расшифровки и поиска исторических документов. Узнайте больше о Транскрибусе здесь.
Содержание
Содержание
В этом руководстве объясняется, как транскрибировать документы с помощью Transkribus для создания обучающих данных для автоматического распознавания конкретных документов или создания транскрипции для научного издания.
Если вы хотите получить более общий обзор, ознакомьтесь с нашим 10-шаговым руководством.
Transkribus — это платформа для автоматизированного распознавания, расшифровки и поиска исторических документов с использованием технологии распознавания рукописного текста (HTR).
Стенограммы, созданные с помощью Transkribus, могут использоваться:
- Используется для обучения модели распознавания рукописного текста (HTR), которая способна автоматически распознавать печатные или рукописные документы;
- В качестве основы для цифровых научных изданий.
Если у вас уже есть расшифрованные документы и вы хотите использовать их в качестве обучающих данных для HTR, обратитесь к нашему руководству «Как использовать существующие расшифровки».
Введение
Существует простой трехэтапный процесс расшифровки документа в Transkribus:
- Загрузка: загрузите свои документы на платформу Transkribus;
- Сегментация: запустите инструмент автоматической сегментации, чтобы создать базовые параметры для вашего документа.;
- Транскрипция: расшифруйте текст в сегментированных строках.
Этой формы простой транскрипции достаточно для обучения технологии распознавания рукописного текста (HTR). Обратите внимание, что HTR может работать как с рукописными, так и с печатными документами. Эффективность модели будет зависеть от качества учебного материала (вашей ручной транскрипции), качества изображений и от того, насколько аккуратно или неряшливо написан текст.
Обратите внимание, что HTR может работать как с рукописными, так и с печатными документами. Эффективность модели будет зависеть от качества учебного материала (вашей ручной транскрипции), качества изображений и от того, насколько аккуратно или неряшливо написан текст.
Для тех, кто работает над научными изданиями, предусмотрены расширенные возможности транскрипции. Вы можете настроить порядок чтения текста, использовать исторические символы, добавлять теги и метаданные, расширять сокращения и многое другое.
1. Загрузите документы в Transkribus
Чтобы иметь возможность запускать необходимые инструменты для ваших документов, они должны находиться на сервере Transkribus. Это означает, что вам нужно загрузить их в Транскрибус.
Все коллекции и документы в Транскрибусе являются частными . Только авторизованные вами пользователи могут просматривать ваши документы. Они не выносятся на всеобщее обозрение.
Для загрузки нажмите кнопку «Импорт документов» в Главном меню.
Рисунок 1. Загрузка файлов в личную коллекцию Рисунок 2. Выберите «Загрузить один документ» для документов размером до 500 МБУ вас есть пять вариантов загрузки документов:
- локальная папка:
Этот параметр позволяет загружать документы размером до 500 МБ. Чтобы выбрать эту опцию, выберите «Загрузить один документ». Пожалуйста, сделайте так, чтобы загружаемые файлы находились в дополнительной папке. При выборе файлов для загрузки вы не сможете увидеть файлы в папке. Это нормально в данном случае. Просто отметьте папку и подтвердите с помощью «ОК». - Загрузка через FTP:
Это подходит, если вы хотите загрузить несколько больших документов. С помощью этой опции вы можете загружать файлы изображений, а также PDF-документы. Пожалуйста, убедитесь, что PDF-файлы не находятся внутри папки при использовании FTP-загрузки. - Загрузка по URL-адресу средства просмотра DFG METS:
Это позволяет загружать документы непосредственно из репозиториев, поддерживающих средство просмотра DFG (Deutsche Forschungsgemeinschaft — Немецкие научные фонды).
- Загрузка через URL-адрес манифеста IIIF:
Вставьте URL-адрес манифеста IIIF в соответствующее поле и нажмите «Загрузить». - Извлечение и загрузка изображений из PDF:
Этот вариант подходит для изображений, которые вы хотите загрузить и которые находятся в PDF-документе. Если эти PDF-документы имеют большой размер, используйте FTP-загрузку. Кроме того, если у вас есть изображения JP2000 в ваших PDF-файлах, имеет смысл использовать FTP-опцию.
Чтобы добавить страницы в уже существующий документ в Transribus: загрузите документ, в который вы хотите добавить страницы в Transkribus. Откройте Диспетчер документов и снова выберите документ, щелкнув его имя в окне «Диспетчер документов». Нажмите на значок зеленого круга рядом с «Добавить новую страницу (ы)» и найдите и добавьте новые страницы через каталог.
Чтобы удалить документы из вашей коллекции: выберите документ в обзоре коллекции на вкладке «Сервер». Нажмите на значок папки с маленьким красным кружком «Удалить выбранные документы из Транскрибуса». Удаленные документы будут находиться в корзине (значок «содержит удаленные документы») в течение двух недель. Если вы удалили документ по ошибке, вы можете связаться с нами ([email protected]), и мы сможем повторно активировать документ в течение этих двух недель. После этого документ будет безвозвратно удален.
Нажмите на значок папки с маленьким красным кружком «Удалить выбранные документы из Транскрибуса». Удаленные документы будут находиться в корзине (значок «содержит удаленные документы») в течение двух недель. Если вы удалили документ по ошибке, вы можете связаться с нами ([email protected]), и мы сможем повторно активировать документ в течение этих двух недель. После этого документ будет безвозвратно удален.
2. Сегментация – анализ макета
После того, как вы загрузили свои документы в Transkribus, вы готовы начать сегментацию. Чтобы транскрибировать ваши документы в Transkribus, они должны быть сегментированы на текстовые области и базовые линии, а для работы HTR необходимо соединить текст и изображение .
Все сегментированные элементы, такие как область печати, область текста, область строки или базовая линия, сохраняются в файле PAGE вместе с их координатами.
Просмотр профилей
Профили просмотра доступны, чтобы помочь вам с задачами сегментации и транскрипции. Вы можете выбрать профили просмотра для « Сегментация » и « Транскрипция », нажав кнопку «Профили» в Главном меню.
Вы можете выбрать профили просмотра для « Сегментация » и « Транскрипция », нажав кнопку «Профили» в Главном меню.
Профиль «Сегментация» означает, что базовые линии отображаются красным цветом, что облегчает обнаружение любых ошибок, возникающих в результате автоматического процесса сегментации.
Профиль «Транскрипция» означает, что будет отображаться поле «Текстовый редактор», позволяющее расшифровать ваш документ. Конечно, вы можете просто использовать профиль «по умолчанию» для выполнения любой задачи.
Рисунок 3. Просмотр профилей для задач сегментации и транскрипцииАвтоматическое определение текстовых областей, линий и базовых линий
Для автоматического запуска анализа макета перейдите на вкладку «Инструменты» на панели «Управление и инструменты» (в левой части экран). Интересующий нас раздел называется «Анализ макета».
Рисунок 4. Раздел «Анализ макета» на вкладке «Инструменты» В разделе «Метод» вы можете выбрать метод определения базовой линии. «Транскрибус ЛА» выбран по умолчанию и хорошо работает с большинством раскладок. Вы можете применить его с настройкой по умолчанию или нажать «Настроить» и изменить параметры конфигурации.
«Транскрибус ЛА» выбран по умолчанию и хорошо работает с большинством раскладок. Вы можете применить его с настройкой по умолчанию или нажать «Настроить» и изменить параметры конфигурации.
В окне Конфигурация анализа макета вы можете настроить следующие параметры:
- Модель: оставьте «Предустановленную» модель, если вы не обучили конкретную базовую модель макету ваших документов.
Модель Preset Transkribus LA хорошо работает для большинства типологий документов. Только если ваши документы имеют сложную компоновку и предустановленная модель неудовлетворительна, вы можете обучить базовую модель, специфичную для типологии вашего документа, как описано здесь.
- Минимальная длина базовой линии: указывает минимальную длину базовой линии в пикселях. Базовые линии короче этой длины не будут обнаружены.
- Порог точности базовой линии: на первом этапе анализа макета каждый пиксель помечается как базовая линия, разделитель или другое.
 Порог базовой точности применяется к маркировке базовой линии на этом этапе. Он находится в диапазоне от 0 до 255, а более высокие значения обеспечивают более высокую точность обнаруженных базовых линий.
Порог базовой точности применяется к маркировке базовой линии на этом этапе. Он находится в диапазоне от 0 до 255, а более высокие значения обеспечивают более высокую точность обнаруженных базовых линий.
Если у вас есть изображения с низким разрешением и не обнаружено ни одного базового уровня или обнаружено только несколько базовых линий, попробуйте уменьшить значение. Имейте в виду, однако, что результаты могут быть зашумлены при более низких порогах.
- Порог разделителя: разделители представляют собой небольшие вертикальные линии, проведенные рядом с каждой базовой линией; они отмечают начало и конец каждой базовой линии (не путайте их с фактическими разделителями на изображениях печатных документов). Что касается порога базовой точности, порог разделителя относится к первому этапу, когда пиксели размечены.
Пороговое значение разделителя находится в диапазоне от 0 до 255: 0 означает, что разделители вообще не используются; с более высоким значением используются разделители, поэтому близлежащие базовые линии, как правило, не сливаются.
Обычно низких значений достаточно, чтобы предотвратить соединение между соседними базовыми линиями. Используйте, например, 1, чтобы использовать информацию-разделитель «иногда», и большие значения, чтобы использовать их практически постоянно, например, когда текстовые строки расположены близко друг к другу, но должны быть разделены, потому что принадлежат разным столбцам.
- Max-dist для объединения: на втором этапе алгоритм пытается объединить ближайшие базовые линии, но только тогда, когда расстояние до них меньше заданного значения. Значение измеряется не в пикселях, а в долях ширины изображения. По умолчанию установлено значение 0,01: когда две базовые линии ближе, чем доля ширины изображения, равная 0,01, они будут объединены; если они дальше этого значения, они не будут объединены. В зависимости от вашего макета и ширины изображения вы можете увеличить значение дроби, чтобы объединить более удаленные линии, или уменьшить его, чтобы предотвратить объединение ближайших базовых линий.

- Максимальное расстояние для кластеризации: это значение относится к созданию текстовой области: после обнаружения базовых линий они группируются в текстовые области в зависимости от их расстояния. Максимальное расстояние для кластеризации — это часть ширины изображения: базовые линии, которые ближе этой доли, группируются вместе в текстовой области.
Если с настройками по умолчанию создается слишком много текстовых областей, можно попытаться увеличить значение, чтобы сгруппировать вместе больше базовых линий. Если установлено значение -1, кластеризация областей выполняться не будет, и будет создана только одна текстовая область в качестве ограничивающей рамки всех строк.
Для получения дополнительной информации об алгоритме и настройках Transkribus LA посетите эту страницу.
Чтобы запустить автоматический анализ макета, выберите, хотите ли вы обрабатывать только текущую страницу, отдельные страницы или весь документ. Убедитесь, что выбран «Найти текстовые области», и нажмите кнопку «Выполнить».
Убедитесь, что выбран «Найти текстовые области», и нажмите кнопку «Выполнить».
Если вы хотите нарисовать текстовые области вручную, а затем найти базовые линии в этих областях, снимите флажок «Найти текстовые области» перед началом анализа макета.
Исправление результатов автоматической сегментации
Может случиться так, что для автоматического анализа макета потребуется ручная коррекция, поскольку некоторые базовые линии отсутствуют или вы хотите объединить/переместить области текста.
Если вы обучаете модель HTR, текстовые области не нужно исправлять, а порядок чтения текста не имеет значения. Важно то, что символы строки опираются на базовую линию, а выносные элементы простираются ниже, и что существует соответствие между линией на изображении и транскрибируемой линией.
Все инструменты для корректировки анализа макета можно найти в меню «Холст» слева от изображения. Вы можете проверить их функциональность, наведя курсор на значок.
Строка пропущена или добавлена по ошибке
Рисунок 5. Добавление строки в существующую текстовую область
Добавление строки в существующую текстовую область В приведенном выше примере программа пропустила первую строку. Если вы хотите добавить его в существующую текстовую область, щелкните внутри области, чтобы она была выделена, и перетащите границу текстовой области по мере необходимости. Чтобы нарисовать базовую линию, нажмите кнопку «+BL» в меню «Холст»: нажмите один раз, чтобы начать рисовать базовую линию, и дважды щелкните, чтобы закончить линию.
Заметку на полях нужно разделить на отдельную текстовую область
Рисунок 6. Разделить текстовую областьЕсли вам нужно разделить одну область на две, вы можете сделать это с помощью кнопок в меню Canvas. «H-кнопка» разделяет текстовую область по горизонтали; кнопка «V» разделяет текстовую область по вертикали; «L-кнопка» позволяет разделить текстовую область настраиваемой линией. Не забывайте всегда сначала выделять текстовую область, которую хотите разделить.
Удалить ненужный регион
Рисунок 7. Удаление области
Удаление области В приведенном выше примере две области перекрываются, поэтому одну можно удалить. Нажмите на текстовую область, которую вы хотите удалить, и нажмите красную кнопку «Удалить фигуру».
Объединить две области
Иногда программа создает две текстовые области там, где нужна только одна. В этом случае вы можете легко объединить их вместе. Удерживая нажатой кнопку «CTRL» на клавиатуре, щелкните обе текстовые области. Нажмите кнопку «Объединить выбранные фигуры» в меню «Холст».
Рисунок 8. Объединение двух текстовых областейИсправление базовых линий
Конечно, в документе также можно исправить базовые линии. Как и в случае с текстовыми областями, нажмите на базовую линию, и вы сможете перетаскивать части линии, разделять линию на две части или объединять две строки вместе.
Вы также можете удалить базовую линию и нарисовать новую с нуля. Нажмите кнопку «+BL» в меню «Холст». Щелкните один раз, чтобы начать рисовать базовую линию, и дважды щелкните, чтобы закончить линию.
3. Расшифровка
Простая расшифровка — для обучения HTR
Чтобы расшифровать документ, выберите профиль просмотра «Транскрипция» в Главном меню. Вы увидите поле текстового редактора под изображением.
Для каждой линии/базовой линии на изображении вы найдете соответствующую строку в текстовом редакторе . Изображение и текст связаны таким образом.
Рисунок 9. Расшифровка документаНад документом может работать несколько человек, но они не должны одновременно работать над одной и той же страницей. Вы можете разрешить другим пользователям Transkribus просматривать ваши документы, нажав кнопку «Диспетчер пользователей» на вкладке «Сервер».
Если вы хотите обучить модель HTR распознаванию ваших документов, этой простой транскрипции достаточно. Мы рекомендуем вам начать учебный процесс с объемом расшифрованного материала от 5 000 до 15 000 слов (около 25–75 страниц). Если вы работаете с печатным, а не рукописным текстом, обычно требуется меньший объем обучающих данных. Прочтите здесь, как обучить модель HTR.
Прочтите здесь, как обучить модель HTR.
Усовершенствованная транскрипция – для научного издания
После того, как документ был сегментирован на текстовые области, строки и базовые линии, вам, возможно, придется подумать о порядке чтения текста (это не имеет значения, если транскрипция должна служить только в качестве учебного материала). Многие рукописные документы содержат исправлений и дополнений , внесенных автором или кем-то другим. В научном издании вы хотите сохранить порядок чтения и, возможно, также указать на то, что этот текст был дополнением. Для этого все элементы сегментации можно заказать в соответствии с пользовательский заказ .
Порядок чтения по умолчанию соответствует топологии текстовых или строковых областей . Все фигуры упорядочены в соответствии с координатами верхнего левого угла области текста или строки.
Рисунок 10. Порядок чтения текстовых областей – порядок номеров может быть изменен Этот механический порядок чтения можно изменить: нажмите кнопку «Видимость элементов» в Главном меню, после чего вы можете выбрать отображение порядка чтения текста области, линии, базовые линии (или слова).
Рисунок 11 Кнопка «Видимость элементов» отображает логический порядок элементов сегментации
После того, как вы выберете отображение порядка чтения текстовых областей или строк, на изображении вашего документа будут отображаться числа. Нажав на одну из цифр, обозначающих порядок чтения, можно ввести новое число и соответствующим образом изменить порядок чтения. То же самое можно сделать, переместив элементы сегментации во вкладке «Макет».
Рисунок 12. Отредактируйте порядок чтения, щелкнув цифру и введя новое числоВ случаях, когда порядок чтения страницы совершенно неверен, можно изменить порядок текста:
- Сделать видимым порядок чтения строк, как описано выше
- Нажмите на вкладку «Макет» в левой части экран
- Выберите страницу или область текста, порядок которых вы хотите изменить
- Нажмите кнопку «R»
- Порядок чтения будет изменен в соответствии с координатами верхнего левого угла области текста или строки.
 После этого строки должны быть в правильном порядке.
После этого строки должны быть в правильном порядке. - Возможны проблемы с порядком чтения газетных колонок и подобных документов. Например. программа назначает порядок чтения на основе горизонтального расположения строк на странице, а не упорядочивает строки по столбцам. Чтобы решить эту проблему, используйте кнопку «V» в меню «Холст», чтобы разделить текстовую область на странице на отдельные области для каждого столбца. Как только для каждого столбца будет создана отдельная текстовая область, порядок чтения должен автоматически обновляться и быть правильным.
Интерстральные добавления — частый способ добавления текста в документ. Чтобы сгенерировать правильный порядок чтения, необходимо выполнить следующие шаги вручную:
- Нажмите кнопку «Видимость элемента» в Главном меню и выберите «Показать порядок чтения строк» (как описано выше)
- Выберите базовая линия ниже дополнения (если дополнение выше линии).

- Разделите область строки с помощью кнопки «V» в меню «Холст» именно там, где добавление должно быть логично расположено
Добавления, которые появляются в виде дополнительных примечаний (например, на полях страницы), должны обрабатываться так же, как и подстрочные добавления. Существует три варианта работы с примечаниями на полях:
- Вариант 1 : Текстовая область может быть расширена так, чтобы все базовые линии добавления также были частью соответствующей текстовой области. Вы можете использовать как довольно большие прямоугольные текстовые области, так и полигональные текстовые области.
 Для этого выберите кнопку «Добавить точку к выбранной фигуре» в меню «Холст». Следуя за движением указателя мыши, вы можете добавлять точки в исходную текстовую область и расширять фигуру, чтобы она также включала добавление.
Для этого выберите кнопку «Добавить точку к выбранной фигуре» в меню «Холст». Следуя за движением указателя мыши, вы можете добавлять точки в исходную текстовую область и расширять фигуру, чтобы она также включала добавление.
После этого дополнительные строки/базовые линии можно перенумеровать в соответствии с их правильным порядком чтения. - Вариант 2: вы можете создать только одну большую текстовую область для всей страницы и выполнить линейную/базовую сегментацию вручную в правильном порядке. Таким образом, вы получите правильный порядок чтения с самого начала. Это может быть лучшим вариантом, если вы имеете дело с документом, который имеет сложную структуру с множеством добавлений, примечаний и удалений.
- Опция 3 : Вы можете соединить дополнительную текстовую область, содержащую дополнение, со строкой, которой принадлежит дополнение. Для этого выберите обе текстовые области, а затем нажмите кнопку «Связывает две фигуры» на вкладке «Структурные» на вкладке «Метаданные».
 Обратите внимание, что ссылка будет частью файла XML (PAGE), но в настоящее время не поддерживается в других форматах экспорта.
Обратите внимание, что ссылка будет частью файла XML (PAGE), но в настоящее время не поддерживается в других форматах экспорта.
Если такие дополнительные примечания (или поля) не являются частью порядка чтения, а являются «комментариями» и, как таковые, находятся на другом уровне по сравнению с основным порядком чтения, достаточно пометить их как «marginalia» на вкладке «Метаданные». Инструкции по разметке текста можно найти в руководстве по разметке расшифрованных документов.
Транскрипция, которая будет служить основой для научного издания, должна давать пользователю больше информации и предлагать больше контекстных данных , чем простая транскрипция. В этом случае важную роль будет играть не только машиночитаемость (т.е. обучающие данные для движка HTR), но и читабельность человека текста.
Вы можете добавлять специальные символы и символы Unicode с помощью кнопки « Виртуальные клавиатуры » в поле «Текстовый редактор».
С помощью кнопки «Редактировать…» можно добавить ярлыки для часто используемых символов и добавить новые символы Unicode. Чтобы создать ярлык, вам просто нужно ввести его в графу «Ярлык». Чтобы добавить новые символы Unicode, вы используете зеленую кнопку с плюсом.
Рисунок 21. Добавление символов Юникода и ярлыковВ текстовом редакторе вы можете использовать «Backspace» для перемещения текста на одну строку вверх и «Ctrl» + «Return» для перемещения текста на одну строку вниз.
Диакритические знаки и лигатуры
Для правильной транскрипции диакритических знаков и лигатур требуются определенные экспертные знания. Есть два основных варианта корректной транскрипции этих символов:
- Небольшая нормализация по словарю:
Основное правило, которое здесь следует применять, следующее: глиф, и до тех пор, пока базовый символ также используется в словаре для выражения этого глифа, придерживайтесь основного символа.
Пример 1 : ЛАТИНСКАЯ СТРОЧНАЯ БУКВА Y будет появляться во многих документах с дополнительным диакритическим знаком, указывающим на историю происхождения этого символа от ii или ij. Поэтому вы найдете две точки или что-то подобное над «y».
В простых расшифровках вы будете расшифровывать это как ЛАТИНСКУЮ СТРОЧНУЮ БУКВУ Y, так как основной символ хорошо виден.
Пример 2 : ЛАТИНСКАЯ СТРОЧНАЯ БУКВА S выражается двумя графемами в большинстве европейских исторических шрифтов. Таким образом, мы находим четкое различие между ЛАТИНСКОЙ СТРОЧНОЙ БУКВОЙ S и ЛАТИНСКОЙ СТРОЧНОЙ БУКВОЙ ДЛИННОЙ S.
Но, несмотря на наличие четкого различия, простая транскрипция будет использовать ЛАТИНСКУЮ СТРОЧНУЮ БУКВУ S в обоих случаях.
 ЛАТИНСКАЯ СТРОЧНАЯ БУКВА S Рисунок 24. Палеографическая транскрипция: Thatbeſtand vs. Kammergerichts
ЛАТИНСКАЯ СТРОЧНАЯ БУКВА S Рисунок 24. Палеографическая транскрипция: Thatbeſtand vs. Kammergerichts Примечание. Пожалуйста, примите во внимание, что это важное решение, которое во многом повлияет на удобство использования текста. Если вы решите использовать палеографическую транскрипцию, это потребует гораздо больше работы, чем слегка нормализованная транскрипция.
Знаки препинания
Знаки препинания расшифровываются так же, как и символы. Используйте соответствующий символ на клавиатуре, не нормализуйте и не добавляйте знаки препинания. Типичные знаки препинания:
- современные символы, такие как точка, запятая, точка с запятой, двоеточие: «.», «», «;»:»
- исторические символы, такие как косая черта (косая черта), заполнители строк и т. д.
Обратите внимание, что двоеточия в исторических текстах часто используются для обозначения сокращенных слов. Они должны быть расшифрованы как двоеточие.
В отличие от многих правил транскрипции, где знаки препинания добавляются и опускаются в соответствии с современным пониманием, мы рекомендуем придерживаться исходных знаков препинания.
Если вы хотите добавить знаки препинания, которых нет в исходном документе, вы можете использовать тег «предоставляется» на вкладке «Тегирование» на вкладке «Метаданные», чтобы указать, что знак препинания был добавлен вами.
Работа в команде – добавление других пользователей в вашу коллекцию
В Транскрибусе также можно работать над коллекциями и документами вместе с другими пользователями Транскрибуса. Вы можете добавить кого-то еще в свою коллекцию через «Диспетчер пользователей», который находится на вкладке «Сервер». Сначала вам нужно будет найти другого пользователя по электронной почте или имени внизу справа, затем выбрать правую строку выше, затем выбрать «Добавить пользователя» внизу слева и, наконец, добавить авторизации, которые приходят с ролью пользователя. На скриншоте ниже вы можете проверить права каждой роли пользователя:
Рисунок 25. Роли пользователейСсылки
Чтобы получить обзор скриптов из Unicode: http://www.unicode. org/charts/
org/charts/
Для исторических транскрипций представляют интерес следующие расширения:
Latin Extended -B: http://www.unicode.org/charts/PDF/U0180.pdf
- Содержит, например:
- Неевропейский и исторический латинский
- Фонетические и исторические письма
- Дополнения для словенского и хорватского языков
- и т.д.
Latin Extended-C: http://www.unicode.org/charts/PDF/U2C60.pdf
- Содержит, например:
- Орфографические латинские дополнения
- и т. д.
Расширенная латиница-D: http://www.unicode.org/charts/PDF/UA720.pdf
- Содержит, например:
- Средневековые дополнения
- Островные и кельтские буквы
- Древнеримские эпиграфические письма
- и т. д.
MUFI (Инициатива средневековых шрифтов Unicode)
- В рамках этой инициативы было собрано и систематизировано около 1512 знаков, которые особенно рекомендуются для транскрипции средневековых документов.
 Примечание. Некоторые из них все еще находятся в «частном» разделе Unicode, поэтому официально недоступны.
Примечание. Некоторые из них все еще находятся в «частном» разделе Unicode, поэтому официально недоступны. - http://folk.uib.no/hnooh/mufi/
- http://folk.uib.no/hnooh/mufi/specs/MUFI-Alphabetic-4-0.pdf
Кредиты
Мы хотел бы поблагодарить многих пользователей, которые оставили свои отзывы, чтобы помочь улучшить программное обеспечение Transkribus.
Международный фонетический алфавит (IPA): определение и таблица
Есть ли какие-либо языки, которые вы хотели бы выучить? Было бы здорово, если бы вы знали, как произносить слова на любом языке?
Это действительно возможно благодаря Международному фонетическому алфавиту! Если вы не знаете, что это такое, не волнуйтесь… Мы изучим Международный фонетический алфавит, зачем он был создан и что он может рассказать нам о звуках речи. Мы также рассмотрим фонематическую таблицу английского языка, которая показывает характерные для английского языка звуки речи. Наконец, мы опишем, как транскрибировать телефоны и фонемы.
Что такое Международный фонетический алфавит?
Международный фонетический алфавит (сокращенно IPA) представляет собой набор символов, обозначающих фонетические звуки. Эти звуки известны как телефоны. IPA используется, чтобы помочь нам понять и транскрибировать различные звуки речи на разных языках.
Чем полезен Международный фонетический алфавит?
IPA помогает нам правильно произносить слова. Вместо того, чтобы полагаться на письменное написание слов, которое не всегда совпадает с тем, как мы их произносим, фонетический алфавит описывает звуки слов (без привязки к буквам языка). Итак, когда что-то написано с использованием IPA, оно всегда будет соответствовать произношению. Это особенно полезно для людей, изучающих новый язык, так как они смогут правильно произносить слова.
Кто создал Международный фонетический алфавит?
Международный фонетический алфавит был создан в 1888 году французским лингвистом Полем Пасси.
Символы международного фонетического алфавита (МФА)
Он был основан на латинском алфавите и изначально представлял звуки речи на разных языках, чтобы их можно было легко записать. Он также был создан с целью замены множества ранее использовавшихся отдельных систем транскрипции; единая система для представления звуков на всех языках была бы проще в использовании.
Каковы различные качества речи?
МФА представляет все различные качества и звуки речи на разных языках. К ним относятся:
- Телефоны
- Фонемы
- Интонация
- Разделение между словами
- Слоги.
Давайте рассмотрим их более подробно!
Что такое телефоны?
Телефоны различаются звуками. Когда мы говорим, мы производим телефоны. Телефоны не привязаны к какому-либо языку, поэтому используются во всем мире. Когда мы транскрибируем телефоны, они пишутся в квадратных скобках [ ].
Когда мы транскрибируем телефоны, они пишутся в квадратных скобках [ ].
Что такое фонемы?
Фонемы — это мысленные представления и значения звука слова. Изменение фонемы в слове может изменить его значение. Например, замена фонемы /t/ в слове лист на фонему /p/ создает слово овца . В отличие от телефонов, фонемы зависят от языка, поэтому их нельзя применить ко всем языкам. Когда мы транскрибируем фонемы, они пишутся между косыми чертами / /.
Что такое интонация?
Интонация — это изменение тона голоса во время разговора. Интонация может использоваться по разным причинам, например:
, чтобы показать эмоции или отношение говорящего.
, чтобы показать разницу между утверждением и вопросом.
, чтобы указать, закончил ли говорящий свое предложение.

для добавления ударения к определенным частям предложения, что может немного изменить смысл.
Что такое разделение между словами?
Когда мы говорим, не каждое слово льется и не каждый слог оканчивается на чистый звук. Таким образом, между звуками, которые мы произносим, могут быть промежутки. Например, в слове «крайний» буква «т» часто произносится нечетко. При расшифровке звук «т» можно заменить символом, называемым гортанной смычкой, который выглядит так: ʔ. Он используется для обозначения блокировки воздушного потока, что мешает нам воспроизводить чистый звук.
Что такое слоги?
Слоги — это единицы разговорной речи, которые должны содержать гласный звук, а иногда и согласные. Например, если мы посмотрим на следующие слова:
Книга – 1 слог
Стол – 2 слога
Садоводство – 3 слога
используется для обозначения разрывов между разными слогами.
Таблица 9 Международного фонетического алфавита (IPA)0035
Таблица IPA показывает все звуки и качества речи в системе репрезентативных символов. – Wikimedia Commons (рис. 1)
Есть много информации, которую нужно принять, но не волнуйтесь! Мы просто разберем каждый раздел и рассмотрим каждую часть по очереди. Затем мы больше сосредоточимся на фонематическом алфавите английского языка, так как это поможет объяснить звуки, характерные для английского языка.
МФА можно разделить на:
Легочные согласные
Non-pulmonic consonants
Vowels (monophthongs and diphthongs)
Suprasegmentals
Tones and word accents
Diacritics
Pulmonic consonants
These are consonants that are made давлением воздуха из легких и блокировкой пространства между голосовыми связками. Все согласных в английском языке являются легочными, но есть и некоторые в других языках (см. ниже).
Все согласных в английском языке являются легочными, но есть и некоторые в других языках (см. ниже).
В таблице IPA легочные согласные классифицируются тремя способами:
Звонкость – это относится к тому, издают ли голосовые связки звук. Звонкие согласные возникают в результате вибрации голосовых связок при воспроизведении звука. Например, согласные: Б, Д, Г, Ж, Л. При глухих согласных голосовые связки не производят звук, вместо этого через них проходит воздух. Например, согласные: с, р, т, ф, ф.
Место сочленения – это относится к тому, где во рту издаются звуки.
Способ артикуляции – это относится к тому, как наши органы речи используются для воспроизведения звука, в частности, как блокируется воздушный поток, чтобы издавать различные звуки.

Например, звук, произносимый / б/ , называется звонким двугубным взрывным . Это означает, что для произнесения звука /b/:
Голосовые связки вибрируют, издавая звук (звонкий).
Обе губы сжаты (двугубные).
Голосовой тракт заблокирован, воздух выталкивается через губы (взрывной).
Нелегочные согласные
Это согласные, которые не образуются с потоком воздуха из легких. В английском языке нет нелегочных согласных.
Три типа нелегочных согласных:
Изъявления
Имплозивы
Щелчки
Койсанские языки известны тем, что в них используются щелкающие согласные, которые можно записать с помощью таких символов, как ǃ и ǂ.
Гласные
Гласные — это звуки, которые произносятся без ограничения воздушного потока, и звук зависит от положения рта и языка.
Например, когда мы произносим гласную «а» в слове «выпекать», наши языки находятся далеко от нёба и направлены к передней части рта. Но когда мы произносим гласную «у» в слове «музыка», язык становится близко к нёбу и расположен по направлению к спине .
Типы гласных
Гласные можно разделить на две категории:
- Монофтонги
- Дифтонги
Монофтонги являются односложными звуками . Например, гласный «i» в слове «hit» — это один гласный звук, который можно записать как /ɪ/.
Дифтонги — это две гласные в слоге. Например, в слове «играть» гласная «а» состоит из двух звуков, которые транскрибируются как /eɪ/. Дифтонги также называют скользящими гласными, так как один гласный звук плавно переходит в другой.
Надсегментарии
Группа символов, обозначающих просодические признаки речи, в том числе
Ударение – ударение на определенных частях слова или высказывания.
Тон – изменение высоты голоса.
Длительность – Продолжительность звука, измеряемая в миллисекундах (не путать с длиной гласной)
Разрывы слогов – где заканчивается один слог и начинается другой.
Связывание – отсутствие разрыва слога
Тоны и словесные акценты
Тоны и акценты используются при расшифровке тональных языков, в которых слова могут иметь различное значение в зависимости от используемой интонации (высоты тона) . Примеры тональных языков включают китайский, тайский, вьетнамский.
Примеры тональных языков включают китайский, тайский, вьетнамский.
Диакритические знаки
Диакритические знаки — это знаки, добавляемые к фонетическим символам (например, ударениям или седилам), которые показывают небольшие различия в звуках, слегка изменяющие произношение.
Например, в слове “ручка” после буквы “п” слышно выдыхание воздуха. Это можно показать с помощью диакритического знака [ʰ], поэтому будет выглядеть как [pʰen].
Диакритические символы и их значения показаны в таблице на диаграмме IPA. – Wikimedia Commons (рис. 2)
Звуки МФА
Международный фонетический алфавит используется для представления всех возможных звуков речи. Это звуки, встречающиеся как в английском языке, так и в других языках. Эти звуки можно разделить на телефоны и фонемы. Мы рассмотрим эти термины и звуки английского языка ниже.
Международный фонетический алфавит (IPA) звуки английского языка
Звуки английского языка (или любого другого языка) показаны в фонематической таблице.
Эта фонематическая таблица основана на IPA и специфична для английского языка. Ниже показаны 44 английские фонемы:
Английский фонематический алфавит показывает все фонемы, используемые в английском языке. – Викисклад (рис. 3).
Расшифровка телефонов
При расшифровке телефоны записываются в квадратных скобках [ ]. Фонетическая транскрипция детализирована, в том числе многие элементы звуков речи, чтобы уточнить варианты произношения. Это так называемые «узкие транскрипции».
Ниже приведены некоторые примеры фонетической транскрипции. Все они написаны в соответствии с британским принятым произношением.
Булавка – [pʰɪn]
Крыло – [wɪ̃ŋ]
Порт – [pʰɔˑt]
Диакритические знаки используются в транскрипциях выше, чтобы показать определенные различия в произношении. [ʰ] указывает на аспирацию – слышимый выдох воздуха. [ h ] указывает на назализацию – воздух выходит из носа.
Расшифровка фонем
При расшифровке фонем они пишутся между косыми чертами / /. В фонематических транскрипциях упоминаются только наиболее очевидные и важные элементы звуков речи. Это так называемые «широкие транскрипции».
Ниже приведены некоторые примеры фонематических транскрипций. Все они написаны в соответствии с британским принятым произношением.
Булавка – /pɪn/
Крыло – /wɪŋ/
Порт – /pɔːt/
Поскольку фонематическая транскрипция не так подробна, как фонетическая транскрипция, диакритические знаки не нужны, поскольку они не нужны для понимания значения слов.
Международный фонетический алфавит. Ключевые выводы
- Международный фонетический алфавит (IPA) представляет собой набор символов, обозначающих фонетические звуки.
- IPA помогает нам транскрибировать слова на разных языках и произносить слова точно независимо от языка.
